







摘要
随着人脸识别系统的日益普及和广泛的应用,人脸识别系统越来越受到攻击者的关注。因此,人脸呈现攻击检测在近年来已成为一个重要的研究课题。现有的人脸呈现攻击检测方法会受到不同摄像头和显示设备的影响,并且在跨数据库测试中会使其性能下降。在本文中,我们提出了一种融合了多视角动态特征的人脸表示攻击检测方案。其中一个特征是在视频中全局提取的一个人脸的时间运动模式。这包括将视频中人脸的局部和全局运动信息映射到单个图像中。 真脸和假脸的运动模式是不同的,这些模式独立于摄像机和显示设备。 另一个特征是噪声模式的视觉节奏,这在单成像和二次成像之间有很大的不同。 所提出的方案在决策层面融合了这两个特征。 在CASIA-FASD、MSU-MFSD和Replay-Attack数据库中进行了跨数据库测试。 实验结果表明,该方案优于现有算法。
关键词:Face presentation attack detection, multi-perspective features, visual rhythm, noise pattern,
motion pattern.
引入
近年来,深度学习技术的发展显著提高了人脸识别的准确性,促进了人脸识别系统的广泛应用,人类的面孔越来越多地与隐私和个人财产联系在一起。
常见人脸展示攻击如下:

本文针对照片和视频展示攻击。
目前存在几种识别展示攻击的方法,分为基于静态特征和动态特征两类。
静态:颜色纹;本地阴影(local shade)
动态:利用无意识动作,如眨眼,微表情等;利用从两个相邻帧之间提取出的光流体。现有提取动态特征方法从单个帧或两个相邻帧之间提取动态特征。
面部表情由面部肌肉控制,虽然人脸轮廓不同,但是面部肌肉分布类似。在照片中,面部肌肉运动不存在;在视频中,由于二次成像,面部运动模式存在改变。
本文提出人脸呈现攻击检测的多视角动态特征,其结构如下图

该网络包含两种动态特征。1:全局性的将时间内运动(temporal motions)映射到一张图片上。提取运动模式的方法受运动模糊图像成像过程的启发,将每个帧中的每个像素视为时变信号,然后计算视频持续时间的积分。2:成像过程中产生噪声的视觉规律。这是用来确定视频是否涉及二次成像。
方法
包括预处理,人脸运动模式提取、噪声模式提取和分类四个步骤。
预处理
1、通过对人脸的检测来确定其在第一帧中的人脸的位置
2、该视频的所有帧都是根据在第一帧中的人脸位置进行裁剪的
面部运动模式提取
运动模糊图像成像过程
运动模糊图像包括丰富的运动信息
运动模糊图像的成像过程如下
假设场景F和镜头间存在相对位移,时间t内在x方向和y方向上的运动距离分别为x0(t), y0(t)。点(x,y)的总曝光通过对曝光时间T内的瞬时曝光整合得到:
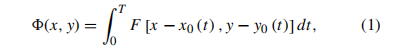
其中,
Φ
\Phi
Φ(x,y)是点(x,y)在曝光图中的值,而F(x,y)是捕获的场景。
视频图像的模糊图片

我们将视频作为一个移动的主题,视频持续时间作为曝光时间。我们可以将视频中的运动模糊图像表示如下:
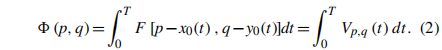
为了去除光照和正负值影响,提取出的值如下:
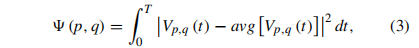
Ψ
\Psi
Ψ(p,q)是(p,q)最终的值。
当以帧率采样时
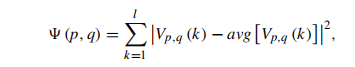
其中Vp,q(k)是在第k帧时点(p,q)的值,l是帧数
计算视频的运动模糊图像
计算该视频的运动模糊图像的详细步骤如下:
- 我们将视频中的每个像素视为以帧速率采样的时间序列信号。在这三个通道(R、G、B)中,我们在接下来的步骤中选择G通道,因为绿色成分比红色和蓝色成分能更好地渗透到人类的皮肤中
- 采用低通滤波器消除噪声。 截止频率设置为2.25Hz,几乎等于最大心率。
- 然后,我们删除信号的平均值,并使用Eq集成它。
噪声模式提取
首先,我们提取了视频中的噪声。假设那个v是一个输入的视频。剩余噪声视频vNR可计算如下:
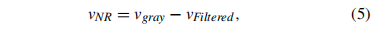
其中Vgray是灰度值视频,VFiltered是由灰度值视频生成的过滤后视频(过滤方法不明,待跟进)
‘接着一个2D离散傅里叶变换应用到残余噪声视频VNR中。
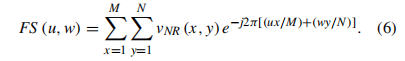
其中M,N代表视频的高和宽。
接着,视觉节奏用于总结傅里叶谱。















 2032
2032











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









