







 S2ANet通过引入Align Convolution和Feature Alignment Module解决遥感图像中目标检测的特征对齐问题,提高检测性能。文章分析了现有方法的局限,提出旋转检测模块ODM,利用ARF编码旋转特征,同时采用单阶段检测器结构进行优化。实验表明,S2ANet在大型图像上的表现优异。
S2ANet通过引入Align Convolution和Feature Alignment Module解决遥感图像中目标检测的特征对齐问题,提高检测性能。文章分析了现有方法的局限,提出旋转检测模块ODM,利用ARF编码旋转特征,同时采用单阶段检测器结构进行优化。实验表明,S2ANet在大型图像上的表现优异。
S2ANet解读
开始入门遥感方向,第一篇看了S2ANet,看了下网上的博客基本就很浅薄地谈了谈Abstract里面的内容,也没有对其进行argue,然后我来做这件事。如果有错误请指正,方便深入交流。
文章内容摘录
题目
首先从题目看本文做的就是Align Deep Feature,更具体地说是"alignment between conv features and Anchor boxes(RoIs)"。见原文Section ⅡB小结开始的话。
Abstract
摘要基本上就是沿着场景->问题->工作->作用->效果这一系列的思路来写。动机就是对于遥感检测这种large scale且arbitrary orientations的场景,传统的定义不同尺度、角度、长宽比的anchor的方法有大问题,原因就是“severe misalignment在anchor boxes和坐标轴方向上的conv特征”。这里应该想说明的意思是:这个图,也就是Figure (a)。但反正这段话读起来怪怪的,也有可能是因为我读得少。 *

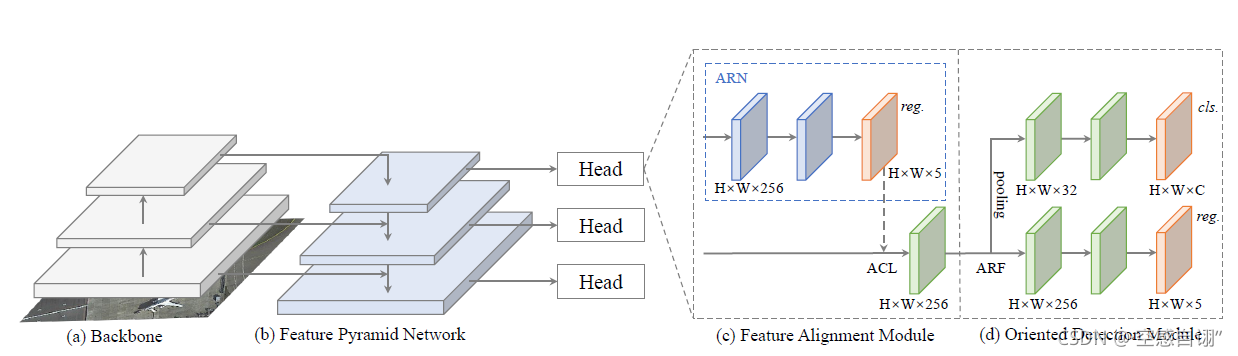
然后作者带你定义了几个名字:FAM,一个特征对其模块,其中的ARN(anchor refinement network)用来生成高质量的Anchors,且anchor并不dense,而是Feature Map一个位置就一个;其中Align Conv用来对齐特征好处就是计算量提升不大的条件下根据anchor自适应对齐特征(也没啥自适应我感觉)。这两个加起来就是Head之后的第一个方框。第二个方框就是ODM,一个旋转检测模块。然后ODM中使用了ARF(activate rotating filters)来编码旋转特征,就是从FAM输出做了各个方向最大相应的提取,拿出有旋转不变性的那部分用于分类网络。而另一路则直接用于回归问题。(我多少觉得下面回归框这部分就吃了前面FAM的红利,不怎么需要新的设计。不然用所谓的orientation-sensitive feature怎么做回归。。?或者说我认为这也是单阶段的detector问题。 *)前面的结构非常简单,就是Backbone(作者用RetinaNet)和FPN(Feature Pyramid Network)。摘要说的有点多,下面遇到就不再重复。
Ⅰ.Intro
Intro部分作者先“按照惯例”说了说ODAI(object detection in aerial images)的进展很大,说了这个领域的难点。
1.然后就提及SOTA的方法用了两阶段的R-CNN结构,不是本文的重点就不说了。(主要就是旋转anchor,两阶段的anchor和RoI Transformer。前者需要很多anchor,后者计算RoI相关操作计算复杂)
2.再提及单阶段的,也就是作者改进的方向:
(1)anchor质量不高:指的是长宽比的设置对遥感目标来说,很少的anchor能被分配于检测该目标,比如桥梁)这就加剧了foreground-background class imbalance(不清楚就见https://zhuanlan.zhihu.com/p/82371629,我觉得说的很好)。
(2)骨干提取的特征一般都是x,y方向的,而且感受野固定,这就和遥感的目标不同。这就导致“anchor box对应的特征无法替代整个物体,那么cls的score和regression的score之间的关联性降低”。再考虑到NMS,事情就更加复杂了。
3.作者提出自己的方法:这部分看摘要我说的那几个名字和功能的解释,基本就是重新说了一遍。除此之外还提了一句用大尺寸的images测试的方法,而不是on-chip images(我的理解就是原始传感器拍出来的)。**注意,此处作者提及其改进工作的总结:Align Conv以及用其构建了S2ANet,并取得了SOTA。**所以不清楚之前提及的FAM(中的ARN)算不算是作者的原始工作。
Ⅱ.Related Works
Object Detection in Aerial Images
提及了这个问题的特点,介绍Ding et al. RoI Transformer、Xu et al.和R3Net的工作。说自己不一样在于:产生高质量Anchor(没说什么是高质量),且能通过全卷积的形式对齐特征。
Feature Alignment in OD
RoIPooling的方法,因为会做量化导致RoI和Feature的不对齐。RoI Align的提出,Deformable RoIPooling的方法。但上述的问题都是慢,或者其中有些的性能不好。
最近的Guided Anchor、AlignDet在单阶段检测器实现了Feature的对齐,但是在本领域性能不行(尤其是有旋转和密集排布的)。所以本文的工作还是从Guided Anchor出发,通过调整sample的点来做特征对齐。
Inconsistency between Regression and Classification
“对于单阶段检测器,一般包含两个互不干扰的过程:分类和坐标回归。二者使用从骨干网络得到的相同特征。在类似于NMS的后处理中,cls的score用来反映坐标回归的准确性。”这一段话说的有些奇怪,尤其是后一句,也是个人意见。 然后作者列举了IoU-Net、Double-Head R-CNN等工作。这里最重要的应该是这句:“shared features are not suitable for both cls and reg”。从而引出ODM中的改进。
Ⅲ.Proposed Methods
RetinaNet and Baseline
作者用RetinaNet作为Baseline,然后把回归的四元结果,改为加上 θ \theta θ组成:{(x,w,h, θ \theta θ)},注意x=( x 1 x_1 x1, x 2 x_2 x2)。这里 θ \theta θ的取值范围为 θ \theta θ∈[ − π 4 -\frac {\pi} {4} −4π, 3 π 4 \frac{3\pi}{4} 43π]。(这里其实我认为也可以argue的,并非一定有道理,我甚至觉得[ − π 2 -\frac {\pi} {2} −2π, π 2 \frac{\pi}{2} 2π]更加合理,评论区讨论)
Alignment Convolution
这里算是作者的核心工作之一了。本质上就是在卷积公式中额外加了一个偏置。每个都加相当于对anchor做了一个旋转。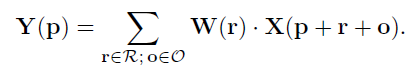
计算公式为:
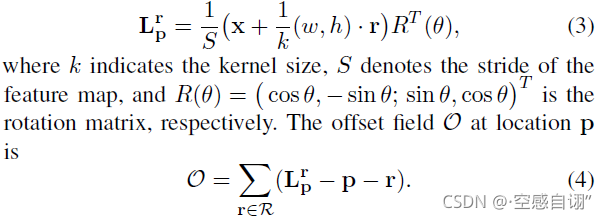
我从下方这个图理解了这个
L
p
r
L^r_p
Lpr的计算过程。不考虑最后的旋转部分,就是一个中心的偏移。再加入旋转和根据步长的放缩。
之后作者对比了和其他几个conv类型的优劣:
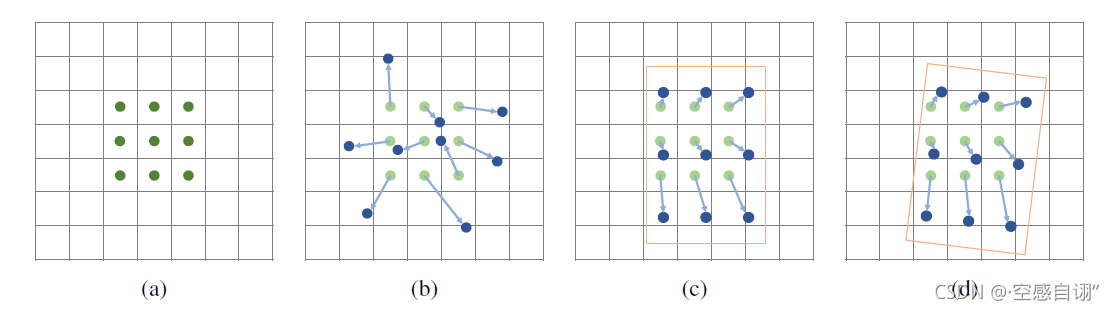
从左到右分别是普通,Deformable conv,Align和Align Rotate。
Feature Alignment Module(FAM)
FAM由ARN和Align Conv Layer(ACL)组成。ARN有对anchor的cls和reg两个分支组成,其中reg用来生成高质量anchors。对于每个anchor box(HxWx5),都会sample 9个点,最终得到18维的field。
Oriented Detection Module(ODM)
ODM由ARF和最后的cls和reg输出组成。实际上ARF本身就是划分了几个通道的卷积,并没有对卷积核做任何约束和处理,并不能说其是旋转。只不过选择了一个旋转角度的最大相应,认为此角度(或者卷积核)提取出了旋转不变的Feature。(我认为需要看下具体实现来argue)。
Single-Shot Alignment Network
组网过程,分为Regression Targets和Matching Strategy。需要对上面定义的五元数组回归。计算两个旋转框的IoU作为筛选fore和back的指标。Loss这里分别考虑FAM和ODM的loss,借助Focal Loss和Smooth L1的思想分别处理分类和回归。
Ⅳ.Experiments and Analysis
Datasets
DOTA和HRSC2016,后面一个稍微小一点,可以跑一下。前一个总共118G。
Implementation Details
Ablation Studies
消融实验,主要为了说明模块的有效性。有几个在Design Network的结论:
(1)约深的具有大感受野的网络层,不利于遥感小目标
(2)FAM和ODM层数一致的时候,效果更好。
(3)几个模块之间组合的相互关系,见下图。对勾表示有:

Detecting on Large-size Images
个人觉得没啥说的,也没有什么新的想法。
Comparisons with SOTA
…
Ⅴ.Conclusion
…
综上,整篇文章我认为最大的亮点就是其Align Conv Layer的设计,以及消融实验中的分析。可以说将Align Conv和ARF的结合让特征对齐,从而得到更有效的中间结果。后面的ARF有点信号处理中分数域傅里叶给chirp信号找最大相应的角度§的感觉。
不足(我读得少,就是片面之词)在于:图有点乱,经常找不到,文中也有很多chinglish+错误用法。Intro个人认为写的比较乱(外层看着清晰,内部不是很清晰,尤其是Related Work,感觉只调研了一半),如果Align Conv给稍微的一些推导会更好理解。对一些关键问题的解释,比如
θ
\theta
θ范围没有一个很好的解释,当然一切因为代码开源能消除不少疑问。但从读者完美主义的角度还是有瑕疵。


















 3069
3069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











