






数据初步了解

(head出现,意味着只出现前5行,如果只出现后面几行就是tail)
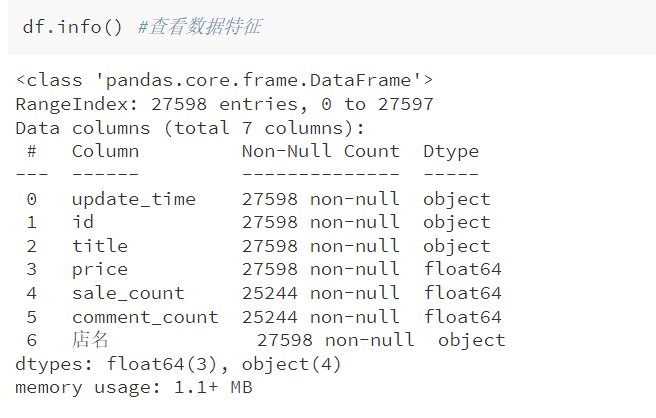
info
shape

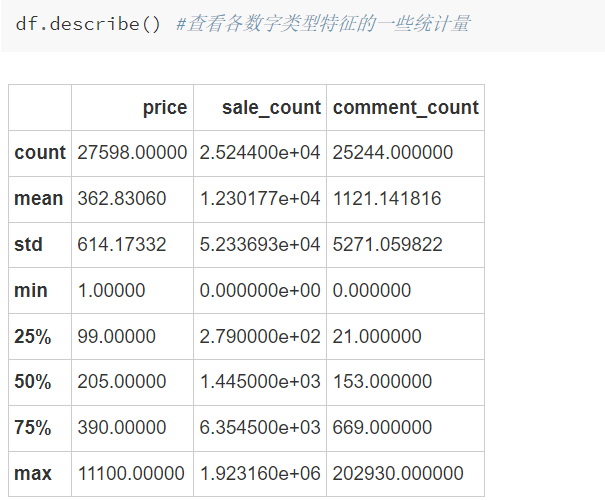
describe
数据清洗
重复值处理
这个重复值是否去掉要看实际情况,比如说:昨天卖了5瓶七喜,今天卖了5瓶七喜,同样的数量,这种重复值就不能删除,要有一个合理的解释去说明删除的是无效重复数据。

缺失值处理

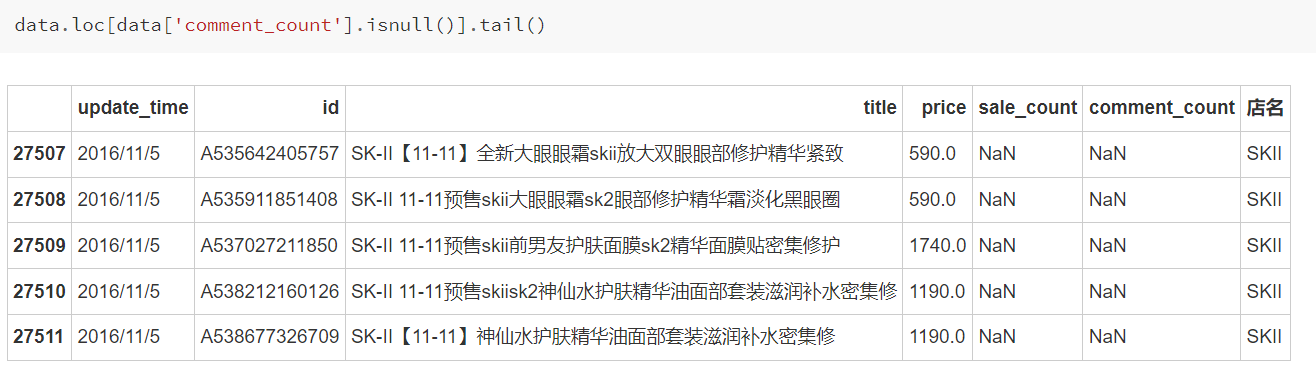
存在的缺失值很可能意味着售出的数量为0或者评论的数量为0,所以我们用0来填补缺失值

数据挖掘寻找新的特征
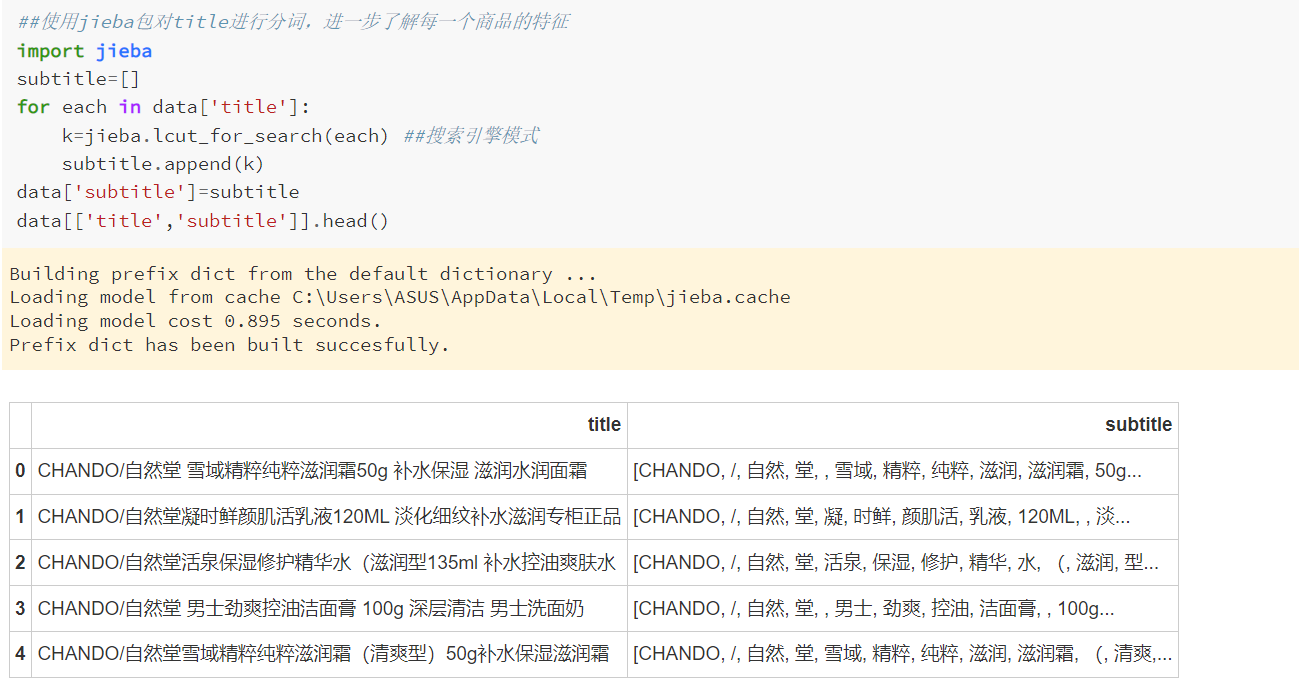
街道库(jieba)的使用方法,包括精确模式、全模式和搜索引擎模式的不同应用场景。
给出各个关键词的分类类别
创建主类别和子类别,并通过关键词进行标签化

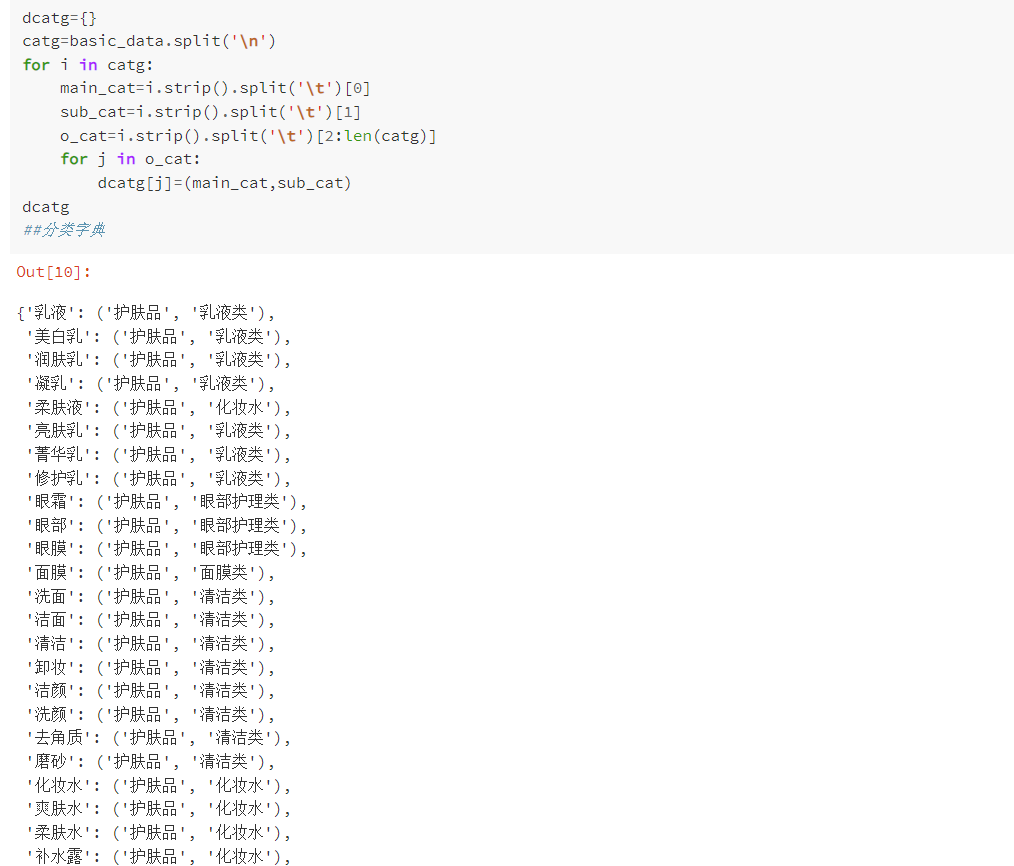
由title新生成两列类别
通过中文分词技术对title列进行处理,将其分为大类和小类,便于后续数据分析。

对是否是男性专用进行分析并新增一列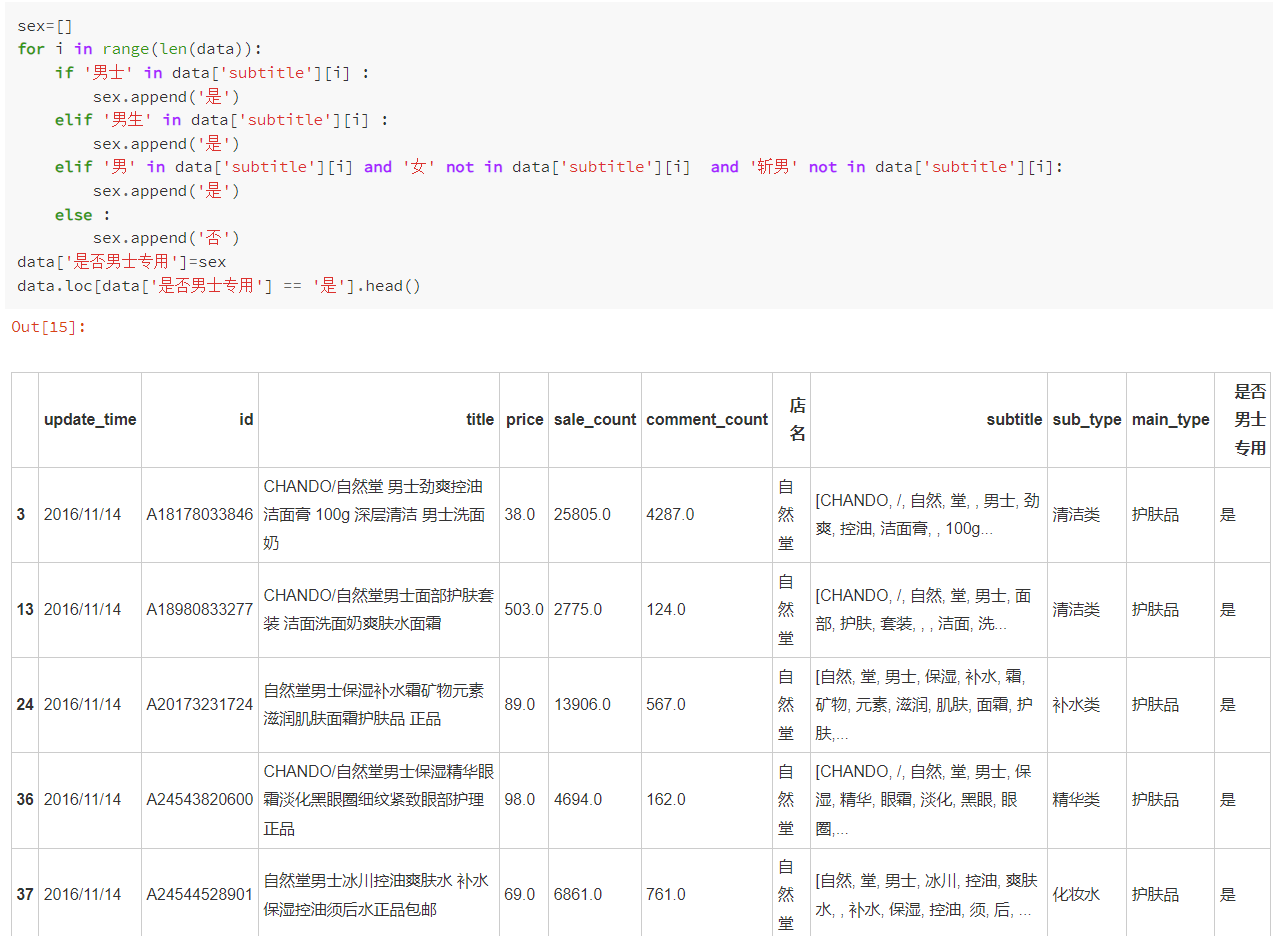

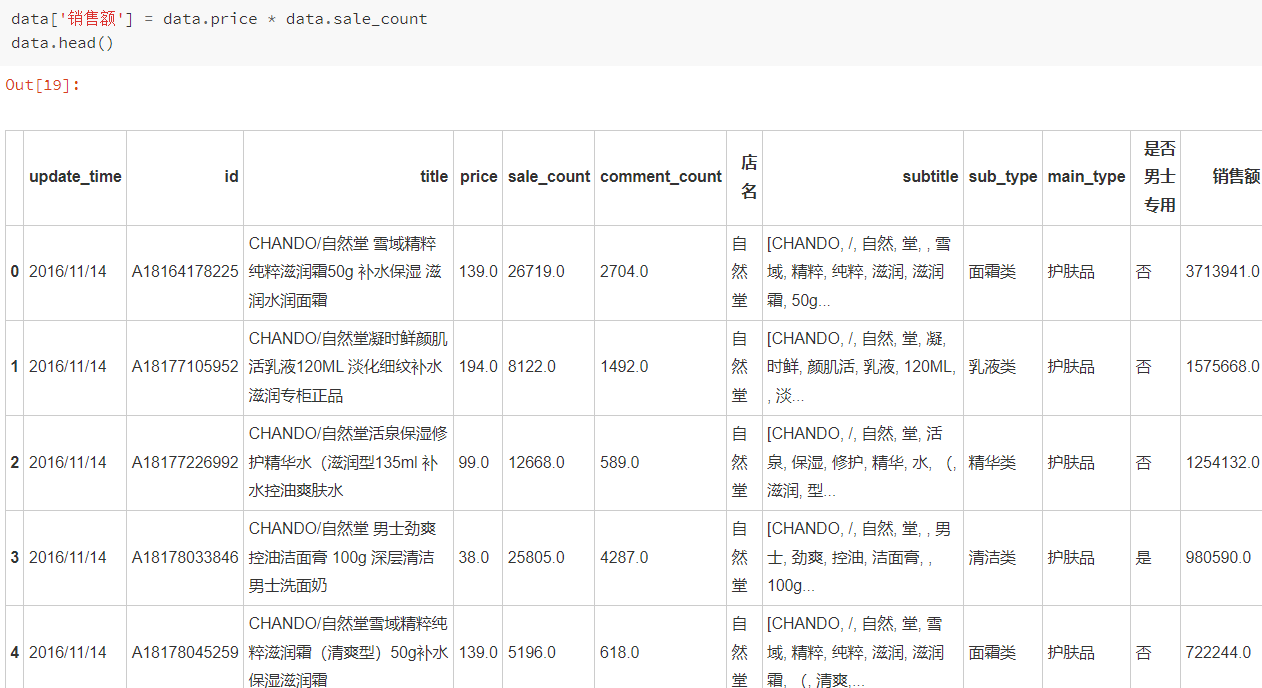
对每个产品总销量新增销售额这一列
数据分析及可视化
使用Python进行数据可视化,包括绘制柱形图和饼图
通过代码实现数据的排序和分组,并生成相应的图表
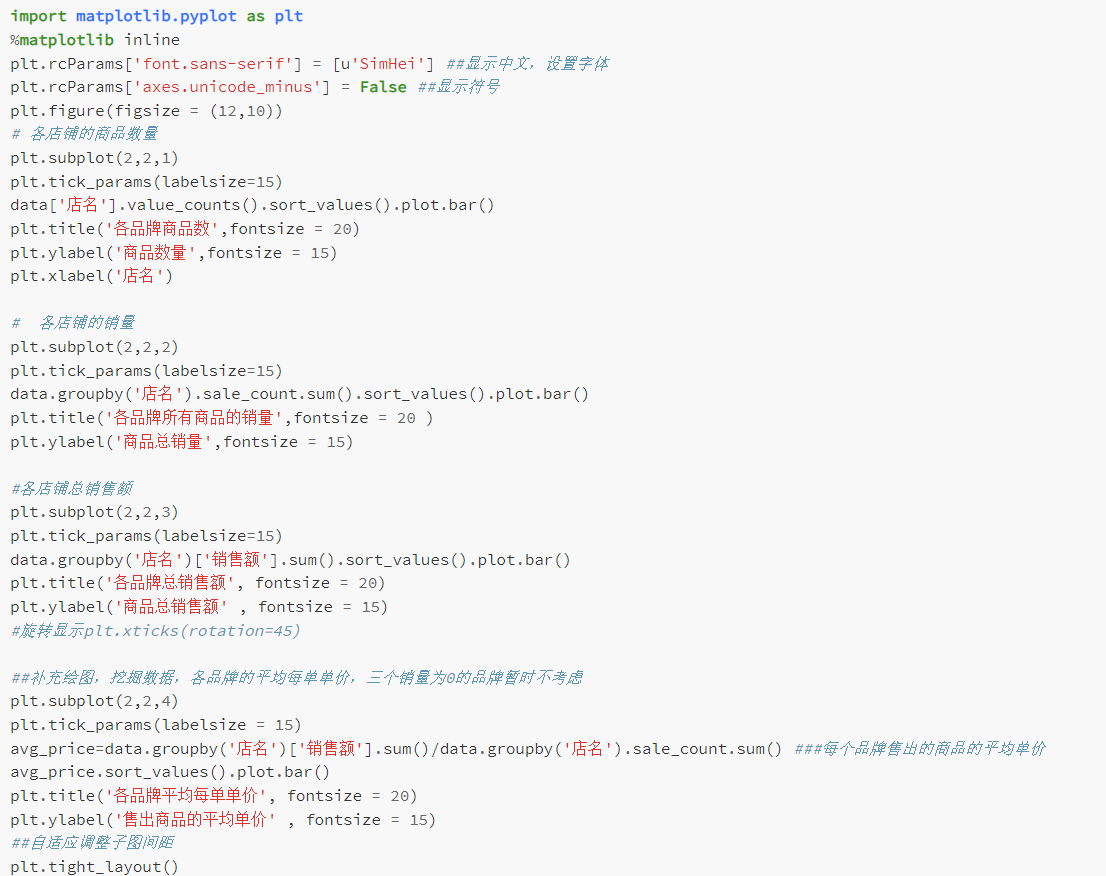
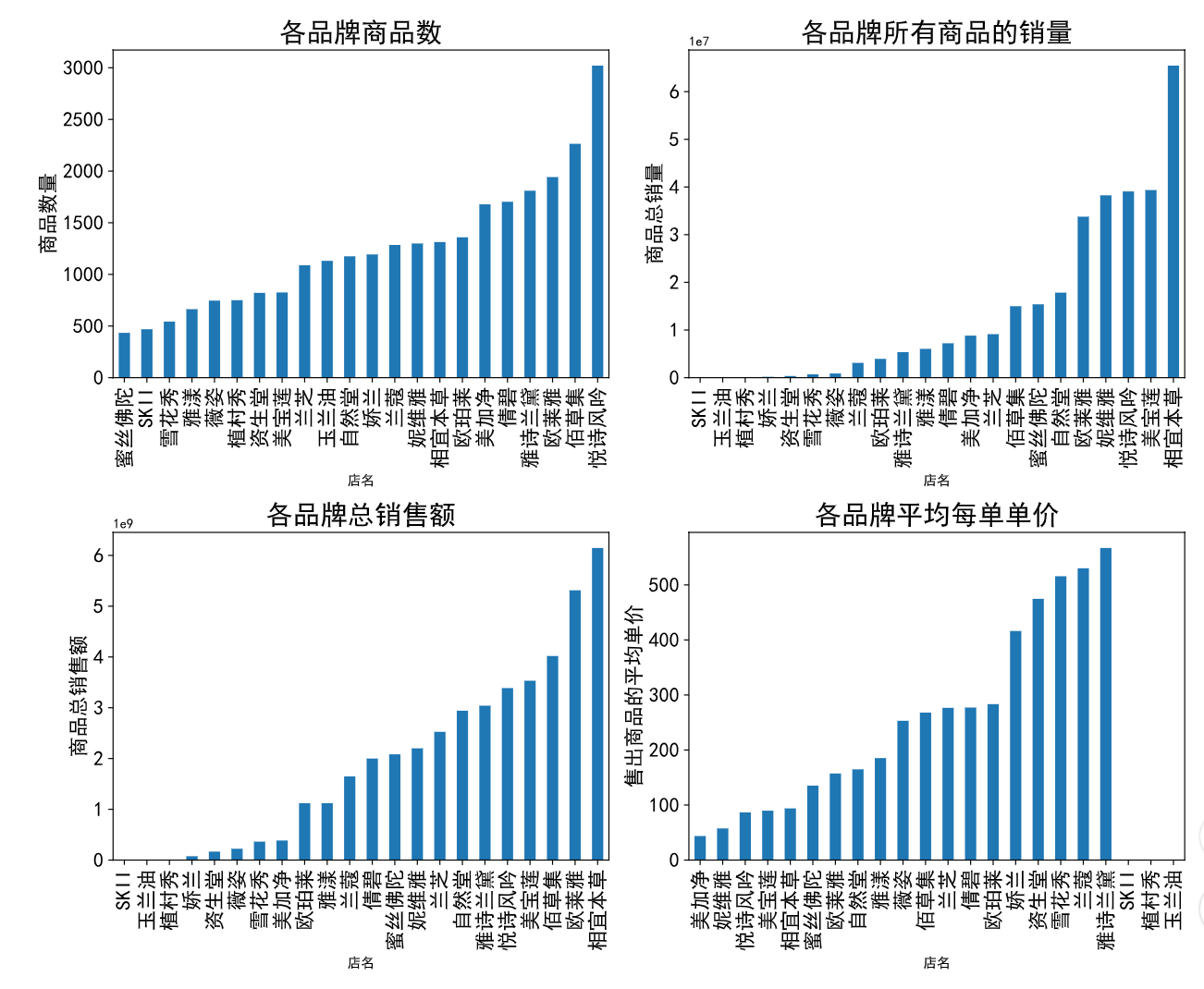
通过图表不难看出以下几点:
悦诗风吟的商品数量遥遥领先,然而其商品销量只排在第三位,总销售额只排在第五位。
SKII,玉兰油,植村秀商品数量大概都在500-1500的范围,而销量为0。
相宜本草商品数量也只属于中游,但其销量销售额均排在第一位,由于其销量是第二名的大约两倍,而销售额远不到两倍,所以销售额/销量,也就是每一单的均价也是一个值得研究的新指标。
通过加入平均每单单价之后,观察销售额较高的几个品牌相宜本草,欧莱雅,佰草集,悦诗风吟,雅诗兰黛。
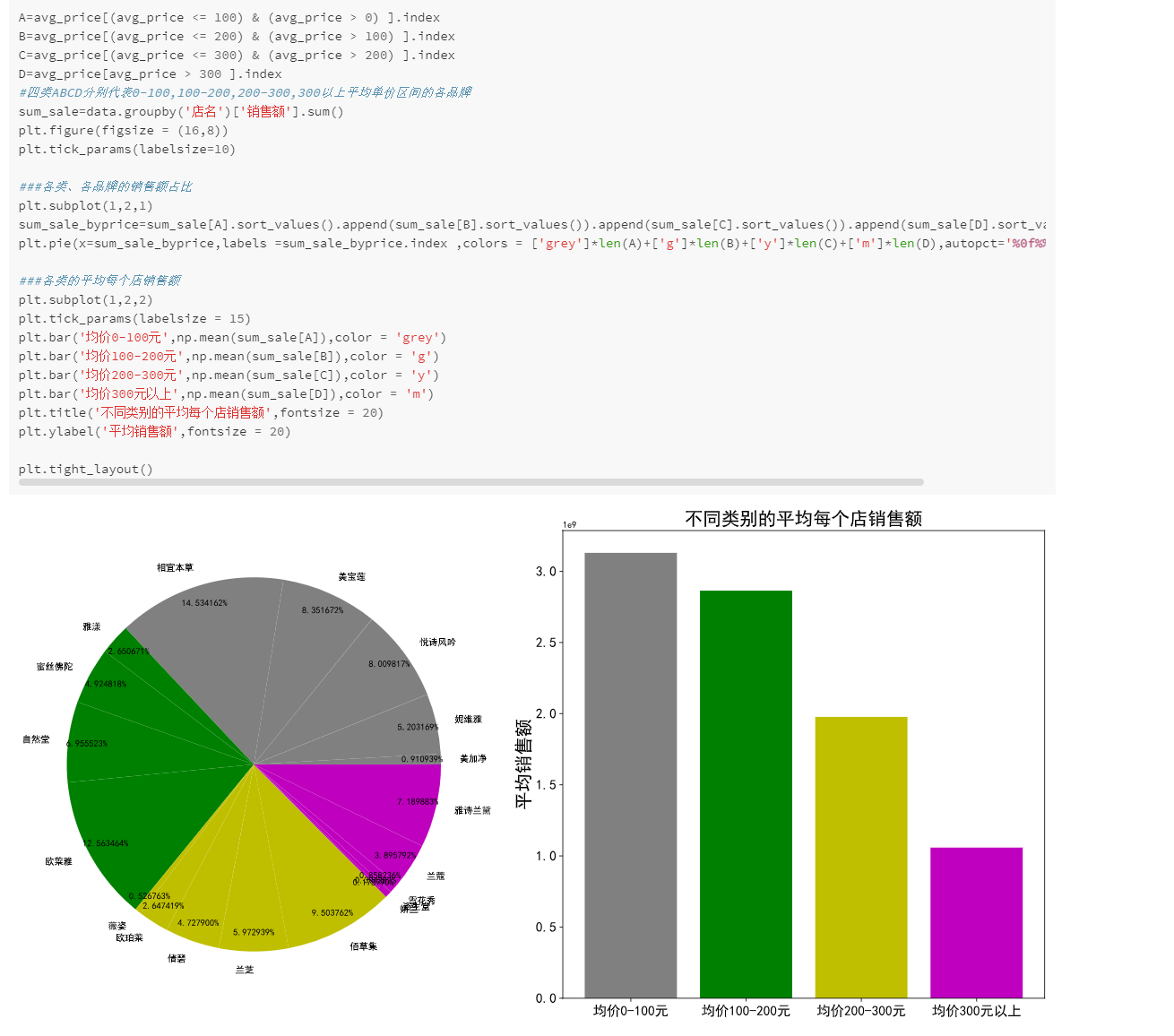
其中相宜本草,悦诗风吟,欧莱雅都是平均单价200元以下的,佰草集为200-300元区间,雅诗兰黛为大于500元区间。是否能够判断价格亲民的品牌的销售额会相对来说更高?下面根据这里的数据先把平均单价分为几个区间,其中0-100元记为A类,100-200元记为B类,200-300元记为C类,300元及以上记为D类。
(分析各品牌商品数、销量和总销售额,以及平均每单单价。
按价格区间将商品分为A、B、C、D四类,分析性价比。
细化品类分析,包括底妆、口红、化妆水等。)

















 1021
1021

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









