







Summarizing Source Code using a Neural Attention Model
论文概述
高质量的源代码通常与它的功能摘要相匹配,例如在代码文档或论坛在线发布的描述。
比如,如下C#代码和SQL查询以及其对应的摘要
public int TextWidth(string text){
TextBlock t = new TextBlock ();
t.Text = text;
return (int)Math.Ceiling(t.ActualWidth );
}
Descriptions:
a. Get rendered width of string rounded up tothe nearest integer
b. Compute the actual textwidth inside a textblock
var input = "Hello";
var regEx = new Regex("World");
return !regEx.IsMatch(input);
Descriptions:
a.Return if the input doesn’t contain aparticular word in it
b.Lookup a substring in a string using regex
SELECT Max(marks) FROM stud_recordsWHERE marks <(SELECT Max(marks) FROM stud_records);
Descriptions:
a. Get the second largest value of a column
b. Retrieve the next max record in a table
摘要对于代码搜索(code search)等任务非常有用,但手工编写代码文档(摘要)的成本很高,因此,只有一小部分代码有相应的代码文档。
所以,作者提出了CODE-NN,来为C# code snippets 和SQL queries生成相应的描述语句。
作者将CODE-NN应用在了2个任务上:
- code summarization(代码摘要生成)
- code retrieval(代码检索)
任务描述
用 U C U_C UC 表示 code snippets集合, U N U_N UN 表示自然语言摘要(summaries)集合。
对于一个有
J
J
J 个 (code snippet, 自然语言summary)对的训练语料库
(
c
j
,
n
j
)
,
1
≤
j
≤
J
,
c
j
∈
U
C
,
n
j
∈
U
N
(c_j, n_j), 1 \le j \le J, c_j \in U_C, n_j \in U_N
(cj,nj),1≤j≤J,cj∈UC,nj∈UN
定义如下2个任务
code summarization (GEN)
给定一个code snippet
c
∈
U
C
c \in U_C
c∈UC, 生成自然语言描述
n
∗
n^*
n∗
其中
n
∗
n^*
n∗ 满足
n
∗
=
a
r
g
m
a
x
n
s
(
c
,
n
)
n^* = \mathop{argmax}\limits_{n} s(c, n)
n∗=nargmaxs(c,n)
s
s
s 为 scoring function
s ( c , n ) = ∏ i = 1 l p ( n i ∣ n 1 , . . . , n i − 1 ) s(c, n) = \prod\limits_{i = 1}^l p(n_i | n_1, ..., n_{i - 1}) s(c,n)=i=1∏lp(ni∣n1,...,ni−1)
code retrieval (RET)
代码检索任务可以看作是摘要生成的逆任务,可以使用同样的scoring function, 给定自然语言摘要 n ∈ U N n \in U_N n∈UN, 查询到code snippet c j ∗ c_j^* cj∗
c j ∗ = a r g m a x c j ∗ s ( c j ∗ , n ) , 1 ≤ j ≤ J c_j^* = \mathop{argmax}\limits_{c_j^*} s(c_j^*, n) ,1 \le j \le J cj∗=cj∗argmaxs(cj∗,n),1≤j≤J
可以看到检索任务是搜索数据库中最匹配的代码片段,并不属于生成式任务。
数据集
数据集收集自StackOverflow。
StackOverflow中每个post,有多个标签,并由1个title,1个question和多个response组成。
下载标签为c#的用作c#数据集,下载标签为sql,database和oracle用作sql数据集。
提取title和被接受的answer的code片段作为(title, code)对。并训练了一个分类器来过滤 Difficult C# if then logic 或者 How can I make this query easier to write? 这类无关的title。
数据预处理部分
这里,作者用ANTLR来解析C#代码,用python 的sqlparse库来处理SQL语句。
处理的主要步骤有:
- 去掉了所有注释
- 为了避免上下文特定,将文字替换为表示其类型的标记(符号化)。
比如,一个SQL语句处理后为:SELECT MAX(col0) FROM tab0 WHERE col0 <(SELECT MAX(col0) FROM tab0)。 其中tab0 col0 分别表示表和列。
之后会被解析为token序列,上述SQL语句会被处理为
select max ( col0 ) from tab0 where col0 < ( select max ( col0 ) from tab0 )
CODE-NN模型
结构体如下所示:
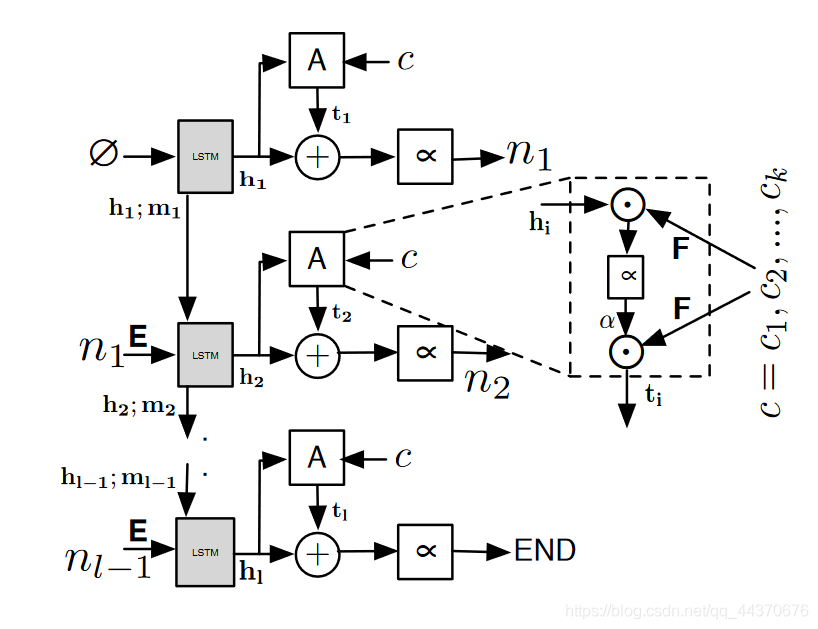
这个模型类似于机器翻译采用的seq2seq + attention模型。
自然语言序列表示为
n
=
n
1
,
.
.
.
,
n
l
n = n_1,...,n_l
n=n1,...,nl。其中
n
i
,
1
≤
i
≤
l
n_i, 1 \le i \le l
ni,1≤i≤l 为词的one-hot向量。
源代码序列表示为
c
=
c
1
,
.
.
.
,
c
k
c = c_1,...,c_k
c=c1,...,ck。 其中
c
i
,
1
≤
i
≤
k
c_i, 1 \le i \le k
ci,1≤i≤k 为源代码token的one-hot向量。
代码作者已开源:codenn














 1813
1813











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









