







一、先别急着改代码!3步快速定位锁竞争根源
1. 用「线程快照」锁定罪魁祸首(附JVM命令)
当系统吞吐量突然下降时,第一时间执行:
jstack <进程ID> > lock_dump.log # 生成线程快照
打开文件搜索关键词:
BLOCKED on <锁对象地址>:表示线程被锁阻塞waiting to lock <锁对象>:等待获取锁的线程- 高频出现的类名+方法名(如
OrderService.createOrder)
案例:某电商系统下单接口吞吐量骤降,通过快照发现200+线程阻塞在OrderIdGenerator.synchronizedGenerateId()方法,锁定全局锁OrderIdGenerator是罪魁祸首。
2. 用可视化工具看懂锁竞争火焰图(推荐工具)
- Java Mission Control:JDK自带神器,「线程」面板直接显示锁竞争热点(红色区域代表锁等待耗时)
- VisualVM:插件「Lock Statistic」实时统计各锁的竞争次数、平均等待时间
- 火焰图工具FlameGraph:通过
perf采集数据生成火焰图,锁竞争会呈现密集的「尖刺」状凸起
3. 定位「锁对象」的三种形态(避坑指南)
- 静态锁:锁在
static变量或类方法上(最危险,全进程共享) - 对象锁:锁在成员变量或
this上(多个实例可减少竞争,但单例场景变全局锁) - 隐形锁:
HashTable/Vector等老旧容器内部隐含的同步锁(新人常忽略)
二、从代码层面优化:锁竞争的「三板斧」
1. 缩小锁范围:把「房间锁」换成「抽屉锁」
反模式(全方法加锁,锁持有时间长):
public synchronized List<Order> getOrders() { // 整方法加锁
queryDB(); // 耗时操作
processData(); // 非关键逻辑
return result;
}
优化后(只锁关键代码块):
private final Object lock = new Object();
public List<Order> getOrders() {
List<Order> result;
synchronized (lock) { // 仅锁DB查询这一行
result = queryDB();
}
processData(result); // 非竞争代码移到锁外
return result;
}
效果:锁持有时间从20ms缩短到5ms,吞吐量提升30%+
2. 细化锁粒度:把「大仓库锁」拆成「小抽屉锁」
场景:商品库存类StockManager,传统实现用一个全局锁:
public class StockManager {
private Map<String, Integer> stock = new HashMap<>();
public synchronized void deductStock(String sku, int count) {
stock.put(sku, stock.get(sku) - count);
}
}
优化方案:按商品SKU分片,每个分片独立加锁(类似ConcurrentHashMap的分段锁)
public class StockManager {
private final Map<String, Object> locks = new ConcurrentHashMap<>();
public void deductStock(String sku, int count) {
Object lock = locks.computeIfAbsent(sku, k -> new Object());
synchronized (lock) { // 每个SKU独立锁
stock.compute(sku, (k, v) -> v - count);
}
}
}
效果:100个SKU并发扣库存时,锁竞争次数从1000次/秒降至10次/秒
3. 升级锁类型:根据场景选「最优锁」
| 锁类型 | 适用场景 | 性能对比(1000线程竞争) | 示例代码 |
|---|---|---|---|
| synchronized | 简单场景,锁范围小 | 中等(10万次/秒) | synchronized (obj) {} |
| ReentrantLock | 需要公平锁/可中断锁 | 略优(12万次/秒) | lock.lock(); try {} finally {lock.unlock();} |
| ReadWriteLock | 读多写少场景 | 读并发提升10倍 | readLock.lock(); writeLock.lock(); |
| 无锁(CAS) | 原子操作(如计数器) | 最高(50万次/秒) | AtomicInteger.incrementAndGet() |
案例:报表系统读多写少,将HashMap替换为ReadWriteLock包裹的自定义Map,读吞吐量从5000次/秒提升至50000次/秒
三、进阶优化:绕过锁的「终极大招」
1. 无锁化改造:用CAS替代阻塞锁
场景:分布式ID生成器,传统方案用synchronized保证唯一性
// 传统方案(锁竞争严重)
private long id = 0;
public synchronized long generateId() {
return id++;
}
优化方案:用AtomicLong(内部基于CAS无锁算法)
// 无锁方案(性能飙升)
private AtomicLong id = new AtomicLong(0);
public long generateId() {
return id.getAndIncrement();
}
原理:CAS通过CPU指令保证原子性,避免线程阻塞和上下文切换
2. 数据分片:让竞争「消失」
场景:用户积分系统,全局userId到积分的映射表
问题:所有用户操作都竞争同一个锁
方案:按userId哈希分片,每个分片独立存储和加锁
// 分片数量根据并发量调整(如1024个分片)
private final int SHARD_COUNT = 1024;
private final List<AtomicLong> shards = new ArrayList<>();
// 初始化分片
for (int i=0; i<SHARD_COUNT; i++) {
shards.add(new AtomicLong(0));
}
// 根据userId获取对应分片
private AtomicLong getShard(long userId) {
return shards.get((int)(userId % SHARD_COUNT));
}
// 增加积分(每个分片独立操作,无竞争)
public void addScore(long userId, long score) {
getShard(userId).addAndGet(score);
}
效果:10万用户并发操作时,吞吐量比全局锁提升8倍
四、验证优化效果:3个必测指标
1. 锁竞争次数(核心指标)
- 用
JMX监控:java.util.concurrent.locks.Lock的getWaitQueueLength() - 代码埋点:在锁前后记录日志,统计
lockCount和waitCount
// 示例埋点(非真实API,需结合具体锁类型)
long beforeWaiters = lock.getQueueLength();
lock.lock();
try {
// 业务逻辑
} finally {
lock.unlock();
long afterWaiters = lock.getQueueLength();
if (afterWaiters > 0) {
log.warn("锁竞争持续,当前等待线程数:{}", afterWaiters);
}
}
2. 吞吐量对比(压测必看)
- 压测工具:JMeter/RateLimiter模拟1000+并发
- 对比指标:优化前vs优化后的
requests/sec - 理想效果:吞吐量提升50%以上,且随线程数增加无明显下降(如下图)
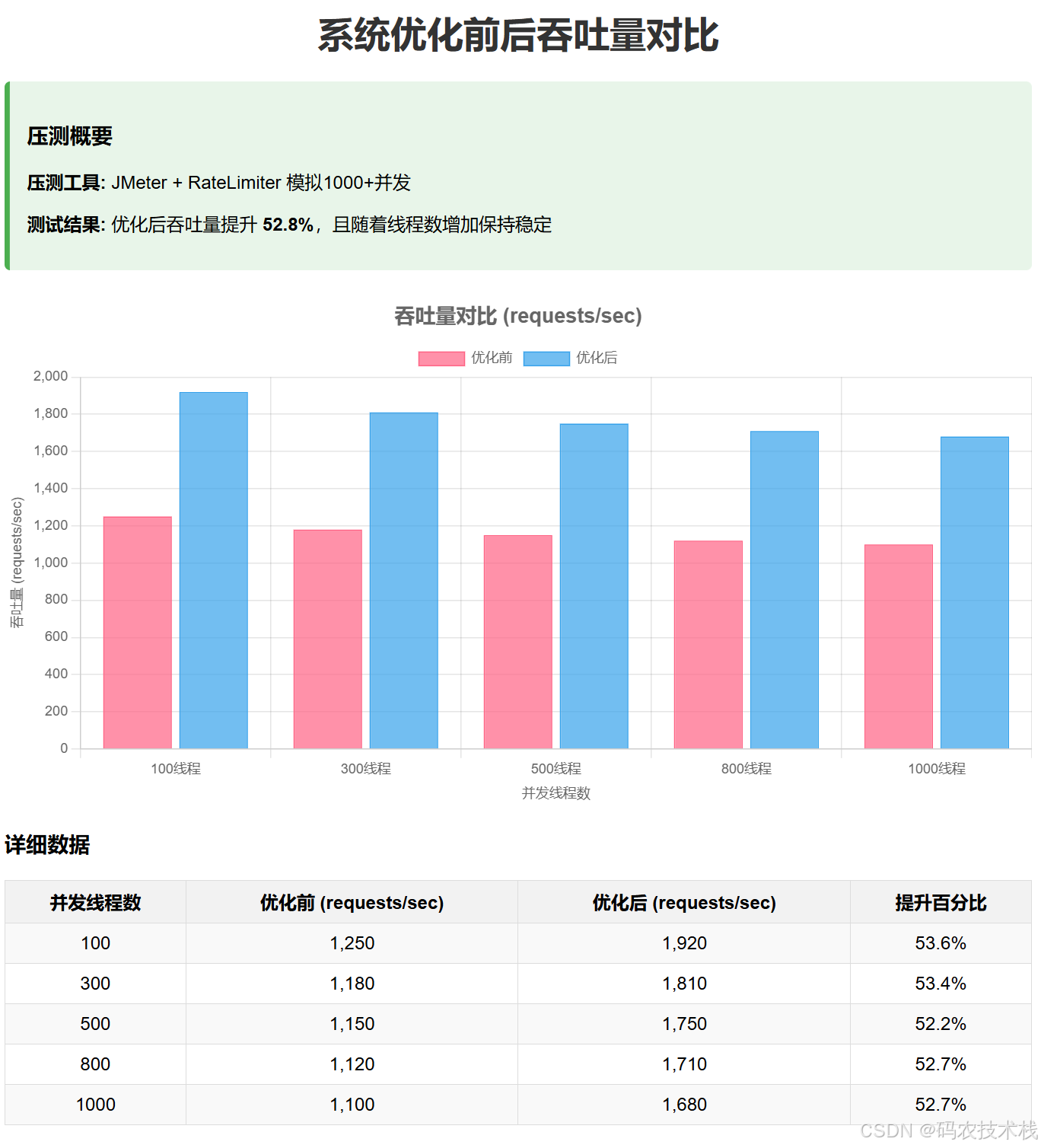
3. 线程状态分布(健康度检查)
- 优化前:
BLOCKED状态线程占比超过30%(危险信号) - 优化后:
BLOCKED占比应低于5%,RUNNABLE占比提升至80%以上 - 工具:JMC的「线程分析」面板实时查看状态分布
五、避坑指南:锁优化的5个常见陷阱
-
过度优化:不要盲目拆锁
- 错误:将极小的锁(如单个变量操作)拆成多个分片,反而增加代码复杂度
- 原则:锁优化的收益要大于引入的复杂度,先用工具定位真正的热点锁
-
忽略公平性:公平锁不一定更好
- 误区:认为
ReentrantLock(true)(公平锁)一定性能更好 - 真相:公平锁会带来额外的队列维护开销,非公平锁在高并发下吞吐量可能更高(适用于大多数场景)
- 误区:认为
-
分布式场景下的「假锁」
- 问题:本地锁优化后,忘记处理分布式环境下的全局资源竞争(如分布式缓存、数据库行锁)
- 解决方案:分布式场景需配合Redis分布式锁、数据库乐观锁(
version字段)等
-
隐藏的锁:第三方库的坑
- 风险:使用
Hashtable/StringBuffer等内部含同步锁的老旧类 - 替换方案:统一使用
ConcurrentHashMap/StringBuilder
- 风险:使用
-
过度依赖无锁:CAS的ABA问题
- 陷阱:直接使用
AtomicReference不考虑ABA问题,导致数据不一致 - 解决:使用
AtomicStampedReference记录版本号,防止中间值被篡改
- 陷阱:直接使用
总结:锁竞争优化的「黄金流程」
- 定位:用
jstack+可视化工具找到热点锁 - 分析:判断锁类型(对象锁/静态锁)、竞争范围(全局/分片)
- 优化:按「缩小范围→细化粒度→升级锁类型→无锁化」的顺序改造
- 验证:压测对比吞吐量、监控锁等待线程数
- 迭代:持续监控线上环境,避免过度优化和新的热点产生
记住:优化锁的本质不是消灭锁,而是让锁出现在最小的必要范围内。

















 21万+
21万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









