







Drain:An Online Log Parsing Approach with Fixed Depth Tree
文章目录
1 论文出处
- 会议/期刊:ICWS(International Conference on Web Services)
- 级别:CCF-B
- 时间:2017
2 背景
2.1 背景介绍
如今,越来越多的开发人员利用现有的Web服务来构建他们自己的系统,在此背景下,基于日志分析的服务管理技术,即利用服务日志来实现自动或半自动的服务管理,已经得到了广泛的研究。因此,应用数据挖掘模型来了解系统行为的日志分析技术被广泛应用于服务管理。
在这些日志分析技术中使用的大多数数据挖掘模型都需要结构化的输入(例如,一个事件列表或一个矩阵)。但是,原始日志消息通常是非结构化的,因为开发人员可以在源代码中编写自由文本的日志消息。因此,日志分析的第一步是日志解析,其中非结构化日志消息被转换为结构化事件。非结构化日志消息,如下例所述,通常包含各种形式的系统运行时信息:时间戳(记录事件发生的时间)、冗长级别(指示事件的严重性级别,例如,INFO)和原始消息内容(服务操作的自由文本描述)。
2.2 针对问题
随着日志量的快速增加,在日志收集后使用所有现有日志的离线日志解析方法的模型训练变得非常耗时,而且大多数现有的日志解析方法都集中在离线的、日志的批处理上。
2.3 创新点
提出了一种在线的流处理日志解析方法,利用深度解析树结构。
3 主要设计思路
3.1 Drain整体结构
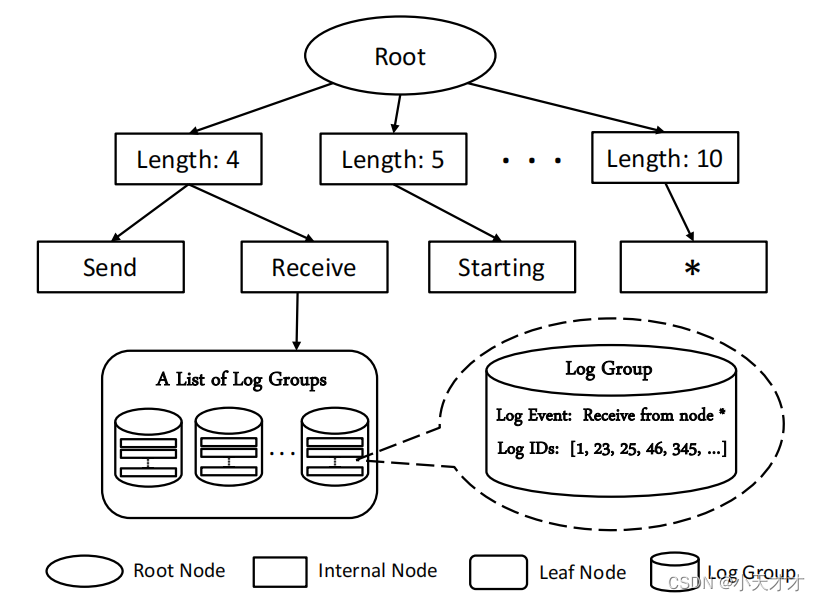
解析树中的每个路径都以一个叶节点结束,该节点存储一个日志组列表,为了简单起见,我们在这里只绘制一个叶节点。每个日志组都有两个部分:日志事件和日志ID。
- 日志事件是最能描述该组中的日志消息的模板,该组由日志消息的常量部分组成。
- 日志ID将记录此组中的日志消息的ID。
解析树的一种特殊设计是,所有叶节点的深度都是相同的,并且由一个预定义的参数深度来固定。例如,图2中的叶节点的深度被固定为3。该参数限制了搜索过程中引流访问的节点数,大大提高了其效率。此外,为了避免树枝爆炸,我们采用了一个参数 ,它限制了一个节点的最大子节点的数量。
3.2 具体步骤
(1)按领域知识进行预处理
Drain允许用户提供基于表示常用变量的域知识的简单正则表达式,如IP地址和块ID。然后,将删除由这些正则表达式从原始日志消息中匹配的标记。例如,图1中的块id将被“blk[0-9]+”删除。在此步骤中使用的正则表达式通常非常简单,并且一个数据集通常只需要少数这样的正则表达式。例如,在我们的计算部分中使用的数据集最多需要两个这样的正则表达式。
(2)按日志消息长度进行搜索
解析树中的第一层节点表示日志消息具有不同日志消息长度的日志组,在此步骤中,Drain会根据预处理的日志消息的日志消息长度选择到第一层节点的路径。例如,对于日志消息“Receive from node 4”,将导线引流到图2中的内部节点“Length:4”。这是基于具有相同日志事件的日志消息可能具有相同的日志消息长度的假设。
(3)通过前面的标记进行搜索
在此步骤中,Drain从步骤2中搜索的一个第一层节点遍历到一个叶节点。这一步是基于日志消息开始位置中的标记更有可能是常量的假设。具体来说,Drain通过日志消息开始位置的标记选择下一个内部节点。例如,对于日志消息“Receive from node 4”,排水管从第一层节点“Length:4”穿越到第二层节点“Receive”,因为在日志消息的第一个位置的标记是“Receive”。然后,Drain将遍历到与内部节点“Receive”链接的叶节点,并转到步骤4。
(4)按标记相似度搜索
在此步骤中,Drain将从日志组列表中选择最合适的日志组。我们计算每个日志组的日志消息和日志事件之间的相似性simSeq。simSeq的定义如下:

|

|
其中,seq1和seq2分别表示日志消息和日志事件;seq (i)为序列的第i个标记;n为序列的日志消息长度。我们将其与预定义的相似度阈值进行比较。如果simSeq远远大于这个阈值,则Drain将返回组作为最合适的日志组。否则,Drain将返回一个标志(例如,Python中的None),以表示没有合适的日志组。
(5)更新解析树
如果在步骤4中返回了合适的日志组,则Drain系统将把当前日志消息的日志ID添加到返回的日志组中的日志ID中。此外,还将更新返回的日志组中的日志事件。如果排水无法找到合适的日志组,则会根据当前日志消息创建一个新的日志组,其中日志ID只包含日志消息的ID,而日志事件正是日志消息。例如,假设当前的解析树是下图左侧的树,并且会到达一个新的日志消息“Receive 120 bytes”。然后,Drain将把解析树更新到下图右侧的树。请注意,第三层中的新内部节点被编码为“*”,因为标记“120”包含数字。

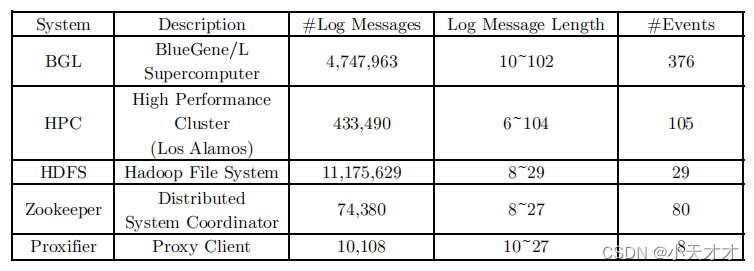
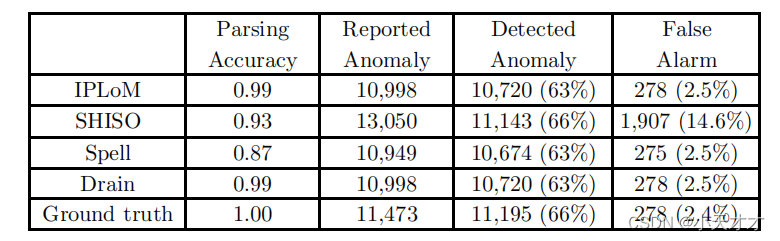
4 实验设计
五种日志数据集,与四种传统方法(2在线2离线)比较,准确率、精度和召回,最后基于PCA+不同的解析方法进行异常检测比较
(1)准确率与运行时间

(2)不同规模对运行时间的影响

(3)异常检测结果(基于PCA)
5 个人总结
Drain是一种在线日志解析方法,通过正则表达式可以将常量与变量分离,加以改进可以把参数提取出来,减少模板数量,同时本篇文章提供了五种日志的解析结果以及相应的设置参数,后期可以考虑用这种方法进行日志解析,并考虑如何引入参数来进行异常检测。
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











