本章展现了操作系统一系列功能:
通过 批处理 支持多个程序的自动加载和运行。 操作系统利用硬件 特权级机制 ,实现对操作系统自身的保护。 背景: 批处理系统 (Batch System) 多个程序 打包到一起输入计算机,而当一个程序运行结束后,计算机会 自动加载下一个程序 到内存并开始执行。这便是最早的真正意义上的操作系统。程序总是难免出现错误。但人们希望一个程序的错误不要影响到操作系统本身,它只需要 终止出错的程序,转而继续运行执行序列中的下一个程序即可。如果后面的程序都无法运行就太糟糕了。这种 保护 操作系统不受有意或无意出错的程序破坏的机制 被称为 特权级 (Privilege) 机制 实现了用户态和内核态的隔离 ,需要 软件和硬件 的共同努力。 本章我们的主要目的也是设计一个批处理的操作系统,毕竟将待执行的程序嵌入main.c之中是十分粗暴的,也不符合我们对操作系统的认知。这同时也意味着我们将开始使用独立的测例文件,并把它们打包到os之中。 为了保护的批处理操作系统不受到出错应用程序的影响 并全程稳定工作,单凭软件实现是很难做到的,而是 需要 CPU 提供一种特权级隔离机制,使CPU在执行应用程序和操作系统内核的指令时处于不同的特权级 。本节主要介绍了特权级机制的软硬件设计思路,以及RISC-V的特权级架构,包括特权指令的描述。 背景 目的 让相对安全可靠的操作系统不受到应用程序的破坏,运行在一个安全的执行环境中,而让应用程序运行在一个无法破坏操作系统的执行环境中。 原则1. 应用程序不能执行某些可能破会计算机系统的指令 (本章的重点)2. 应用程序不能访问任意的地址空间 (这个在第四章会进一步讲解,本章不会讲解) 低特权级软件都只能做高特权级软件允许它做的,且低特权级软件的超出其能力的要求必须寻求高特权级软件的帮助 。在这里的 高特权级软件就是低特权级软件的软件执行环境 。 方法设置两个不同安全等级的执行环境 :用户态特权级的执行环境 内核态特权级的执行环境 内核态特权级指令子集中的指令只能在内核态特权级的执行环境中执行,如果在用户态特权级的执行环境中执行这些指令,会产生异常 。处理器在执行不同特权级的执行环境下的指令前进行 特权级安全检查 具体实现ecall 执行环境调用(Execution Environment Call) 用户态到→内核态的执行环境切换 能力的函数调用指令(RISC-V中就有这条指令)。eret 执行环境返回(Execution Environment Return) 内核态到→用户态的执行环境切换 能力的函数返回指令(RISC-V中有类似的 sret 指令)。 在实际的CPU,如x86、RISC-V等,设计了多达4种特权级。对于一般的操作系统而言,其实只要两种特权级就够了。RISC-V 架构中一共定义了 4 种特权级: 级别的数值越大,特权级越高,掌控硬件的能力越强 。例如:M 模式就处在最高的特权级,而 U 模式处于最低的特权级。 级别 编码 名称 0 00 用户/应用模式 (U , User/Application) 1 01 监督模式 (S , Supervisor) 2 10 H , Hypervisor3 11 机器模式 (M , Machine)
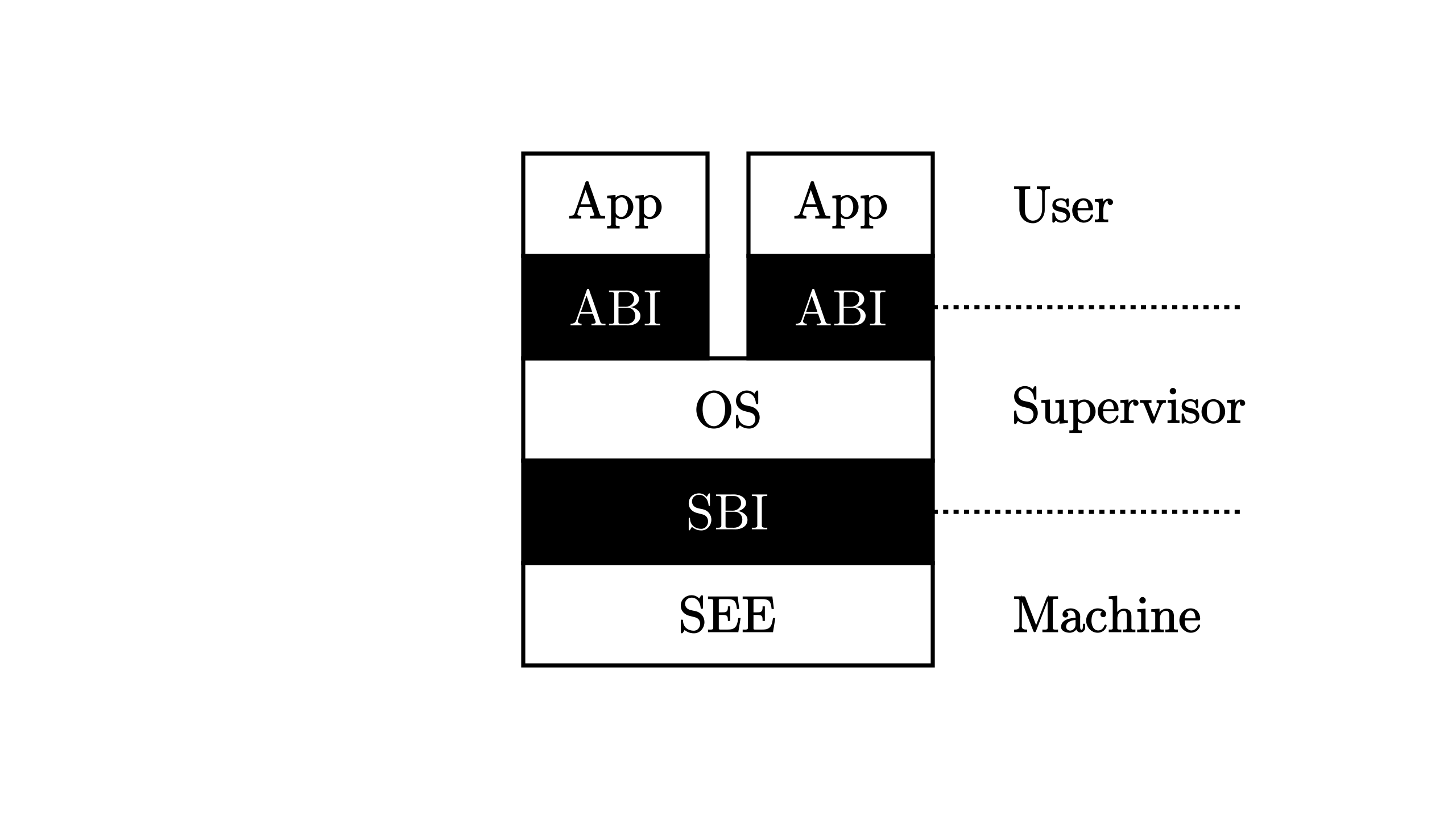
下图是支持应用程序运行的一套 执行环境栈 ,现在我们站在特权级架构的角度去看待它:其中,白色块表示一层执行环境,黑色块表示相邻两层执行环境之间的接口。
OS 内核代码 运行在 S (Supervisor) 监督模式上 ; APP 应用程序 运行在 U (User/Application) 用户/应用模式模式上 。 监督模式执行环境 (SEE, Supervisor Execution Environment) 运行在 M(Mashine)机器模式上 ,这是站在运行在 S 模式上的软件的视角来看,它的下面也需要一层执行环境支撑,因此被命名为 SEE,它需要在相比 S 模式更高的特权级下运行, 一般情况下在 M 模式上运行。 按需实现 RISC-V 特权级 RISC-V 架构中,只有 M 模式是必须实现的,剩下的特权级则可以根据跑在 CPU 上应用的实际需求进行调整 :
简单的嵌入式应用只需要实现 M 模式; 带有一定保护能力的嵌入式系统需要实现 M/U 模式; 复杂的多任务系统则需要实现 M/S/U 模式。 到目前为止,(Hypervisor, H)模式的特权规范还没完全制定好,所以暂时不会涉及。 执行环境的其中一种功能是在执行它支持的上层软件之前进行一些初始化工作。我们之前提到的引导加载程序会在加电后对整个系统进行 初始化,它实际上是 SEE 功能的一部分,也就是说 在 RISC-V 架构上引导加载程序一般运行在 M 模式上 。此外,编程语言的标准库也会在执行程序员 编写的逻辑之前进行一些初始化工作,但是在这张图中我们并没有将其展开,而是统一归类到 U 模式软件,也就是应用程序中。
简单的支持单个裸机应用的库级别的“三叶虫”操作系统 和应用程序全程运行在 S 模式下,应用程序很容易破坏没有任何保护的执行环境–操作系统。 在后续的章节中,我们会涉及到RISC-V的 M/S/U 三种特权级:其中应用程序和用户态支持库运行在 U 模式的最低特权级;操作系统内核运行在 S 模式特权级(在本章表现为一个简单的批处理系统),形成支撑应用程序和用户态支持库的执行环境;而第一章提到的预编译的 bootloader – RustSBI 实际上是运行在更底层的 M 模式特权级下的软件,是操作系统内核的执行环境。整个软件系统就由这三层运行在不同特权级下的不同软件组成。 在特权级相关机制方面,本书正文中我们重点关心RISC-V的 S/U 特权级, M 特权级的机制细节则是作为可选内容在 深入机器模式:RustSBI 中讲解,有兴趣的读者可以参考。
执行环境的另一种功能是对上层软件的执行进行 监控管理 上层软件执行的时候出现了一些情况导致需要用到执行环境中提供的功能, 因此需要暂停上层软件的执行,转而运行执行环境 的代码。由于上层软件和执行环境被设计为运行在不同的特权级,这个过程也往往(而 不一定 ) 伴随着 CPU 的 特权级切换,当执行环境的代码运行结束后,我们需要返回到上层软件暂停的位置继续执行。在 RISC-V 架构中,这种与常规控制流 (顺序、循环、分支、函数调用)不同的 异常控制流 (ECF, Exception Control Flow) 异常 (Exception 用户态应用直接触发从用户态到内核态的 异常控制流 的原因 总体上可以分为两种:执行 Trap类异常 指令和执行了会产生 Fault类异常 的指令 。Trap类异常 用户态软件为获得内核态操作系统的服务功能而发出的特殊指令 。 Fault类异常 用户态软件执行了在内核态操作系统看来是非法操作的指令 。下表中我们给出了 RISC-V 特权级定义的会导致从低特权级到高特权级的各种 异常: Interrupt Exception Code Description 0 0 Instruction address misaligned 0 1 Instruction access fault 0 2 Illegal instruction 0 3 Breakpoint 0 4 Load address misaligned 0 5 Load access fault 0 6 Store/AMO address misaligned 0 7 Store/AMO access fault 0 8 Environment call from U-mode 0 9 Environment call from S-mode 0 11 Environment call from M-mode 0 12 Instruction page fault 0 13 Load page fault 0 15 Store/AMO page fault
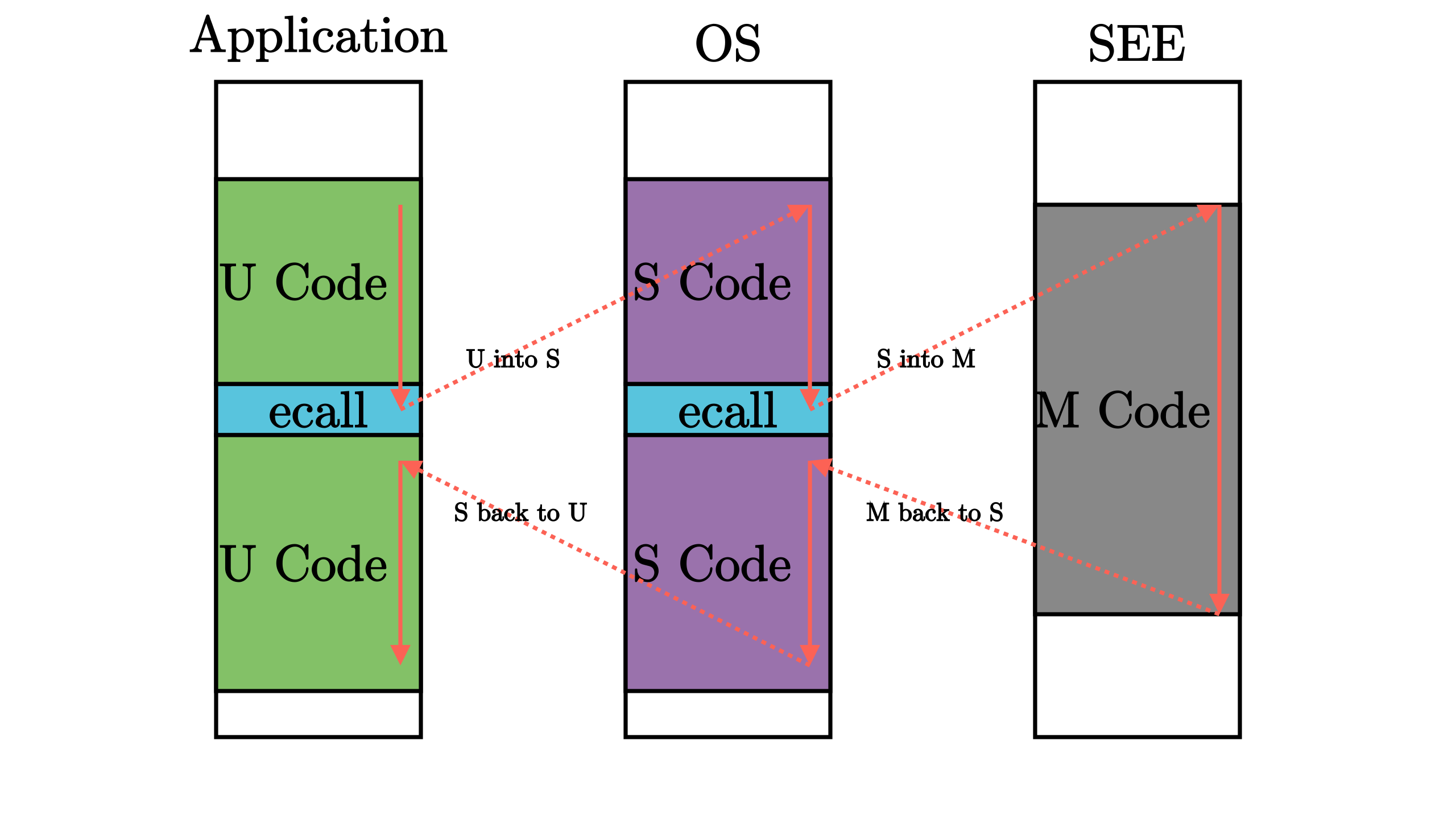
Breakpoint断点和 Environment call执行环境调用 两个异常(为了与其他非有意为之的异常区分,会把这种 有意为之 的指令称为 陷入 trap 类指令 执行环境调用 ecall 指令的应用其中,M 模式软件 SEE 和 S 模式的内核之间的接口被称为 监督模式二进制接口 (Supervisor Binary Interface, SBI) 而内核和 U 模式的应用程序之间的接口被称为 应用程序二进制接口 (Application Binary Interface, ABI) 系统调用 (syscall, System Call) 只有将接口下降到汇编指令级才能够满足其通用性和灵活性 。 可以看到,在这样的架构之下,每层特权级的软件都只能做高特权级软件允许它做的、且不会产生什么撼动高特权级软件的事情,一旦低特权级软件的要求超出了其能力范围, 就必须寻求高特权级软件的帮助 。因此,在一条执行流中我们经常能够看到特权级切换。如下图所示: 其他的异常则一般是在 执行某一条指令的时候发生了某种错误 (如除零、无效地址访问、无效指令等),或处理器认为处于当前特权级下执行当前指令是高特权级指令或会访问不应该访问的高特权级的资源(可能危害系统)。碰到这些情况,就需要需要 将控制转交给高特权级的软件(如操作系统)来处理 。当处理错误恢复后,则可重新回到低优先级软件去执行;如果不能回复错误,那高特权级软件可以杀死和清除低特权级软件,免破坏整个执行环境。 与特权级无关的一般的指令和通用寄存器 x0~x31 在任何特权级都可以任意执行 。而每个特权级都对应一些特殊指令和 控制状态寄存器 (CSR, Control and Status Register),来控制该特权级的某些行为并描述其状态,当然特权指令不只是具有有读写 CSR 的指令,还有其他功能的特权指令。如果低优先级下的处理器执行了高优先级的指令,会产生非法指令错误的异常,于是位于高特权级的执行环境能够得知低优先级的软件出现了该错误,这个错误一般是不可恢复的,此时一般它会 将上层的低特权级软件终止 。这在某种程度上体现了特权级保护机制的作用。 在RISC-V中,会有 两类低优先级U模式下运行高优先级S模式的指令 :
指令本身属于 高特权级的指令 ,如 sret 指令(表示从S模式返回到U模式)。 指令访问了 S模式特权级下才能访问的寄存器 或内存 ,如表示S模式系统状态的 控制状态寄存器 sstatus 等。 RISC-V S模式特权指令 含义 sret 从S模式返回U模式。在U模式下执行会产生非法指令异常 wfi 处理器在空闲时进入低功耗状态等待中断。在U模式下执行会尝试非法指令异常 sfence.vma 刷新TLB缓存。在U模式下执行会尝试非法指令异常 访问S模式CSR的指令 通过访问 sepc/stvec/scause/sscartch/stval/sstatus/satp等CSR 来改变系统状态。在U模式下执行会尝试非法指令异常
在下一节中,我们将看到 在U模式下的用户态应用程序 ,如果执行S模式特权指令,将会产生非法指令异常,从而看出RISC-V的特权模式设计在一定程度上提供了对操作系统的保护。 本节主要讲解如何设计实现被批处理系统逐个加载并运行的应用程序,它们是假定在 U 特权级模式运行的前提下而设计、编写的。实际上,如果应用程序的代码都符合它要运行的某特权级的约束,那它完全可能在某特权级中运行。保证应用程序的代码在 U 模式运行是我们接下来将实现的批处理系统的任务,其涉及的设计实现要点是:
测例实际就是批处理操作系统中一个个待执行的文件。我们的测例是 通过cmake来编译 的。具体编译出测例的指令可以参见其中的readme。 下面我们看一个测例来理解本章以及之后测例的本质:
# include <stdio.h> # include <unistd.h> int main ( void )
{
puts ( "Hello world from user mode program!\nTest hello_world OK!" ) ;
return 0 ;
}
在使用测例的时候要注意,由于我们使用的是 自己的os系统 ,因此所有常见的C库,比如stdlib.h,stdio.h等等都 不能使用C官方的版本 。因此,在user的include和lib之中我们提供了搭配本次实验的对应库 ,里面实现了所有测例所需要的函数。大家可以看到,所有测例代码调用的函数都是使用的这里的代码 ,而 这些函数会依赖我们编写的os提供的 系统调用(syscall) 来完成运行 。 user的库是如何调用到os的系统调用的呢?syscall_arch.h 包装好了使用riscv汇编调用系统调用ecall的函数接口 。lib之中的 syscall.c 用这些包装好的函数来进行系统调用实现完整的函数功能 。 在第一章中大家已经了解了异常委托的机制。U态的ecall指令会转到S态,也就是我们编写的os来进行处理,这样整个逻辑就打通了:为了使得测例成功运行,我们必须实现处理对应ecall的函数。 现在我们还面临一个理解上的问题,那就是测例文件在调用ecall的时候的细节: ecall 作为异常的一种,操作系统和CPU对它的处理方式其实和其他各种异常没什么区别。U态进行ecall调用具体的异常编号是8-Environment call from U-mode 。 RISCV处理异常需要引入几个特殊的寄存器——CSR 控制状态寄存器 (Control and Status Register) 记录异常和中断处理流程所需要或保存的各种信息 。几个比较关键的CSR寄存器如下(需要注意的是下面这些寄存器是S态的CSR寄存器,M态还有一套自己的CSR寄存器mcause,mtvec等):
scause: 它用于 记录异常和中断的原因 。它的最高位为1是中断,否则是异常;其低位决定具体的种类。 sepc:处理完毕中断异常之后 需要返回的PC值 。 stval: 产生 异常的指令的地址 。 stvec:处理异常的函数的起始地址 。 sstatus:记录一些比较重要的状态 。比如是否允许中断异常嵌套。 当U态执行ecall指令的时候就 产生了异常 跳转至stvec所指向的地址(也就是异常处理函数) uservec函数 在uservec函数之中,Ucore操作系统 保存了U态执行流的各个寄存器的值,这些值的位置其实已经由trap.h中的 trapframe结构体
struct trapframe {
uint64 kernel_satp;
uint64 kernel_sp;
uint64 kernel_trap;
uint64 epc;
uint64 kernel_hartid;
uint64 ra;
uint64 sp;
. . . .
uint64 t5;
uint64 t6;
} ;
由于涉及到直接操作寄存器,因此这里只能使用汇编语言来编写。具体可以参考下面trampoline.S之中的代码:
这里需要注意 sscratch (属于CSR寄存器) 就是一个cache缓存 ,它只负责存某一个值,这里它 保存的就是上面trapframe 结构体的位置 。 csrr和csrrw指令是RV特供的读写CSR寄存器的指令,我们取用它的值的时候实际把原来a0的值和sscratch的值交换了,因此返回时大家可以看到我们会再交换一次得到原来的a0。这里注释了的两句代码是页表相关的处理,我们在第四章会仔细了解它。 代码最后我们使用jr t0指令,就跳转到了我们早先设定在 trapframe->kernel_trap 中的地址,也就是 trap.c 之中的 usertrap 函数 完成异常中断处理与返回 ,包括执行我们写好的syscall。 . section . text
. globl trampoline
trampoline:
. align 4
. globl uservec
uservec:
#
# trap . c sets stvec to point here, so# traps from user space start here, # in supervisor mode, but with a # user page table. # sscratch points to where the process' s p-> trapframe is # mapped into user space, at TRAPFRAME. # swap a0 and sscratch # so that a0 is TRAPFRAME , sscratch, a0
# save the user registers in TRAPFRAME , 40 ( a0)
. . .
sd t6, 280 ( a0)
# save the user a0 in p-> trapframe-> a0 , sscratch
sd t0, 112 ( a0)
csrr t1, sepc
sd t1, 24 ( a0)
ld sp, 8 ( a0)
ld tp, 32 ( a0)
ld t1, 0 ( a0)
# csrw satp, t1 # sfence . vma zero, zero, 16 ( a0)
jr t0
trapinit 这个函数在main的初始化之中已经调用了。
void trapinit ( void )
{
w_stvec ( ( uint64) uservec & ~ 0x3 ) ;
}
从S态返回U态 是由 usertrapret 函数 void usertrapret ( struct trapframe * trapframe, uint64 kstack)
{
trapframe-> kernel_satp = r_satp ( ) ;
trapframe-> kernel_sp = kstack + PGSIZE;
trapframe-> kernel_trap = ( uint64) usertrap;
trapframe-> kernel_hartid = r_tp ( ) ;
w_sepc ( trapframe-> epc) ;
uint64 x = r_sstatus ( ) ;
x &= ~ SSTATUS_SPP;
x |= SSTATUS_SPIE;
w_sstatus ( x) ;
userret ( ( uint64) trapframe) ;
}
userret 函数userret 函数 将保存在 trapframe结构体 之中的数据依次读出用于恢复对应的寄存器,实现恢复用户中断前的状态 。需要注意最后执行的 sret 指令执行了2个事情:从S态回到U态,并将PC程序计数寄存器移动到sepc指定的位置,继续执行用户程序。 . globl userret
userret:
# userret ( TRAPFRAME, pagetable) # switch from kernel to user. # usertrapret ( ) calls here. # a 0 : TRAPFRAME, in user page table. # a 1 : user page table, for satp. # switch to the user page table. 在第四章才会有具体作用。 , a1
sfence. vma zero, zero
# put the saved user a0 in sscratch, so we # can swap it with our a0 ( TRAPFRAME) in the last step. , 112 ( a0)
csrw sscratch, t0
# restore all but a0 from TRAPFRAME , 40 ( a0)
ld sp, 48 ( a0)
ld gp, 56 ( a0)
ld tp, 64 ( a0)
ld t0, 72 ( a0)
ld t1, 80 ( a0)
ld t2, 88 ( a0)
. . .
ld t4, 264 ( a0)
ld t5, 272 ( a0)
ld t6, 280 ( a0)
# restore user a0, and save TRAPFRAME in sscratch , sscratch, a0
# return to user mode and user pc. # usertrapret ( ) set up sstatus and sepc. 前面一节中我们明白了os是如何执行应用程序的。但是os是如何”找到“这些应用程序并允许它们的呢?在之前我们简要介绍了这是由link_app.S以及kernel_app.ld完成的。实际上,能够 在批处理操作系统与应用程序之间建立联系 的纽带。这主要包括两个方面:
静态编码 编程技巧 ,把应用程序代码和批处理操作系统代码“绑定”在一起。动态加载 基于静态编码留下的“绑定”信息 ,操作系统可以找到应用程序文件二进制代码的起始地址和长度,并能加载到内存中运行。 这里与硬件相关且比较困难的地方是如何 让在内核态的批处理操作系统启动应用程序,且能让应用程序在用户态正常执行 。 我们首先看一看本章的makefile改变了什么: link_app. o: link_app. S
link_app. S: pack. py
@$( PY) pack. py
kernel_app. ld: kernelld. py
@$( PY) kernelld. py
kernel: $( OBJS) kernel_app. ld link_app. S
$( LD) $( LDFLAGS) - T kernel_app. ld - o kernel $( OBJS)
$( OBJDUMP) - S kernel > kernel. asm
$( OBJDUMP) - t kernel | sed '1 , / SYMBOL TABLE/ d; s/ . * / / ; / ^ $$/ d' > kernel. sym
. align 4
. section . data
. global _app_num
_app_num:
. quad 2
. quad app_0_start
. quad app_1_start
. quad app_1_end
. global _app_names
_app_names:
. string "hello.bin"
. string "matrix.bin"
. section . data. app0
. global app_0_start
app_0_start:
. incbin "../user/target/bin/ch2t_write0.bin"
. section . data. app1
. global app_1_start
app_1_start:
. incbin "../user/target/bin/ch2b_write1.bin"
app_1_end:
pack.py将该目录下的目标用户程序*.bin包含入 link_app.S中,同时给每一个bin文件记录其地址和名称信息 。最后,我们在 Makefile 中会将内核与 link_app.S 一同编译并链接 。这样,我们在内核中就可以通过 extern 指令访问到用户程序的所有信息,如其文件名等。 kernelld.py遍历…/user/target/,并对每一个bin文件分配对齐的空间 。最终修改后的kernel_app.ld脚本中多了如下对齐要求: . data : {
* ( . data)
. = ALIGN ( 0x1000 ) ;
* ( . data. app0)
. = ALIGN ( 0x1000 ) ;
* ( . data. app1)
. = ALIGN ( 0x1000 ) ;
* ( . data. app2)
. = ALIGN ( 0x1000 ) ;
* ( . data. app3)
. = ALIGN ( 0x1000 ) ;
* ( . data. app4)
* ( . data. * )
}
编译出的kernel已经包含了bin文件的信息。熟悉汇编的同学可以去看看生成的kernel.asm(kernel整体的汇编代码)来加深理解。 内核中通过访问 link_app.S 中定义的 _app_num、app_0_start 等符号来获得用户程序位置。
extern char _app_num[ ] ;
void batchinit ( ) {
app_info_ptr = ( uint64* ) _app_num;
app_num = * app_info_ptr;
app_info_ptr++ ;
}
然而我们并不能直接跳转到 app_n_start 直接运行,因为用户程序在编译的时候,会假定程序处在虚存的特定位置,而由于我们还没有虚存机制,因此我们在 运行之前还需要将用户程序加载到规定的物理内存位置 。为此我们 规定了用户的链接脚本,并在内核完成程序的 “搬运” 。这样之后,我们就可以在读取指定内存位置的bin文件来执行它们了。 # user / lib/ arch/ riscv/ user. ld{
. = 0x80400000 ; # 规定了内存加载位置
. startup : {
* crt. S. o ( . text) # 确保程序入口在程序开头
}
. text : { * ( . text) }
. data : { * ( . data . rodata) }
/ DISCARD/ : { * ( . eh_* ) }
}
下面是os内核读取link_app.S的info并把它们搬运到0x80400000开始位置的具体过程:
const uint64 BASE_ADDRESS = 0x80400000 , MAX_APP_SIZE = 0x20000 ;
int load_app ( uint64* info) {
uint64 start = info[ 0 ] , end = info[ 1 ] , length = end - start;
memset ( ( void * ) BASE_ADDRESS, 0 , MAX_APP_SIZE) ;
memmove ( ( void * ) BASE_ADDRESS, ( void * ) start, length) ;
return length;
}
操作系统内核运行时需要一个栈来存放自己需要的变量 ,这个栈我们称之为 内核栈 在RV之中,我们使用sp寄存器来记录当前栈顶的位置 。因此,在进入OS之前,我们需要告诉qemu我们的操作系统内核栈的起始位置,这个在entry.S之中有实现:
_entry:
la sp, boot_stack_top
call main
. section . bss. stack
. globl boot_stack
boot_stack:
. space 4096 * 16
. globl boot_stack_top
一个应用程序肯定也需要内存空间来存放执行时需要的种种变量 ,也就是执行程序对应的 用户栈 那么OS是如何给应用程序分配这些对应的空间的呢?采用一个静态分配的方式来给程序分配对应的一定大小的空间 ,并在run_next_app函数初始化应用程序对应的 trapframe结构体 ,并 将用户栈对应的起始位置写入trapframe之中的sp寄存器,来让程序找到自己用户栈起始的位置 。(注意栈在空间是高到低位,因此这里起始位置的初始化是在静态分配数组的尾部)。
__attribute__ ( ( aligned ( 4096 ) ) ) char user_stack[ USER_STACK_SIZE] ;
__attribute__ ( ( aligned ( 4096 ) ) ) char trap_page[ TRAP_PAGE_SIZE] ;
int run_next_app ( )
{
struct trapframe * trapframe = ( struct trapframe * ) trap_page;
. . .
memset ( trapframe, 0 , 4096 ) ;
trapframe-> epc = BASE_ADDRESS;
trapframe-> sp = ( uint64) user_stack + USER_STACK_SIZE;
usertrapret ( trapframe, ( uint64) boot_stack_top) ;
. . .
}
到这里,一个应用程序就算真正完全加载进入了内存之中进入就绪状态,可以随时运行了。 相比于上一章的操作系统,本章操作系统有两个最大的不同之处,一个是支持应用程序在用户态运行,且能完成应用程序发出的系统调用;另一个是能够一个接一个地自动运行不同的应用程序。所以,我们需要对操作系统和应用程序进行修改,也需要对应用程序的编译生成过程进行修改。 首先改进应用程序,让它能够在用户态执行,并能发出系统调用,这其实就是上一章中 构建用户态执行环境 小节介绍内容的进一步改进。具体而言,编写多个应用小程序,修改编译应用所需的 linker.ld 文件来 调整程序的内存布局 ,让操作系统能够把应用加载到指定内存地址后顺利启动并运行应用程序 。 应用程序运行中,操作系统要支持应用程序的输出功能,并还能支持应用程序退出,这需要完成 sys_write 和 sys_exit 系统调用访问请求的实现。 具体实现涉及到内联汇编的编写,以及应用与操作系统内核之间系统调用的参数传递的约定。 写完应用程序后,还需实现支持多个应用程序轮流启动运行的操作系统。
这里首先能把本来相对松散的应用程序执行代码和操作系统执行代码连接在一起,便于 qemu-system-riscv64 模拟器一次性地加载二者到内存中,并让操作系统能够找到应用程序的位置。 为把二者连在一起,需要对生成的应用程序进行改造,首先是把应用程序执行文件从ELF执行文件格式变成Binary格式(通过 rust-objcopy 可以轻松完成);scripts/kernellld.py来生一个新的规定程序空间的kernel_app.ld取代之前的kernel.ld。 操作系统本身需要完成对Binary应用的位置查找,找到后 (通过 os/link_app.S 中的变量和标号信息完成),会把Binary应用拷贝到 os/kernel_app.ld 指定的物理内存位置 (OS的加载应用功能)。为了让Binary应用能够启动和运行,操作系统还需给Binary应用 分配好执行环境所需一系列的资源,这主要包括设置好用户栈和内核栈 (在应用在用户态和内核在内核态需要有各自的栈),实现Trap 上下文的保存与恢复 (让应用能够在发出系统调用到内核态后,还能回到用户态继续执行),完成Trap 分发与处理等工作。
























 904
904











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











