









Towards Making Deep Learning-based Vulnerability Detectors Robust
一.Introduction
这篇paper主要研究的是DL-based vulnerability detectors的鲁棒性(robustness)。所有的ML-based应用都会受到对抗样本的影响,在image processing,speech recognition,malware detection,program analysis,code authorship attribution等领域都开展了相关的研究。而在漏洞识别领域还没展开,主要是adversarial vulnerability examples必须是可编译可执行的代码,并且要保存语义和漏洞(程序功能不变的同时不改变漏洞),这个要求在其它领域是不存在的。
作者的contribution主要有3部分:
- 作者采用了能保存语义的code transformation方法表明4个代表性的DL-based detectors在面对对抗样本时鲁棒性不够。这4种方法从不同的粒度(granularity)出发,使用不同的vector representations和神经网络。(论文中section2)
- 为了使DL-based detectors鲁棒到足以对付对抗样本,作者提出了一个框架,ZigZag,核心在于减弱feature learning和classifier learning来使得学习到的features和classifiers足够鲁棒。实验结果表明这个框架可以降低模型的FPR和FNR。(框架在论文section3,实验在论文section4)
- 作者从NVD和SARD重新获取一个数据集,总共50,562个vulnerable function以及80,043个non-vulnerable function,作者将数据集和ZigZag框架都开源到github。
二.Robustness Of DL-Based Detectors
一个DL-based detector D D D 由一系列源代码训练好,Defender(或者说开发者)会用 D D D 来判断一个Program是否包含漏洞,而一个Attacker会对输入Program进行一些修改,在不改变程序基本逻辑并保留漏洞的基础上绕过 D D D 的检测。
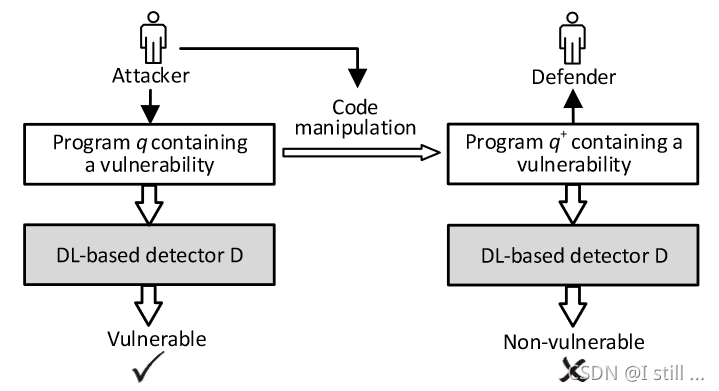
2.1.Attack Requirements
攻击者对代码的修改称为attack,这一部分有3个要求:
- 保存程序的语义信息,不能破坏程序原有的功能。
- 不使用混淆(obfuscation )技巧,因为用户不太可能使用第三方库中经过混淆的代码,因为不太可信(容易有恶意代码混入)。
- 修改前代码的漏洞必须被保存下来。攻击者的目的就是使得漏洞可以逃过检测。
2.2.Attack Experiments
2.2.1.Selecting DL-based Detectors
DL-based Detectors会在下面几个方面有各自的不同:
- 检测粒度(granularity):function(Devign)或者program slice(VulDeePecker)
- 向量表示(vector representation):sequence-based(VulDeepecker),AST-based
- 神经网络(neural network):BGRU,BLSTM,CNN
作者由此选取了4个代表性的DL-based detectors。
- Program Slice + Sequence + BGRU:代表是SySeVR,这是VulDeepecker的一个扩展。一个program slice是由语义上相关的一些statement构成。而一个slice会被解析为token序列,再通过BGRU分类。
- Function + Sequence + CNN:代表是Russell(IVDetect对比实验有),它的检测基本单位是程序的一个函数,每个函数会被解析为token序列并用CNN来进行分类。
- Function + Sequence + BLSTM:跟上面一个类似,不过最后用的分类器是BLSTM。
- Function + AST + BLSTM:用code2vec等tool将多个AST Path聚合成一个向量。
2.2.2.Preparing Dataset
作者的这个研究需要的数据集要满足下面条件:
- 数据集支持不同粒度的方法的样本的生成(slice和function)。
- 为了满足code transformation的目的,程序必须可编译。
- 数据集应包含现实环境中的漏洞因为最终目标是检测现实环境中的软件漏洞,这和合成漏洞又会有所不同。
现有的数据集(VulDeepecker,SySeVR,Devign,Russell等)不能满足以上3个条件,所以作者从NVD和SARD重新创建了一个数据集。作者收集了2017年之前的报出的有漏洞的程序,并且在开源平台上的,还有它们的修复补丁(patches)。
对SARD,每个program有3种标注:good (not vulnerable), bad (vulnerable), mixed (vulnerable functions and their patched versions)。
作者收集了6803个program,每一个要么是vulnerable要么是patched。作者选取function level来作为ground truth,因为每一个vulnerability都能映射到一个function并且数据集中的每个function最多只有1个漏洞。6803个原始program包含6865个vulnerable function和10843个non-vulnerable function。经过code transformation之后得到50562个vulnerable function和80043个non-vulnerable function。
2.2.3.Attack Methods
为了证明攻击的可行性,作者利用了已有的code transformation工具进行修改,可用的有:
最终作者选取了Tigress,因为它提供了多种transformation方法并且不会有混淆的代码,下表展示了作者从Tigress选取的8个transformation方法,CT-1 … CT-8。
| 编号 | 名字 | 描述 |
|---|---|---|
| CT-1 | EncodeStrings | 将文本字符串(literal string)替换为生成这些字符串的函数调用 |
| CT-2 | RndArgs | 重新排列函数的参数甚至添加无用参数 |
| CT-3 | Flatten | 从function中移除一些control flow |
| CT-4 | MergeSimple | 在不进行control flow flattening的情况下将多个function合并到一个function中 |
| CT-5 | MergeFlatten | 在进行control flow flattening的情况下将多个function合并到一个function中 |
| CT-6 | SplitTop | 将top statement拆分成多个function |
| CT-7 | SplitBlock | 将一个基本块(basic block)拆分成多个function |
| CT-8 | SplitRecursive | 将一个基本块(basic block)拆分成多个function,并且将调用也拆分到function中 |
作者这里举了一个CT-6的例子。
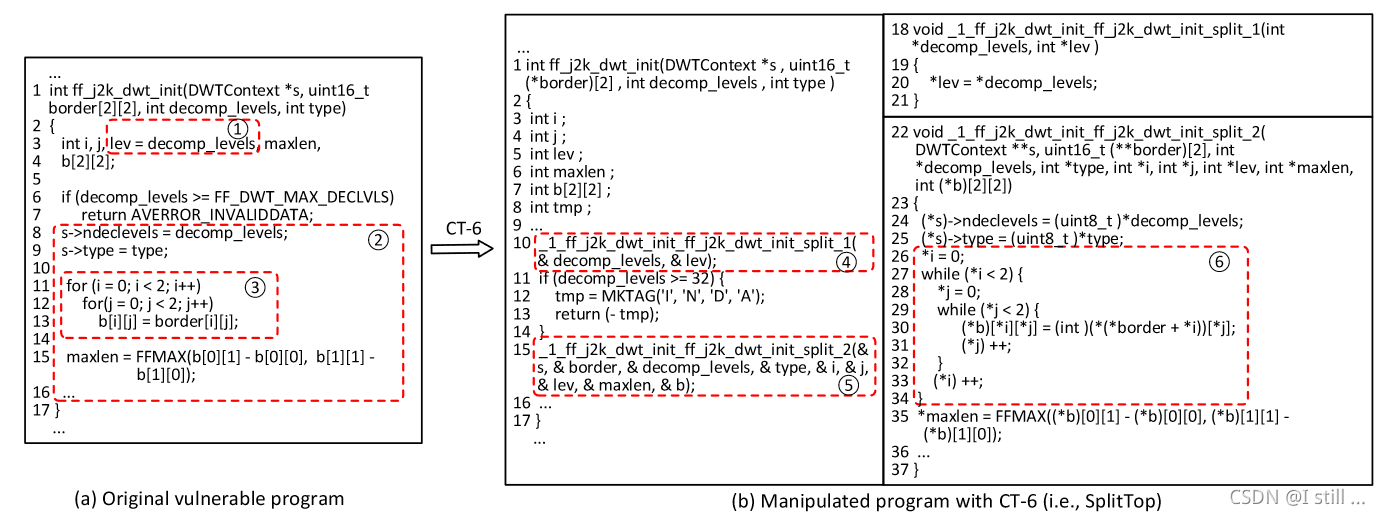
源代码第6行存在整数溢出漏洞(CVE-2012-0849),而CT-6将
ff_j2k_dwt_init拆分成了2个函数_1_ff_j2k_dwt_init_ff_j2k_dwt_init_split_1和_1_ff_j2k_dwt_init_ff_j2k_dwt_init_split_2。- 将
for循环替换成了while循环。 - 将数组替换成指针。
- 将宏定义替换成常量值。
2.2.4.Experimental Results
上面提到的3个code transformation要求
- Tigress本身就可以保存程序语义信息。
- 选出来的8个transformation方法不包括混淆。
- 作者通过手动检查确保漏洞保存下来。作者对原始代码的vulnerable line添加一个flag,并追踪变化后的代码。作者随机选取200个手动验证,花了105个小时。
这里提到了如下概念,有一部分在第三部分提到
| 概念 | 含义 |
|---|---|
| M M M | 所有能够满足语义保存的code transformation方法 |
| M A M_A MA | M A ⊆ M M_A \subseteq M MA⊆M 是攻击者可以获得的transformation方法 |
| M D , M D , i M_D,M_{D,i} MD,MD,i | M D ⊆ M M_D \subseteq M MD⊆M 是defender可以获得的transformation方法, M D , i ⊆ M D M_{D,i} \subseteq M_D MD,i⊆MD 是在特定实验中用到的方法 |
| P P P | P = { p 1 , . . . , p n } P = \{p_1,...,p_n\} P={p1,...,pn} 是一个training program的集合 |
| P + P^+ P+ | P + P^+ P+ 是通过 M D M_D MD 中的方法对 P P P 中的代码进行transformation得到的程序集合 |
| D D D | 从训练代码 P P P 集合中学到的模型 |
| D + D^+ D+ | ZigZag用到的模型,该模型从 P + P+ P+ 学到 |
| q , q + q,q^+ q,q+ | 程序 p p p 是有漏洞并且能被 D D D 检测出来的, q + q^+ q+ 是经过transformation不能被 D D D 检测出来的 |
| Q , Q + Q,Q^+ Q,Q+ | Q Q Q 是测试用例集合, Q + Q^+ Q+ 是 Q Q Q和其变换过的程序构成的集合 |
| P r ( D , q ) Pr(D,q) Pr(D,q) | 检测器 D D D 预测程序 p p p 有漏洞的概率 |
| X X X | X = { x 1 , . . . , x μ } X = \{x_1,...,x_\mu\} X={x1,...,xμ} 是 P P P 中所有程序样本的向量表示 |
| X ′ X^{'} X′ | X ′ = { x 1 ′ , . . . , x υ ′ } X^{'} = \{x^{'}_1,...,x^{'}_\upsilon\} X′={x1′,...,xυ′} 是 P + − P P^+ - P P+−P 中所有程序样本的向量表示 |
| X ′ ′ X^{''} X′′ | X ′ ′ = { x 1 ′ ′ , . . . , x γ ′ ′ } X^{''} = \{x^{''}_1,...,x^{''}_\gamma\} X′′={x1′′,...,xγ′′} 是 X ′ X^{'} X′ 中的FP和FN |
| F , F ∗ F,F^∗ F,F∗ | D + D^+ D+ 中用到的feature generator |
| C 1 , C 2 , C 1 ∗ , C 2 ∗ C_1,C_2,C^∗_1 ,C^∗_2 C1,C2,C1∗,C2∗ | D + D^+ D+ 中用到的分类器 |
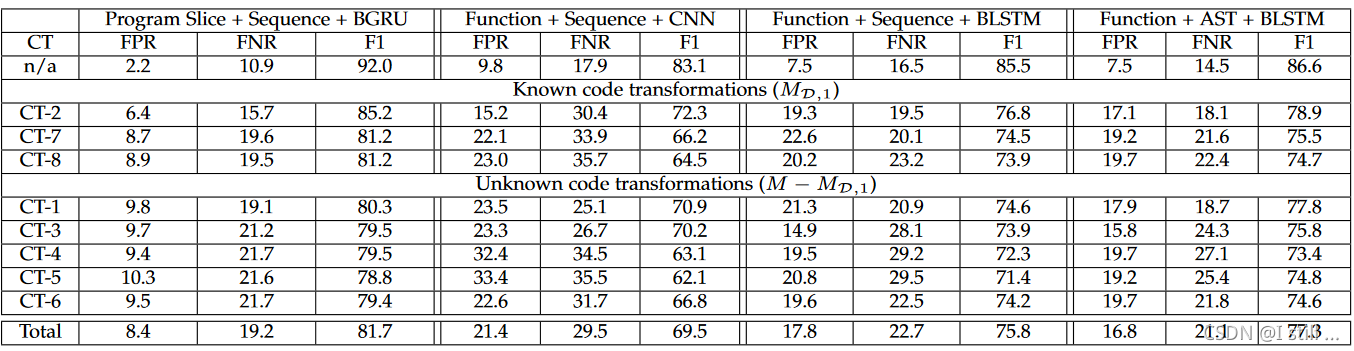
作者用FPR和FNR以及F1来衡量模型,结果如下
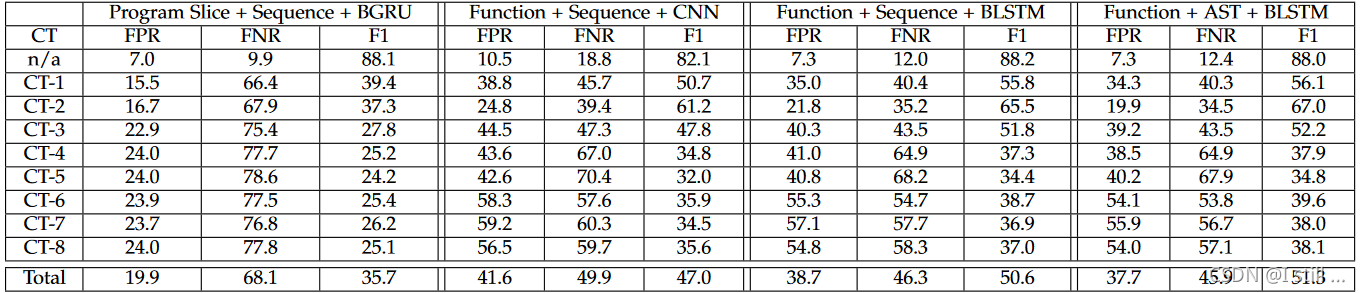 可以看到,经过transformation后,4种模型的FPR和FNR提高,而F1降低了。其中基于slice的方法FNR和F1的结果比function level的要更差。这表明slice在transformation后的代码里错失了很多漏洞语义。作者认为,由于slice粒度更细,会更加敏感。
可以看到,经过transformation后,4种模型的FPR和FNR提高,而F1降低了。其中基于slice的方法FNR和F1的结果比function level的要更差。这表明slice在transformation后的代码里错失了很多漏洞语义。作者认为,由于slice粒度更细,会更加敏感。
作者这里还总结了3个开源数据集中的检测逃逸情况,如下表(表太大了,所以只贴上一张表)
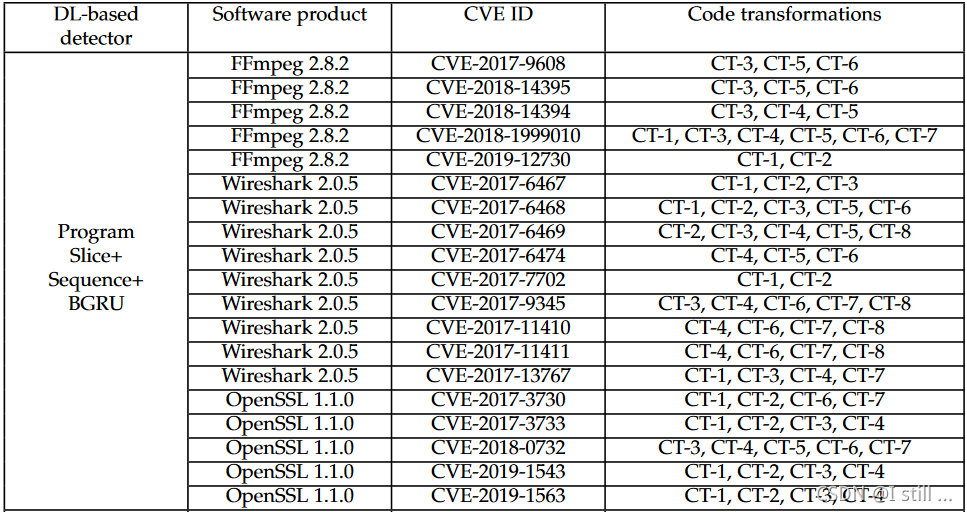
由此作者得出了一个结论,就是DL-based vulnerability detectors还不足够鲁棒。
三.ZigZag Framework
3.1.Characterizing DL-based Detectors
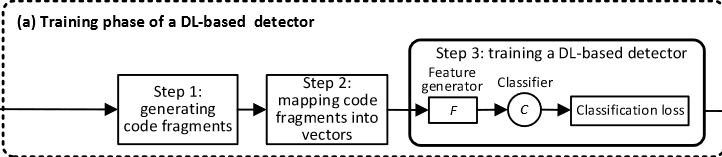
DL-based Detectors的训练阶段可用下图表述(截的子图)
测试阶段如下图所示

可以看到训练阶段和测试阶段的差异在最后一步
- Step 1: generating code fragments
这一步从训练程序中提取不同粒度的fragment单元(function或slice),并标注为vulnerable或者non-vulnerable。 - Step 2: mapping code fragments to vectors
这一步首先将上一步得到的code fragment根据不同的方法解析为一个程序表示(token sequence或者AST),然后将code fragment嵌入到向量中,获得code fragment的向量表示。 - Step 3: training a DL-based detector
用上一步得到的向量表示训练detector,主要是训练BGRU,BLSTM,CNN等神经网络。 - Step 4: detecting vulnerabilities
这一步就是根据step 2得到的程序向量,用神经网络判断该向量对应的code fragment是否包含漏洞。
3.2.System and Threat Model
这里考虑模型 D D D 为defender(应该是普通人)用训练数据 P P P 训练的模型。 M M M 是所有可行的code transformation方法, M A M_A MA 为攻击者可以接触的到的。攻击者可以将一个程序 q q q 通过 M A M_A MA 中的方法转换得到 q + q^+ q+。攻击者希望模型 D D D 针对 q q q 和 q + q^+ q+ 会给出不同的分类结果。而作者就是希望能够将 D D D 增强为 D + D^+ D+。以此针对 q q q 和 q + q^+ q+获取一致的分类结果。(不是概率,是分类值)
3.3.The ZigZag Framework
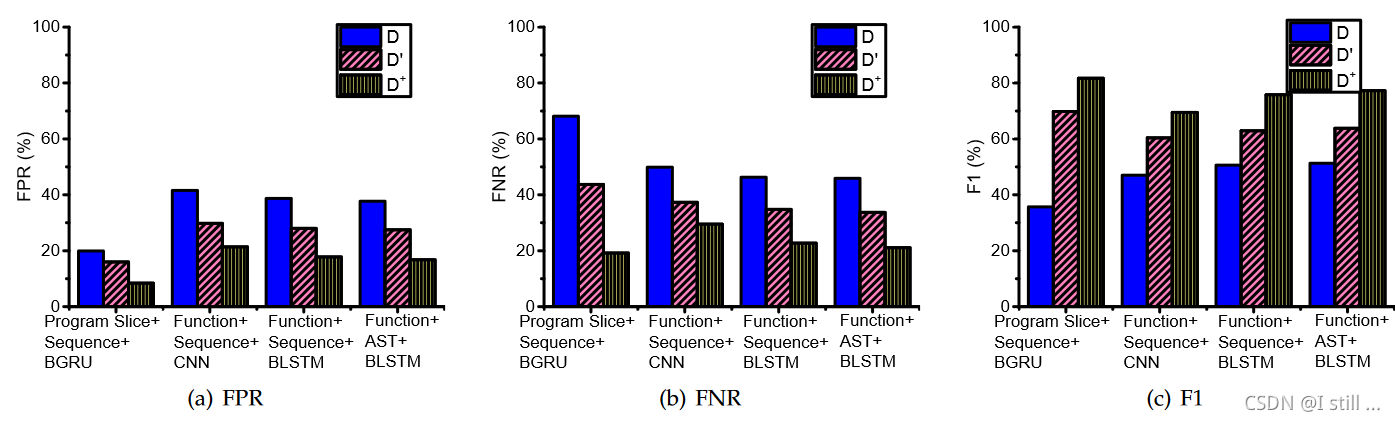
为了达到这个目标,直观上defender可以通过transformation将 P P P 扩展为 P + P^+ P+ 训练一个更鲁棒的模型 D ′ D^{'} D′,这是传统的对抗学习思路。但实际上,仅仅这么做是不够的(实验结果表明),这么做仅仅使得 P P P 和 P + − P P^+ - P P+−P 中的数据分布相似,如下图所示。
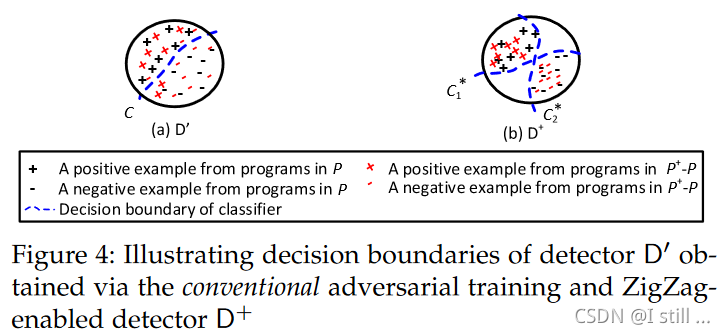
左边是传统对抗学习的结果,右边是ZigZag的结果。
整个框架如下图所示:
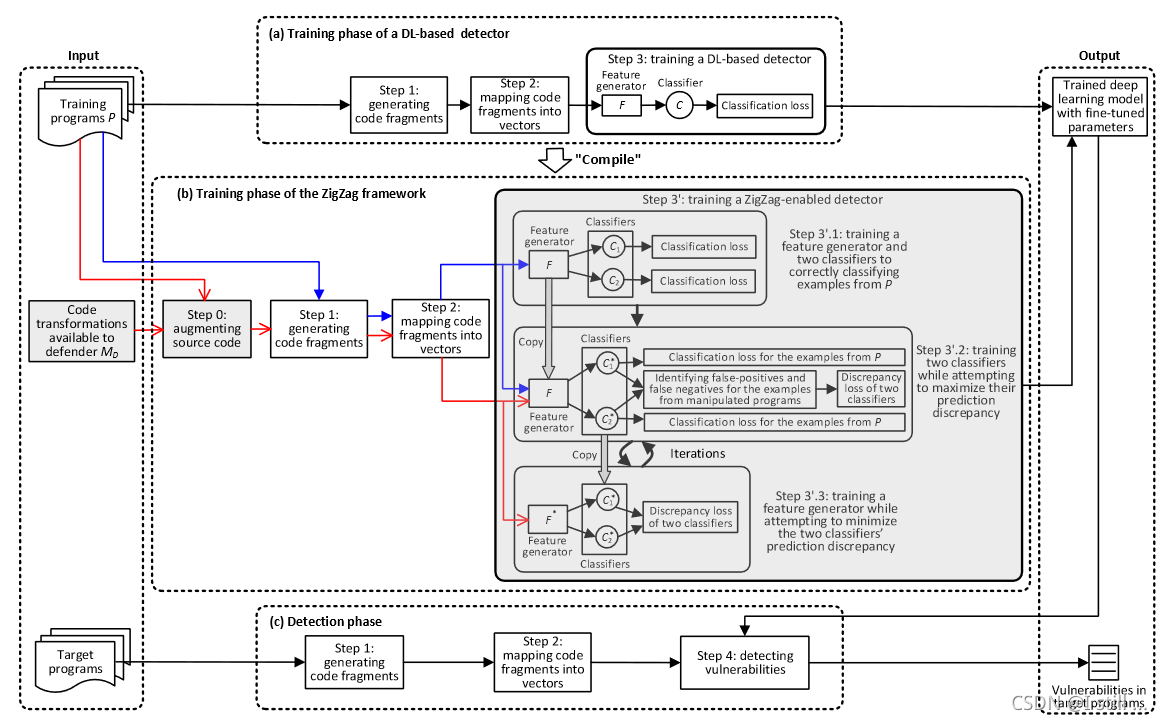 涂灰的部分都是ZigZag的部分。ZigZag可以看成是一个编辑器,将一个只拥有一个classifier的模型
D
D
D,编辑成一个拥有2个classifier的更加鲁棒的模型
D
+
D^+
D+。关键点在于对抗样本经常游荡在一个classifier的决策边界。ZigZag确保一个对抗样本必须欺骗2个classifier才算成功。
涂灰的部分都是ZigZag的部分。ZigZag可以看成是一个编辑器,将一个只拥有一个classifier的模型
D
D
D,编辑成一个拥有2个classifier的更加鲁棒的模型
D
+
D^+
D+。关键点在于对抗样本经常游荡在一个classifier的决策边界。ZigZag确保一个对抗样本必须欺骗2个classifier才算成功。
训练ZigZag包括2个步骤:
- feature learning:由于2个classifier使用不同的决策边界但是预测结果要保持一致,所以需要更好的特征向量表示,这一步意在优化之前的向量表示。即向量表示需要更鲁棒。
- classifier learning:这一步意在优化2个分类器使它们的决策边界相隔越远越好。ZigZag的2个classifier用 C 1 ∗ , C 2 ∗ C^∗_1 ,C^∗_2 C1∗,C2∗ 表示。
ZigZag的训练在图中b部分。这部分还有一个step 0。总体步骤如下:
3.3.1 Step 0-2
- Step 0: augmenting source code
这一部分意在生成增强数据集 P + P^+ P+。通过原始训练数据 P P P 和 P P P 经过 M D M_D MD 中的transformation生成的新数据组合而成。这意味着 P ⊂ P + P \subset P^+ P⊂P+。这一步也是在模仿攻击者生成其它样本的对抗学习套路。 - Step 1: generating code fragments
和正常训练模型 D D D 一样 - Step 2: mapping code fragments into vectors
和正常训练模型 D D D 一样
3.3.2 Step 3: training a ZigZag-enabled detector
ZigZag-enabled detector成为模型 D + D^+ D+。这里用 X X X 表示 P P P 中样本的向量表示, X ′ X^{'} X′ 表示 P + − P P^+ - P P+−P 中的样本的向量表示。这一步也分为3小步。
3.3.2.1 Step 3.1: 训练一个feature generator以及2个classifiers
这一步意在训练一个feature generator F F F 和2个classifier C 1 C_1 C1 和 C 2 C_2 C2,能够正确的分类所有 P P P 中的样本。用 c 1 ( x s , F ) c_1(x_s,F) c1(xs,F) 和 c 2 ( x s , F ) c_2(x_s,F) c2(xs,F) 表示, C 1 C_1 C1 和 C 2 C_2 C2 通过 F F F 对样例 x s x_s xs 预测的有漏洞的概率。 C C C 为模型 D D D 用到的classifier。这里 C , C 1 , C 2 C, C_1, C_2 C,C1,C2 除了初始化方式以外其它都相同。训练用到的loss如下
m i n F , C 1 , C 2 − ∑ l = 2 2 { E x s ∼ X [ y s . l o g ( c l ( x s , F ) ) + ( 1 − y s ) . l o g ( 1 − c l ( x s , F ) ) ] } \underset{F,C_1,C_2}{min} - \sum\limits^2_{l=2} \{ E_{x_s \sim X}[y_s.log(c_l(x_s,F)) + (1 - y_s).log(1 - c_l(x_s,F))]\} F,C1,C2min−l=2∑2{Exs∼X[ys.log(cl(xs,F))+(1−ys).log(1−cl(xs,F))]}
其实就是把2个classifier的交叉熵加在一起。在这一步之后, P P P 中的样例几乎全部都能被 C 1 C_1 C1 和 C 2 C_2 C2 正确分类。但是 P + − P P^+ - P P+−P 中的大部分都会被错误分类。
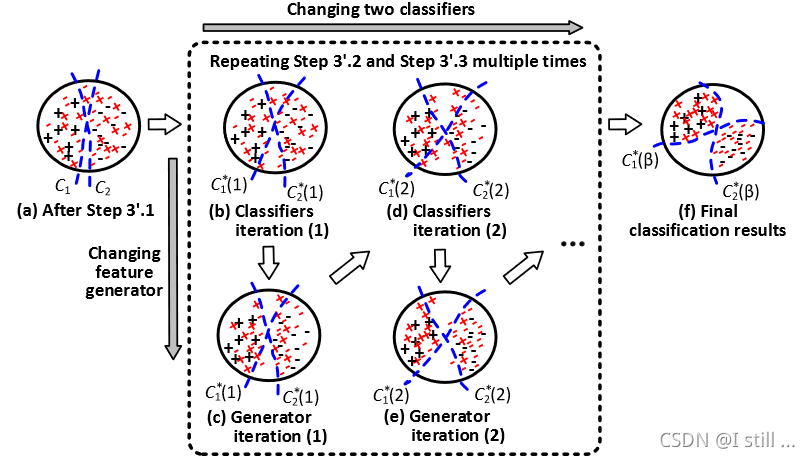
3.3.2.2 Step 3’.2: 训练2个classifier并最大化它们的预测差异
上一步获取的clasifier C 1 C_1 C1 和 C 2 C_2 C2 可能会相似,所以这一步意在训练classifier C 1 ∗ C^*_1 C1∗ 和 C 2 ∗ C^*_2 C2∗ 来最大化这2个classifier的预测差异。它们的模型初值是 C 1 C_1 C1 和 C 2 C_2 C2。
这里用 c 1 ∗ ( x s , F ) c^*_1(x_s,F) c1∗(xs,F) 和 c 2 ∗ ( x s , F ) c^*_2(x_s,F) c2∗(xs,F) 表示 C 1 ∗ C^∗_1 C1∗ 和 C 2 ∗ C^*_2 C2∗ 针对 x s x_s xs 预测的有漏洞的概率。在训练 C 1 ∗ C^*_1 C1∗ 和 C 2 ∗ C^*_2 C2∗ 时,loss由几个部分组成,这里依旧会用到上一步的交叉熵损失,针对 X X X 中的样例。
L c ( X ) = − ∑ l = 2 2 { E x s ∼ X [ y s . l o g ( c l ∗ ( x s , F ) ) + ( 1 − y s ) . l o g ( 1 − c l ∗ ( x s , F ) ) ] } L_c(X) = - \sum\limits^2_{l=2} \{ E_{x_s \sim X}[y_s.log(c^*_l(x_s,F)) + (1 - y_s).log(1 - c^*_l(x_s,F))]\} Lc(X)=−l=2∑2{Exs∼X[ys.log(cl∗(xs,F))+(1−ys).log(1−cl∗(xs,F))]}
在 X ′ X^{'} X′ 中,有一部分样本 C 1 ∗ C^*_1 C1∗ 或者 C 2 ∗ C^*_2 C2∗ 会产生错误预测,把这类样本称为hard example,记作 X ′ ′ X^{''} X′′。这里 X ′ ′ ⊆ X ′ X^{''} \subseteq X^{'} X′′⊆X′。hard example满足2个classifier中至少有一个错误分类,2个都错误分类也可以。这里用到了一个discrepency loss,记为:
L h ( X ′ ′ ) = E x d ′ ′ ∼ X ′ ′ [ ∣ c 1 ∗ ( x d ′ ′ , F ) − c 2 ∗ ( x d ′ ′ , F ) ∣ ] L_h(X^{''}) = E_{x_d^{''} \sim X^{''}}[|c^*_1(x^{''}_d,F) - c^*_2(x^{''}_d,F)|] Lh(X′′)=Exd′′∼X′′[∣c1∗(xd′′,F)−c2∗(xd′′,F)∣]
最终优化目标为
m
i
n
C
1
∗
,
C
2
∗
[
L
c
(
X
)
−
L
h
(
X
′
′
)
]
\underset{C^*_1,C^*_2}{min} [L_c(X) −L_h(X^{′′})]
C1∗,C2∗min[Lc(X)−Lh(X′′)]
这里可以看出
- feature generator F F F 这里不参与训练,作为常量。
- 用到的数据集包括 X X X 和 X ′ ′ X^{''} X′′,并不是 X ′ X^{'} X′ 所有的样本都参与了训练。
3.3.2.3 Step 3’.3: 训练一个feature generator并最小化2个classifier的预测差异
这里需要优化的目标即feature generator F F F。这里的目标就是得到 F ∗ F^* F∗ 能够最小化 C 1 ∗ C^*_1 C1∗ 和 C 2 ∗ C^*_2 C2∗ 的预测差异。 F ∗ F^* F∗ 的初值是第一步中得到的 F F F。这里使用全部 X ′ X^{'} X′ 中的数据来进行训练,损失函数如下:
m i n F ∗ E x w ′ ∼ X ′ [ ∣ c 1 ∗ ( x w ′ , F ) − c 2 ∗ ( x w ′ , F ) ∣ ] \underset{F^*}{min} E_{x_w^{'} \sim X^{'}} [|c^*_1(x^{'}_w,F) - c^*_2(x^{'}_w,F)|] F∗minExw′∼X′[∣c1∗(xw′,F)−c2∗(xw′,F)∣]
这里第2步和第3步是循环进行的。一个训练过程示意图如下:
四.Evaluation Of Zigzag-Enabled Robustness
作者提出了3个研究问题
- RQ1:Are ZigZag-enabled detectors robust against code transformations?也就是 D + D^+ D+ 是否足够鲁棒。
- RQ2:Does the robustness of ZigZag-enabled detectors depend on the defender’s choices of code transformations? D + D^+ D+ 的鲁棒性是否与用户对数据集 P P P 的transformation策略有关。
- RQ3:Are ZigZag-enabled detectors more effective than other widely-used vulnerability detectors? D + D^+ D+ 是否比其它广泛使用的漏洞检测模型更有效。
4.1.Robustness against Code Transformation Attacks (RQ1)
作者这里设置 M D , 1 M_{D,1} MD,1 = {CT-2,CT-7,CT-8}
训练超参数如下
| key | value |
|---|---|
| batch size | 64 |
| number of hidden layers | 2 |
| dimension of hidden vectors | 900 |
| dropout | 0.2 |
| output dimension | 512 |
| learning rate | 0.002 |
| number of iterations for step 2 and 3 | 8 |
| probability threshold δ \delta δ | 0.4 |
实验结果总结如下表。
比较
D
,
D
′
,
D
+
D,D^{'},D^+
D,D′,D+。
可以看到从
D
D
D 到
D
′
D^{'}
D′ 再到
D
+
D^+
D+,FPR和FNR逐级降低,F1逐级增大。因此可以得出结论:
D
+
D^+
D+ 确实足够鲁棒,比
D
′
D^{'}
D′ 更鲁棒。
4.2.Dependence on Defender’s Code Transformations (RQ2)
主要验证鲁棒性是否与transformation的选择策略有关,作者设置了6组 M D M_D MD。
- M D , 0 = ∅ M_{D,0} = \emptyset MD,0=∅
- M D , 1 = M_{D,1} = MD,1= {CT-2, CT-7, CT-8}
- M D , 2 = M_{D,2} = MD,2= {CT-3, CT-4, CT-6}
- M D , 3 = M_{D,3} = MD,3= {CT-2, CT-4, CT-5, CT-6}
- M D , 4 = M_{D,4} = MD,4= {CT-1, CT-2, CT-3, CT-4, CT-6, CT-7}
- M D , 5 = M M_{D,5} = M MD,5=M
这里作者只针对slice粒度的方法进行测试,结果如下:
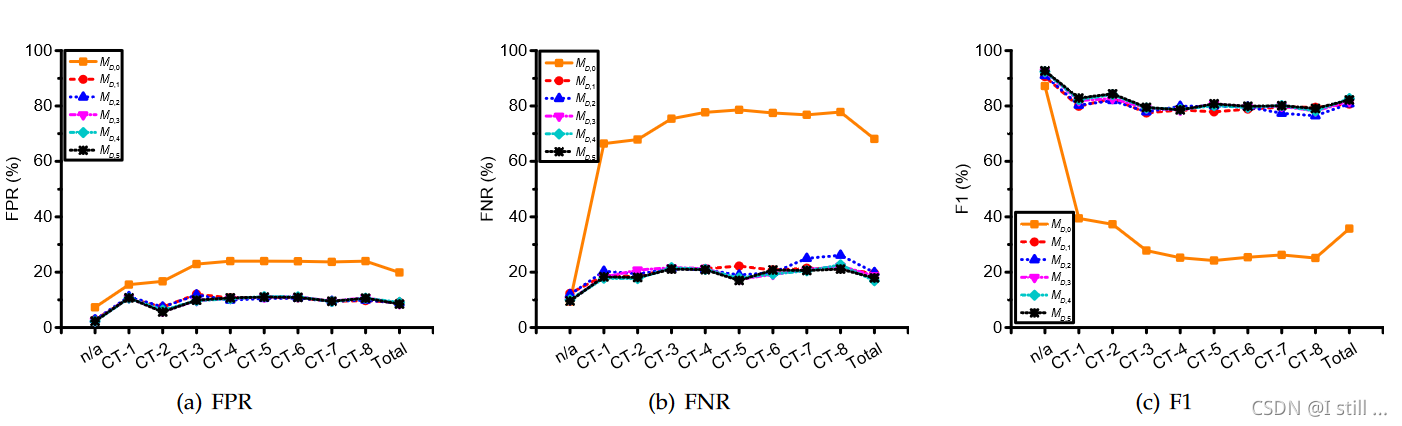
得出结论:引入code transformation策略确实有利于提高模型鲁棒性,有些策略甚至能够取得更好的有效性。
4.3.Comparison with Other Vulnerability Detectors (RQ3)
与其它的检测器对比,包括VUDDY,Flawfinder,Checkmarx,DL-based function-level detector,SySeVR 对比。作者这里使用的transformation策略是 M D , 1 M_{D,1} MD,1,使用的测试集是 Q + Q^+ Q+。
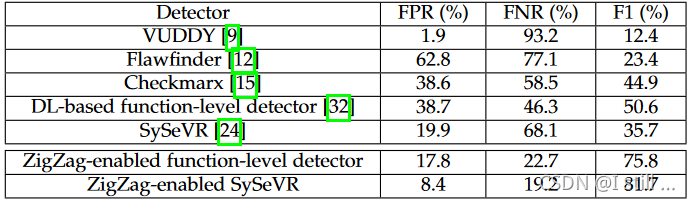
可以得出结论:
D
+
D^+
D+ 确实比其它广泛使用的漏洞检测模型更有效。
五.Limitations And Future Work
作者提到了一下不足:
- 只研究C语言,以后可以添加其它语言的支持
- 只考虑了Tigress中8种transformation策略,未来的研究需要考虑所有的transformation策略。
- 作者重新从sard和nvd上制作一个数据集,可能会引起external validity issue。
- 这里考虑的transformation范围都比较大,还没有考虑比较小的对样本的扰动。
- ZigZag用到了一对classifier,未来可以研究下是否可能使用更多的classifier。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









