







一切要从一个神经元开始
神经元的样子:

计算机科学家们有一个设想,是不是我们能从神经元出发,创造出一个人造大脑,来帮我们完成各种不同的任务呢?事实上,随着近十年深度学习网络的快速发展,这个设想已经被成功应用到 图像识别、语音处理、推荐搜索 等多个领域了!
那组成这个“人造大脑”的基础,也就是神经元和深度学习之间有什么联系呢?
举个例子,我们可以假设其他神经元通过树突传递过来的信号就是推荐系统用到的特征,有的信号可能是“用户性别是男是女”,有的信号可能是“用户之前有没有点击过这个物品”等等。细胞体在接收到这些信号的时候,会做一个简单的判断,然后通过轴突输出一个信号,这个输出信号大小代表了用户对这个物品的感兴趣程度。这样一来,我们就可以用这个输出信号给用户做推荐啦。
在实际应用里面,我们还得把生物结构的神经元抽象成一个数学形式,这样我们才能用程序来实现它。下图就是这样的一个抽象结构,这个神经元的结构很简单,只有两个传递输入信号的树突。

图中的 x1、x2就相当于两个树突传递的输入信号,蓝圈内的结构相当于神经元的细胞体,细胞体用某种方式处理好输入信号之后,就通过右面的轴突输出信号 y。
其中细胞体的数学结构放大看如下:

这一部分做了两件事情,一件事情是把输入信号 x1、x2各自乘以一个权重 w1、w2,再把各自的乘积加起来之后输入到一个叫“激活函数”的结构里。
激活函数是 sigmoid 激活函数,它的数学定义是:f(z)=(1+e−z1)-1 。它的函数图像就是图 3 中的 S 型曲线,它的作用是把输入信号从(-∞,+∞)的定义域映射到(0,1)的值域(因为在点击率预测,推荐问题中,往往是要预测一个从 0 到 1 的概率)。再加上 sigmoid 函数有处处可导的优良数学形式,方便之后的梯度下降学习过程,所以它成为了经常使用的激活函数(激活函数的种类有很多种,比较流行的还有 tanh、ReLU 等,在训练神经元或者神经网络的时候,我们可以尝试多种激活函数,根据效果来做最终的决定)。
什么是神经网络?
单神经元由于受到简单结构的限制,预测能力并不强,因此在解决复杂问题时,我们经常会用多神经元组成一个网络,这样它就具有更强的拟合数据的能力了,这也就是我们常说的神经网络。一个由输入层、两神经元隐层和单神经元输出层组成的简单神经网络如下。

其中,每个蓝色神经元的构造都和刚才的单神经元构造相同,h1和 h2神经元的输入是由 x1和 x2组成的特征向量,而神经元 o1的输入则是由 h1和 h2输出组成的输入向量。这是一个最简单的三层神经网络.
在深度学习的发展过程中,正是因为研究人员对神经元不同的连接方式的探索,才衍生出各种不同特性的深度学习网络,让深度学习模型的家族树枝繁叶茂。
神经网络是怎么学习的?
我们该如何训练一个神经网络。也就是说,我们怎么得到如下图中 x1到 h1、h2的权重 w1、w3,以及图中其他的权重呢?
这里需要用到神经网络的重要训练方法:
1.前向传播(Forward Propagation)
前向传播的目的是在当前网络参数的基础上得到模型对输入的预估值,也就是我们常说的模型推断过程。
比如说,我们要通过一位同学的体重、身高预测 TA 的性别,前向传播的过程就是给定体重值 71,身高值 178,经过神经元 h1、h2和 o1的计算,得到一个性别概率值,比如说 0.87,这就是 TA 可能为男性的概率。
在得到预估值之后,我们就可以利用损失函数(Loss Function)计算模型的损失。比如我们采用绝对值误差(Absolute Loss)作为我们的损失函数,
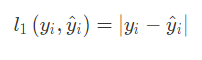
如果这位同学的真实性别是男,那真实的概率值就是 1,根据绝对值误差定义,这次预测的损失就是|1-0.87| = 0.13。随后利用误差来指导权重的更新,最常见的权重更新方式就是梯度下降法,它是通过求取偏导的形式来更新权重的。
比如,我们要更新权重 w5,就要先求取损失函数到 w5 的偏导 ∂Lo1/∂w5。从数学角度来看,梯度的方向是函数增长速度最快的方向,那么梯度的反方向就是函数下降最快的方向,所以让损失函数减小最快的方向就是我们希望梯度 w5 更新的方向。这里我们再引入一个超参数α,它代表了梯度更新的力度,也称为学习率。则梯度更新的公式为:w5t+1=w5t−α∗(∂Lo1/∂w5)。公式中的 w5当然可以换成其他要更新的参数,公式中的 t 代表着更新的次数。
对输出层神经元来说(图中的 o1),我们可以直接利用梯度下降法计算神经元相关权重(即图 5 中的权重 w5和 w6)的梯度,从而进行权重更新,但对隐层神经元的相关参数(比如 w1),我们又该如何利用输出层的损失进行梯度下降呢?
利用求导过程中的链式法则(Chain Rule)。通过链式法则我们可以解决梯度逐层反向传播的问题。最终的损失函数到权重 w1的梯度是由损失函数到神经元 h1输出的偏导,以及神经元 h1输出到权重w1的偏导相乘而来的。也就是说,最终的梯度逐层传导回来,“指导”权重w1的更新。
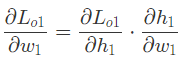
对于大部分的机器学习库来说,梯度反向传播的过程已经被实现并且封装好了,直接调用就可以了,但其原理就是如此。
2.反向传播(Back Propagation)(反向传播算法(BP 算法))
神经网络与深度学习的关系是什么?
深度学习可以说是神经网络的延伸和发展,它极大地丰富神经网络的结构种类,让它能够处理各类复杂问题。
深度学习是如何应用在推荐系统中的?
用单个神经元可以预测用户对物品感兴趣的程度。事实上,无论是单个神经元,还是结构非常复杂的深度学习网络,它们在推荐系统场景下要解决的问题都是一样的,就是预测用户对某个物品的感兴趣程度,这个感兴趣程度往往是一个概率,最典型的就是点击率、播放率、购买概率等。
所以在深度学习时代,我们使用深度学习模型替代了传统的推荐模型,目的就是让它作出更准确的推荐。
总结
神经元是神经网络中的基础结构,它参照生物学中的神经元构造,抽象出带有输入输出和激活函数的数学结构。而神经网络是通过将多个神经元以串行、并行、全连接等方式连接起来形成的网络,神经网络的训练方法是基于链式法则的梯度反向传播。
















 805
805











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









