






1.学习路径
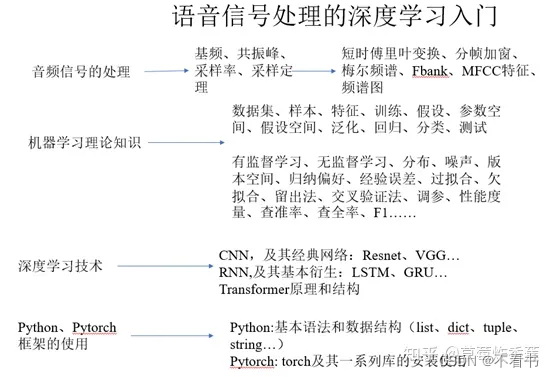
引自语音信号处理的深度学习入门 - 知乎 (zhihu.com)
2.音频信号简介
语音其实是人类采集的声音的幅度强度随着时间变化的一系列点。如下图为汉语元音韵母 “a”的声音波形图的一部分。

声音即为空气分子不断的振动和传播。把声音想象成水龙头中流出的水流,用一个传感器以某种频率探入这股水流,每探测一次测量一次声音的振幅强度以及振动的方向,即可以得到一系列的随时间变化的点。这种频率就是采样频率。
例如有一个语音,某个录音机器以 16000个点/秒的速度(采样率)去测试这个声音, 测了2s,我们则会得到 2 * 16000 = 32000个采样点。 也就是说,实际在图片里看到的曲线虽然是连续的曲线,但是实际上是由 离散的有间隔的点组成的。
因此我们得出一个 公式: 采样率 * 语音时长 = 语音采样点数。
同样的采样率的情况下,语音的采样点数越多,就会导致语音文件的大小越大。
对于人类发出的声音,有基频、共振峰、基音周期等概念。简单地理解声音的产生: 能量通过声带使其振动产生一股基声音,这个基声音再通过声道,与声道发生相互作用产生共振声音,基声音与共振声音一起传播出去。
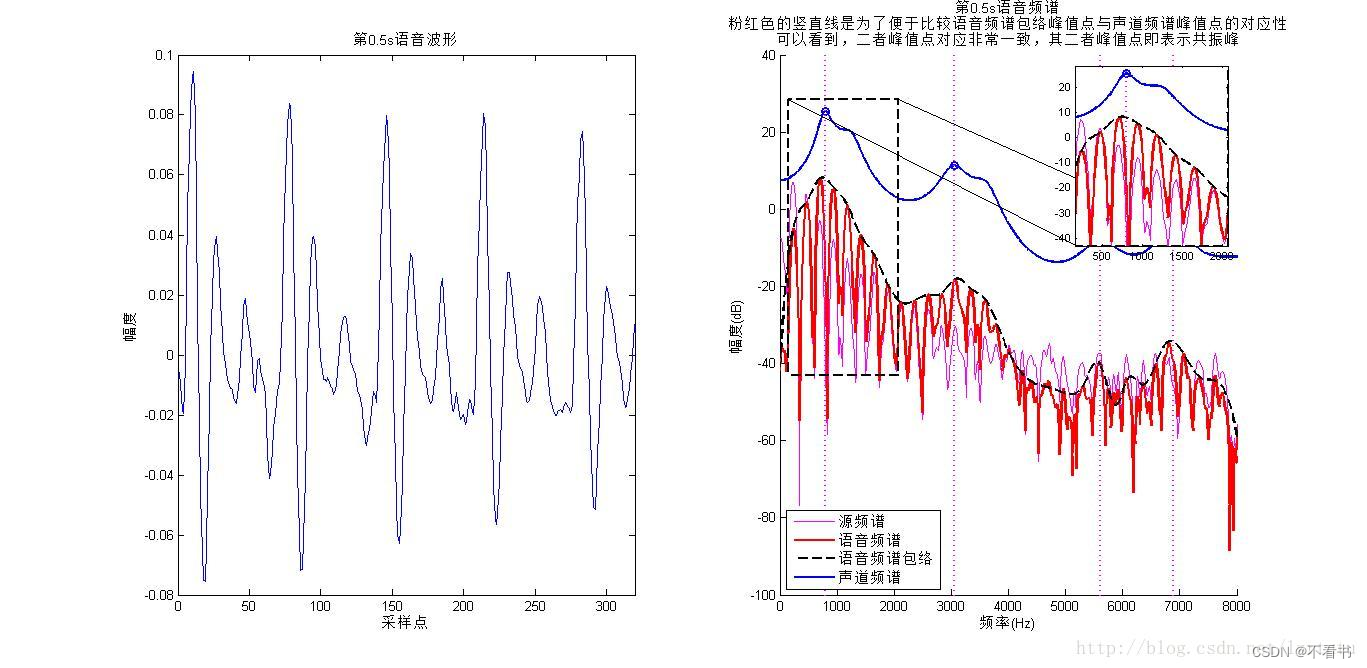
基音频率体现的是声源的信息,而共振峰体现的是声道的信息。下图粉红线是声源信息的频谱,红线是语音的频谱,黑色虚线是语音频谱的包络,蓝线是声道频谱,蓝色圈圈标示出声道频谱的峰值点,粉红虚竖线显示这些峰值点的位置,可以观察到,语音频谱的包络显示的是声道的信息,而小尖峰显示声源的信息,如谐波。
3.语音信号处理

传统的语音信号处理,主要是傅里叶变换(FFT)的一系列操作,和小波变换两种。而在深度学习领域使用最多是傅里叶变换。
在讨论分帧、预加重和加窗之前,我们先来学习傅里叶变换,从傅里叶变换中遇到的问题,再讨论分帧等操作。
傅里叶级数与傅里叶变换
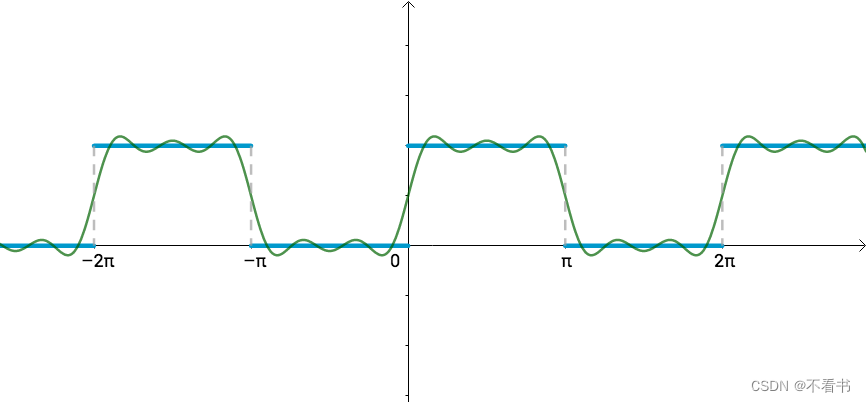
傅里叶级数由任意周期函数都可以写成三角函数之和这一猜测开始,从代数上看,傅立叶级数就是通过三角函数和常数项来叠加逼近周期为T的函数f(x):
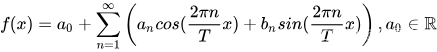
 但对于一个非周期函数,写成三角级数的形式可能是困难的。
但对于一个非周期函数,写成三角级数的形式可能是困难的。
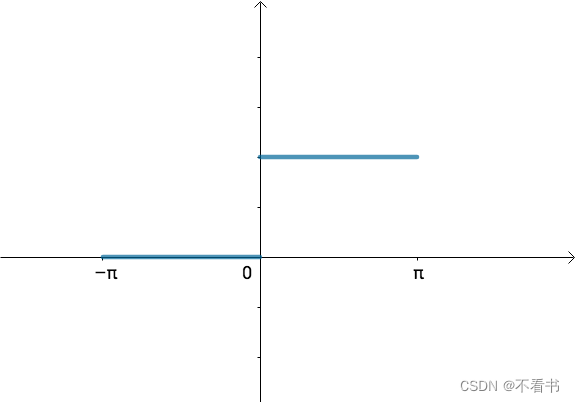
傅里叶变换的基本思想是:非周期性的信号也是可以由多个周期性的 信号叠加而逼近得到的,只要我们将T取为无限大就行。为了便于计算a0,an和bn,我们根据欧拉公式先将傅里叶级数从时域变换到频域。
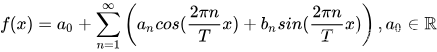
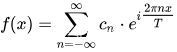
其中, ![]()
然后我们将T取为无穷大
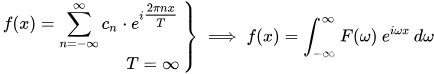
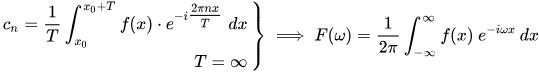
经过FFT计算,我们再将结果变回时域,最终的时域结果可能是这样的:
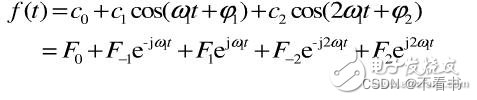
其中:
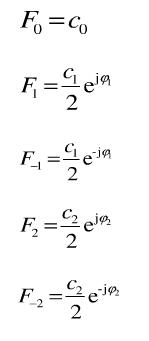
基于时域结果,我们可以绘制幅度谱与相位谱(周期函数)。
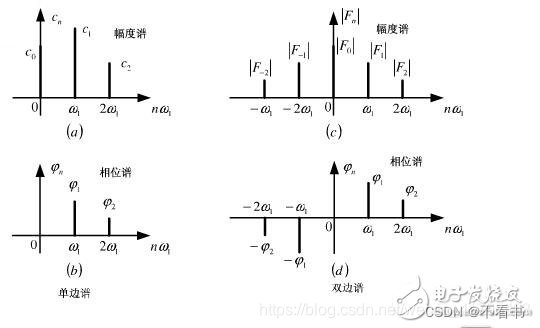
那么问题来了,对于频率随着时间变化的非平稳信号,在进行FFT后,我们发现这三个时域上有巨大差异的信号,频谱(幅值谱)却非常一致。尤其是下边两个非平稳信号,我们从频谱上无法区分它们,因为它们包含的四个频率的信号的成分确实是一样的,只是出现的先后顺序不同。
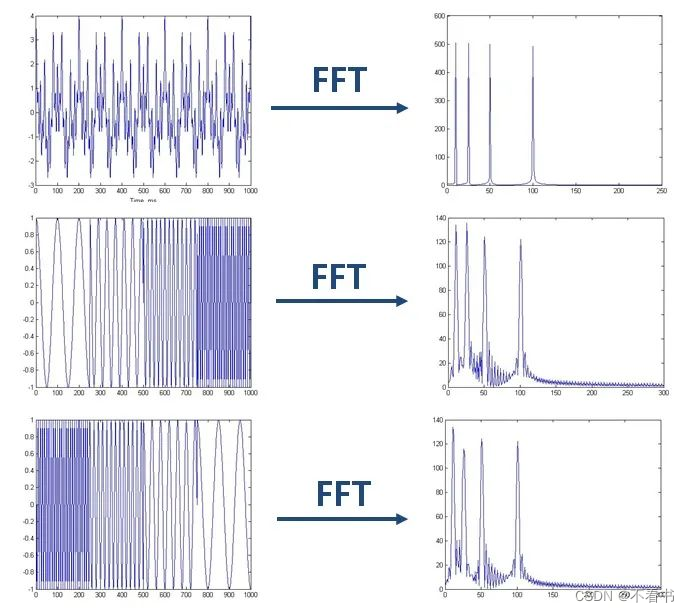
可见,傅里叶变换处理非平稳信号有天生缺陷。它只能获取一段信号总体上包含哪些频率的成分,但是对各成分出现的时刻并无所知。时域相差很大的两个信号,可能频谱图一样。短时傅里叶变换(Short-time Fourier Transform, STFT)能帮助我们结合信号在时域和频域的特征,进行时频分析。
短时傅里叶变换(Short-time Fourier Transform, STFT)
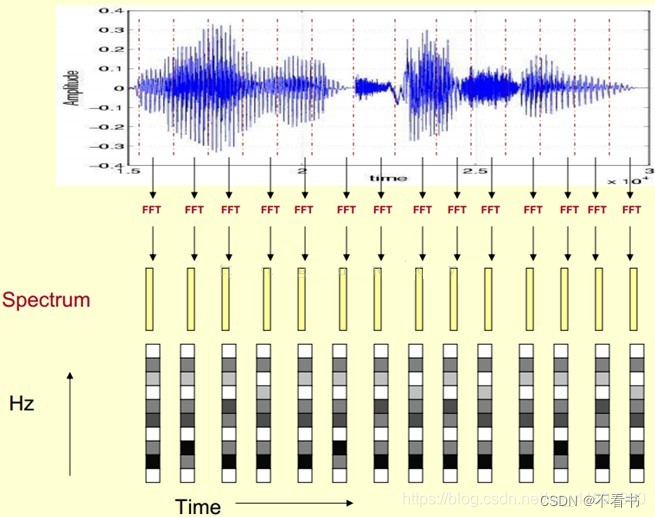
一个简单可行的方法就是——加窗。把整个时域过程分解成无数个等长的小过程,每个小过程近似平稳,再傅里叶变换,就知道在哪个时间点上出现了什么频率了。具体操作上,就是对一段长语音信号,分帧、加窗,再对每一帧做傅里叶变换,对于每一帧结果,我们以时间为横轴,频率(Hz)为纵轴,对应频率的幅值(或相位、功率)通过颜色深浅表示,之后把每一帧的结果沿另一维度堆叠,得到一张图(类似于二维信号/热力图),这张图就是语谱图。
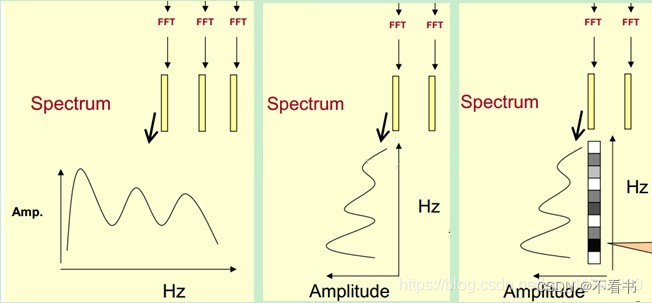

对于分帧的窗口大小与帧移,需要具体根据信号而定。
上面的例子,我们把10,20,30…3000作为纵坐标,时间帧的数量作为横坐标,幅度(STFT特征)数值的大小以颜色表示,即得到了语谱图。获得语谱图后,我们紧接着进行mel滤波处理。
由于得到的声谱图较大,为了得到合适大小的声音特征,通常将它通过梅尔尺度滤波器组(Mel-scale filter banks),变为梅尔频谱。
频率的单位是HZ,人耳能听到的频率范围是20-20000HZ,但是人耳对HZ单位不是线性敏感,而是对低HZ敏感,对高HZ不敏感,将HZ频率转化为梅尔频率,则人耳对频率的感知度就变为线性。
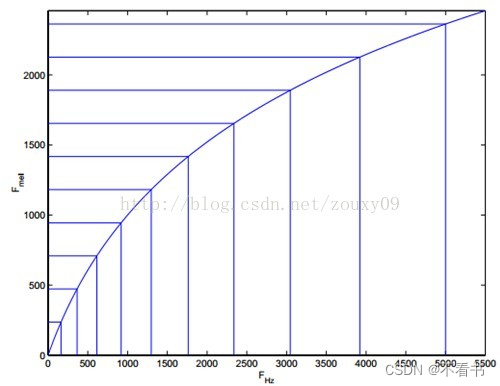
上图是HZ到Mel的映射关系图,由于二者为log关系,在频率较低时,Mel随HZ变化较快;当频率较高时,曲线斜率小,变化缓慢。
而梅尔倒谱就是在梅尔频谱上做倒谱分析(取对数,做DCT变换)。
我们得到了STFT、Mel谱等等特征以后,就会将这些特征送入神经网络模型去学习其内在规律,从而实现语音识别、语音合成、音色转换、说话人识别、语音降噪、语音端点检测等等的任务。
4.语音去噪
语音去噪(noise reduction)又被称为语音增强(speech enhancement),主要是针对于有人声的音频进行处理,目的是去除那些背景噪声,增强音频中人声的可懂性(intelligibility)。其应用范围很广,可以用于人与人之间的语音通讯,也可以用于很多语音任务的预处理,比如Automatic speech recognition。
这里的噪声通常被分为两大类,stationary和non-stationary。
stationary noise是指不随着时间发生变化变化的噪声,比如菜场的嘈杂声,电台的杂讯声等等。
non-stationary noise是指随时间发生变化的噪声,比如说话时背后突然经过一辆汽车,又比如突然响起的警报声等等。
传统解决方法包含谱减法、维纳滤波法。其中谱减法噪声删除不足会造成音乐噪声,删除过多又会造成语音失真。
新型方法是深度语音去噪。如下图是DEMUCS网络结构示意图:
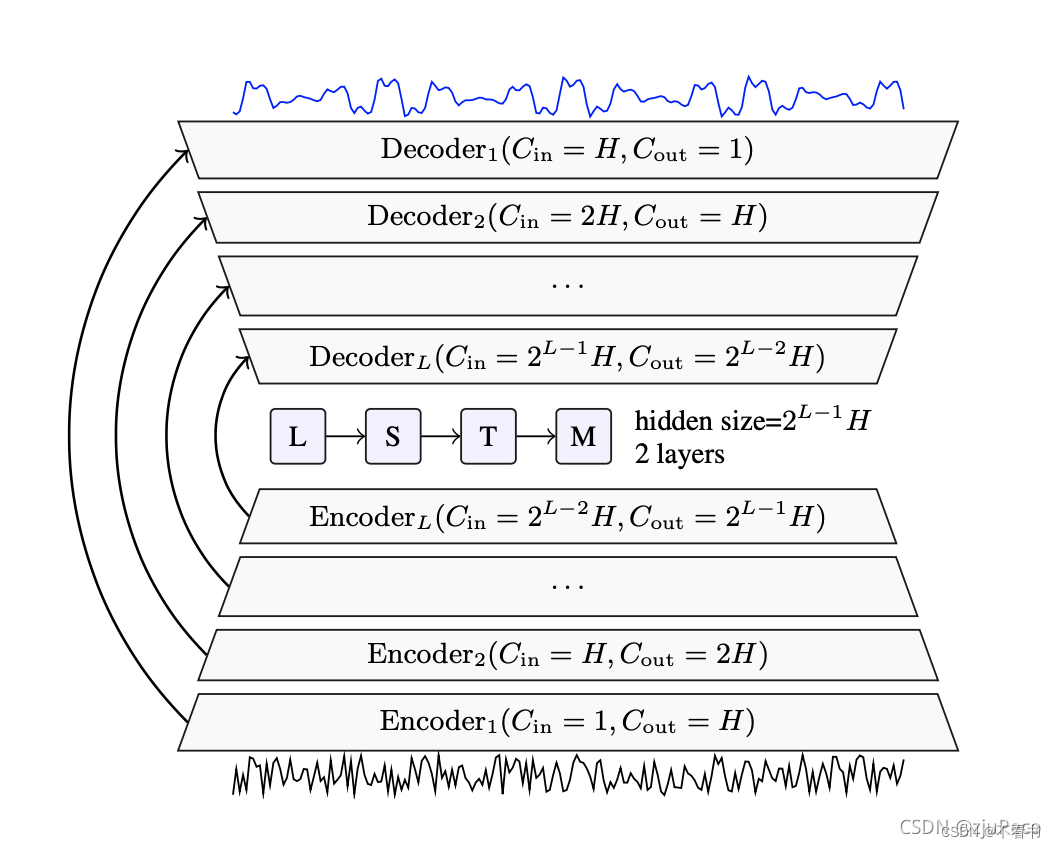
整个结构就是一个U-net的结构,输入和输出都直接是声音信号,Encoder和Decoder都分别有L LL层,每一层都是由一个conv1d+relu+conv1d+glu组成的。网络的loss由两部分组成,分别是L1 loss和多尺度的STFT loss组成。前者保证输出信号相近,后者保证组成该输出信号的频率相近。
5.参考
语音信号处理的深度学习入门 - 知乎 (zhihu.com)
形象易懂的傅里叶变换、短时傅里叶变换和小波变换 (qq.com)
音频特征(2):时域图、频谱图、语谱图(时频谱图)_时频图-CSDN博客
【语音信号处理】1语音信号可视化——时域、频域、语谱图、MFCC详细思路与计算、差分_mfct语谱-CSDN博客 声谱图,梅尔谱图_梅尔声谱图-CSDN博客















 850
850











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









