







MixFormer: Mixing Features across Windows and Dimensions
这是一篇backbone工作,《MixFormer: Mixing Features across Windows and Dimensions》。
摘要
提出两个创新点,文中这样描述:
First, we combine local-window self-attention with depth-wise convolution in a parallel design, modeling cross-window connections to enlarge the receptive fields. Second, we propose bi-directional interactions across branches to provide complementary clues in the channel and spatial dimensions.
第一,用并行设计的方式结合了局部窗口自注意力和深度卷积,建模跨窗口连接去增大感受野。
第二,提出了一种双向交互分支去提供通道和空间维度的线索(这里理解为信息)
相关工作
- vision transformer:引入了transformer到CV领域
- Window-based Vision Transformers:vit的计算成本较高,在一些高分辨率的工作中,这带来了很大的代价,所以出现了基于窗口的vit,采用了局部窗口的注意力机制,减少了计算复杂度。
- Receptive Fields:基于窗口的vit,使用的是非重叠的窗口,这限制了感受野,有很多改进的方法,比如使用shift,expand,shuffle来连接邻近的窗口从而扩大感受野。也有一些方法使用卷积来扩大感受野。
- Dynamic Mechanism:动态网络指那些权重或者路径是数据依赖的网络(其实就是注意力机制)。In this paper, we also adopt the dynamic mechanism in the network design, while our application is based on the finding that the two efficient components share their weights on different dimensions [17].
方法
The Mixing Block
这个block在标准的基于窗口的transformer中增加了两个关键的设计,第一个就是采用并行的设计来结合局部窗口的自注意力和深度卷积,第二个就是在两个分支之间进行双向交互。
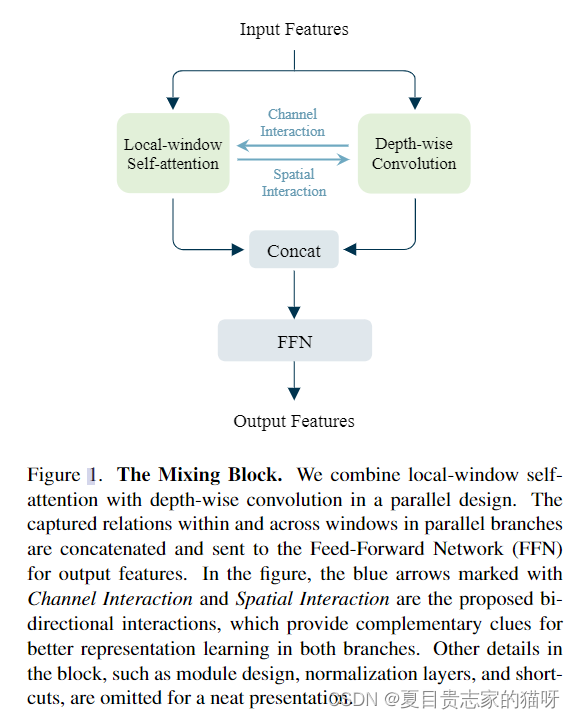
**Mixing Block由并行设计和双向交互以及一个前馈神经网络FFN组成。**前馈神经网络FFN是由两个MLP组成的,两个MLP之间有一个GELU。
并行设计
以前的方法使用卷积和自注意力依次使用的方式来增大感受野,但是这种方式会导致两种窗口内和窗口间的关系交织很少。
双向交互
The bi-directional interactions consist of the channel and spatial interaction among the parallel branches.
双向交互包括了通道交互和空间交互
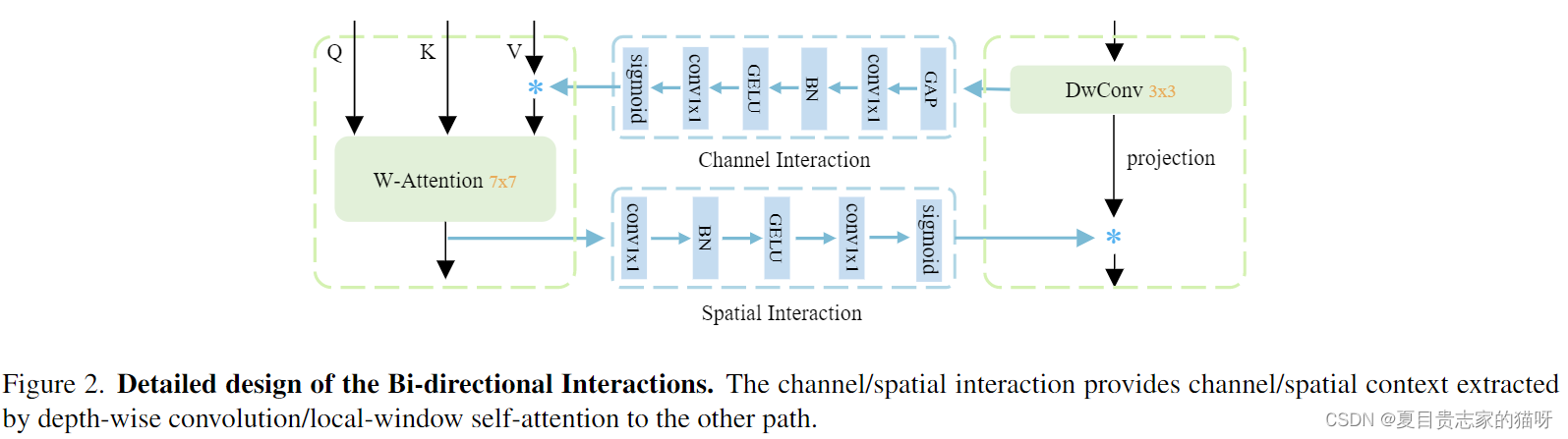
channel interaction
深度卷积提供给self-attention结构通道注意力,采取的结构与SEnet结构类似。
spatial interaction
self-attention结构提供给深度卷积空间注意力,中间的下面是将得到的特征图降低通道数到1,从而形成空间注意力。由于local window的窗口大小是7x7,而深度卷积的大小只有3x3,并且self-attention更加侧重于空间维度,所以可以提供给深度卷积强大的空间线索(信息)。
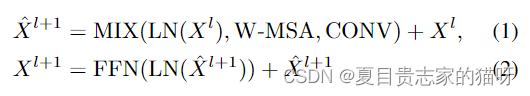
Where MIX represents a function that achieves feature mixing between the W-MSA (Window-based Multi-Head SelfAttention) branch and the CONV (Depth-wise Convolution) branch. The MIX function first projects the input feature to parallel branches by two linear projection layers and two norm layers. Then it mixes the features by following the steps shown in Figure 1 and Figure 2. For FFN, we keep it simple and follow previous works , which is an MLP that consists of two linear layers with one GELU between them.
其中MIX是将W-MSA (Window-based Multi-Head SelfAttention)分支和CONV (Depth-wise Convolution)分支特征混合的函数。MIX函数首先通过两个线性层和两个范数层将输入特征投影到并行分支上。然后按照图1和图2所示的步骤融合这些特征。对于FFN是一个MLP,由两个线性层组成,它们之间有一个GELU。
Mixformer
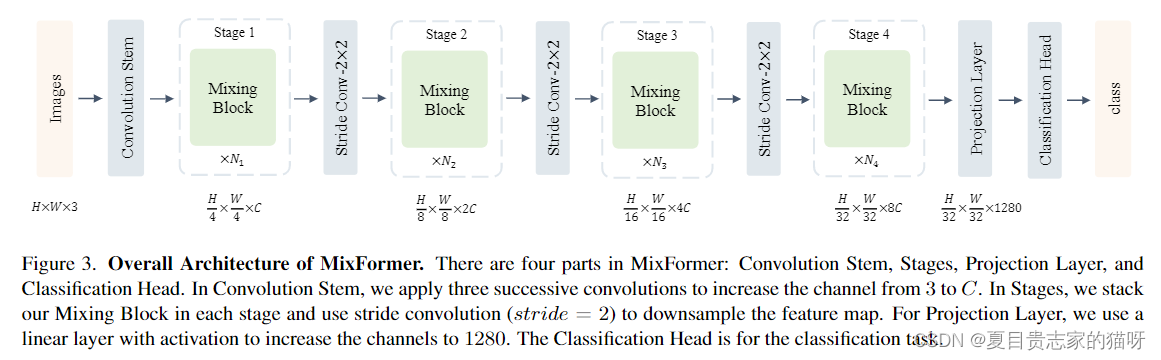
卷积Stem是由三个卷积层组成的,将通道数从3增加到C。一个Stage中,堆叠了不同数量的Mixing Block。Stride Conv的步长是2,是用来进行下采样的。Projection Layer中使用的是Linear layer和激活函数将通道数增加到1280,这里猜测Linear layer应该就是1x1卷积。1280x1x1x8c的卷积核。














 1657
1657











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









