







C++ 命名空间
其实在C语言中也有命名空间这一说法,只是在C语言中只有全局和函数的命名空间,就是在各自的作用域中使用同名变量、函数等等都不会受到影响。而在C++中,为了避免同名变量、函数、类等的冲突,引入了命名空间,目的是对标识符的名称进行本地化。
如何定义和使用命名空间
命名格式:
namespace 命名空间名称
{变量 + 函数}
定义命名空间的三种方式
1、普通的命名空间
namespace N1
{
int a = 1;
void fun1()
{
printf("N1: fun1()\n");
}
}
2、嵌套的命名空间
namespace N1
{
int a = 1;
void fun1()
{
printf("N1: fun1()\n");
}
//嵌套的命名空间
namespace N2
{
int a = 1;
void fun1()
{
printf("N1: fun1()\n");
}
}
}
3、分段命名空间
namespace N1
{
int a = 1;
void fun1()
{
printf("N1: fun1()\n");
}
}
//同一个工程中允许存在多个相同名称的命名空间,编译器最后会合成同一个命名空间中。
namespace N1
{
int b = 2;
void fun2()
{
printf("N1: fun2()\n");
}
}
使用命名空间也有三种方式
一个命名空间就定义了一个新的作用域,命名空间中的所有内容都局限于该命名空间中。
为了减少冗余,将命名空间N1的定义拿出来:
namespace N1
{
int a = 1;
void fun1()
{
printf("N1: fun1()\n");
}
}
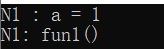
1、加命名空间名称及作用域限定符::
int main()
{
printf("N1 : a = %d\n", N1::a);
N1::fun1();
return 0;
}
运行结果:
2、使用using将命名空间中成员引入
using N1::a;
using N1::fun1;
int main()
{
//using N1::a;
//using N1::fun1;
printf("N1 : a = %d\n", a);
fun1();
return 0;
}
运行结果:
3、使用using namespace 命名空间名称引入
using namespace N1;
int main()
{
//using namespace N1;通常放到函数之前或者与头文件放一起
printf("N1 : a = %d\n", a);
fun1();
return 0;
}
运行结果:
在工作写大项目时尽量少用第三种使用方法,全部展开后,所有成员都暴露在全局作用域中,会与全局变量等造成命名冲突。而在平时的练习学习当中,建议全部展开。命名是我们自己命名,我们知道会不会造成命名冲突,而且我们练习的程序代码往往不会太大。
C++ 输入与输出
在C语言中,我们通常要输出一个变量和一段字需要用到printf()函数,在printf函数中需要指定变量的格式,输入一个变量的scanf函数也是需要指定格式。而在C++中,有两个流,分别是输出流cout和输入流cin。这两个在C++中替代了printf和scanf,之所以替代,是因为这两个的功能强于printf和scanf函数。接下来我们看看如何使用cout和cin。
使用cout函数和cin函数都必须要导入头文件<iostream>,注意,这里是没有以.h结尾,这也是C和C++头文件的区别。而在C++中,所有C++头文件中所定义的函数都属于命名空间std中,所以在使用的时候我们都必须导入头文件和使用相对应的命名空间
#include <iostream>
using namespace std;
int main()
{
int a = 10;
//cout支持连续输出,输出顺序丛左往右
//endl:end line相当于c语言中的换行
cout << "a = " << a << endl; // a = 10
return 0;
}
而对于初学者来说,可能箭头的指向会混乱,我们可以把cout看成是控制台,后面的内容都留进cout,相当于流进控制台,箭头指向控制台<<。打印相对应的内容。
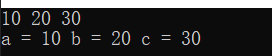
#include <iostream>
using namespace std;
int main()
{
int a, b, c;
//cin支持连续输出,输出顺序丛左往右
cin >> a >> b >> c ;
cout << "a = " << a << " b = " << b << " c = " << c << endl;
return 0;
}
运行结果:
C++ 缺省参数
C++中的缺省参数,用“备胎”来形容,是最好不过的了。

在C++中,声明或者定义函数时,函数的参数可以给予一个默认值,在调用该函数时如果没有指定实参,在执行函数时会使用默认值。如果指定了实参,这执行函数时会使用指定的实参,这是不是和“备胎”这词意思太相近了。
我们来看以下代码:
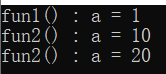
#include <iostream>
using namespace std;
void fun1(int a)
{
cout << "fun1() : a = " << a << endl;
}
void fun2(int a = 10)
{
cout << "fun2() : a = " << a << endl;
}
int main()
{ //没有缺省值必须传参
fun1(1);
//有缺省值可以不传参
fun2();
//有缺省值还传参,使用指定的参数
fun2(20);
return 0;
}
执行结果:
缺省参数分为两类:全缺省和半缺省
全缺省:函数中的参数都给了默认值,即使一个参数也不传也不会报错。
半缺省:函数中的参数有些给了默认值,有些没给。没给默认值的参数必须再传参。
在全缺省中,如果要指定参数,必须是从左往右依次指定。
//全缺省
void fun1(int a = 1, int b = 2, int c = 3)
{
cout << "fun1() : a = " << a << " b = " << b << " c = " << c << endl;
}
int main()
{
fun1();
fun1(10);
fun1(10, 20);
fun1(10, 20, 30);
return 0;
}
运行结果:
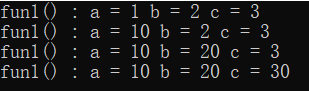
半缺省函数代码实例:
void fun1(int a, int b, int c = 3)
{
cout << "fun1() : a = " << a << " b = " << b << " c = " << c << endl;
}
int main()
{
fun1(10,20);
fun1(10, 20, 30);
return 0;
}
运行结果:

注意:
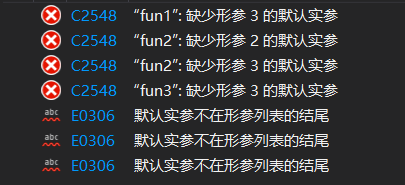
1、在半缺省函数中,缺省的顺序必须是从右往左且连续。
//以下函数都不会通过编译
void fun1(int a, int b = 2, int c){}//不连续
void fun2(int a = 1, int b, int c){}//没有从右向左
void fun3(int a = 1, int b = 2, int c){}
报错结果:
2、缺省参数不能同时出现在声明和定义当中,只能出现在一处,否则编译器无法识别默认值。
//未通过编译
void fun(int a = 1);
void fun(int a = 10){}
报错结果:

3、缺省值支持常量和全局变量
int num = 20;
void fun(int a = num)
{
cout << "a = " << a << endl;
}
int main()
{
fun(); //输出 a = 20
return 0;
}
4、在C语言中不支持缺省参数
C++函数重载
函数重载,可以简单理解为“一词多意”。
函数重载:函数重载是用来描述同名函数具有相同或者相似功能,但是参数个数或者类型顺序不一样的函数管理操作。
在C语言中,我们写的相加函数:
int AddInt(int a, int b)
{
return a + b;
}
char AddChar(char a, char b)
{
return a + b;
}
double AddDouble(double a, double b)
{
return a + b;
}
在这里我们可以看到,他们的功能都是相加两个变量的值,但是他们的函数名不同。因为他们的功能相同,那么我们能不能让它们的函数名都相同呢,无论我们调用什么类型的函数,只要调用Add()函数,并传入我们想要相加的值就可以得到结果呢?
答案是可以的,在C++中,函数支持重载。
我们来看一下下面的代码:
int Add(int a, int b)
{
return a + b;
}
char Add(char a, char b)
{
return a + b;
}
double Add(double a, double b)
{
return a + b;
}
int main()
{
int a = 1, b = 2;
cout << "a + b = " << Add(a, b) << endl;
char c = 'A', d = '!';
cout << "c + d = " << Add(c, d) << endl;
double e = 1.01, f = 2.02;
cout << "e + f = " << Add(e, f) << endl;
return 0;
}
运行结果:
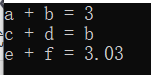
这就达到了我们无论什么类型都只要调用Add()函数,都会相加两个值。
我们知道函数重载可以是函数的参数类型不同,参数的顺序不同也可以构成重载,当传入的参数顺序不同时,编译器可以自动识别参数类型,调用相对应参数类型的函数,实例如下代码:
void fun(int a, char c)
{
cout << "fun(int, char)" << endl;
}
void fun(char c, int a)
{
cout << "fun(char, int)" << endl;
}
int main()
{
int a = 10;
char c = 'a';
fun(a, c);
fun(c, a);
return 0;
}
执行结果:
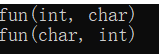
函数的参数不同,也可以构成重载:
void fun(int a)
{
cout << "fun(int)" << endl;
}
void fun(int a, int b)
{
cout << "fun(int ,int)" << endl;
}
int main()
{
fun(1);
fun(1, 2);
return 0;
}
运行结果:
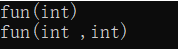
总结:函数重载的要求:
1、函数参数的类型不同
2、函数参数的类型顺序不同
3、函数参数的个数不同
注意:函数重载不参考函数的返回值。
那为什么C语言不支持函数重载,而C++支持函数重载呢? --通过名字修饰
名字修饰
名字修饰是针对函数在编译后对函数名称的修饰。这也是为什么函数C++能够支持重载的一个重要原因。
那为什么C语言不支持函数重载呢?
示例代码:
int funtion1(int a, int b)
{
return a + b;
}
int funtion2(double a, double b)
{
return a + b;
}
int main()
{
funtion(10, 20);
funtion(1.01, 2.02);
return 0;
}
在vs2019编译环境下
在vs2019编译环境下,函数名称被修饰为<_funtion1>和<_funtion2>,我们可以看出,C语言在vs编译环境下,函数名称修饰只是在原名称前加了_,由于整个编译过程都会经过4个过程,预处理-编译-汇编-链接。在链接的时候,会专门去找名称为_funtion1和_funtion2的函数。如果两个函数同名,那么编译器就无法识别调用哪个函数。
在Linux gcc编译环境下

我们可以看出,在gcc环境下函数名修饰只是它原函数名本身,没有附加其他信息。那在链接的时候肯定就会报错。所以不支持重载。
那C++有怎样的名称修饰让其函数支持重载呢?
示例代码:
int funtion1(int a, int b)
{
return a + b;
}
int funtion2(double a, double b)
{
return a + b;
}
int main()
{
funtion(10, 20);
funtion(1.01, 2.02);
return 0;
}
在vs2019编译环境下
名称修饰分别为:
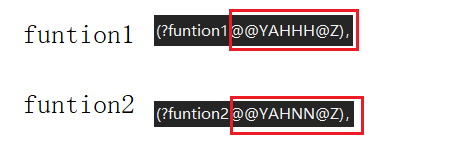
我们可以看到,两个函数的名称修饰,在函数名后面还附加了一下其他信息用来区分同名不同类型的函数。在链接器链接时就能通过函数修饰后的名称来找到相应的函数,从而支持函数的重载。在vs下函数的修饰后的名称可读性比较差,且比较复杂,有兴趣的小伙伴可以上网查查。接下来我们再看看Linux g++编译器对函数名称的修饰。
在Linux g++编译环境下

我们可以看到g++和vs堆函数名称修饰是不一样的,现在我们来了解g++对函数名称的修饰规则。
_Z8funtion1ii:第一个字符_Z是对C++文件的一个修饰,但不起重载作用。数字8是函数的长度,后面接着funtion1是函数的名字,从现在来看也并不起重载的作用。后面两个字母ii表示的是参数的类型。ii是对int的缩写。函数funtion2中后面两个字符是dd,是对double的一个缩写。而两个i是因为有两个int类型的参数。这里要注意的是修饰也参考了参数的顺序。如果函数声明为int funtion3(int a, double b, int c);那么函数修饰后的名称为_Z8funtion3idi。我们也可以从修饰名称规则知道,在函数名相同的情况下,参数的类型、顺序、以及个数的不同,在修饰函数名称后的函数名都不同。所以支持重载,也可以看出函数返回值并没有参与名称修饰,所以函数的重载不以函数返回值作参考。
那我们可以在C++工程中,不想让这个函数重载,有没有办法达到呢,当然可以- -extern “c”
extern “c”
extern "C"作用:在函数前加extern “C”,意思是告诉编译器, 将该函数按照C语言规则来编译。
示例代码:
#include <stdio.h>
extern "C" int funtion(int a, int b)
{
return a + b;
}
double funtion(double a, double b)
{
return a +b;
}
int main()
{
funtion(1, 2);
funtion(1.01, 2.02);
return 0;
}
g++编译器下的名称修饰

可以看出在C++的函数前加上extern "c"后,编译器并没有对该函数进行名称修饰。这通常用在C/C++混合编程中。特别是在嵌入式编程中,对内存有一定的要求,这时候按照C来编译可以减少内存的开销。
















 519
519











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











