









Fast and Accurate Pointer Analysis for Millions of Lines of Code
这篇blog主要讲的是上一篇提到的Lazy Cycle Detection算法和Hybrid Cycle Detection算法,因此并不是严格按照时间顺序来讲的。这篇文章中作者提出了Lazy Cycle Detection(简称LCD)和Hybrid Cycle Detection(简称HCD),用来优化原始Andersen算法,这篇文章中的Andersen算法依旧是 field-insensitive 的。
这里需要提到的是,Andersen算法的优化可分为在线优化(online)和离线优化(offline):
-
在约束求解过程中进行的优化为在线优化
-
在约束生成之后、约束求解之前进行的优化为离线优化
一.Introduction
Andersen指针分析算法的复杂度是
o
(
n
3
)
o(n^3)
o(n3)(
n
n
n 是约束图结点数),所以提高算法效率的关键在于减小
n
n
n。环路(强连通分量)检测是一个减小
n
n
n 的方法,约束图中,环路中的结点的 pts 集永远保持一致,因此可以将环路压缩为1个结点。因此环路检测算法对指针分析算法的性能有显著影响。
作者在这里分别提出了LCD和HCD算法来优化原始Andersen算法,减小计算环路的开销,不过这里并没有添加新的约束类型。
二.提出的算法
Andersen算法的约束:
| Constraint Type | Assignment | Constraint | Meaning |
|---|---|---|---|
| Base | a = &b | a ⊇ { b } a \supseteq \{b\} a⊇{b} | { b } ∈ p t s ( a ) \{b\} \in pts(a) {b}∈pts(a) |
| Simple | a = b | a ⊇ b a \supseteq b a⊇b | p t s ( a ) ⊇ p t s ( b ) pts(a) \supseteq pts(b) pts(a)⊇pts(b) |
| Complex | a = *b | a ⊇ ∗ b a \supseteq *b a⊇∗b | ∀ v ∈ p t s ( b ) , p t s ( a ) ⊇ p t s ( v ) \forall v \in pts(b), pts(a) \supseteq pts(v) ∀v∈pts(b),pts(a)⊇pts(v) |
| Complex | *a = b | ∗ a ⊇ b *a \supseteq b ∗a⊇b | ∀ v ∈ p t s ( a ) , p t s ( v ) ⊇ p t s ( b ) \forall v \in pts(a), pts(v) \supseteq pts(b) ∀v∈pts(a),pts(v)⊇pts(b) |
Andersen算法的伪代码
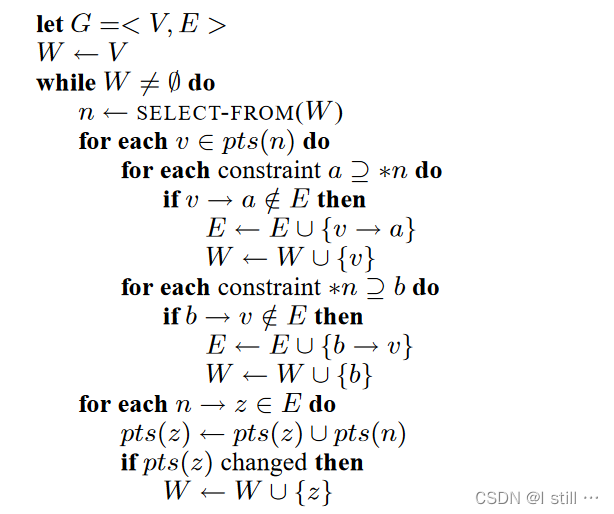 W
W
W 即
W
W
W 即 worklist。
2.1.LCD算法
LCD算法是一种在线优化方案,伪代码如下,红框标出了比原始Andersen算法多出的部分:
 约束图中的环路可以压缩,因为同一环路中的结点具有相同的
约束图中的环路可以压缩,因为同一环路中的结点具有相同的 pts 集。作者由此提出了一种启发式搜索方法:在进行Propagation(Copy 边处理)之前检查 Source 结点和 Destination 结点是否已经具有相同的 pts 集;如果是这样,那么它们可能在同一个环路上,因此使用深度优先搜索来检查可能的循环。
这种技术是惰性的,因为在环路形成时(即约束图插入形成该环路的最后一条边),算法不会尝试检测环路,而是等到一段propagation后环路效应变得显著才进行(相同 pts 集)。这种技术的优点是,只在可能找到环路时才尝试检测环路。一个潜在的缺点是,在环路形成后,才可能会很好地检测到环路,因为必须等待信息点在环路周围传播,然后才能检测到它。
LCD算法的准确性取决于这样的假设:即两个节点通常只有在同一个环路内才具有相同的 pts 集;否则,试图检测不存在的环路会浪费时间。
同时,这个算法还做了一个改进:从不在同一条边上触发两次环路检测( R R R 集合的作用)。因此,LCD算法避免了重复的环路检测。因此LCD算法不能保证在约束图中找到所有的环路。
2.2.HCD算法
HCD算法是一种离线优化方案,在进行Andersen分析之前,HCD会针对原始约束图创建一个offline副本,副本中的约束图不仅包含变量结点,每个变量结点还会配上一个 ref结点(比如变量 b 对应 ref 结点为 *b),并
-
针对约束 a ⊇ ∗ b a \supseteq *b a⊇∗b 产生
copy边 ∗ b → a *b \rightarrow a ∗b→a。 -
针对约束 ∗ a ⊇ b *a \supseteq b ∗a⊇b 产生
copy边 b → ∗ a b \rightarrow *a b→∗a。
在正式开始约束求解之前HCD算法会先处理offline副本。
举个例子针对如下示例:
a = &c;
d = c;
b = ∗a;
∗a = b;
其对应的约束图为(这里约束图只包含 copy 边,因此 a 先被忽视了):
 offline副本如下:
offline副本如下:
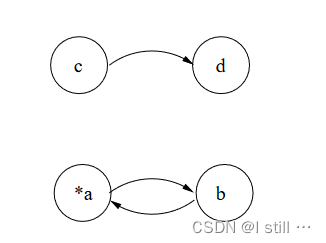
处理offline副本按如下方式进行:
-
首先用Tarjan算法计算强连通分量(环路)。对于副本中的环路,如果环路中只包含普通结点(上图
b, c, d),那么直接将环路压缩为1个结点。 -
如果环路包含了
ref结点(上图*a),算法定义了1个list L L L,对于该环路算法首先选取一个正常结点b(representative),并且对于环路中的每个ref结点*a,将二元组 ( a , b ) (a, b) (a,b) 添加进 L L L,该二元组表示a的pts集所有的变量应该跟b同环路。上图示例中 L = [ ( a , b ) ] L = [(a, b)] L=[(a,b)]
之后就是正式的AndersenHCD算法,伪代码如下(红框为相比原始Andersen算法多出的部分):
 可以看到红框部分中,如果
可以看到红框部分中,如果 *n 和 a 在同一环路中,那么 pts(n) 中所有变量(结点)都会压缩到 a 中。
不过HCD并不能保证在约束图中找到所有环路,只能从offline副本中推断出一些环路。但是它寻找环路是以一种不需要遍历图的方式进行的。除此之外,HCD可以与其它优化方式(LCD,PKH等)结合使用。
三.SVF中的实现
论文中的实验部分这里就不写了,主要是性能评测,这里主要看下SVF中的实现,SVF中Andersen算法继承关系如下:
3.1.AndersenLCD
3.1.1.主循环代码
由于代码太多,这里只看几个重要的函数,collapseFields, collapsePWCNode 与 field 有关暂时忽略:
大部分Andersen算法的分析过程为 analyze 函数,该函数主体由 initialize、initWorkList 和 solveWorkList 两个函数构成。
-
对于
initialize方法AndersenLCD继承自Andersen,该方法主要内容是processAllAddr,即初始化的时候处理a = &c;这类情况,将c添加进pts(a)。 -
对于
initWorkList方法AndersenLCD继承自WPASolver,主要是初始化workList,相当于算法中的 W ← V W \leftarrow V W←V。 -
同时
AndersenLCD的构造方法中包含了变量metEdges的初始化,该变量类型是EdgeSet(本质是Set<int>,保存的是EdgeID)。metEdges则相当于算法中的 R R R。 -
solveWorkList是循环主体部分。Andersen的solveWorkList继承自WPASolver,与AndersenLCD的 solveWorkList 不同点在于开头多了mergeSCC方法(这是算法中Detect-And-Collapse-Cycles的一部分),这里我暂时只关注processNode方法,该方法包含算法中循环所有主体内容。而AndersenLCD的processNode继承自Andersen,主要包含了handleLoadStore和handleCopyGep。handleLoadStore对应下图中红框内容,而handleCopyGep对应蓝框。LCD相对原始Andersen算法改进在蓝框内,因此AndersenLCD只重写了handleCopyGep方法。

Andersen 的handleCopyGep如下(Gep 与 field有关,暂时忽略):
void Andersen::handleCopyGep(ConstraintNode* node)
{
NodeID nodeId = node->getId();
computeDiffPts(nodeId);
if (!getDiffPts(nodeId).empty())
{
for (ConstraintEdge* edge : node->getCopyOutEdges())
processCopy(nodeId, edge);
for (ConstraintEdge* edge : node->getGepOutEdges())
{
if (GepCGEdge* gepEdge = SVFUtil::dyn_cast<GepCGEdge>(edge))
processGep(nodeId, gepEdge);
}
}
}
AndersenLCD 的handleCopyGep如下:
void AndersenLCD::handleCopyGep(ConstraintNode* node)
{
double propStart = stat->getClk();
NodeID nodeId = node->getId();
computeDiffPts(nodeId);
for (ConstraintEdge* edge : node->getCopyOutEdges())
{
NodeID dstNodeId = edge->getDstID();
const PointsTo& srcPts = getPts(nodeId);
const PointsTo& dstPts = getPts(dstNodeId);
// In one edge, if the pts of src node equals to that of dst node, and the edge
// is never met, push it into 'metEdges' and push the dst node into 'lcdCandidates'
if (!srcPts.empty() && srcPts == dstPts && !isMetEdge(edge))
{
addMetEdge(edge);
addLCDCandidate((edge)->getDstID());
}
processCopy(nodeId, edge);
}
for (ConstraintEdge* edge : node->getGepOutEdges())
{
if (GepCGEdge* gepEdge = SVFUtil::dyn_cast<GepCGEdge>(edge))
processGep(nodeId, gepEdge);
}
double propEnd = stat->getClk();
timeOfProcessCopyGep += (propEnd - propStart) / TIMEINTERVAL;
}
AndersenLCD 和 Andersen 的主要区别在于在 processCopy 前添加了如下代码:
NodeID dstNodeId = edge->getDstID();
const PointsTo& srcPts = getPts(nodeId);
const PointsTo& dstPts = getPts(dstNodeId);
// In one edge, if the pts of src node equals to that of dst node, and the edge
// is never met, push it into 'metEdges' and push the dst node into 'lcdCandidates'
if (!srcPts.empty() && srcPts == dstPts && !isMetEdge(edge))
{
addMetEdge(edge);
addLCDCandidate((edge)->getDstID());
}
相当于下面这段伪代码:
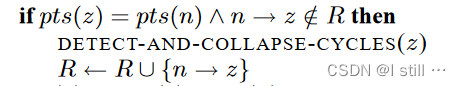
3.1.2.压缩环路
-
addMetEdge对应 R ← R ∪ { n → z } R \leftarrow R \; \cup \; \{n \rightarrow z\} R←R∪{n→z} -
addLCDCandidate和前面提到的mergeSCC对应Detect-And-Collapse-Cycles
addMetEdge 和 isMetEdge 的内容分别如下(基础 Set<int> 操作):
// 'metEdges' is used to collect edges met by AndersenLCD, to avoid redundant visit
//@{
bool isMetEdge (ConstraintEdge* edge) const
{
EdgeSet::const_iterator it = metEdges.find(edge->getEdgeID());
return it != metEdges.end();
};
void addMetEdge(ConstraintEdge* edge)
{
metEdges.insert(edge->getEdgeID());
};
addLCDCandidate 相关代码如下:
NodeSet lcdCandidates;
inline bool hasLCDCandidate () const
{
return !lcdCandidates.empty();
};
inline void cleanLCDCandidate()
{
lcdCandidates.clear();
};
inline void addLCDCandidate(NodeID nodeId)
{
lcdCandidates.insert(nodeId);
};
lcdCandidates 本质上是 Set<int> 类变量,相当于一个node stack,用来辅助压缩结点。真正负责检测和压缩的是 mergeSCC 方法。mergeSCC代码如下(mergeSCC 的主要目标是检测压缩与 lcdCandidate 中所有结点相关的环):
void AndersenLCD::mergeSCC()
{
if (hasLCDCandidate())
{
SCCDetect();
cleanLCDCandidate();
}
}
主要功能由SCCDetect执行:
NodeStack& AndersenLCD::SCCDetect()
{
numOfSCCDetection++;
NodeSet sccCandidates;
sccCandidates.clear();
for (NodeSet::iterator it = lcdCandidates.begin(); it != lcdCandidates.end(); ++it)
if (sccRepNode(*it) == *it)
sccCandidates.insert(*it);
double sccStart = stat->getClk();
/// Detect SCC cycles
getSCCDetector()->find(sccCandidates);
double sccEnd = stat->getClk();
timeOfSCCDetection += (sccEnd - sccStart) / TIMEINTERVAL;
double mergeStart = stat->getClk();
/// Merge SCC cycles
mergeSccCycle();
double mergeEnd = stat->getClk();
timeOfSCCMerges += (mergeEnd - mergeStart) / TIMEINTERVAL;
return getSCCDetector()->topoNodeStack();
}
代码将 lcdCandidates 中可能出现在环路中的结点( representative/sccRepNode 不是自己的结点)添加到 sccCandidates 集合中。并调用 getSCCDetector()->find 查找环路,再调用 mergeSccCycle 压缩环路。查找环路参考SCC,算法是文献
[
2
]
^{[2]}
[2] 中的升级版Tarjan算法。
mergeSccCycle 参考Andersen::mergeSccCycle,主要功能是按照拓扑序一个个将约束图中每个 rep 结点和对应环路中的其它结点进行合并,主要是合并 pts 集,底层功能由 mergeSrcToTgt 方法实现。
这里AndersenLCD改写了mergeSrcToTgt方法,与父类Andersen的mergeSrcToTgt方法对比可以发现,在 unionPts(newRepId,nodeId); 之后多了一句 pushIntoWorklist(newRepId);(这里我还没有摸清为什么只有 AndersenLCD 需要添加进 Worklist)。
3.1.3.总结
这里我没有太关注与field相关的函数,主要关注循环主体和环路检测部分。可以看到在SVF实现中,AndersenLCD 底层调用升级版Tarjan算法
[
2
]
^{[2]}
[2] 检测与上图红框
z
z
z 有关的环路并压缩。对于SVF中的其它细节,以后再仔细琢磨。
3.2.AndersenHCD
SVF中Andersen算法大致流程是:构造函数 -> initialize -> initWorklist -> solveWorklist(后面3个包括在 analyze 函数中)
AndersenHCD 的构造函数中多了一个OfflineConsG类型的变量,即offline副本。
3.2.1.生成offline副本
其initialize方法如下:
void AndersenHCD::initialize()
{
Andersen::initialize();
// Build offline constraint graph and solve its constraints
oCG = new OfflineConsG(pag);
OSCC* oscc = new OSCC(oCG);
oscc->find();
oCG->solveOfflineSCC(oscc);
delete oscc;
}
OfflineConsG为offline副本对应的类型,其中:
-
OfflineConsG中普通结点的NodeID和原约束图中的NodeID保持一致。 -
成员变量
refNodes保存offline副本中所有用到的ref结点。 -
成员变量
nodeToRefMap将普通结点的NodeID映射到对应ref结点的NodeID。 -
成员变量
norToRepMap相当于论文HCD算法中的 L L L,norToRepMap[a] = b表示*a与b在同一环路上。
创建offline副本用到了buildOfflineCG方法:
void OfflineConsG::buildOfflineCG()
{
LoadEdges loads;
StoreEdges stores;
// Add a copy edge between the ref node of src node and dst node
for (ConstraintEdge::ConstraintEdgeSetTy::iterator it = LoadCGEdgeSet.begin(), eit =
LoadCGEdgeSet.end(); it != eit; ++it)
{
LoadCGEdge *load = SVFUtil::dyn_cast<LoadCGEdge>(*it);
loads.insert(load);
NodeID src = load->getSrcID();
NodeID dst = load->getDstID();
addRefLoadEdge(src, dst);
}
// Add a copy edge between src node and the ref node of dst node
for (ConstraintEdge::ConstraintEdgeSetTy::iterator it = StoreCGEdgeSet.begin(), eit =
StoreCGEdgeSet.end(); it != eit; ++it)
{
StoreCGEdge *store = SVFUtil::dyn_cast<StoreCGEdge>(*it);
stores.insert(store);
NodeID src = store->getSrcID();
NodeID dst = store->getDstID();
addRefStoreEdge(src, dst);
}
// Dump offline graph with all edges
dump("oCG_initial");
// Remove load and store edges in offline constraint graph
for (LoadEdges::iterator it = loads.begin(), eit = loads.end(); it != eit; ++it)
{
removeLoadEdge(*it);
}
for (StoreEdges::iterator it = stores.begin(), eit = stores.end(); it != eit; ++it)
{
removeStoreEdge(*it);
}
// Dump offline graph with removed load and store edges
dump("oCG_final");
}
addRefLoadEdge和addRefStoreEdge的代码如下:
bool OfflineConsG::addRefLoadEdge(NodeID src, NodeID dst)
{
createRefNode(src);
NodeID ref = nodeToRefMap[src];
return addCopyCGEdge(ref, dst);
}
bool OfflineConsG::addRefStoreEdge(NodeID src, NodeID dst)
{
createRefNode(dst);
NodeID ref = nodeToRefMap[dst];
return addCopyCGEdge(src, ref);
}
createRefNode代码如下:
bool OfflineConsG::createRefNode(NodeID nodeId)
{
if (hasRef(nodeId))
return false;
NodeID refId = pag->addDummyValNode();
ConstraintNode* node = new ConstraintNode(refId);
addConstraintNode(node, refId);
refNodes.insert(refId);
nodeToRefMap[nodeId] = refId;
return true;
}
3.2.2.计算list L L L
计算环路依旧是用到文献
[
2
]
^{[2]}
[2] 中的算法,之后 oCG->solveOfflineSCC(oscc); 会调用OfflineConsG::buildOfflineMap方法。
/*!
* Build offline node to rep map, which only collect nodes having a ref node
*/
void OfflineConsG::buildOfflineMap(OSCC* oscc)
{
for (NodeToRepMap::const_iterator it = nodeToRefMap.begin(); it != nodeToRefMap.end(); ++it)
{
NodeID node = it->first;
NodeID ref = getRef(node);
NodeID rep = solveRep(oscc,oscc->repNode(ref));
if (!isaRef(rep) && !isaRef(node))
setNorRep(node, rep);
}
}
每个 ref 结点最多出现在1个环路上,对于如下示例:
*a = b;
b = c;
c = *a;
*a(ref)、b、c 会在同一个环路上,在 buildOfflineMap 函数中当 node 值为 a 时,ref 值为 *a,solveRep返回 ref 所在环路的 rep 结点。当环路 rep 结点为 ref 结点时,solveRep 会将该环路的 ref 设置为另一个普通结点并返回,否则直接返回。比如上面示例中当环路 rep 为 *a 时,solveRep 会将 rep 设置为 b 并返回 b。
在调用完父类 initialize 之后创建offline副本并查找之上的强连通分量。
3.2.3.主循环代码
主循环代码如下:
void AndersenHCD::solveWorklist()
{
while (!isWorklistEmpty())
{
NodeID nodeId = popFromWorklist();
collapsePWCNode(nodeId);
//Merge detected offline SCC cycles
mergeSCC(nodeId);
// Keep solving until workList is empty.
processNode(nodeId);
collapseFields();
}
}
除了中间的 mergeSCC 其它均与父类 solveWorkList 保持一致,processNode 也继承于父类,这里重点关注mergeSCC(推测 mergeSCC 对应上图中红框部分),其代码如下:
void AndersenHCD::mergeSCC(NodeID nodeId)
{
if (hasOfflineRep(nodeId))
{
// get offline rep node
NodeID oRep = getOfflineRep(nodeId);
// get online rep node
NodeID rep = consCG->sccRepNode(oRep);
const PointsTo &pts = getPts(nodeId);
for (PointsTo::iterator ptIt = pts.begin(), ptEit = pts.end(); ptIt != ptEit; ++ptIt)
{
NodeID tgt = *ptIt;
ConstraintNode* tgtNode = consCG->getConstraintNode(tgt);
if (!tgtNode->getDirectInEdges().empty())
continue;
if (tgtNode->getAddrOutEdges().size() > 1)
continue;
assert(!oCG->isaRef(tgt) && "Point-to target should not be a ref node!");
mergeNodeAndPts(tgt, rep);
}
}
}
这段代码和上图算法的对应关系为:
-
nodeId对应 n n n。 -
rep对应 a a a(oRep为中间变量)。 -
mergeNodeAndPts(tgt, rep);对应 c o l l a p s e ( v , a ) collapse(v, a) collapse(v,a) 和 W ← W ∪ { a } W \leftarrow W \cup \{a\} W←W∪{a}
mergeNodeAndPts代码如下:
void AndersenHCD::mergeNodeAndPts(NodeID node, NodeID rep)
{
node = sccRepNode(node);
rep = sccRepNode(rep);
if (!isaMergedNode(node))
{
if (unionPts(rep, node))
pushIntoWorklist(rep);
// Once a 'Node' is merged to its rep, it is collapsed,
// only its 'NodeID' remaining in the set 'subNodes' of its rep node.
mergeNodeToRep(node, rep);
setMergedNode(node);
}
}
c
o
l
l
a
p
s
e
(
v
,
a
)
collapse(v, a)
collapse(v,a) 主要由 mergeNodeToRep(node, rep); 完成,即合并 node 和 rep(包括 pts 集的合并)。setMergedNode是将 node 添加到集合 mergedNodes 避免重复访问。
四.总结
这篇blog我主要研究另一种Andersen算法的优化方式并分析SVF中的实现方式,跟上一篇WaveDiff优化一样,HCD和LCD默认都是field-insensitive的,因此不便于用来直接分析有结构体变量的程序。
这里对于SVF我也只是简单分析了下API的功能,SVF的底层设计以后再研究。
五.参考文献
[1].Hardekopf B , Lin C . The ant and the grasshopper: Fast and accurate pointer analysis for millions of lines of code[C]// Proceedings of the ACM SIGPLAN 2007 Conference on Programming Language Design and Implementation, San Diego, California, USA, June 10-13, 2007. ACM, 2007.
[2] Nuutila E , Soisalon-Soininen E . On finding the strongly connected components in a directed graph[J]. Information Processing Letters, 1994, 49(1):9-14.















 4002
4002











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









