







稀疏奖励
出现的原因:训练agent的时候,多数时候agent获取不到reward,没有奖励或惩罚,乱探索什么也学不到【这是不是奖惩设置不合理的一种体现??】
解决方案:
Reward Shaping
Reward shaping 的思想是说环境有一个固定的 reward,它是真正的 reward,但是为了让 agent 学出来的结果是我们要的样子,我们刻意地设计了一些 reward 来引导我们的 agent。
存在问题:
什么 reward shaping 有帮助,什么 reward shaping 没帮助,会变成一个 domain knowledge【领域知识】,要自己去调参数
通用可有用的设计 reward (刻意设计的)
1. curiosity(curiosity driven reward)
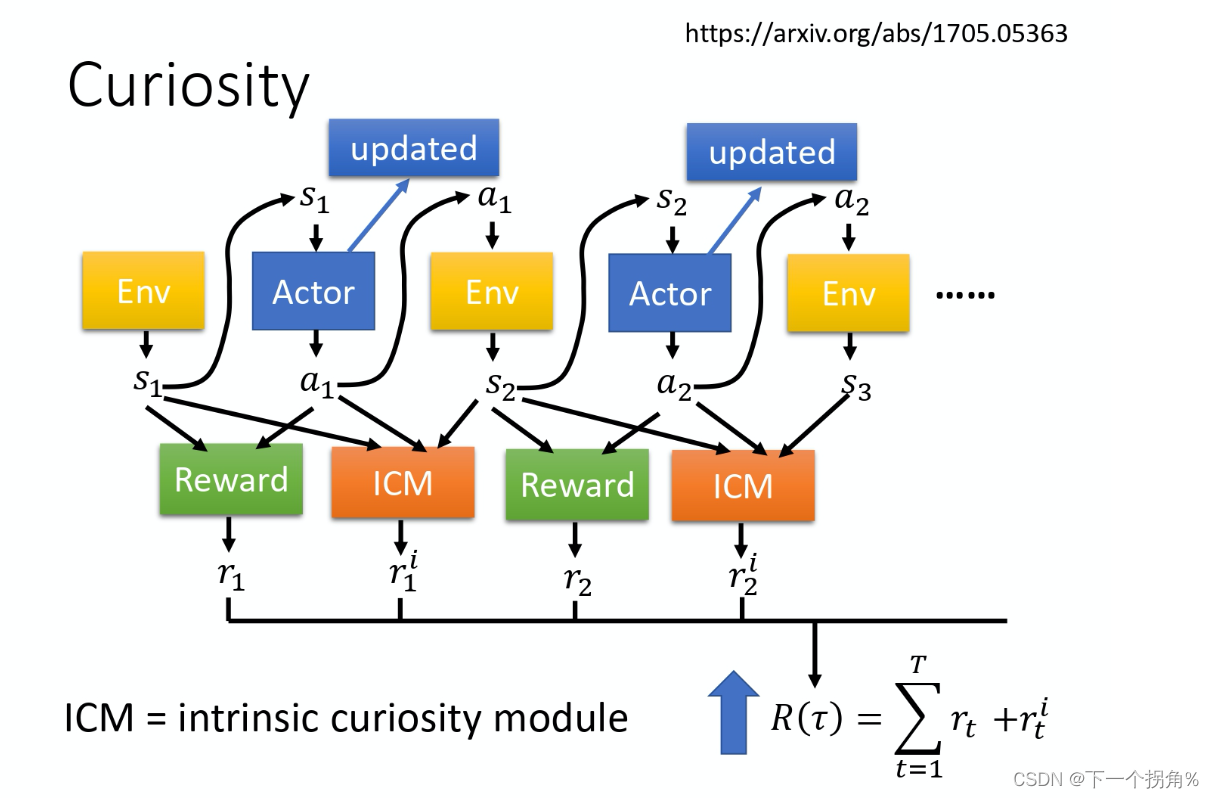
总奖励 = r1+r1i , r1i 称为ICM(intrinsic curiosity module),希望这两个奖励越大越好,ICM就是curiosity,r1i 设计模型:

意思是: 紫色Network1输入at、st,会输出一个预测的s_t+1,和下时刻的真实s_t+1 比较,差距奖励越大,意味着如果未来的 state 越难被预测的话,那得到的 reward 就越大。这就是鼓励 machine 去冒险,增加 machine exploration 的能力。
同时 处理一点 问题是:状态差的大但是不能和要做的事情无关,所以要过滤掉一些状态,做法是绿色Network2 ,用 ϕ(st)、ϕ(st+1) 预测 action,预测的a-t和之前实际输入的a_t要尽可能接近。所以,今天我们抽出来的 feature 跟预测 action 这件事情是有关的。
2.curriculum learning
在 machine learning,尤其是 deep learning 里面用到的概念,思想就是 给training data 的时候 由简单到复杂,类比人学习课程由初级到高级。
比较通用方法-- Reverse Curriculum Generation:
思想是 有最后的目标gold state 去反推 离他近的state 可以完成的同时删除掉极端的case超容易到达的state和超难到达的state。前半部分思想类似于动态规划的反推【个人感觉】

3.Hierarchical RL
分层强化学习是指将一个复杂的强化学习问题分解成多个小的、简单的子问题,每个子问题都可以单独用马尔可夫决策过程来建模。【问题拆解】思想【类似动态规划拆解成子问题】
这样,我们可以将智能体的策略分为高层次策略和低层次策略,高层次策略根据当前状态决定如何执行低层次策略。这样,智能体就可以解决一些非常复杂的任务。














 412
412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









