










Ferry: State-Aware Symbolic Execution for Exploring State-Dependent Program Paths
1.引言
现有的符号执行方法和工具在程序实现的有限状态机模型中探索程序状态相关分支的能力非常有限。图1示例代码实现了一个状态机来解析视频输入。

现有技术的方法可以有效地探索第
6
6
6 行的分支,因为 box_type 的值在每轮循环都会重新从输入无条件加载。
然而,为了便于实现带状态的程序逻辑,真实世界的程序使用某些变量来存储程序的内部状态,条件语句可能依赖于内部状态而不是当前的程序输入。比如第
9
9
9 行条件取决于变量 saved_size 的值。
-
假如第一次循环进入了
encode("tx3g")分支,那么此时saved_size并没有被重新赋值,为 − 1 -1 −1。 -
对
saved_size的赋值在encode("trak")分支中,即encode("trak")分支的执行对encode("tx3g")。
因此,作者将 saved_size 这种变量称之为state-describing variable(状态描述变量)。对于条件语句保护的分支,如果条件语句依赖于这些state-describing variable,那么这些分支称为state-dependent branches(状态依赖分支)。
示例第
16
16
16 和
18
18
18 行可能分别触发整数溢出和缓冲区溢出漏洞。在默认情况(saved_size = -1)下漏洞并不会被触发。而在示例输入中:
-
示例输入序列由2个输入组成,每轮循环处理1个输入,每个输入在概念上都是一个data box。每个data box包含必要的元数据
box_size和box_type,分别描述其大小和类型,同时data box还包含可选的有效负载数据(负载在示例中没有提到)。 -
该程序实现了一个循环,在循环的不同迭代过程中,data box被依次处理。
-
第1轮循环对应
box_type为trak,box_size为8,那么saved_size被设置为8。 -
第2轮循环对应
box_type为tx3g,box_size为0xFFFFFFF8,此时saved_size为正数,size被设置为8。第 16 16 16 行size + box_size的值超过32位整数上限,发生溢出。
-
这种状态感知的程序逻辑打破了SOTA方法的假设。即程序独立地处理来自单个文件的输入的每个部分,并且可以忽略早期输入导致的状态变化对后期输入处理方式的影响。但是许多真实环境程序都包括了状态依赖分支,下表列出的程序包含数十甚至数百个状态依赖分支。

状态依赖分支会从2个方面降低路径搜索的效率:
-
由于缺乏对内部程序状态的了解,现有的方法无法生成探索大量程序状态的所需程序输入,导致对状态依赖分支的探索非常有限。
-
一个程序语句在不同的程序状态下可以有不同的行为(例如,在示例中,第16行默认情况下是不会触发溢出的,只有在程序状态发生变化时才会暴露漏洞),这意味着仅仅访问1次状态依赖分支是不够的。相反,应该在不同的程序状态下对它们进行全面检查。这就需要一种新的衡量标准来评估现有工具的状态探测能力。
为了解决上述问题,作者提出了状态感知(state-aware,我也不知道aware怎么翻译比较好)的符号执行框架ferry,ferry会自动识别状态描述变量,并使用它们引导符号执行和探索状态依赖分支。同时,作者根据ferry在测试真实环境程序遇到的困难提出了数种策略优化ferry以提高其效率和可扩展性。
2.问题陈述与分析
符号执行引擎的一个主要障碍是不了解程序的内部状态,这会导致对状态依赖分支的低效探索。对于图1中的示例,在忽略被注释的其它分支的情况下每轮循环存在3个不同的路径:
-
case encode("tx3g")+saved_size < 0 -
case encode("tx3g")+saved_size >= 0 -
case encode("trak")
但是对于符号执行,该示例可能有无限数量的符号状态,比如循环次数小于 m 的符号状态数最多包括
3
∗
(
1
+
.
.
.
+
m
)
3 * (1 + ... + m)
3∗(1+...+m)。其中就包括了循环 m 次每次都走 case encode("tx3g") 这个分支,那么 saved_size 一直没被重新赋值,这样的状态显然是无意义的且应该被修剪掉。
示例展示了一个简单的情况,真实环境中一个程序可能包含上千个状态依赖分支,且可能更复杂有嵌套情况。
2.1.实现状态感知符号执行的挑战
-
挑战1,程序状态推理:最关键的问题是如何推断给定程序的内部状态,不同于操作系统的状态,这些状态有充分的文档记录。通常情况下,应用程序的状态与它的实现有关,并且没有明确的规约。由于程序通常使用特定变量(即状态描述变量)跟踪其状态,通过识别状态描述变量可以推断程序状态。不幸的是,由于状态描述变量和无关变量之间的语义或结构差异很小,因此识别这些变量本身就是一个挑战。
-
挑战2,运行时程序状态识别:就算识别出程序中的状态描述变量,也很难确定当前状态是否被探索过(推测是指当前状态是否重复)。
2.2.真实程序的特征
作者对具有状态依赖分支的真实程序进行了调查,以了解其特征。具体来说,作者手动分析了AFL分析过的106个程序。结果显示91个有至少1个状态依赖分支。包含状态相关分支的程序被广泛用作软件系统的各个方面的基本组件,从网络数据传输到多媒体数据处理。更重要的是,它们中的许多是大型项目和系统的基石。例如,Chromium项目由几个具有状态依赖分支的库提供支持,包括libpng和libtiff。它们的特征被总结如下:
-
C1:它们从单个输入源接收一系列输入,输入源可以是1个
socket或者1个文件。 -
C2:它们按顺序依次处理输入。这些程序不是一次处理整个输入序列,而是一次处理一个输入(在输入序列中)。图1是一个典型的示例,它包含一个输入处理循环,用于从文件中连续读取数据。在循环的当前迭代中处理的输入被称为当前输入(
current input),而在先前迭代中处理过的输入被称作早期输入(early input)。 -
C3:它们用一个或多个状态描述变量来维护程序状态。当状态描述变量的值与这些输入之间存在数据依赖时,程序状态会受到一些早期输入的影响。这些变量通过影响某些条件语句的分支来进一步改变程序行为。
作者没有试图有效地分析任何具有内部状态的程序,而是在本文中将目标程序的范围明确定义为具有上述三个特征的真实世界程序。
本文解决的问题就是对于具有上述特征的程序,如何解决第2.1节中的挑战,以便有效地探索依赖于状态的分支,如图1所示的分支?
2.3.Ferry的模型
2.3.1.程序状态的定义
程序中的状态可以由下列特征描述:
-
状态由一组状态描述变量描述。
-
当两个状态不同时,至少一个状态描述变量具有不同的值。
-
程序在不同状态下具有不同的行为(即采取不同的分支方向)。
自动识别状态描述变量是一项具有挑战性的任务。作者应对这一挑战的解决方案基于分析程序的特性:如第2.2节所述,每个程序都有一个外部数据源,它以这样的方式决定程序的执行,即早期输入可以影响某些状态描述变量的值,其进一步确定在处理当前输入时对某些条件语句采取的分支。
在执行期间,程序状态在处理输入序列期间发生变化。在本文中,作者将相关的状态变化事件分为三类:
-
一个新的状态描述变量被初始化。
-
某个状态描述变量的值被更改,这意味着它被分配了不同的值或其符号表达式的数据约束被更改。
-
一个状态描述变量被释放。
具体来说,输入序列对运行时程序状态的影响可以通过以下定义来具体指明:
-
首先,作者将把输入序列的一部分加载到存储单元的指令定义为输入加载指令(input loading instruction,图1中的
read_box_size()和read_box_type()就是这样的指令)。 -
其次,作者将初始化、释放或修改状态描述变量的值或数据约束的指令称为状态描述变量操作(state-describing variable operation,SDVO)指令。根据定义,执行SDVO指令肯定会导致状态转换。这里的修改并不局限于赋值操作,状态描述变量的约束条件变了也算修改。
-
第三,作者定义SDVO指令和输入加载指令之间的数据依赖关系如下:每当状态描述与输入加载指令间存在数据依赖关系时,作者称对应的SDVO指令数据依赖于输入加载指令。实现上,作者通过动态污点跟踪来捕获这种依赖关系。
被分析程序的一个内在特征是SDVO指令和输入加载指令之间广泛存在数据依赖性。Ferry利用这一特性来识别状态描述变量。
2.3.2.状态描述变量的特征
状态描述变量具有以下两个特征:
-
状态描述变量显式/隐式数据依赖于输入。
-
至少在一个条件分支语句中检查状态描述变量。
尽管作者的方法直接利用了第2.2节中确定的三个特征,但这项技术可能适用于具有上述特征的所有程序,这意味着:
-
对于基本状态描述变量的子集,其SDVO指令是数据依赖于至少一个输入加载指令。
-
如果状态描述变量的内容不同(即值不同),程序可能采取不同的分支来进行不同的行为。
3.Design
3.1.Overview of Ferry
框架整体概览如图2所示:
-
首先,基于状态描述变量和程序输入之间存在数据依赖性的insight,Ferry监控给定程序的执行,并识别状态描述变量。
-
其次,Ferry识别运行时程序状态,并驱动符号执行来探索大量程序状态。
-
此外,作者观察到真实世界程序的复杂性会影响Ferry的有效性。基于这一insight,作者的第三步通过引入两个优化进一步提高Ferry效率:缩减拥有闲置状态描述变量的状态(state-reduction of inactive state-describing variables)和快捷符号执行(shortcut symbolic execution)。

3.2.状态描述变量识别
在第2.3节中,作者确定了状态描述变量的两个特征,即它们数据依赖于输入(这个特征在以下段落中记为 InputDetermined),并且它们在至少在一个条件语句(这个特征记为 BranchRelated )中被检查,具有这些特征的变量是状态描述变量。
值得注意的是,变量的这些特征是全局的(不同状态共享),这意味着如果一个变量在一个执行路径中标记为 InputDetermined,而在另一个执行路径中标记为 BranchRelated,那么可以将其标记为状态描述变量。
状态描述变量的识别过程如下:
-
首先,作者应用动态污点分析从外部输入源来追踪
InputDetermined变量。目标是找到依赖于输入序列的状态描述变量。-
作者将所有输入变量(在本例中,来自视频文件,例如
box_size和box_type)标记为Tainted,并跟踪它们在程序中的传播。与传统污点分析相比,作者的方法跟踪符号输入而不是具体输入的传播。具体来说,作者将污点信息记录为符号输入上的特定类型的数据约束,因此污点标记会随着符号执行的进行而自然传播,不会引入额外的开销。 -
如果一个变量接收到一个被污染的符号表达式,它将被标记为
InputDetermined。在给定的示例中,box_size、box_type和saved_size为InputDetermined。 -
除了显式的数据依赖性之外,图3中描述的控制依赖也可以帮助识别状态描述变量。然而,动态污点分析通常不包括控制依赖。事实上,考虑到这种依赖性是一把双刃剑。尽管它扩大了覆盖范围,但许多不相关的变量(误报)可能会被错误地引入。因此,作者的分析只考虑了一阶控制依赖性,也就是说,一个变量
a控制依赖于变量b,而变量b数据依赖于输入,那么a会被标注为Tainted。比如在图3中,state_var会被标注为污点,因为其直接控制依赖于输入,而tmp_var不会,因为其控制依赖于state_var,而state_var并不数据依赖于输入。
-

-
其次,如2.3所示,程序在不同状态下采取不同的分支方向。因此,对于程序中的每个条件语句,作者在检查相应条件时记录它访问的所有变量,并用
BranchRelated标记它们。如果在条件语句中使用InputDetermined变量,这意味着它也是BranchRelated,作者将其标记为状态描述变量。在图1中,saved_size在第 9 9 9 行条件语句被访问,而且又数据依赖于输入,因此它属于状态描述变量。 -
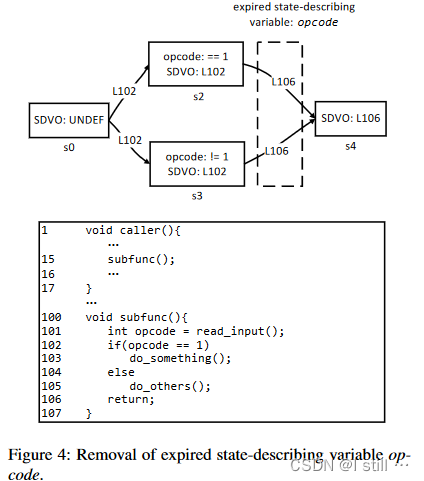
最后一步就是识别无效状态描述变量。变量具有活动持续时间,当状态描述变量被释放时会发生状态转换。比如在图4中,
opcode是状态描述变量。如果它是堆栈上的局部变量,那么一旦函数返回,函数的局部堆栈就会失效。为了避免错误地识别具有此类过期变量的程序状态,Ferry引入了两种优化:-
如果释放的对象包含状态描述变量,则对
free函数的调用被视为SDVO指令。 -
函数调用返回后,作者检查状态描述变量,并丢弃返回函数的栈帧中的变量。
-
此外,如果任何变量被丢弃,作者将返回指令视为SDVO指令,并检查是否引入了新状态。
-
3.3.状态感知符号执行
这一部分将解释如何使用已识别的状态描述变量来引导符号执行。如挑战2中所介绍的,很难确定某个状态是否已经探索过。为了应对这一挑战,作者的解决方案基于以下insight:程序中的状态转换取决于状态描述变量的约束。
符号执行引擎记录每个执行路径的符号输入上的约束,并确保满足相同约束的任何输入肯定会采用相同的执行路径。此外,程序状态信息被Ferry捕获为状态描述变量。因此,如果两个执行对每个状态描述变量具有相同的约束,则它们应该遵循相同的状态转换(也就是走过相同的路径)。
如2.3所述,在执行某些SDVO指令时会发生状态转换。在真实世界的程序中,在以下情况下,指令是SDVO指令。
-
初始化:一个新的状态描述变量被初始化。
-
数据约束更改:状态描述变量上的约束通过赋值进行更改或更新以采用特定的分支方向。
-
变量释放:状态描述变量的释放发生在其活动结束时。可能是
free调用或者return指令。
除了状态描述变量外,Ferry还记录最新状态转换发生的位置(即,它最后遇到的SDVO指令的地址).
如果两个执行路径的状态转换位置或对状态描述变量的约束不同,那么它们就换探索不同的程序路径。然后,一旦发生状态转换,Ferry将当前状态与探索记录进行比较。如果观察到新的未探索状态,作者将记录其SDVO指令地址和状态描述变量的约束。否则回滚符号执行以探索不同的程序状态。
4.算法
状态感知符号执行算法如下图所示,一个状态用4元组 ( l , s , ∏ , Δ ) (l, s, \prod, \Delta) (l,s,∏,Δ) 表示:
-
l l l 表示当前执行指令的地址(对应klee中ExecutionState::pc)。
-
s s s 存储当前执行路径对应的程序状态(对应
ExecutionState的部分子集) -
∏ \prod ∏ 保存路径约束(对应klee中Executionstate::constraints)。
-
Δ \Delta Δ 保存一个符号存储字典(对应klee中ExecutionState::symbolics),将运行时变量映射到具体值或符号表达式。
此外,作者还引入了一个状态变量 ,以及一个全局状态存储
Ω
\Omega
Ω,它记录探索过的程序状态(包括这些状态对应的最近SDVO指令的地址和状态本身)。
s
s
s 会追踪3个变量集合:BranchRelated, InputDetermined, StateDescribing。

-
红框部分为Ferry相比标准符号执行多出的部分。
-
蓝框里面的
updateState函数的功能相比标准符号执行有了扩展。Ferry中update(s, v, e)中s为对应状态,v为要赋值的变量,e为值或者约束。
默认情况下,Ferry采用BFS状态搜索策略,pickNext 相当于 selectState()。在算法中,只有被计算出未被探索过的状态会添加进 worklist。
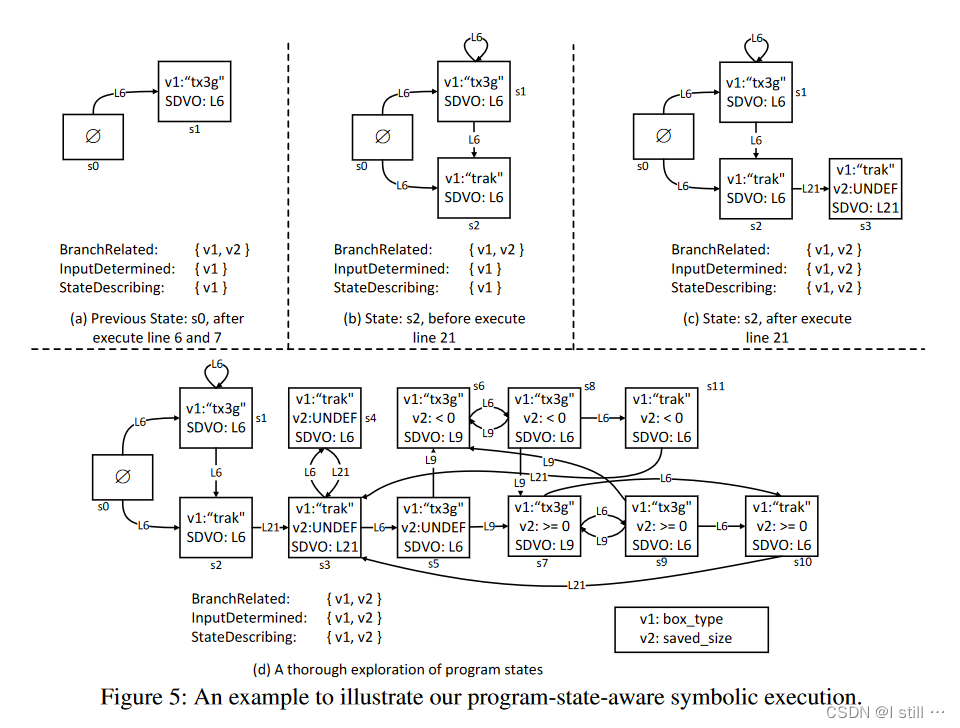
图5展示了图1示例用Ferry运行的过程,图中的环路表示执行完环路对应的指令后会出现重复状态。能够识别重复状态后符号执行的效率会更高。不同的状态的区别如下:
-
s6和s8的SDVO地址不同(L9和L6)。 -
s1和s2关于v1(box_type)对应的约束条件不同(值为tx3g还是trak)。 -
s11和s2相比多了变量v2(box_size) 的约束。
-
第一个状态描述变量是
box_type。首先在第 4 4 4 行加载并被标记为InputDetermined,然后在第 6 6 6 行被switch指令访问然后被标记为BranchRelated。然后被标记为stateDescribing。因此,第 6 6 6 行是1个SDVO指令,第 6 6 6 行执行完毕后,fork出的2个状态分别记为s1,s2。如果s1被执行过1遍,第2次执行第 6 6 6 行时再次fork,新fork的s1会被识别为已被探索过,避免重复执行。 -
saved_size是另一个状态描述变量,第 9 9 9 行的条件判断语句访问了它。然而,直到输入序列的内容流入其中(第 21 21 21 行的赋值操作),它才被标识为StateDescribing。因此,第 9 9 9 行的第一次执行不会引入新的程序状态。稍后,当任何执行路径到达第 21 21 21 行时,saved_size被标识为StateDescribeing,因此引入了新的状态s3。然后,对第 6 6 6 行的进一步执行可以进入分支“tx3g”,因为引入了一个新的状态描述变量。在第 9 9 9 行的第二次执行中进一步更新对该存储器位置的约束。因此,引入了两种新状态(s6和s7)。
5.针对复杂真实程序的优化
真实程序的复杂性可能主要通过两种方式影响Ferry的有效性:
-
真实程序可能有数百甚至数千个状态描述变量,这导致状态描述变量跟踪的高开销。
-
真实程序可能在执行路径上有多个状态依赖分支,因此,Ferry可能会陷入探索早期状态依赖分支的困境,而无法探索后期的分支。
为了解决这些问题,作者提出了2种解决思路:
-
通过移除闲置变量减少对少用状态描述变量的不必要跟踪。
-
通过快捷符号执行(SSE) 探索更深的状态。
值得注意的是,这两种优化虽然不一定适用于每个程序,但并不影响基本算法。
5.1.移除闲置状态依赖变量
为了避免探索已经探索的程序状态,Ferry需要不断地将每个状态描述变量的约束(即所有可能值的集合)与探索历史进行比较,这会导致不可忽略的性能开销。为了缓解这个问题,作者提出了一种优化方法,它减少了要跟踪的状态描述变量数量。
作者没有跟踪所有状态描述变量,而是设置了数量限制,只关注最近访问的变量(即,重新赋值或被条件判断语句访问)。作者的研究表明,状态描述变量的访问频率不同。在表1列举的程序中,72%的状态描述变量被检查不超过5次,top 4%的状态描述变量占据了85%以上的变量访问。这个分布表明,对于程序中的许多状态描述变量,它们的值将在很长一段时间内保持不变。如果执行路径不访问状态描述变量,则其值保持不变,并且不会导致状态转换。
应仔细选择跟踪变量的数量。跟踪较低的数字可能会错误地忽略状态描述变量,导致不同的状态被识别为相同的状态(因此路径被错误地修剪)。高限制会增加要跟踪的变量数量,从而将时间浪费在约束求解上而不是路径探索上。
作者对表1中的7个程序进行了实验,试图找出不同数量的跟踪变量如何影响执行路径的数量。最后,作者发现跟踪3个变量有助于减少状态之间的比较,并达到深层程序状态,因此我们在下面的实验中将其设置为默认配置。
5.2.带有输入分区的快捷符号执行(SSE)
在真实程序中,到“深层”状态的执行路径由许多状态依赖分支来保护。与路径爆炸类似,程序状态的数量随着状态依赖分支数量的增加而快速增长。幸运的是,作者发现,除了试图覆盖所有这些分支,还可以将它们分成独立的组,这些组可以单独处理。
在真实程序中,开发人员不会在一个函数中处理整个输入序列,相反,输入序列的不同部分由不同的函数组处理。例如,图1示例中的输入处理循环仅解析每个 data box 的 box_type 和 box_size。另一方面,有效载荷数据在第
18
18
18 行被读入缓冲区 buf,并由另一个函数处理。
因此,这些函数中的状态依赖分支也取决于输入序列的不同部分,我们可以根据输入序列中由它们所属函数处理的部分对这些分支进行分组。基于这一观察,可以通过有选择地提供具体的输入,绕过早期的状态依赖分支。
当开启SSE后,需要手动提供种子文件(seed file)以约束输入,给定种子,SSE按以下步骤运行:
-
首先,SSE通过符号仿真自动识别由不同组状态依赖分支处理的不同输入部分的边界。
-
然后,利用推断出的边界,SSE有选择地使某些输入分区符号化,以符号化的方式在状态感知的状态中执行相应的状态依赖分支组。
-
然后,它尝试通过动态移除相应输入部分上的约束来探索特定的状态相关分支组。
6.实验
Ferry基于angr框架实现,约束求解器用的是Z3,unicorn被用来加速SSE中具体文件内容的仿真。
实验过程包括:
-
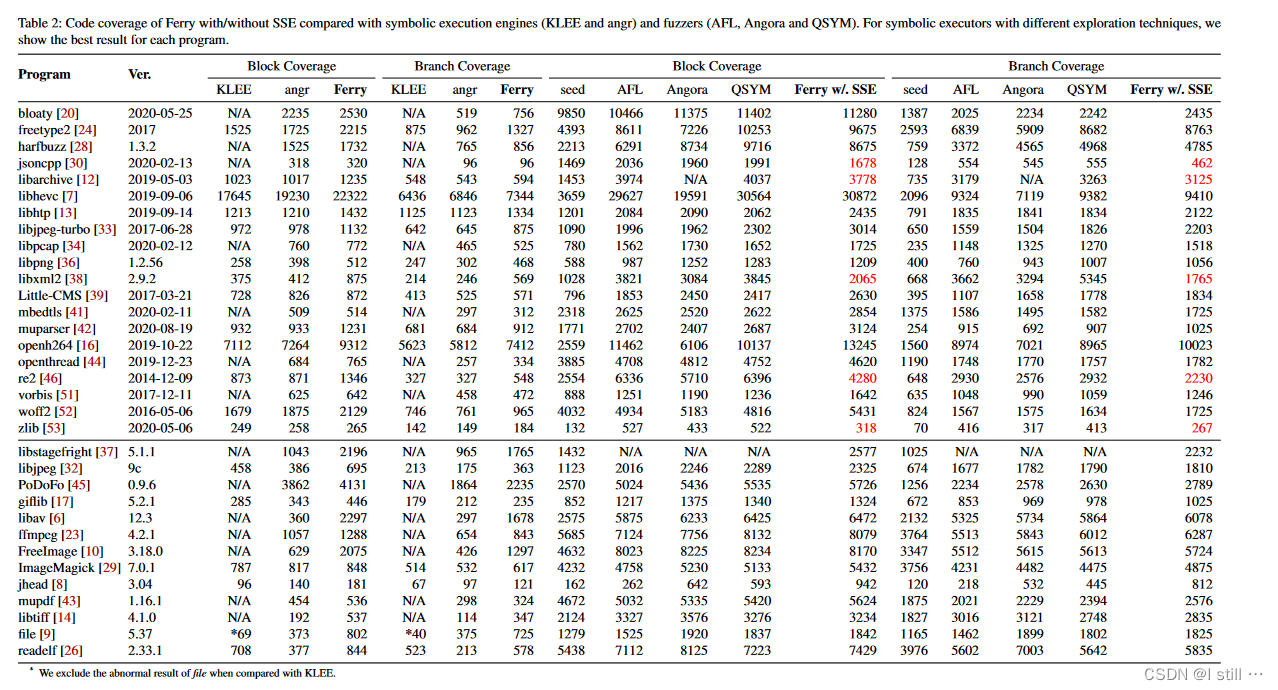
首先在13个真实程序和Google FuzzBench 上和其它工具比较覆盖率。结果表明
-
与klee相比,Ferry能多覆盖38%的基本块以及42%的分支;与angr相比,Ferry能多覆盖42%的基本块以及47%的分支。
-
给定相同的输入种子,Ferry在开启SSE后覆盖率超过AFL,Angora和QSYM 3个fuzz工具。其中15%的基本块这3个fuzz工具都错过了。
-
-
在漏洞检测方面,作者构造了一个测试套件River。River由6个程序构成,包含160个手动注入的漏洞。这些漏洞必须在特定的上下文上触发(与状态依赖分支有关的漏洞)。与2个符号执行工具,3个fuzz工具相比,Ferry找出的漏洞比它们多40%,同时速度快2.4倍。
-
作者用LAVA-m数据集来评估Ferry在状态无关漏洞下的性能。在最坏的情况下,Ferry在BFS策略上的表现几乎与angr相同,只是它避免了探索一些重复的路径。
在符号执行中,如何驱动执行到达触发漏洞的分支,以及如何触发/利用漏洞(在通过符号执行到达相应的安全漏洞之后)是两个独立的问题。由于第2个问题在符号执行领域没有得到很好的解决,因此这项工作必须将其排除在范围之外。同时sanitizer和符号执行工具目前不能很好的结合,反而更容易引起严重的路径爆炸,因为它针对输入数据引入了更多的条件检查。
实验过程中,作者给每个程序设置的时间限制是6小时,并且重复3次实验取平均值。Ferry采用的搜索策略包括了BFS和DFS。SSE中用到的种子文件来自AFL测试用例(另一个下载地址)。
6.1.覆盖率测试
下表总结了覆盖率测试结果
6.2.状态依赖漏洞测试
如果漏洞触发路径至少包含1个状态依赖分支,那么这个漏洞是状态依赖漏洞。作者按下列3步构造漏洞数据集:
-
首先,确定每个相关程序的版本,减少搜索范围。将其版本设置为CVE数据库中报告漏洞最多的版本。
-
然后收集每个漏洞的信息,包括其代码位置和触发的输入序列。具体来说,通过三种方式收集漏洞详细信息:
-
找到CVE数据库中每个漏洞的参考链接 。
-
在Exploit数据库中搜索它们,该数据库提供了许多漏洞的POC。
-
找到修复漏洞的补丁并从中学习。
-
-
最后,手动过滤那些不依赖于程序状态的漏洞。
下表展示了收集到的15个漏洞以及各个工具的测试结果。但是符号执行器不能自动触发这些漏洞,因此作者将这些漏洞的触发位置替换为 assert(0),被替换的语句必须在特定状态下触发。这些漏洞包含堆/栈溢出,整数溢出,double-free,use-after-free,除0,未初始化的指针引用。

从结果来看,Ferry效果最好,开启SSE前覆盖了8个漏洞,开启SSE后全部覆盖。标准符号执行受到路径爆炸的影响会重复探索很多状态,Fuzz的效果受到输入种子的影响。
6.3.深度状态探索
作者提出了一个测试套件River,以帮助评估动态分析工具可以探索状态依赖分支的程度。River与其他数据集(如LAVA-M)的不同之处在于,它意味着评估工具探索“深层”状态的能力。River数据集具有以下特征:
-
所有插入的漏洞都属于状态依赖类型,这意味着它们只能由特定的输入序列触发。
-
漏洞分布在不同的状态深度上。
作者手动注释了所有插入的漏洞,并记录了它们的状态深度信息。每个漏洞被标注为二元组 (ID, depth),触发了该漏洞意味着该工具可以探索深度为 depth 的状态依赖分支。
River构建过程如下:
-
首先,使用Ferry来分析程序6个小时,并记录漏洞注入所需的信息,包括每个状态转换的代码位置,SDVO地址,以及路径约束。
-
在每个SDVO之后手动注入漏洞(这一步会忽略路径约束太复杂的SDVO)。
每个注入的漏洞为 assert(0 && state_depth && vul_id),这表示这些漏洞不会无条件被触发。
下图为测试结果,横轴为漏洞深度,纵轴某个工具累计找到的bug数量。(小于该深度的累计)

6.4.推断的SDVO准确率
这部分暂时略过。
6.5.Case study
libstagefright中的CVE-2016-3830漏洞:在所有已评估的符号执行引擎中,只有具有SSE的Ferry才能自动定位此漏洞。作者的手动分析指出困难在于:
-
该漏洞发生在AAC格式的音频解码器中,该解码器受到至少两个早期状态机的“保护”。
-
第一状态机初始化音频解码器并提取音频报头和音轨,第二状态机利用音频报头来配置解码器。
-
该漏洞存在于解码音轨的第三状态机中。实验表明,angr在第一状态机中遭受路径爆炸,如果禁用SSE,Ferry在第二状态机中遭遇严重路径爆炸。
-
-
该漏洞只能在第三状态机的深层程序状态下被利用。具体而言,在预期的有效负载大小
adtsHeaderSize与存储在aac_frame_length中的计算结果不匹配之后的状态下。
为了衡量SOTA符号执行算法的效率,作者通过手动将第三个状态机的入口点分配给angr,将此案例进一步应用于angr。评估显示,angr仍然未能找到该漏洞。
6.6.性能baseline
这一部分作者用Lava-M进行评估,Lava中注入的漏洞都是上下文无关的(不是状态依赖的),下表为实验结果。可以看到,Ferry在最坏的情况下和angr-BFS性能相同。

6.7.Discussion
这里,作者主要讨论Ferry失效的一些场景。Ferry在特定的程序逻辑上性能会受限(字符串搜索,压缩算法)。
-
一方面,对于符号执行器来说,它们是常见的挑战,因为这样的逻辑会产生复杂的路径约束,而这些约束会压倒约束求解器。
-
另一方面,这种程序逻辑会导致状态爆炸。
例如,压缩算法具有巨大的内部状态空间,对输入字节的任何更改都将导致不同的程序状态,并改变处理所有后续输入的方式。在这种情况下,Ferry遭受了状态爆炸(这进一步导致了路径爆炸)作者们的优化有助于缓解状态爆炸,但不能完全解决这个问题。
作为系统地处理具有状态依赖分支的程序以进行符号执行的第一次尝试,作者的技术适用于具有2.3中讨论的特性的程序。然而,它目前还不是一种通用方法。仍然阻碍符号执行引擎的一个主要挑战是如何识别任意程序中的状态描述变量。作者将此问题作为未来在Ferry上的工作。
七.参考文献
Ferry: State-Aware Symbolic Execution for Exploring State-Dependent Program Paths















 58
58











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









