







案例主要用来熟悉pandas库和与mysql的连接知识
1首先建立连接 导入MySQL中的数据 代码如下
import pandas as pd # 使用pandas库进行数据库的读取
from sqlalchemy import create_engine # 导入连接数据库和python的函数:create_engine
# 建立连接
con = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8')
# 读取数据库中的SQL文件
data1 = pd.read_sql('meal_order_detail1', con=con)
data2 = pd.read_sql('meal_order_detail2', con=con)
data3 = pd.read_sql('meal_order_detail3', con=con)
# 合并读取的三个SQL文件后删除原来的数据
data = pd.concat([data1, data2, data3], axis=0) # axis=0是纵向拼接,axis=1是横向拼接
del data1, data2, data3 # 删除多余资源2将我们需要分析的列的数据 对列重命名改成中文名
#列重命名
data.rename(columns={'order_id':'订单号'},inplace=True)
data.rename(columns={'dishes_name':'菜品名称'},inplace=True)
data.rename(columns={'counts':'菜品数量'},inplace=True)
data.rename(columns={'amounts':'菜品单价'},inplace=True)
data.rename(columns={'place_order_time':'下单时间'},inplace=True)
print(data.columns)打印结果(中文名字就是我们要分析的数据列)

计算收入
# 计算收入
data['价格'] = data['菜品数量'] * data['菜品单价']
print(data)打印结果如下

查看下单时间这一列
# 查看下单时间这列
print(data['下单时间'])结果

获取八月的天数量度和星期量度
# 订餐日期与星期相对应
ind = pd.DatetimeIndex(data['下单时间'])
data['weekday_name'] = ind.dayofweek
data['day'] = pd.DatetimeIndex(data['下单时间']).day
print(data['day'])
print(data['价格'])
print(data['下单时间'])
print(data['weekday_name'])
打印结果
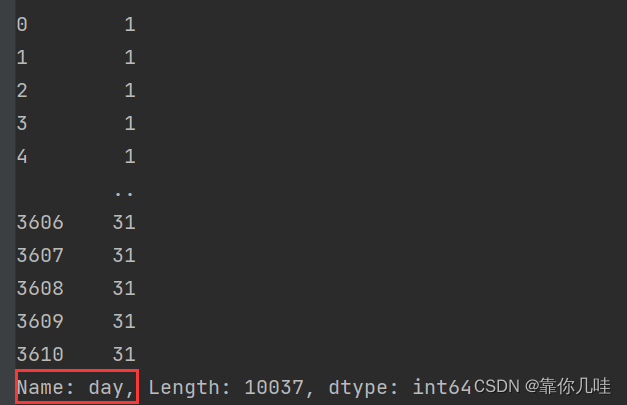
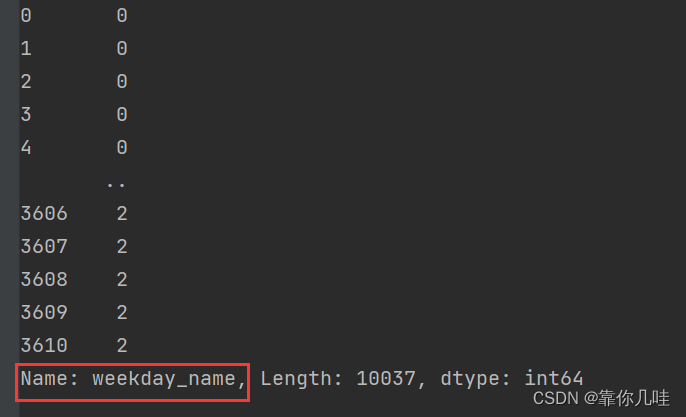
weekday_name为订单所处在星期几,0代表星期一,以此类推
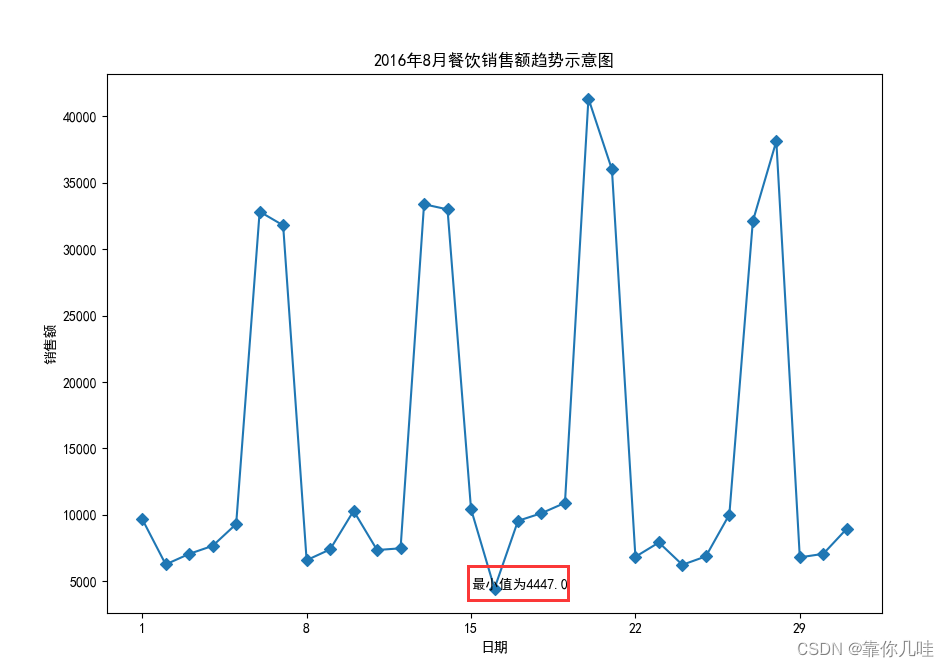
计算最小销售额的日期为16日 最小销售额为4447
import numpy as np
#print(data[['day', '价格']])
data_gb = data[['day', '价格']].groupby(by='day')
number = data_gb.agg(np.sum)
print(number)
print(number.loc[number['价格'] == number['价格'].min(),'价格']) # # 求最小值其日期
print(number['价格'].argmin()+1) # 求最小值其日期
销售额随时间天数日期变化的可视化表
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 7)) # 设置绘图窗口
plt.rcParams['font.sans-serif'] = 'SimHei' # 中文字体
plt.scatter(range(1, 32), number, marker='D')
plt.plot(range(1, 32), number)
plt.title('2016年8月餐饮销售额趋势示意图')
plt.xlabel('日期')
plt.ylabel('销售额')
plt.xticks(range(1, 32)[::7], range(1, 32)[::7]) # [::7] 坐标刻度隔七个显示一下 值为8
# 在价格最小的横纵坐标处显示其值
plt.text(number['价格'].argmin(), number['价格'].min(), '最小值为' + str(number['价格'].min()))
plt.show()如图
柱状图 星期与销售额的数量情况
# 分组聚合
import numpy as np
data_gb = data[['weekday_name', '价格']].groupby(by='weekday_name')
number = data_gb.agg(np.sum)
print(number) # number为series数据格式 
绘制图表
# 绘制图表
index = [0, 1, 2, 3, 4, 5, 6]
number2 = number.loc[index, '价格'] # 切片 切片后的number2为列表数据格式
index = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday']
number2.index = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
print(number2)
import matplotlib.pyplot as plt
# 柱状图 星期与销售额的数量情况
plt.bar(range(1, len(number2) + 1), number2, width=0.5, alpha=0.5)
plt.xticks(range(1, len(number2) + 1), number2.index)
plt.title('星期与销售额的数量情况')
for i, j in zip(range(1, len(number2) + 1), number2):
print(i, j)
print('%i' % j)
plt.text(i, j, '%i' % j, ha='center', va='bottom')
plt.show()
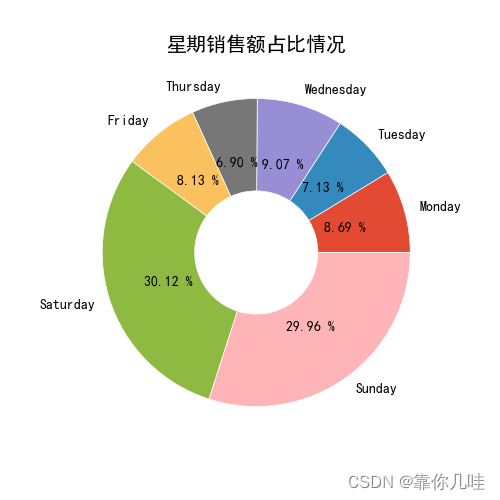
# 饼状图
import matplotlib.pyplot as plt
plt.figure(figsize=(5, 5))
plt.style.use('ggplot')
plt.pie(number2, labels=number2.index, autopct='%.2f %%', wedgeprops=dict(width=0.6, edgecolor='w'))
plt.title('星期销售额占比情况')
plt.show()

时间、销售额与订单量的关系分析
data_gb = data[['订单号', '价格', 'day']].groupby(by='day')
def myfun(data):
return len(np.unique(data))
number = data_gb.agg({'价格': np.sum, '订单号': myfun})
print(number)价格是每天的销售额,订单号是每天的总订单量
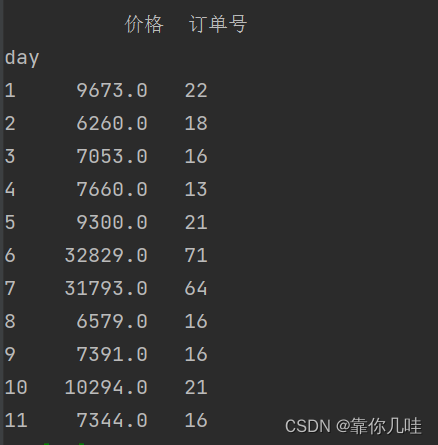
绘图(粗点代表订单量大)

后续会继续分析















 2052
2052











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









