






因为硬件资源有限,本来在研究LLM量化的,后来发现这与lora和Qlora有点关系,刚好我对这两个技术知之甚浅,一并进行学习了。
首先模型量化分为量化感知训练(QAT)和训练后量化(PTQ)。顾名思义,PTQ是在LLM完成训练(预训练/微调)后对权重/权重+激活进行直接量化,这种方法目前非常热门,与QAT相比研究的人非常多,猜测可能是方法比较粗暴简单,往上面做文章也好下手,从下图应该可以看出来。
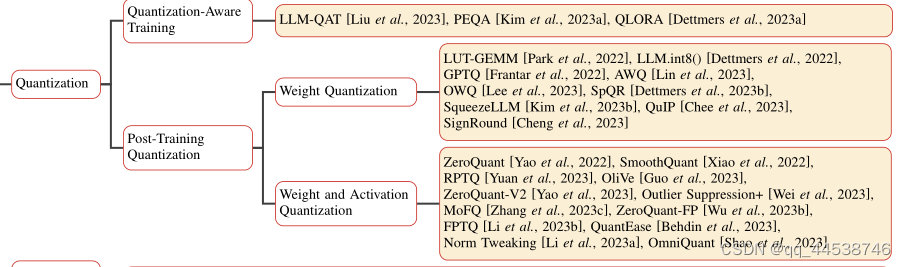
PTQ虽然简单,但是有个比较大的弊端是,对训练后的参数直接量化会削弱模型性能,于是有学者提出了QAT的方法,这个方法宗旨是让模型更适应后量化,主要操作是在模型训练阶段,前向推理使用低精度的模型参数,计算得到损失之后,反量化至高精度如FP16,根据这一损失优化fp16的原参数,原参数优化后再量化为低精度,参与下一轮参数更新(大致过程应该是这样,有错误的欢迎指出)。Qlora是QAT中最成功的方法之一,在讲Qlora之前,我们需要讲一下lora。
lora其实很简单,总所周知,LLM参数量基本都在十亿以上,当进行微调的时候,更新全参数所需的GPU将是巨大的(后续补充一些常见LLM训练/推理的内存需求统计),利用网络中的矩阵计算特点,我们将部分网络层的更新用两个矩阵乘积表示
在模型接收微调时,模型参数被冻结,只有A和B矩阵的参数被更新。等到微调完成后,我们可以将参数更新与原参数融合获得任务适配的LLM
作为参数高效微调方法 ,lora现在广泛用于LLM参数微调中,其极大地减少了模型微调中梯度带来的内存占用。但是,lora还是需要加载全部的模型参数参与训练,如果我的硬件实在很拉怎么办?于是人们提出了Qlora。
Qlora是QAT与lora的一个结合。这一方法采用lora的结构,但是模型参数采用int4量化后的预训练模型,适配器采用fp16的精度,训练过程如上述QAT所述,最后获得高精度微调后的int4量化LLM。
从目前的研究来看,感觉大多数的模型,尤其是垂域模型都是采用lora进行微调,量化这一块,感觉水确实蛮深的,而且量化完后设备也不一定能支持,初学者慎入。。
学习参考
模型量化、感知训练以及混合精度训练的理论理解和总结_模型混合量化 敏感-CSDN博客
QLoRA: 4bit量化+LoRA训练=瞬间起飞 - 知乎 (zhihu.com)
高效大语言模型微调:LoRA 和 QLoRA - 掘金 (juejin.cn)
太通透了!大模型训练和推理优化技术最全汇总! - 知乎 (zhihu.com)
关于LLM推理/训练内存占用量
【大模型】LLM显存占用对比:Qwen-7B-Chat,Qwen-14B-Chat-Int8,chatglm3-6b_qwen7b微调显存-CSDN博客
开源大模型部署及推理所需显卡成本必读:也看大模型参数与显卡大小的大致映射策略 - 智源社区 (baai.ac.cn)
QwenLM/Qwen:阿里云提出的 Qwen (通义千问) 聊天和预训练大型语言模型的官方存储库。 (github.com)
开源大模型部署及推理所需显卡成本必读:也看大模型参数与显卡大小的大致映射策略 - 智源社区 (baai.ac.cn)

















 702
702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









