







DDD(领域驱动设计(Domain-Driven Design)
原文参考:https://learn.lianglianglee.com
本文学习使用
领域边界(业务架构)
领域:有明确边界的范围,领域即范围,有明确边界的范围
描述要解决的问题的范围,明确了哪些问题要在该范围中解决,哪些不在该范围中解决
描述与其它业务域之间的关系和协作方式,从而解决更复杂、更系统性的问题
如果颗粒度太大,可以拆分为子域


如何更精确的建模
准确性比正确性更重要:
团队扩大,需要分工的时候
i性能考量
稳定性思考
领域事件(订单已支付):
领域事件(Domain Event)是领域驱动设计(DDD)中的一个概念,用于表示在领域模型内部发生的某个业务显著事件。这些事件通常标志着业务状态的变化,对业务流程中的重要事项进行编码。
核心特点
业务意义:领域事件通常具有明确的业务意义,例如“订单已支付”或“用户账户已创建”。
不可变性:一旦发生并记录下来,领域事件通常是不可变的。这意味着您不修改事件本身,而是通过产生新的事件来表示随后的状态变化。
时间顺序:领域事件通常与时间戳相关联,这表明了事件发生的顺序。
关注点分离:通过领域事件,您可以将核心业务逻辑(领域模型的状态变化)与副作用(如通知用户或更新外部系统)分离开来。
使用场景
集成:在微服务或模块化的架构中,领域事件可以用作服务或模块间通信的一种方式。当一个服务的领域状态改变时,它可以发出一个事件,其他服务可以订阅并响应这些事件,而无需直接耦合。
触发工作流:领域事件可以触发业务流程中的下一个步骤,比如在购买流程中,“订单已支付”事件可以触发发货流程的开始。
事件溯源:在事件溯源(Event Sourcing)系统中,领域事件是系统状态变化的主要记录形式。系统的当前状态是通过重放这些事件来构建的。
public class OrderCreatedEvent {
private final OrderId orderId;
private final Date creationDate;
private final CustomerId customerId;
private final List<OrderLine> orderLines;
public OrderCreatedEvent(OrderId orderId, Date creationDate, CustomerId customerId, List<OrderLine> orderLines) {
this.orderId = orderId;
this.creationDate = creationDate;
this.customerId = customerId;
this.orderLines = orderLines;
}
// Getters and methods to process the event...
}
使用消息队列来发送领域事件
领域模型(可以理解数据模型层):
在领域驱动设计(DDD)中,"模型"通常指的是领域模型,它是对特定业务领域的抽象表示,可以包含实体(Entity)、值对象(Value Object)、服务(Service)、聚合(Aggregate)等多种概念。
- 实体(Entity):具有唯一标识符的对象,它代表了系统中可区分的实体。即使属性值相同,只要标识符不同就被视为不同的实体。
- 值对象(Value Object):没有唯一标识符的对象,它描述了领域中的一些特性或属性,其相等性是通过它的属性值来确定的。
当我们在DDD中谈论"模型"时,我们不仅仅是指一个单一的实体或值对象,而是指一个包含这些元素并能够表达业务规则和业务逻辑的更广泛的领域模型。这个模型是整个系统设计的基础,它应当精确地反映业务领域的复杂性和业务行为
服务,值对象与实体:
服务
服务,标识的是那些在领域对象之外的操作与行为。 在 DDD 中,“服务”通常承担了两种类型的职责:接收用户的请求和执行某些操作
值对象(Value Object)
值对象是一种不可变的对象,它的主要目的是描述事物的某些特性或属性,而不是事物本身。值对象的相等性不是通过唯一标识来判断的,而是通过对象属性的值。如果两个值对象的所有属性值都相等,那么这两个对象就被认为是相等的。
特点:
- 不可变性:一旦创建,值对象的状态就不应该被改变。
- 可替换性:值对象没有唯一标识,它们通过属性值来定义相等性。如果两个值对象的属性相同,它们就是等价的,可以相互替换。
- 无副作用:由于值对象是不可变的,它们的操作不会对外界产生影响。
示例:在一个电商系统中,一个地址可能被表示为一个值对象,包含街道、城市、国家等属性。如果两个地址对象的所有属性值都相同,那么这两个地址对象就被认为是相同的。
实体(Entity)
实体是具有唯一标识(ID)的对象,它代表了系统中的一个可变的概念或事物。实体的相等性是基于它们的唯一标识来判断的,而不是它们的属性。
特点:
- 唯一性:每个实体都有一个用于区分其他实体的唯一标识符。
- 可变性:实体的属性可能会随着时间的推移而改变,但它仍然保持同一个实体。
- 持续性:实体通常需要被持久化存储,它们的状态变化可能会跨越系统的多个事务或会话。
示例:在同一个电商系统中,用户可以被视为实体,因为每个用户都有一个唯一的用户ID。即使用户的姓名或邮箱地址改变,用户ID保持不变,系统仍然将其视为同一个用户。
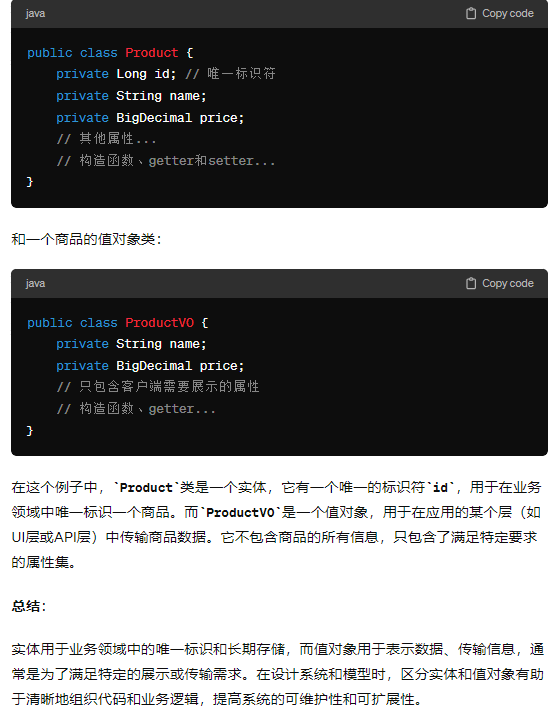
充血模型(微信服务号回复信息toXml,toMap)&贫血模型(常见pojo)
服务、实体与值对象是领域驱动设计的基本元素。然而,要将业务领域模型最终转换为程序设计,还要加入相应的设计。通常,将业务领域模型转换为程序设计,有两种设计思路:贫血模型与充血模型。
**贫血模型:**就是在软件设计中,有很多的 POJO(Plain Ordinary Java Object)对象,它们除了有一堆 get/set 方法,几乎没有任何业务逻辑。这样的设计被称为“贫血模型
**充血模型:**把业务增加到pojo,比如金卡,银卡,铂金,都有打折却不相同,则可以创建三个类,里面实现三个不同的打折方法,业务只需要调用打折即可
聚合根(业务全量VO对象)
聚合根是一个实体(订单订单详细),
外部访问的唯一入口
了解聚合根,要先了解什么是聚合,比如我们如下设计
public class Order {
private Set<Items> items;
public void setItems(Set<Item> items){
this.items = items;
}
public Set<Item> getItems(){
return this.items;
}
……
}
要做订单保存,查询,订单作为一个整体进行操作,不需要单独操作订单明细,当订单不存在,明细也就没有了意义, 而有些不是整体与部分关系是不能设计成聚合的,比如订单明细和商品 没有了这个订单的订单明细,依然会有商品存在的意义
这样的设计有时是有效的,但并非都有效。譬如,在管理订单时,对订单进行增删改,聚合是有效的。但是,如果要统计销量、分析销售趋势、销售占比时,则需要对大量的订单明细进行汇总、进行统计;如果每次对订单明细的汇总与统计都必须经过订单的查询,必然使得查询统计变得效率极低而无法使用。
领域驱动设计通常适用于增删改的业务操作,但不适用于分析统计。在一个系统中,增删改的业务可以采用领域驱动的设计,但在非增删改的分析汇总场景中,则不必采用领域驱动的设计,直接 SQL 查询就好了,也就不必再遵循聚合的约束了。
仓储(加一层):
持久实体,取出实体
理解: 在持久层到数据库之前加了一层 操作聚合根(实体)存取的过程,而具体实现,就是仓库,至于工厂则是用来,生产聚合根(实体)的
但是因为上面所说查询是需要分离,不希望使用聚合根,比如我分析订单,不希望有所有的订单商品出现
命令与查询分离 CQRS模式

聚合的实现,仓库与工厂(封装聚合根)
仓库:
- 作为桥梁:仓库充当了持久层与业务层之间的桥梁。通过仓库,业务层可以对数据进行操作,而无需直接与数据库打交道。
- 数据来源透明:业务层通过仓库访问数据时,不需要关心数据的实际来源是SQL数据库、NoSQL数据库还是其他存储方式。这种抽象化使得后端存储可以灵活变更,而不影响业务逻辑层。
- 简化业务逻辑:仓库还可以封装复杂的数据操作,如跨多表的数据持久化或一致性维护等,业务层调用仓库提供的方法即可,无需自行处理这些复杂逻辑
工厂:
在业务层创建对象时使用,帮助业务层不需要知道复杂的创建逻辑。比如,创建一个订单时,可能需要根据不同的条件来设置订单的不同状态或者计算价格,工厂就是把这些逻辑封装起来,让业务层只需要调用一个方法就可以得到一个准备好的订单对象,这也就是业务层可以不关心封装复杂数据的原因
案例
我们一般开发中,使用的贫血模型,也就是订单处理订单服务,再去处理明细服务,调用不同mapper,携带不同实体做持久化,然后由,订单的service添加事务操作,那么聚合操作应该是如何呢
也就是我们会实现一个仓库(Repository),去完成对数据库的访问(说人话,就是在之前手动操作两个dao,增加一层操作两个dao,业务以后调用直接调用这个增加的层,也就是仓库(Repository),甚至可以是异构的持久层,比如redis)比如:
领域模型是啥样,程序就设计成啥样(其实我们以前在业务里面也是这样返回的这个vo, 只是现在我们把他封装到新增的那层, 只要调用,什么数据都出来了,跟前端原型一样,那就是说,我们不在业务层封装,那就需要找个地方进行封装,而这个动作就是工厂需要做的事情)
与 DAO 不同的是:
- 订单仓库在查询订单时,只是简单地查询订单表,不会去 Join 其他表,比如 Join 用户表,不会做这些事情;
- 当查询到该订单以后,将其封装在订单对象中,然后再去通过查询补填用户对象、订单明细对象;
- 通过补填以后,就会得到一个用户对象、多个订单明细对象,需要将它们装配到订单对象中。
这时,那些创建、装配的工作都交给了另外一个组件——工厂来完成
public class Order {
......
private Long customer_id;
private Customer customer;
private List<OrderItem> orderItems;
总结:
比如拿订单和订单明细来说 ,我之前是业务层操作 订单dao和订单明细dao,
那现在 我就是业务层调用repository, 执行新增, service调用工厂的方法进行组装聚合根, 最终由仓库(reporitory)执行保存, 这是新增,
当需要查询的时候, 业务层可以直接调用repository,一般满足需求,不用特意调用工厂
工厂(Factory)的主要职责是创建聚合根或领域对象,并确保它们在创建时符合业务规则和约束条件
也就是业务层看到的就是拿到了最终查询的订单聚合根,以及给参数到工厂 而不需要关注参数在工厂内部如何进行的组装,也不需要关注各个表的保存 ,以及事务操作
GPT:
新增操作:
- 业务层调用仓储(Repository):当业务层需要执行新增操作时,它不直接与数据访问对象(DAO)交互,而是通过仓储进行。这样做的目的是将业务逻辑与数据存储细节解耦。
- 仓储调用工厂(Factory)组装聚合根:仓储利用工厂来创建或组装聚合根实例。工厂封装了聚合根的创建逻辑,确保聚合根在被创建时就符合业务规则。
- 仓储执行保存:一旦聚合根被正确组装,仓储就会将其保存到数据库中。这个过程可能包括将聚合根及其组成部分(如订单及订单明细)映射到数据库的相应表中。
查询操作:
- 业务层调用仓储进行查询:当业务层需要查询数据时,它同样通过仓储进行。这里的仓储可能提供了一些方法来支持复杂的查询操作。
- 仓储可能调用工厂封装查询结果:在某些情况下,尤其是当查询结果需要被组装成特定形式的聚合根或DTO时,仓储可能会利用工厂来完成这一步。不过,这不是必需的,因为查询操作通常不涉及创建新的聚合根实例,而是从数据库检索数据。
GPT总结:
- 业务逻辑与数据存储的解耦:通过仓储和工厂,业务逻辑不需要直接与数据库交互,这使得代码更加清晰,易于维护。
- 聚合根的封装和一致性维护:工厂确保聚合根在创建时就满足业务规则,而仓储则管理聚合根的持久化,确保数据的一致性和完整性。
- 对数据的查询不再通过 SQL 语句进行 Join,而是通过工厂进行补填与装配。这样的设计更有利于微服务的设计与大数据的调优
- 事务操作的隐藏:在整个操作过程中,事务管理被隐藏在仓储层中,业务层不需要关注事务的具体处理,只需关注业务逻辑。
缺点:
这样会大大增加开发工作量。但这些仓库与工厂的设计大致都是相同的,会催生大量的重复代码。能不能通过抽象,提取出共性,形成通用的仓库与工厂,下沉到底层技术中台中,从而进一步降低领域驱动的开发成本与技术门槛?也就是说,实现领域驱动设计还需要相应的平台架构支持。关于这些方面的思路,我们将在 DDD 的架构设计部分进一步探讨。
最终代码结构案例:
ecommerce-system/
│
├── domain/
│ ├── model/
│ │ ├── Order.java // 聚合根
│ │ └── OrderItem.java // 实体
│ │
│ ├── repository/
│ │ └── OrderRepository.java // 仓储接口
│ │
│ └── service/
│ └── OrderService.java // 应用服务
│
├── infrastructure/
│ ├── repository/
│ │ └── OrderRepositoryImpl.java // 仓储实现
│ │
│ └── factory/
│ └── OrderFactory.java // 工厂
│
└── application/
└── web/
└── OrderController.java // 控制器
- domain/model/: 这个目录包含了领域模型,
Order.java作为聚合根管理订单的整体和订单项OrderItem.java。 - domain/repository/: 存放仓储接口
OrderRepository.java,定义了对聚合根Order的基本操作,如保存订单和查询订单等。 - domain/service/: 包含应用服务
OrderService.java,它使用OrderRepository来执行业务操作,如创建订单。 - infrastructure/repository/: 提供
OrderRepository接口的实现OrderRepositoryImpl.java,负责与数据库交互。 - infrastructure/factory/: 包含
OrderFactory.java,负责创建和组装Order聚合根实例。 - application/web/: 包含
OrderController.java控制器,负责处理外部请求,调用OrderService来执行业务操作,并返回相应结果
操作流程简述
- 新增订单:
- 控制器
OrderController接收创建订单的请求。 OrderController调用OrderService的方法来处理这个请求。OrderService通过OrderFactory创建Order聚合根实例。OrderService使用OrderRepository保存Order实例到数据库。
- 控制器
- 查询订单:
- 控制器
OrderController接收查询订单的请求。 OrderController调用OrderService的方法来处理这个请求。OrderService使用OrderRepository查询订单详情。OrderService返回查询结果给OrderController,然后返回给客户端。
- 控制器
代码分层结构

分层架构

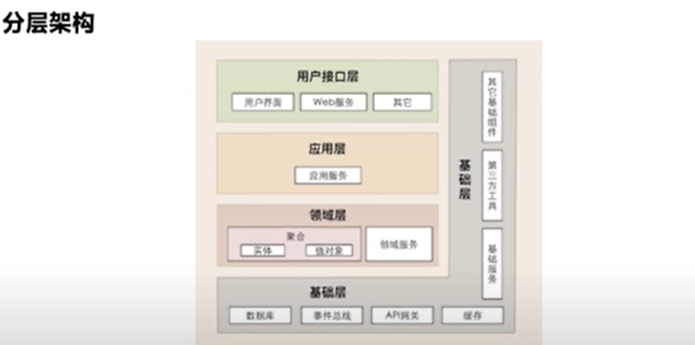
- 表示层(Presentation Layer) - 负责与用户界面交互,通常包括控制器(Controllers)和视图模板(Views)。
- 业务逻辑层(Business Logic Layer) - 负责处理业务规则和应用逻辑,通常包含服务(Services)和领域模型(Domain Models),比如实体(Entities)和值对象(Value Objects)。
- 持久层(Persistence Layer) - 负责数据持久化机制,通常包括仓库(Repositories)或数据访问对象(Data Access Objects, DAOs)。
- 数据库层(Database Layer) - 存储数据,通常是SQL或NoSQL数据库。
实例
com.example.myapp
├── Application.java # Spring Boot应用的主入口点
├── controller # 表示层 - REST API的控制器
│ ├── UserController.java
│ └── ...
├── service # 业务逻辑层 - 业务服务和应用逻辑
│ ├── UserService.java
│ └── ...
├── domain # 领域层 - 领域模型
│ ├── User.java
│ └── ...
├── repository # 持久层 -
在这样的结构中,每层只与相邻的层直接通信,层与层之间的依赖关系是自上而下的,表示层依赖业务逻辑层,业务逻辑层依赖持久层,持久层依赖数据库层。这种依赖管理的方法有助于减少代码耦合,使系统更易于维护和测试。
在这样的结构中,每层只与相邻的层直接通信,层与层之间的依赖关系是自上而下的,表示层依赖业务逻辑层,业务逻辑层依赖持久层,持久层依赖数据库层。这种依赖管理的方法有助于减少代码耦合,使系统更易于维护和测试。
分层架构的关键点:
- 隔离性:每层都应该是自包含的,并且能独立于系统的其他部分工作。
- 可替换性:由于清晰的界限,可以较容易地替换或修改某一层的实现,而不影响其他层。
- 测试性:分层架构简化了单元测试和集成测试的过程。每层都可以被单独测试,同时可以通过模拟或存根测试层与层之间的交互。
要注意的是,即使分层架构有这些好处,也不应该过度设计。例如,如果某个应用很小,没有复杂的业务逻辑或多变的需求,那么采用过于复杂的分层可能会导致不必要的复杂性和开销。
最后,Spring Boot项目中的Application.java文件通常包含@SpringBootApplication注解,它是@Configuration、@EnableAutoConfiguration和@ComponentScan注解的组合,这意味着Spring Boot会自动扫描这个类所在包以及其子包中的Bean,因此,组织好您的包结构至关重要。
- 隔离性:每层都应该是自包含的,并且能独立于系统的其他部分工作。
- 可替换性:由于清晰的界限,可以较容易地替换或修改某一层的实现,而不影响其他层。
- 测试性:分层架构简化了单元测试和集成测试的过程。每层都可以被单独测试,同时可以通过模拟或存根测试层与层之间的交互。
要注意的是,即使分层架构有这些好处,也不应该过度设计。例如,如果某个应用很小,没有复杂的业务逻辑或多变的需求,那么采用过于复杂的分层可能会导致不必要的复杂性和开销。
最后,Spring Boot项目中的Application.java文件通常包含@SpringBootApplication注解,它是@Configuration、@EnableAutoConfiguration和@ComponentScan注解的组合,这意味着Spring Boot会自动扫描这个类所在包以及其子包中的Bean,因此,组织好您的包结构至关重要。
分层架构与mvc
- 分层架构更侧重于后端的整体结构,它包含了从前端到后端,从用户界面到数据持久化的所有层面。
- MVC架构更侧重于如何在前端组织用户界面逻辑,它主要处理如何响应用户的输入,展示数据,并将用户界面的变化通知到模型。
虽然在多层架构中的表示层可以被看作是MVC架构中的控制器和视图的组合,但MVC并不涉及到如何组织业务逻辑和数据访问逻辑。实际上,MVC可以作为分层架构中表示层的一个内部模式来使用。在Web应用中,后端可能采用分层架构,而前端(比如单页面应用)可能采用MVC或类似的模式(如MVVM)来组织代码。
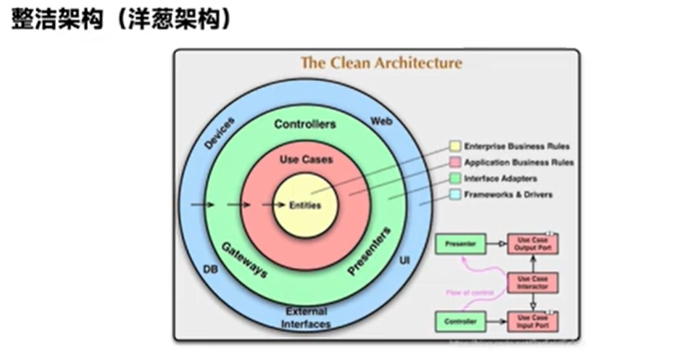
整洁架构

project-root/
│
├── backend/ # 后端Spring Boot项目根目录
│ ├── src/
│ │ ├── main/
│ │ │ ├── java/
│ │ │ │ ├── com/
│ │ │ │ │ ├── yourcompany/
│ │ │ │ │ │ ├── application/ # 应用层 - 用例和数据传输对象
│ │ │ │ │ │ │ ├── dto/ # 数据传输对象
│ │ │ │ │ │ │ ├── service/ # 应用服务实现
│ │ │ │ │ │ │ └── ...
│ │ │ │ │ │ ├── domain/ # 领域层 - 业务逻辑核心
│ │ │ │ │ │ │ ├── model/ # 领域模型 (实体、值对象、枚举)
│ │ │ │ │ │ │ ├── service/ # 领域服务
│ │ │ │ │ │ │ └── ...
│ │ │ │ │ │ ├── infrastructure/ # 基础设施层 - 持久化和基础服务
│ │ │ │ │ │ │ ├── config/ # 配置类
│ │ │ │ │ │ │ ├── persistence/ # 持久化实现 (如JPA仓库)
│ │ │ │ │ │ │ └── ...
│ │ │ │ │ │ ├── presentation/ # 表现层 - 控制器和资源映射
│ │ │ │ │ │ │ ├── controller/ # REST控制器
│ │ │ │ │ │ │ └── ...
│ │ │ │ │ │ └── YourApplication.java # Spring Boot应用主类
│ │ │ └── resources/
│ │ │ ├── application.properties # 应用程序配置文件
│ │ │ └── ...
│ │ └── test/ # 测试目录
│ └── pom.xml # Maven项目文件
│
├── frontend/ # 前端项目根目录
│ ├── public/ # 静态资源
│ ├── src/ # 前端源代码
│ │ ├── components/ # UI组件
│ │ ├── services/ # 前端服务层 (与后端通信)
│ │ ├── app.js # 应用程序入口文件
│ │ ├── ...
│ ├── package.json # npm配置文件
│ └── ...
│
└── README.md # 项目文档说明
- application:包含应用服务和数据传输对象(DTOs),用来定义用例的接口,以及用于与外界交互的数据结构。
- domain:包含核心业务逻辑的领域模型,如实体、值对象、领域服务、领域事件等。
- infrastructure:包含支持领域模型和应用层的所有技术细节,如数据库访问(通常使用Spring Data JPA)、消息发送(可能使用Spring Integration或RabbitMQ等)、以及其他跨应用服务。
- presentation:包含与用户界面交互的组件,通常是REST API的控制器
六边形架构
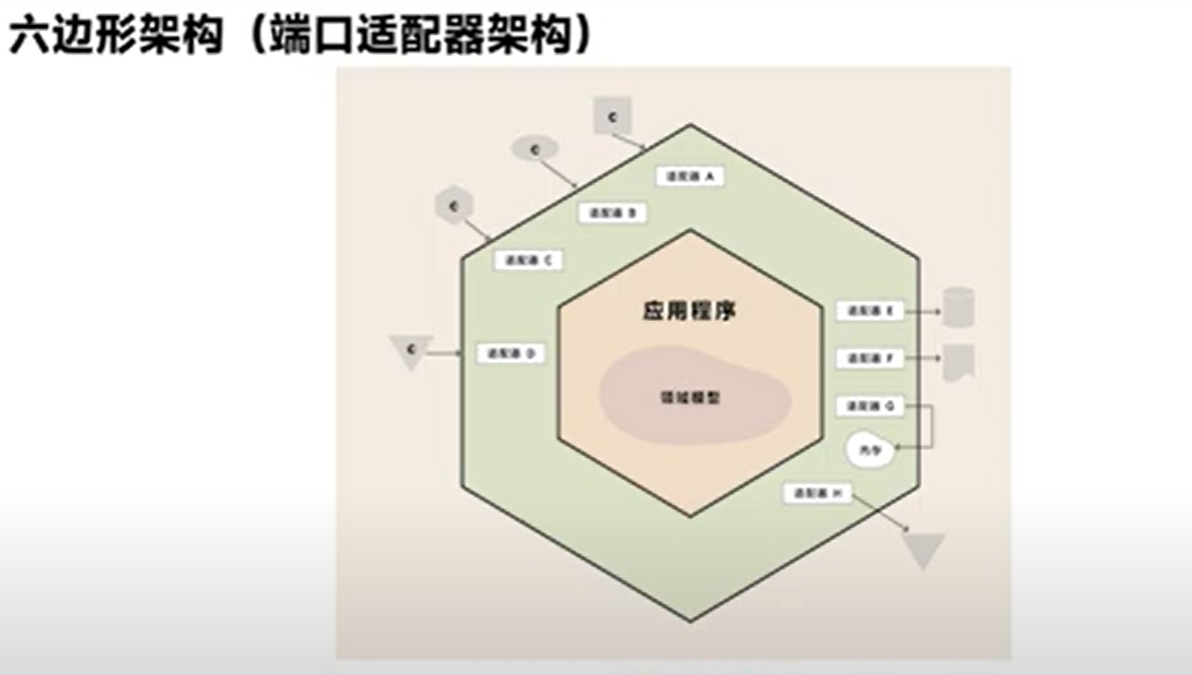

六边形架构(也称为端口与适配器架构)是由Alistair Cockburn提出的,旨在促进应用程序与外部因素(如用户界面、数据库、外部服务等)的解耦。在这种架构中,应用程序的核心逻辑被封装在内部,通过端口(Ports)暴露出服务和数据流接口,适配器(Adapters)负责将这些端口连接到外部系统或服务。
my-springboot-app/
├── src/
│ ├── main/
│ │ ├── java/
│ │ │ ├── com/
│ │ │ │ ├── mycompany/
│ │ │ │ │ ├── MySpringBootApplication.java # 启动类
│ │ │ │ │ ├── application/ # 应用程序的核心逻辑
│ │ │ │ │ │ ├── port/ # 端口定义核心逻辑的接口
│ │ │ │ │ │ └── service/ # 核心业务逻辑实现
│ │ │ │ │ ├── domain/ # 领域模型(实体和领域服务)
│ │ │ │ │ ├── infrastructure/ # 基础设施层(数据库适配器等)
│ │ │ │ │ │ ├── config/ # 配置类
│ │ │ │ │ │ ├── repository/ # 数据库访问适配器
│ │ │ │ │ │ └── ...
│ │ │ │ │ ├── adapter/ # 外部接口适配器
│ │ │ │ │ │ ├── web/ # REST API或Web界面适配器
│ │ │ │ │ │ ├── messaging/ # 消息队列适配器
│ │ │ │ │ │ └── persistence/ # 数据持久化适配器
│ │ │ │ │ └── ...
│ │ │ └── resources/
│ │ │ ├── static/ # 静态资源
│ │ │ ├── templates/ # 模板文件
│ │ │ ├── application.properties # 应用配置文件
│ │ │ └── ...
│ ├── test/
│ │ ├── java/
│ │ │ ├── com/
│ │ │ │ ├── mycompany/
│ │ │ │ │ ├── adapter/ # 适配器层测试
│ │ │ │ │ ├── application/ # 应用层测试
│ │ │ │ │ ├── domain/ # 领域层测试
│ │ │ │ │ └── ...
│ │ └── ...
├── pom.xml # Maven项目配置文件
└── ...
六边形架构的关键概念是:
- 应用程序的内部:应用程序的业务逻辑,包含领域模型和应用服务。
- 端口:定义应用程序提供和需要的服务接口。在Spring中,这可以是通过接口定义的服务,可用于访问应用程序核心或被应用程序核心调用。
- 适配器:将端口连接到具体的技术细节。适配器层负责转换数据,并确保端口可以与外部世界(如数据库、Web客户端或其他应用程序)通信。
- 领域模型:业务规则和逻辑的实现,独立于外部关注点。
- 基础设施:支持持久化和其他交叉关注点的实现细节
菱形对称架构
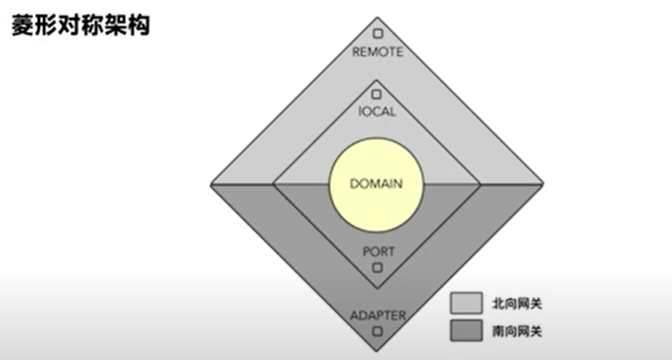

菱形对称架构(Diamond Architecture)是一个不太常见的术语,它不是一个广泛认可的标准软件架构模式,如六边形架构或洋葱架构。如果您是指通过特定的设计模式或原则(如微服务、CQRS、事件溯源)来构建一个对称的、响应性能强的架构,那么这可能指的是系统的不同部分对称地处理命令和查询,或者说读写操作是分离的,类似于CQRS(Command Query Responsibility Segregation)模式。
在CQRS中,命令(执行写操作)和查询(执行读操作)被明确地分开,通常是为了提高大规模系统的性能和可伸缩性。在此模式下,菱形对称架构可能看起来像这样:
- 命令侧:处理创建、更新、删除操作的系统部分。
- 查询侧:处理数据读取和显示的系统部分。
由于“菱形对称架构”不是一个标准术语,我将提供一个基于CQRS模式的架构示例,它可能与您所说的菱形对称架构有关联
my-application/
├── cmd/ # 命令侧
│ ├── src/
│ │ ├── main/
│ │ │ ├── java/
│ │ │ │ ├── command/ # 处理命令的逻辑
│ │ │ │ ├── model/ # 领域模型,聚合根,实体
│ │ │ │ └── ...
│ │ │ └── resources/
│ │ │ └── application.properties
│ └── pom.xml
├── query/ # 查询侧
│ ├── src/
│ │ ├── main/
│ │ │ ├── java/
│ │ │ │ ├── query/ # 查询处理器,视图模型
│ │ │ │ ├── view/ # 数据视图,展示逻辑
│ │ │ │ └── ...
│ │ │ └── resources/
│ │ │ └── application.properties
│ └── pom.xml
└── common/ # 公共库,包含共享代码
├── src/
│ ├── main/
│ │ ├── java/
│ │ │ ├── events/ # 领域事件
│ │ │ ├── util/ # 工具类
│ │ │ └── ...
限界上下文
背景
假设我们正在开发一个在线零售平台,这个平台包含以下几个关键的业务领域:
- 商品目录(Product Catalog):管理商品信息,如名称、描述、价格等。
- 订单管理(Order Management):处理客户订单的创建、支付、状态跟踪等。
- 库存管理(Inventory Management):追踪商品库存量,管理库存补充。
- 客户关系管理(Customer Relations):维护客户信息,处理客户咨询和投诉。
限界上下文划分
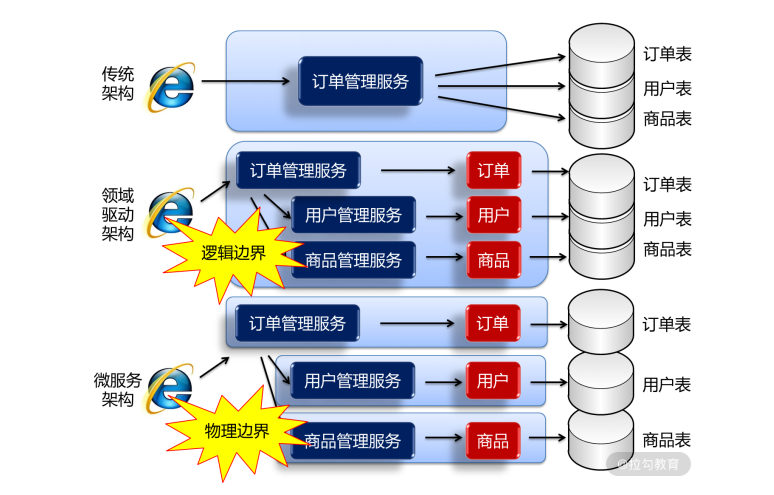
- 过去,每个模块在读取用户信息时,都是直接读取数据库中的用户信息表,那么一旦用户信息表发生变更,各个模块都要变更,变更成本就会越来越高。
- 现在,采用领域驱动设计,读取用户信息的职责交给了“用户管理”限界上下文,其他模块都是调用它的接口,这样,当用户信息表发生变更时,只与“用户管理”限界上下文有关,与其他模块无关,变更维护成本就降低了。通过限界上下文将整个系统按照逻辑进行了划分,但从物理上它们都还是一个项目、运行在一个 JVM 中,这种限界上下文只是“逻辑边界”。
- 今后,将单体应用转型成微服务架构以后,各个限界上下文都是运行在各自不同的微服务中,是不同的项目、不同的 JVM。不仅如此,进行微服务拆分的同时,数据库也进行了拆分,每个微服务都是使用不同的数据库。这样,当各个微服务要访问用户信息时,它们没有访问用户数据库的权限,就只能通过远程接口去调用“用户”微服务开放的相关接口。这时,这种限界上下文就真正变成了“物理边界”,如下图所示:
1. 商品目录限界上下文:
- 聚焦业务:商品信息的管理和展示。
- 模型:商品(Product)、分类(Category)、描述(Description)等。
- 特点:关注于如何展示和描述商品,以吸引客户购买。
2. 订单管理限界上下文:
- 聚焦业务:订单的生命周期管理,包括订单创建、支付处理、状态更新等。
- 模型:订单(Order)、订单项(OrderItem)、支付信息(PaymentInfo)等。
- 特点:处理客户下单流程和支付流程,保证订单状态正确管理。
3. 库存管理限界上下文:
- 聚焦业务:库存量的监控和调整。
- 模型:库存项(InventoryItem)、补货单(RestockOrder)等。
- 特点:确保商品库存量准确,及时补充库存以满足销售需求。
4. 客户关系管理限界上下文:
- 聚焦业务:维护客户资料,处理客户咨询和投诉。
- 模型:客户(Customer)、咨询(Inquiry)、投诉(Complaint)等。
- 特点:提升客户满意度和忠诚度,处理客户的反馈和问题。
上下文间的交互
虽然每个限界上下文都有其独立的模型和逻辑,但它们之间需要通过明确定义的接口(对外接口)和事件(领域事件)进行交互。例如:
- 当订单管理中创建新订单时,需要与库存管理进行交互,确保所购买的商品有足够的库存。
- 商品目录中的商品信息更新,可能需要通知到订单管理和库存管理,以便它们可以同步最新的商品信息。
小结
通过将在线零售系统划分为不同的限界上下文,我们能够清晰地管理和开发复杂的业务需求。每个限界上下文都聚焦于特定的业务领域,具有独立的模型和逻辑,同时通过定义良好的接口和事件与其他上下文进行交互,确保整个系统的协调一致性。这样的划分有助于团队更有效地开发和维护系统,同时也使得系统更加灵活,能够适应未来的业务变化
个人理解:
可以使用类似feign接口对外的api,不暴露内部具体实现以及领域事件来实现不同限界上下文的沟通,限界上下文跟领域模型有很大关系,确定了边界,业务,特点,再创建模型,就是所谓的领域模型,而领域模型,就包括了用于描述和处理某个业务领域问题的对象模型。它包括实体(Entities)、值对象(Value Objects)、聚合(Aggregates)、域服务(Domain Services)(独立于各个服务的一个聚合体比如OrderPaymentService)、领域事件(Domain Events)等元素。领域模型反映了业务专家的语言和业务规则,它是业务知识在软件中的表现形式。
具体实现:
假如将整个系统中那么多的场景、涉及的那么多领域对象,全部绘制在一张大图上,可以想象这张大图需要绘制出密密麻麻的领域对象,以及它们之间纷繁复杂的对象间关系。绘制这样的图,绘制的人非常费劲,看这张图的人也非常费劲,这样的图也不利于我们理清思路、
正确的做法就是将整个系统划分成许多相对独立的业务场景,在一个一个的业务场景中进行领域分析与建模,这样的业务场景称为 “问题子域”,简称“子域”。
领域驱动核心的设计思想,就是将对软件的分析与设计还原到真实世界中,那么就要先分析和理解真实世界的业务与问题。而真实世界的业务与问题叫作 “问题域”,这里面的业务规则与知识叫 “业务领域知识”,譬如:
- 电商网站的“问题域”是人们如何进行在线购物,购物的流程是怎样的;
- 在线订餐系统的“问题域”是人们如何在线订餐,饭店如何在线接单,系统又是如何派送骑士去配送的。
因此需要采用 “分而治之”的策略,将这个问题域划分成许多个问题子域。比如:
- 电商网站包含了用户选购、下单、支付、物流等多个子域;
- 在线订餐系统包含了用户下单、饭店接单、骑士派送等子域。
如果某个子域比较复杂,在子域的基础上还可以进一步划分子域。
因此,一个复杂系统的领域驱动设计,就是以子域为中心进行领域建模,绘制出一张一张的领域模型设计,然后以此作为基础指导程序设计。这一张一张的领域模型设计,称为“限界上下文”(Context Bounds,CB)
实例二:
在这个业务场景中,“用户下单”限界上下文属于“主题域”,而“用户注册”与“饭店管理”限界上下文属于“支撑域”
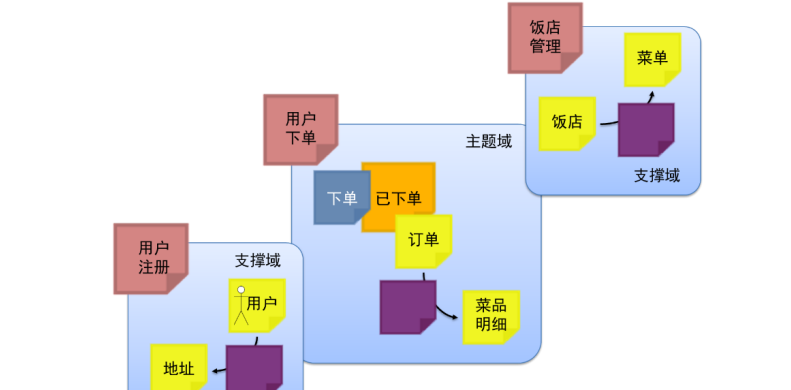
“已下单”的限界上下文分析图
用户下单操作,可以在主体域也就是订单里面实现,相关的领域模型,也可以绘制出来了
其他支撑域采用微服务的 远程接口,不允许使用联表
微服务技术实践
怎样提供微服务接口
因此,微服务的设计彼此之间不是孤立的,它们需要相互调用接口实现高内聚。然而,当一个微服务团队向另一个微服务团队提出接口调用需求时,另一个微服务团队该如何设计呢?
首先第一个问题,当多个团队都在向你提出 API 接口时,你怎么提供接口。如果每个团队给你提需求,你就必须要做一个新接口,那么你的微服务将变得非常不稳定。因此,当多个团队向你提需求时,必须要对这些接口进行规划,通过复用用尽可能少的接口满足他们的需求;当有新的接口提出时,要尽量通过现有接口解决问题。这样做,你就能用更低的维护成本,更好地维护自己的微服务。
接着,当调用方需要接口变更时怎么办?变更现有接口应当尽可能向前兼容,即接口的名称与参数都不变,只是在内部增加新的功能。这样做是为了不影响其他微服务的调用。如果确实需要更改现有的接口怎么办?宁愿增加一个新的接口也最好不要去变更原有的接口。
实现: 在微服务的本地新增一个“用户注册 Service”的 feign 接口这就是“防腐层”的作用,即接口变更时降低维护成本
去中心化的数据管理
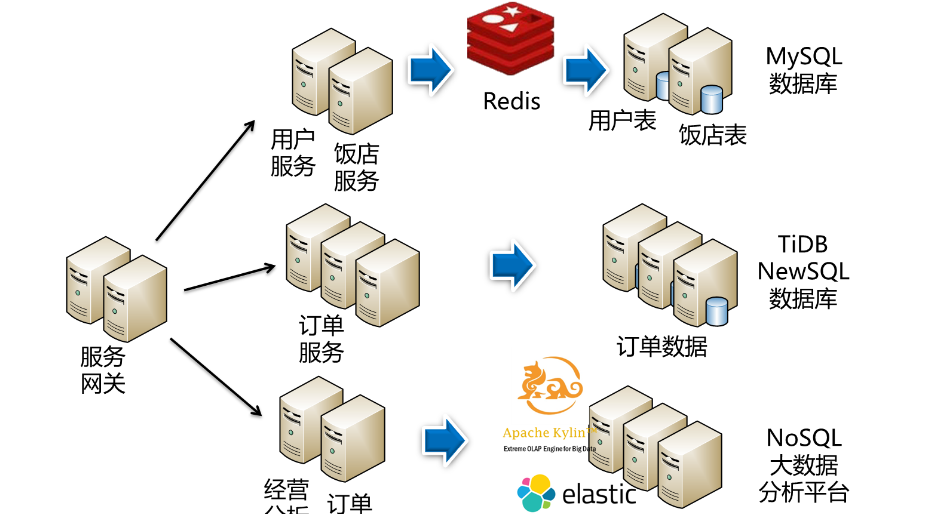
按照前面 DDD 的设计,已经将数据库按照微服务划分为用户库、下单库、接单库、派送库与饭店库。这时候,如何来落地这些数据库的设计呢?微服务系统最大的设计难题就是要面对互联网的高并发与大数据。因此,可以按照“去中心化数据管理”的思想,根据数据量与用户访问特点,选用不同的数据存储方案存储数据:
- 微服务“用户注册”与“饭店管理”分别对应的用户库与饭店库,它们的共同特点是数据量小但频繁读取,可以选用小型的 MySQL 数据库并在前面架设 Redis 来提高查询性能;
- 微服务“用户下单”“饭店接单”“骑士派送”分别对应的下单库、接单库、派送库,其特点是数据量大并且高并发写,选用一个数据库显然扛不住这样的压力,因此可以选用了 TiDB 这样的 NewSQL 数据库进行分布式存储,将数据压力分散到多个数据节点中,从而解决 I/O 瓶颈;
- 微服务“经营分析”与“订单查询”这样的查询分析业务,则选用 NoSQL 数据库或大数据平台,通过读写分离将生产库上的数据同步过来进行分布式存储,然后经过一系列的预处理,就能应对海量历史数据的决策分析与秒级查询。
基于以上这些设计,就能完美地应对互联网应用的高并发与大数据,有效提高系统性能。设计如下图所示:
数据关联查询的难题(重构join)
此外,各个微服务在业务进行过程需要进行的各种查询,由于数据库的拆分,就不能像以前那样进行 join 操作了,而是通过接口调用的方式进行数据补填。比如“用户下单”“饭店接单”“骑士派送”等微服务,由于数据库的拆分,它们已经没有访问用户表与饭店表的权限,就不能像以往那样进行 join 操作了。这时,需要重构查询的过程。如下图所示
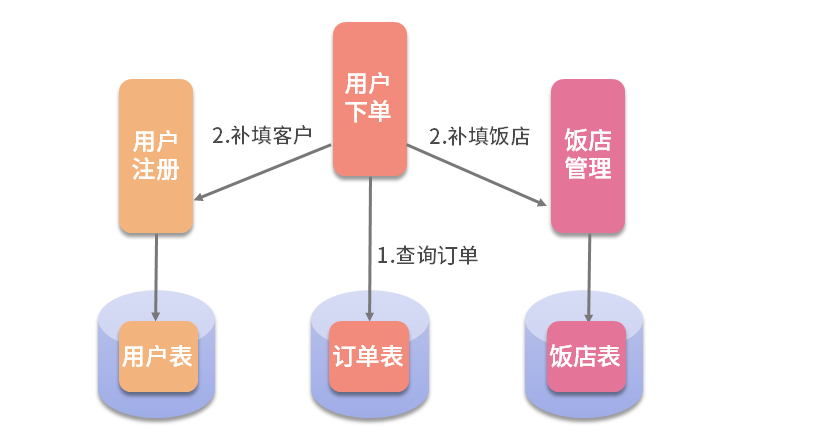
查询的过程分为 2 个步骤。
- 查询订单数据,但不执行 join 操作。这样的查询结果可能有 1 万条,但通过翻页,返回给微服务的只是那一页的 20 条数据。
- 再通过调用“用户注册”与“饭店管理”微服务的相关接口,实现对用户与饭店数据的补填。
这种方式,既解决了跨库关联查询的问题,又提高了海量数据下的查询效率。注意,传统的数据库设计之所以在数据量越来越大时,查询速度越来越慢,就是因为存在 join 操作。因而,在面对海量数据的查询时,干掉 join 操作,改为分页后的数据补填,就能有效地提高查询性能。
然而,在查询订单时,如果要通过用户姓名、联系电话进行过滤,然后再查询时,又该如何设计呢?这里千万不能先过滤用户数据,再去查询订单,这是一个非常糟糕的设计。我们过去的数据库设计采用的都是3NF(第 3 范式),它能够帮助我们减少数据冗余,然而却带来了频繁的 join 操作,降低了查询性能。因此,为了提升海量数据的查询性能,适当增加冗余,即在订单表中增加用户姓名、联系电话等字段。这样,在查询时直接过滤订单表就好了,查询性能就得到了提高。
最后,当系统要在某些查询模块进行订单查询时,可能对各个字段都需要进行过滤查询。这时就不再采用数据补填的方式,而是利用 NoSQL 的特性,采用“宽表”的设计。按照这种设计思路,当系统通过读写分离从生产库批量导入查询库时,提前进行 join 操作,然后将 join 以后的数据,直接写入查询库的一个表中。由于这个表比一般的表字段更多,因此被称为“宽表”。
由于 NoSQL 独有的特性,为空的字段是不占用空间的,因此字段再多都不影响查询性能。这样,在日后的查询时,就不再需要 join 操作,而是直接在这个单表中进行各种过滤、各种查询,从而在海量历史数据中实现秒级查询。因此,“订单查询”微服务在数据库设计时,就可以通过NoSQL 数据库建立宽表,从而实现高效的数据查询。
DDD指导微服务最终实现
限界上下文(确认事件和接口,调用关系) -> 问题子域(处理某个业务模块的统称)->领域模型(实体,服务,值对象)(充血/贫血)(增删改可以增加聚合根包括缓存,异构数据源多个表事务实现)->数据库 (设计)
在 DDD 指导微服务设计的过程中:
- 首先按照限界上下文进行微服务的拆分,按照上下文地图定义各微服务之间的接口与调用关系;
- 在此基础上,通过限界上下文的划分,将领域模型划分到多个问题子域,每个子域都有一个领域模型的设计;
- 这样,按照各子域的领域模型,基于充血模型与贫血模型设计各个微服务的业务领域层,即各自的 服务 、实体 与 值对象;
- 同时,按照领域模型设计各个微服务的数据库。
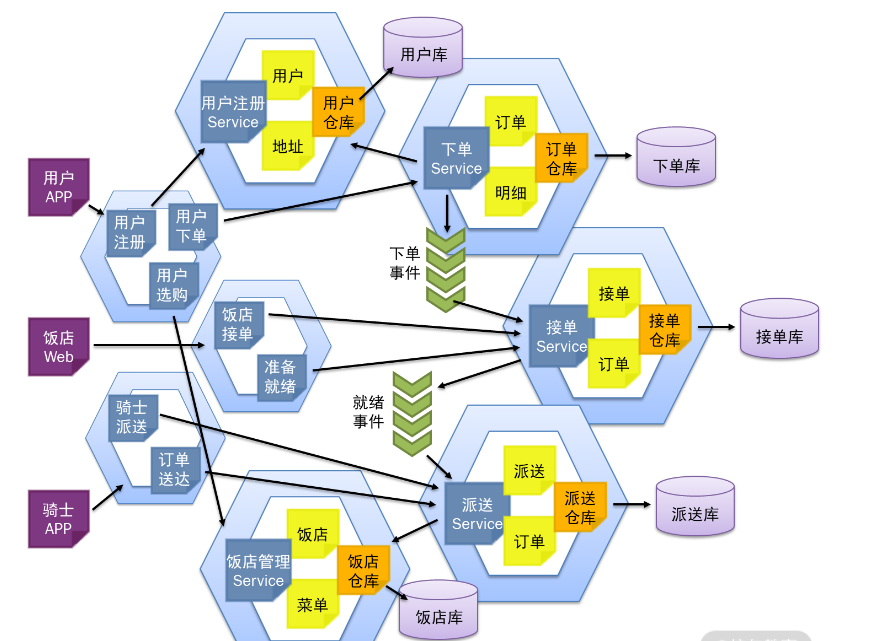
最后,将以上的设计最终落实到微服务之间的调用、领域事件的通知,以及前端微服务的设计。如下图所示
具体建模实现
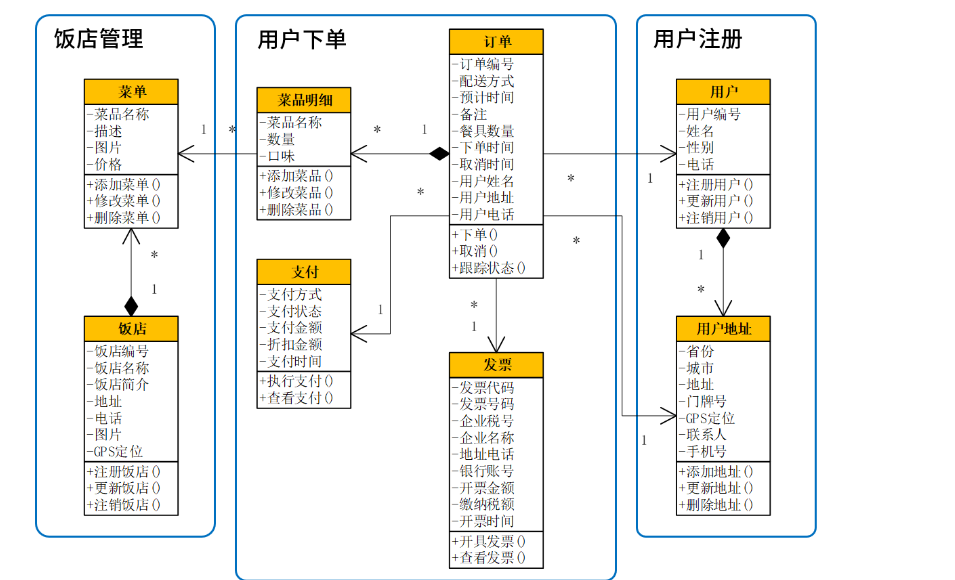
用户下单领域建模:
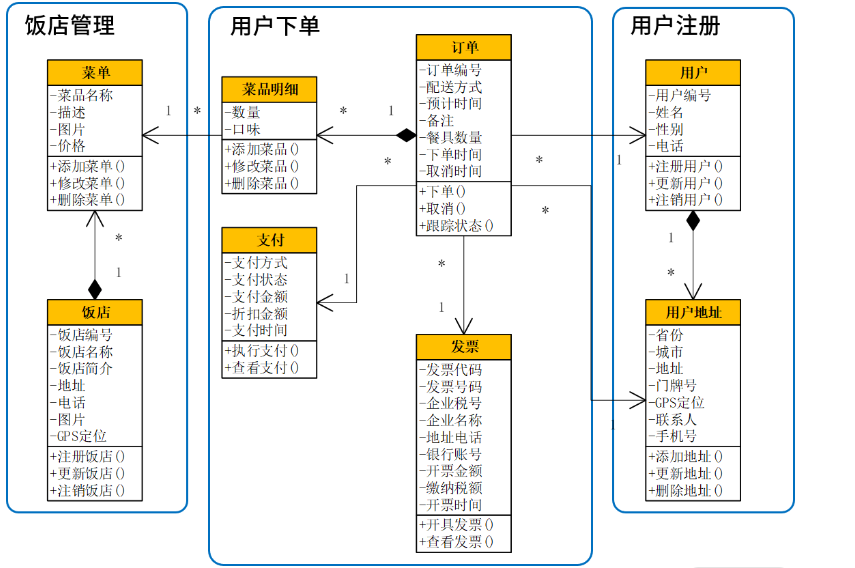
在这样的基础上开始划分限界上下文,用户与用户地址属于“用户注册”上下文,饭店与菜单属于“饭店管理”上下文。它们对于“用户下单”上下文来说都是支撑域,即给“用户下单”上下文提供接口调用的。真正属于“用户下单”上下文的,就只有订单、菜品明细、支付、发票这几个类,它们最终形成了“用户下单”微服务及其数据库设计。由于用户姓名、地址、电话等信息,都在“用户注册”上下文中,每次都需要远程接口调用来获得。这时就需要从系统优化的角度,适当将它们冗余到“订单”领域对象中,以提升查询效率。同样,“菜品名称”也进行了冗余
事件通知机制
每个微服务在执行完某个领域事件的操作以后,就将领域事件封装成消息发送到消息队列中。比如,“用户下单”微服务在完成用户下单以后,将下单事件放到消息队列中。这样,不仅“饭店接单”微服务可以接收这个消息,完成后续的接单操作;而且“订单查询”微服务也可以接收这个消息,实现订单的跟踪。
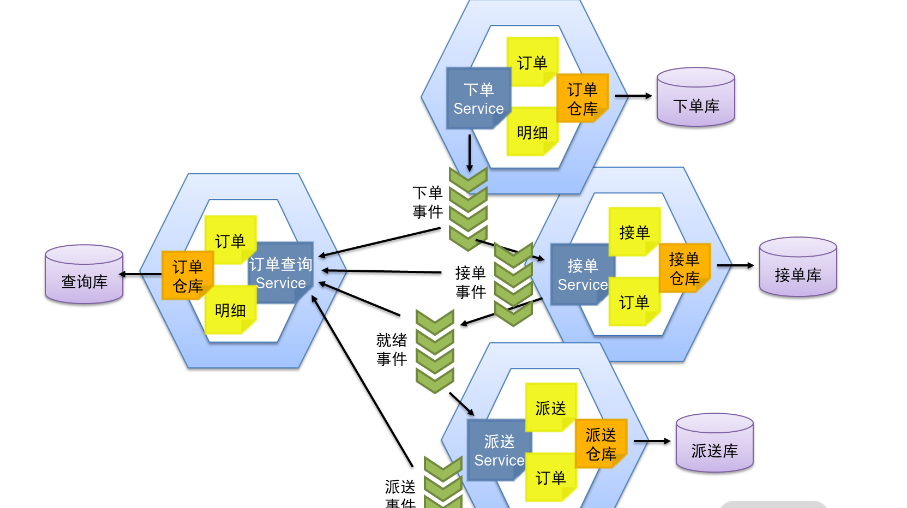
通过领域事件的通知与消息队列的设计,使微服务间调用的设计松耦合,“订单查询”微服务可以像外挂一样采集各种订单状态,同时不影响原有的微服务设计,使得微服务之间实现解耦,降低系统维护的成本。而“订单查询”微服务通过冗余,将“下单时间”“取消时间”“接单时间”“就绪时间”等订单在不同状态下的时间,以及其他相关信息,都保存到订单表中,甚至增加一个“订单状态”记录当前状态,并增加 Redis 缓存的功能。这样的设计就保障了订单跟踪查询的高效。要知道,面对大数据的高效查询,通常都是通过冗余来实现的
事件具体实现增加朔源
前面讲解了领域溯源的设计思路,最后要落地到项目实践中,依然需要技术中台的相应支持。譬如,业务系统的发布者只负责事件的发布,订阅者只负责事件的后续操作。但这个过程该如何发布事件呢?发布事件到底要做什么呢?又如何实现事件的订阅呢?这就需要下沉到技术中台去设计。
首先,事件的发布方在发布事件的同时,需要在数据库中予以记录。数据库可以进行如下设计:
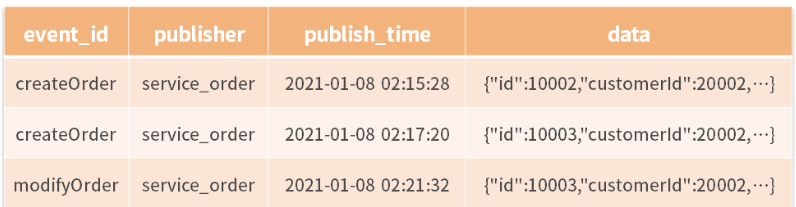
接着,领域事件还需要通过消息队列进行发布,这里可以采用 Spring Cloud Stream 的设计方案。Spring Cloud Stream 是 Spring Cloud 技术框架中一个实现消息驱动的技术框架。它的底层可以支持 RabbitMQ、Kafka 等主流消息队列,通过它的封装实现统一的设计编码。
譬如,以 RabbitMQ 为例,首先需要在项目的 POM.xml 中加入依赖:
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>
</dependencies>
接着,在 bootstrap.yml 文件中,将领域事件与消息队列绑定。例如,在“用户下单”微服务中定义领域事件的发布,如下代码所示:
spring:
rabbitmq:
host: xxx.xxx.xxx.xxx
port: 5672
username: guest
password: guest
cloud:
stream:
bindings:
createOrder:
destination: createOrder
modifyOrder:
destination: modifyOrder
然后,定义领域事件及其客户端,如下代码所示:
public interface CreateOrderEventClient {
String OUTPUT = "createOrder";
@Output(CreateOrderEventClient.OUTPUT)
MessageChannel output();
}
@EnableBinding(value=CreateOrderEventClient.class)
@Component
public class CreateOrderEvent {
@Autowired
private CreateOrderEventClient client;
/**
* @param publisher
* @param data
*/
public void publish(String publisher, Object data) {
String eventId = "createOrder";
Date publishTime = DateUtils.getNow();
DomainEventObject event = new DomainEventObject(eventId,
publisher, publishTime, data);
event.save();
client.output().send(MessageBuilder.withPayload(event).build());
}
}
在“用户下单”微服务中,如上所述依次定义每个领域事件,如用户下单、修改订单、取消订单,等等。这样,在“用户下单”微服务完成相应操作时,领域事件就会发布到消息队列中。
最后,再由订阅者去完成对消息队列的订阅,并完成相应操作。这时,还是先在 bootstrap.yml文件中绑定领域事件,如下代码所示:
spring:
profiles: dev
rabbitmq:
host: 118.190.201.78
port: 31672
username: guest
password: guest
cloud:
stream:
bindings:
createOrder:
destination: createOrder
group: ${spring.application.name}
modifyOrder:
destination: modifyOrder
group: ${spring.application.name}
这里增加了一个 group,当该服务进行多节点部署时,每个事件只会有一个微服务接收并予以处理。接着,定义领域事件类,一方面监听消息队列,一方面定义后续需要完成什么操作:
public interface CreateOrderEventClient {
String INPUT = "createOrder";
@Input(CreateOrderEventClient.INPUT)
SubscribableChannel input();
}
@Component
@EnableBinding(value= {CreateOrderEventClient.class})
public class CreateOrderEvent {
@StreamListener(CreateOrderEventClient.INPUT)
public void apply(DomainEventObject obj) {
...
}
}
这时,在“饭店接单”与“订单跟踪”微服务都有 CreateOrderEvent 这个领域事件,然而它们各自的 apply() 方法要完成的事情是不一样的,就可以彼此独立地完成各自的工作。比如:“饭店接单”是发送消息给前端,通知饭店完成接单操作,而“订单跟踪”则是接收到信息以后,更新订单的相应状态。但不论是谁,都会在各自的数据库中记录下接收的领域事件。














 834
834











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









