







Explainability in Graph Neural Networks:A Taxonomic Survey
一.解释方法
作者用到的解释方法太多了,这里就看2个
1.1.SubgraphX
subgraphX聚焦图分类任务,并
- 用 f ( . ) f(.) f(.) 表示要解释的GNN分类模型
- 输入图 G G G, 输出标签为 y y y
- 潜在的子图集合为 { G 1 , ⋅ ⋅ ⋅ , G i , ⋅ ⋅ ⋅ , G n } \{G_1,···,G_i,···,G_n\} {G1,⋅⋅⋅,Gi,⋅⋅⋅,Gn}
目标是选取子图
G
∗
G^*
G∗,满足
G
∗
=
a
r
g
m
a
x
∣
G
i
∣
≤
N
m
i
n
S
c
o
r
e
(
f
(
⋅
)
,
G
,
G
i
)
G^* = \underset{|G_i| \leq N_{min}}{argmax } \; Score(f(·),G,G_i)
G∗=∣Gi∣≤NminargmaxScore(f(⋅),G,Gi)
- N m i n N_{min} Nmin 为子图大小上限
- S c o r e ( ⋅ , ⋅ , ⋅ ) Score(·,·,·) Score(⋅,⋅,⋅) 为一个得分函数,用来衡量子图重要性
这里获取 G ∗ G^* G∗ 最直接暴力的方式就是遍历所有的 G i G_i Gi,然而当图 G G G 非常大时,这样做会很棘手,因此需要一个高效的搜索方法。
可以说搜索算法(search algorithm)和得分函数(scoring function)
- 作者用蒙特卡洛树(MCTS)作为搜索算法
- 用Shapley Value作为得分函数。关于Shapley Value可以参考博弈论之Shapley Value(Shapley值)
1.1.1.搜索算法
MCTS搜索树的根节点 N 0 N_0 N0 与初始的输入图 G G G 相关联。搜索树的一条边表示这条边子结点 N c h i l d N_{child} Nchild 相关联的图 G c h i l d G_{child} Gchild 可通过其父节点 N p a r e n t N_{parent} Nparent 相关联的图 G p a r e n t G_{parent} Gparent 通过修剪(node-pruning)得到,即这条边表示一次修剪操作 a a a。一颗MCTS树结点可有多个修剪操作,且修剪操作与数据集或者邻域知识有关。对于 pair ( N i , a j ) (N_i, a_j) (Ni,aj),有
- 子图 G i G_i Gi 与 N i N_i Ni 相关联
- G j G_j Gj 有 G i G_i Gi 通过修剪操作 a j a_j aj 获得
- C ( N i , a j ) C(N_i,a_j) C(Ni,aj) 表示 N i N_i Ni 可选的修剪操作数量( a j a_j aj 的数量)
- W ( N i , a j ) W(N_i,a_j) W(Ni,aj) 为所有的 ( N i , a j ) (N_i,a_j) (Ni,aj) 遍历的奖励
- Q ( N i , a j ) = W ( N i , a j ) / C ( N i , a j ) Q(N_i,a_j) = W(N_i,a_j)/C(N_i,a_j) Q(Ni,aj)=W(Ni,aj)/C(Ni,aj) 表示平均奖励
- R ( N i , a j ) R(N_i,a_j) R(Ni,aj) 为 N i N_i Ni 进行 a j a_j aj 操作的即时奖励,作者用这个作为得分函数,即 R ( N i , a j ) = S c o r e ( f ( ⋅ ) , G , G j ) R(N_i,a_j) = Score(f(·),G,G_j) R(Ni,aj)=Score(f(⋅),G,Gj)
而对于
N
i
N_i
Ni, 其最终操作
a
∗
a^*
a∗ 满足
a
∗
=
a
r
g
m
a
x
a
j
Q
(
N
i
,
a
j
)
+
U
(
N
i
,
a
j
)
a^∗= \underset{a_j}{argmax} \; Q(N_i,a_j) + U(N_i,a_j)
a∗=ajargmaxQ(Ni,aj)+U(Ni,aj)
U ( N i , a j ) = λ . R ( N i , a j ) . ∑ k C ( N i , a k ) 1 + C ( N i , a j ) U(N_i,a_j) = \lambda.R(N_i,a_j).\frac{\sqrt{\sum_k C(N_i,a_k)}}{1 + C(N_i,a_j)} U(Ni,aj)=λ.R(Ni,aj).1+C(Ni,aj)∑kC(Ni,ak)
1.1.2.得分函数
用的是Shapley Value,给定
- GNN模型 f ( ⋅ ) f(·) f(⋅)
- V = { v 1 , ⋅ ⋅ ⋅ , v i , ⋅ ⋅ ⋅ , v m } V = \{v_1,···,v_i,···,v_m\} V={v1,⋅⋅⋅,vi,⋅⋅⋅,vm} 表示图 G G G 中所有结点
- G i G_i Gi 为拥有 k k k 个结点的子图并令其为 { v 1 , ⋅ ⋅ ⋅ , v k } \{v_1,···,v_k\} {v1,⋅⋅⋅,vk}
- { v k + 1 , ⋅ ⋅ ⋅ , v m } \{v_{k+1},···,v_m\} {vk+1,⋅⋅⋅,vm} 属于 G \ G i G \backslash G_i G\Gi
- player集合定义为 P = { G i , v k + 1 , ⋅ ⋅ ⋅ , v m } P = \{G_i, v_{k+1},···,v_m\} P={Gi,vk+1,⋅⋅⋅,vm},即子图 G i G_i Gi 为1个player
G i G_i Gi 的Shapley value可通过如下步骤计算:
随机sample T T T 个set { S 1 , S 2 , . . . , S T } \{S_1, S_2,..., S_T\} {S1,S2,...,ST}
m ( S t , G i ) = f ( S t ∪ { G i } ) − f ( S t ) m(S_t, G_i) = f(S_t \cup \{Gi\}) − f(S_t) m(St,Gi)=f(St∪{Gi})−f(St)
在计算 f ( S j ) f(S_j) f(Sj) 时,对于图中不属于 S j S_j Sj 的结点,将它们的特征向量置0.
S c o r e ( f ( ⋅ ) , G , G i ) = 1 T ∑ t = 1 T m ( S t , G i ) Score(f(·),G,G_i) = \frac{1}{T} \sum\limits_{t = 1}^T m(S_t, G_i) Score(f(⋅),G,Gi)=T1t=1∑Tm(St,Gi)
这里没有用到标准的Shapley value计算公式,考虑到它计算太过耗时并且需要遍历所有的 S S S 集合。
1.1.3.实验复现
这里我只用Graph-SST2数据集复现实验结果。根据作者的代码
- 搜索算法中,对结点 N i N_i Ni 生成MCTS树的备选子结点时,从 N i N_i Ni 对应图 G i G_i Gi 中选取度最大的 K K K(代码中设置为12)个结点作为备选修剪操作,修剪后生成子结点 N j N_j Nj, N j N_j Nj 对应的图 G i G_i Gi 为删除一个备选结点之后剩下的图中的最大连通分量。此外,该代码只适用于无向图,有向图数据需要先转化为无向图。
- 评估结果时用到的指标为 F i d e l i t y + p r o b Fidelity^{+prob} Fidelity+prob 和 S p a r s i t y Sparsity Sparsity。
Graph-SST2测试集上的实验结果大约为:
- Fidelity: 0.45-0.55
- Sparsity: 0 - 0.5
直观上:
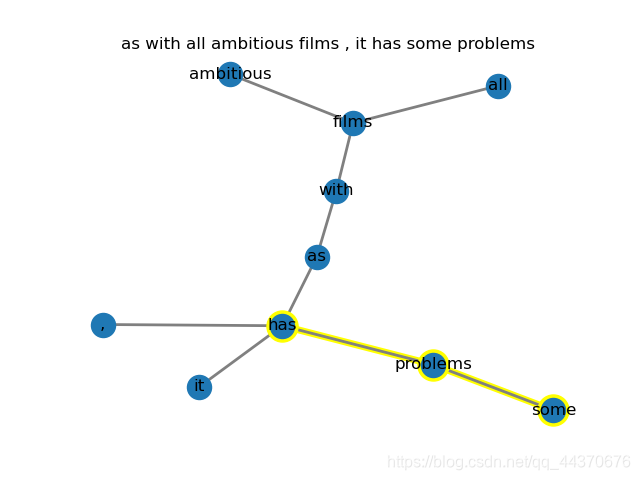
标为黄色的即为解释子图
总的来说,SubgraphX首先的选出最可能影响预测结果(从度最大的几个结点触发)的子图(严格意义上的子图,即保证连通性)的角度来解释GNN模型,但是它并非一种基于学习的方式,需要人为定义规则,并且对于情感分类这种文本分类来说,有时候可能关键在于一小部分结点(负类情感的词),也就是需要从结点的特征来入手,当影响预测结果的结点在图的边界结点而不是中心结点时预测结果可能非常差。
1.2.PGExplainer
1.2.1.背景知识
图的表示
- G = ( V , E ) G = (V,E) G=(V,E)
- V = { v 1 , . . . , v n } V = \{v_1,...,v_n\} V={v1,...,vn} 为结点集合( n n n 个结点)
- E = V × V E = V \times V E=V×V 表示边集合( m m m 条边)
- A ∈ { 0 , 1 } n × n A \in \{0,1\}^{n \times n} A∈{0,1}n×n 为邻接矩阵
- X ∈ R n × d X \in R^{n \times d} X∈Rn×d 为图结点的特征矩阵
图神经网络是基于消息传播机制,用
N
i
N_i
Ni 表示第
i
i
i 个结点的邻居结点集合,对一个
L
L
L 层的GNN网络,第
i
i
i 个结点第
l
l
l 层的隐层向量计算
h
i
l
h^l_i
hil 如下
m
i
j
l
=
M
e
s
s
a
g
e
(
h
i
l
−
1
,
h
j
l
−
1
)
m^l_{ij} = Message(h^{l−1}_i, h^{l−1}_j)
mijl=Message(hil−1,hjl−1)
m i l = a g g r e g a t i o n ( m i j l ∣ j ∈ N i ) m^l_i = aggregation({m^l_{ij} | j \in N_i}) mil=aggregation(mijl∣j∈Ni)
h i l = u p d a t e ( m i l , h i l − 1 ) h^l_i = update(m^l_i , h^{l−1}_i) hil=update(mil,hil−1)
而结点 i i i 的特征向量 z i = h i L z_i = h^L_i zi=hiL 会应用在结点分类,图分类等下游任务
1.2.2 解释目标
这里将一个GNN的分类过程拆分为2个部分,1个是获取结点特征向量,一个是获取分类结果
Z = G N N E Φ 0 ( G o , X ) Z = GNNE_{\Phi_0}(G_o,X) Z=GNNEΦ0(Go,X)
Y = G N N C Φ 1 ( Z ) Y = GNNC_{\Phi_1}(Z) Y=GNNCΦ1(Z)
这里
- Z = { z 1 , . . . , z n } Z = \{z_1, ..., z_n\} Z={z1,...,zn} 为GNN输出的图结点的特征向量
- Y Y Y 为最终的概率分布。如果是图分类(graph classification),那么GNNC很可能包括了graph pooling层和MLP分类器。如果是结点分类(node classification),那么GNNC可能只包括MLP分类器。
- Φ = [ Φ 0 , Φ 1 ] \Phi = [\Phi_0, \Phi_1] Φ=[Φ0,Φ1] 为GNN的参数
解释的最终目标函数为
m
i
n
Ω
−
1
K
∑
k
=
1
K
∑
c
=
1
C
P
Φ
(
Y
=
c
∣
G
=
G
o
)
l
o
g
P
Φ
(
Y
=
c
∣
G
=
G
^
s
k
)
\underset{\Omega}{min} -\frac{1}{K}\sum\limits_{k = 1}^K \sum\limits_{c = 1}^C P_\Phi(Y=c|G=G_o) log P_\Phi(Y=c|G=\hat G^{k}_s)
Ωmin−K1k=1∑Kc=1∑CPΦ(Y=c∣G=Go)logPΦ(Y=c∣G=G^sk)
- G o G_o Go 为原始输入图
- K K K 为采样出来的子图总数
- C C C 为类别总数
- Ω \Omega Ω 为解释方法所用模型的参数
- G s k G^{k}_s Gsk 为 G o G_o Go 采样出来的第 k k k 个子图
- P Φ ( Y = c ∣ G = G o ) P_\Phi(Y=c|G=G_o) PΦ(Y=c∣G=Go) 表示GNN模型预测的 G o G_o Go 属于类别 c c c 的概率(包括图分类和结点分类)
- P Φ ( Y = c ∣ G = G ^ s k ) P_\Phi(Y=c|G=\hat G^{k}_s) PΦ(Y=c∣G=G^sk) 为GNN模型预测的采样出来的第 k k k 个子图属于类别 c c c 的概率
1.2.3 解释步骤
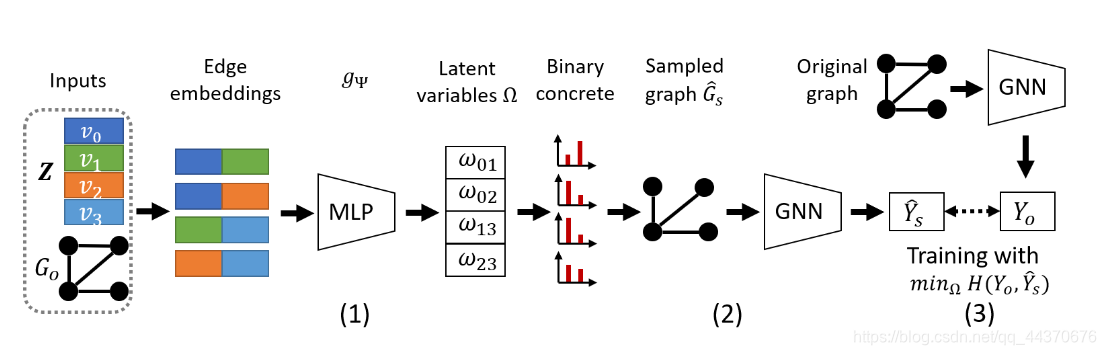 PGExplainer对GNN的解释基于概率图模型,
e
i
j
=
1
e_{ij} = 1
eij=1 表示边
(
i
,
j
)
(i, j)
(i,j) 被选到了子图当中。
P
(
e
i
j
=
1
)
=
θ
i
j
P(e_{ij} = 1) = \theta_{ij}
P(eij=1)=θij 表示边
(
i
,
j
)
(i, j)
(i,j) 被选中的概率。选中子图
G
G
G 的概率则为
P
(
G
)
=
∏
(
i
,
j
)
∈
ε
P
(
e
i
j
)
P(G) = \prod_{(i,j) \in \varepsilon}P(e_{ij})
P(G)=∏(i,j)∈εP(eij) 。
ε
\varepsilon
ε 为边集合
PGExplainer对GNN的解释基于概率图模型,
e
i
j
=
1
e_{ij} = 1
eij=1 表示边
(
i
,
j
)
(i, j)
(i,j) 被选到了子图当中。
P
(
e
i
j
=
1
)
=
θ
i
j
P(e_{ij} = 1) = \theta_{ij}
P(eij=1)=θij 表示边
(
i
,
j
)
(i, j)
(i,j) 被选中的概率。选中子图
G
G
G 的概率则为
P
(
G
)
=
∏
(
i
,
j
)
∈
ε
P
(
e
i
j
)
P(G) = \prod_{(i,j) \in \varepsilon}P(e_{ij})
P(G)=∏(i,j)∈εP(eij) 。
ε
\varepsilon
ε 为边集合
采样过程表示为
G
s
=
f
Ω
(
G
o
,
τ
,
ϵ
)
G_s = f_\Omega(G_o, \tau, \epsilon)
Gs=fΩ(Go,τ,ϵ)
边
(
i
,
j
)
(i,j)
(i,j) 的权重
e
^
i
j
=
σ
(
(
l
o
g
ϵ
−
l
o
g
(
1
−
ϵ
)
+
ω
i
j
)
/
τ
)
\hat e_{ij} = \sigma((log \epsilon - log(1 - \epsilon) + \omega_{ij}) / \tau)
e^ij=σ((logϵ−log(1−ϵ)+ωij)/τ)
对结点分类任务中对结点
v
v
v 的解释中
ω
i
j
=
M
L
P
Ψ
(
[
z
i
;
z
j
;
z
v
]
)
\omega_{ij} = MLP_\Psi([z_i; z_j; z_v])
ωij=MLPΨ([zi;zj;zv])
其中边
(
i
,
j
)
(i, j)
(i,j) 对
v
v
v 的解释不重要(没太看懂这句)。
对图分类的解释中
ω
i
j
=
M
L
P
Ψ
(
[
z
i
;
z
j
]
)
\omega_{ij} = MLP_\Psi([z_i; z_j])
ωij=MLPΨ([zi;zj])
- τ , ϵ \tau, \epsilon τ,ϵ 为外部设置的参数,其中 ϵ ∼ U n i f o r m ( 0 , 1 ) \epsilon \sim Uniform(0,1) ϵ∼Uniform(0,1) 随机产生, τ \tau τ 需要人工设置,并会随着训练epoch变化而变化。
- ω i j ∈ Ω \omega_{ij} \in \Omega ωij∈Ω 为模型的参数
- 用梯度 ∂ e ^ i j ∂ ω i j \frac{\partial \hat e_{ij}}{\partial \omega_{ij}} ∂ωij∂e^ij 来优化目标函数
- M L P Ψ MLP_\Psi MLPΨ 为多层神经网络模型 。 Ψ \Psi Ψ 为其参数, [ . ; . ] [.;.] [.;.] 表示concatenation操作
1.2.4 实验复现
这里用到了torch_geometric.nn.conv.GCNConv,其中包括了
# Support for GNNExplainer.
self.__explain__ = False
self.__edge_mask__ = None
2个属性。希望有大佬可以讲讲torch_geometric.nn.GCNConv的区别,在对边进行mask的时候用到了这个API。
1.2.4.1 前向传播
def forward(self, inputs, training=None):
x, embed, edge_index, tmp = inputs # X向量,Z向量,边,τ
nodesize = embed.shape[0]
feature_dim = embed.shape[1]
f1 = embed.unsqueeze(1).repeat(1, nodesize, 1).reshape(-1, feature_dim)
f2 = embed.unsqueeze(0).repeat(nodesize, 1, 1).reshape(-1, feature_dim)
# using the node embedding to calculate the edge weight
f12self = torch.cat([f1, f2], dim=-1)
h = f12self.to(self.device)
for elayer in self.elayers:
h = elayer(h)
values = h.reshape(-1) # value = w_ij,[num_node * num_node]
values = self.concrete_sample(values, beta=tmp, training=training) # value = e_ij
self.mask_sigmoid = values.reshape(nodesize, nodesize) # e^ij=σ((logϵ−log(1−ϵ)+ωij)/τ)
# set the symmetric edge weights
sym_mask = (self.mask_sigmoid + self.mask_sigmoid.transpose(0, 1)) / 2
edge_mask = sym_mask[edge_index[0], edge_index[1]]
# inverse the weights before sigmoid in MessagePassing Module
edge_mask = inv_sigmoid(edge_mask)
self.__clear_masks__()
self.__set_masks__(x, edge_index, edge_mask)
# the model prediction with edge mask
data = Batch.from_data_list([Data(x=x, edge_index=edge_index)])
data.to(self.device)
outputs = self.model(data)
return outputs[1].squeeze(), edge_mask
前向传播的输入参数包括结点初始向量 X X X, G N N E Φ 0 GNNE_{\Phi_0} GNNEΦ0 输出的 结点向量 Z Z Z ,边集合,论文中的参数 τ \tau τ。
f12self 为拼接的结点向量,shape为 [node_size, node_size, feature_dim] 。f12self[i,j] 表示结点
(
i
,
j
)
(i,j)
(i,j) 的拼接向量,这里还并没有考虑edge_index。
for elayer in self.elayers: h = elayer(h) 表示
ω
i
j
=
M
L
P
Ψ
(
[
z
i
;
z
j
]
)
\omega_{ij} = MLP_\Psi([z_i; z_j])
ωij=MLPΨ([zi;zj])(这里用图分类)。
values = self.concrete_sample(values, beta=tmp, training=training) 计算的是
(
l
o
g
ϵ
−
l
o
g
(
1
−
ϵ
)
+
ω
i
j
)
/
τ
(log \epsilon - log(1 - \epsilon) + \omega_{ij}) / \tau
(logϵ−log(1−ϵ)+ωij)/τ
self.__clear_masks__() 和 self.__set_masks__(x, edge_index, edge_mask) 分别清除上一个子图的mask和设置该子图的mask。这里用到了torch_geometric.nn.conv.GCNConv的API。前向传播输出的是论文中的
P
Φ
(
Y
=
c
∣
G
=
G
^
s
k
)
P_\Phi(Y=c|G=\hat G^{k}_s)
PΦ(Y=c∣G=G^sk)
1.2.4.2 loss
在代码中其loss定义如下:
def __loss__(self, prob, ori_pred):
"""
the pred loss encourages the masked graph with higher probability,
the size loss encourage small size edge mask,
the entropy loss encourage the mask to be continuous.
"""
logit = prob[ori_pred]
logit = logit + EPS
pred_loss = -torch.log(logit)
# size
edge_mask = torch.sigmoid(self.mask_sigmoid)
size_loss = self.coff_size * torch.sum(edge_mask)
# entropy
edge_mask = edge_mask * 0.99 + 0.005
mask_ent = - edge_mask * torch.log(edge_mask) - (1 - edge_mask) * torch.log(1 - edge_mask)
mask_ent_loss = self.coff_ent * torch.mean(mask_ent)
loss = pred_loss + size_loss + mask_ent_loss
return loss
可以看到PGExplainer的loss包括3个部分:
- pred loss
- size loss
- mask entropy loss
其中pred loss即一开始的目标函数,不过代码中做了一些修改,原本的
−
1
K
∑
k
=
1
K
∑
c
=
1
C
P
Φ
(
Y
=
c
∣
G
=
G
o
)
l
o
g
P
Φ
(
Y
=
c
∣
G
=
G
^
s
k
)
-\frac{1}{K}\sum\limits_{k = 1}^K\sum\limits_{c = 1}^C P_\Phi(Y=c|G=G_o) log P_\Phi(Y=c|G=\hat G^{k}_s)
−K1k=1∑Kc=1∑CPΦ(Y=c∣G=Go)logPΦ(Y=c∣G=G^sk)
变成了
−
1
K
∑
k
=
1
K
l
o
g
(
P
Φ
(
Y
=
c
∣
G
=
G
^
s
k
)
+
e
p
s
)
,
e
p
s
为
常
量
-\frac{1}{K}\sum\limits_{k = 1}^Klog (P_\Phi(Y=c|G=\hat G^{k}_s) + eps) ,eps为常量
−K1k=1∑Klog(PΦ(Y=c∣G=G^sk)+eps),eps为常量
size loss的意义在于尽可能的生成小的子图,增加稀疏度。代码中的edge_mask为一个
n
×
n
n \times n
n×n 的矩阵。第
(
i
,
j
)
(i,j)
(i,j) 项为
e
^
i
j
=
σ
(
(
l
o
g
ϵ
−
l
o
g
(
1
−
ϵ
)
+
ω
i
j
)
/
τ
)
\hat e_{ij} = \sigma((log \epsilon - log(1 - \epsilon) + \omega_{ij}) / \tau)
e^ij=σ((logϵ−log(1−ϵ)+ωij)/τ)。self.coff_size 为人工设置的常量参数。
mask entropy loss在于尽量让 e ^ i j \hat e_{ij} e^ij 的值连续。
1.2.4.3 如何解释GNN
以Graph-SST2数据集为例
def calculate_selected_nodes(data, edge_mask, top_k):
threshold = float(edge_mask.reshape(-1).sort(descending=True).values[min(top_k, edge_mask.shape[0]-1)])
hard_mask = (edge_mask > threshold).cpu() # 矩阵中为一的为top_k的边
edge_idx_list = torch.where(hard_mask == 1)[0]
selected_nodes = []
edge_index = data.edge_index.cpu().numpy()
for edge_idx in edge_idx_list:
selected_nodes += [edge_index[0][edge_idx], edge_index[1][edge_idx]]
selected_nodes = list(set(selected_nodes))
return selected_nodes
data表示输入的图,edge_mask为[num_node, num_node] 矩阵,表示每条边被选中的概率,top_k为人工设定的参数,DIG中设定的默认值为5。可以看到它实际上是先选出概率最大的top_k个边,再将top_k个边对应的结点加入解释结点集合,实质上最后还是利用结点解释(仅仅考虑Graph-SST2)。
由于结果涉及的图太多了,这里就不粘贴了。
1.2.5 总结
PGExplainer是一个基于边的解释方法,模型主要包括1个 M L P MLP MLP 模型,用以预测边 ( i , j ) (i,j) (i,j) 被选到解释子图中的概率。 与SubgraphX不同的是它是基于学习的方法。
二.数据集
1.合成数据集
- BA-shapes: 结点分类数据集
- BA-Community: 结点分类数据集
- Tree-Cycle: 结点分类数据集
- Tree-Grids: 结点分类数据集
- BA-2Motifs: 图分类数据集
2.情感分类数据集
基于SST2,SST5 和Twitter 3个情感分类数据集制作3个图数据集Graph-SST2, Graph-SST5, Graph-Twitter,其中每个单词为一个结点,而有向边表示2个词之间的联系,并且用BERT对结点进行初始embedding。作者通过Biaffine parser来提取词之间的关系。

3.分子数据集
结点表示原子,边表示化学键,数据集有
- MUTAG
- BBBP
- Tox21
三.评估解释方法的指标
1.Fidelity
保真度(Fidelity)用来确保解释方法选取出对模型分类影响较大的输入特征 (nodes / edges / node features) 。当这些特征被删除时,预测结果应该有大幅改变。
用 G i G_i Gi 表示数据集中第 i i i 个图。 f ( G i ) f(G_i) f(Gi) 为GNN模型的预测结果概率分布。 y i ^ = a r g m a x ( f ( G i ) ) \hat{y_i} = argmax(f(G_i)) yi^=argmax(f(Gi))。 m i m_i mi 为一个mask向量表示选取出来的重要特征
F i d e l i t y + a c c = 1 N ∑ i = 1 N ( l ( y i ^ = y i ) + l ( y i ^ 1 − m i = y i ) ) Fidelity^{+acc} = \frac{1}{N}\sum\limits_{i = 1}^N(l(\hat{y_i} = y_i) + l(\hat{y_i}^{1 - m_i} = y_i)) Fidelity+acc=N1i=1∑N(l(yi^=yi)+l(yi^1−mi=yi))
- y i y_i yi 为原始的预测结果
- l ( y i ^ = y i ) = { 1 i f y i ^ = y i 0 o t h e r w i s e l(\hat{y_i} = y_i) = \left\{\begin{array}{rcl}1 & & if \; \hat{y_i} = y_i\\ 0 & & {otherwise}\\ \end{array} \right. l(yi^=yi)={10ifyi^=yiotherwise
F i d e l i t y + p r o b = 1 N ∑ i = 1 N ( f ( G i ) − f ( G i 1 − m i ) ) Fidelity^{+prob} = \frac{1}{N}\sum\limits_{i = 1}^N(f(G_i) - f(G_i^{1 - m_i})) Fidelity+prob=N1i=1∑N(f(Gi)−f(Gi1−mi))
F i d e l i t y − a c c = 1 N ∑ i = 1 N ( l ( y i ^ = y i ) + l ( y i ^ m i = y i ) ) Fidelity^{-acc} = \frac{1}{N}\sum\limits_{i = 1}^N(l(\hat{y_i} = y_i) + l(\hat{y_i}^{m_i} = y_i)) Fidelity−acc=N1i=1∑N(l(yi^=yi)+l(yi^mi=yi))
F i d e l i t y − p r o b = 1 N ∑ i = 1 N ( f ( G i ) − f ( G i m i ) ) Fidelity^{-prob} = \frac{1}{N}\sum\limits_{i = 1}^N(f(G_i) - f(G_i^{m_i})) Fidelity−prob=N1i=1∑N(f(Gi)−f(Gimi))
2.Sparsity
好的解释方法应该具备稀疏性,也就是提取出的特征应该尽量不相关,特征数尽可能少。
S p a r s i t y = 1 N ∑ i = 1 N ( 1 − ∣ m i ∣ ∣ M i ∣ ) Sparsity = \frac{1}{N} \sum\limits^N_{i=1}(1 − \frac{|m_i|}{|M_i|}) Sparsity=N1i=1∑N(1−∣Mi∣∣mi∣)
- ∣ m i ∣ |m_i| ∣mi∣ 表示选取的特征数(结点数/边数)
- ∣ M i ∣ |M_i| ∣Mi∣ 表示图中特征的总数(结点数/边数)
3.Stability
稳定性是指当输入图中出现小的改动并且没有影响预测结果,那么相应的解释也应该保持稳定。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









