







 Wav2vec是一种基于CNN的无监督预训练模型,用于学习语音特征,以提高有监督的语音识别任务。在大量无标签语音数据上训练,模型能显著降低字错误率(WER),在WSJ上达到2.43%的WER,优于DeepSpeech2。预训练模型使用原始音频输入,通过对比学习方法区分真实和负样本。实验表明,即使在少量转录音频数据下,也能显著提升识别效果。
Wav2vec是一种基于CNN的无监督预训练模型,用于学习语音特征,以提高有监督的语音识别任务。在大量无标签语音数据上训练,模型能显著降低字错误率(WER),在WSJ上达到2.43%的WER,优于DeepSpeech2。预训练模型使用原始音频输入,通过对比学习方法区分真实和负样本。实验表明,即使在少量转录音频数据下,也能显著提升识别效果。
【论文向】Wav2vec无监督预训练语音模型
wav2vec: Unsupervised Pre-training for Speech Recognition
目录
注:论文阅读笔记仅帮助大家快读了解、知晓论文的创新点、重点等,如需详细掌握请点击上方标题自行阅读,在此是存在一定博主和读者偏见的,有任何问题欢迎留言指正补充或讨论。
博客顺序完全参照论文顺序书写
Abstract 摘要
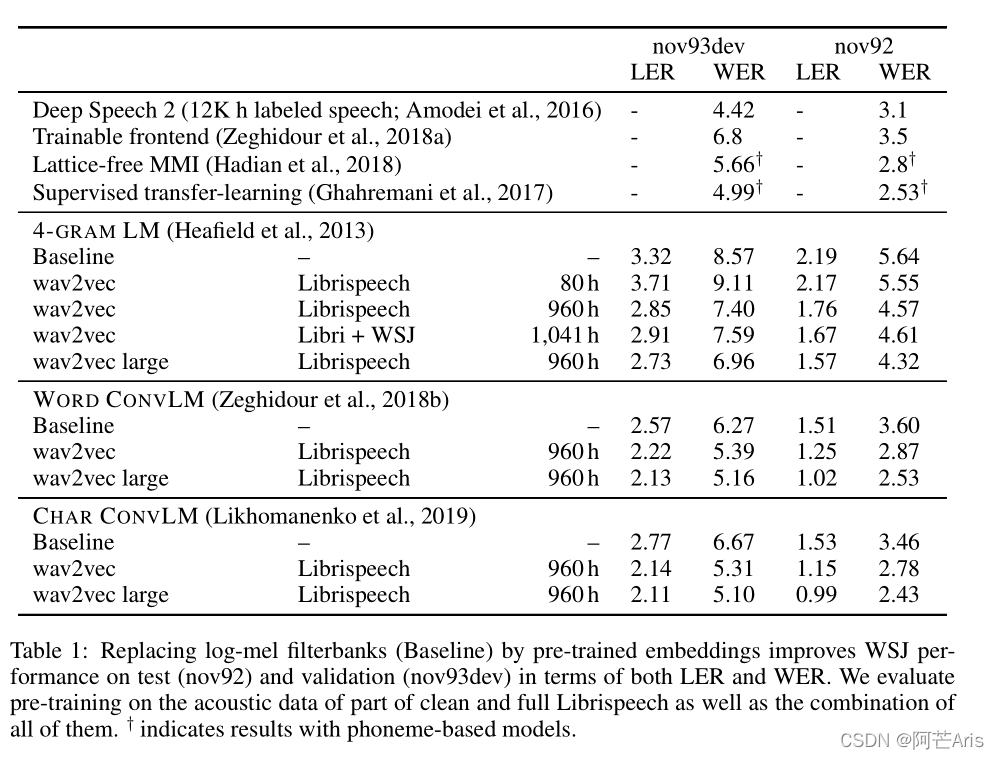
个人翻译:Wav2vec是在大量无标签语音数据集上学习训练的,得到的语音representations特征被用来提高acoustic声学模型效果。首先通过简单的多层CNN模型完成一种噪音对比二分类任务,在仅有几小时转录数据下,实验优化了在华尔街日报只通过基于字符的对数梅尔谱(log-mel)基线模型上减少字错误率(WER)最高至36%,并在nov92测试集达到了2.43%的WER,超过了基于字符的SOTA的DeepSpeech2模型,并使用了更少的标记数据。
个人总结:Wav2vec超过SOTA的DeepSpeech2
1 Introduction 简介
个人翻译:目前SOTA的语音识别模型都需要大量的转录音频数据来达到较好的效果。近来,神经网络中的预训练技术有效解决了有标签数据稀少的问题。核心想法是在大量有标签或无标签的数据集上学习表征通用的语音特征,并用此来提高有限数据下的下游任务效果。这对需要大量转录数据的语音识别任务特别管用。
CV计算机视觉领域,ImageNet和COCO的特征表示已经被证明在诸如图像标注、姿态估计任务上非常有效。CV领域的无监督预训练模型也同样很有潜力,NLP自然语言处理领域中无监督预训练语言模型也同样提高了许多任务如文本分类、词组结构和机器翻译。在语音处理上,预训练模型早已应用到情感识别、语者识别、音素区分、以及语音识别上。对语音识别的无监督学习已有研究,但还没有应用于提高有监督的语音识别任务上。
本文中,使用无监督预训练模型提高有监督语音识别任务。无标签的语音数据比有标签数据更易收集。Wav2vec是一种CNN模型,使用原始语音数据作为输入,计算得到一种通用的语音特征并被用来输入给语音识别系统。目标是区分真实音频样本和负样本的差别。不同于前人之作,移除了基于帧的音素识别而直接使用学到的语音特征来提高有监督的语音识别(ASR)任务。Wav2vec依赖于一个完全卷积架构,这样可以很容易在现代硬件上并行使用,而非RNN循环神经网络。
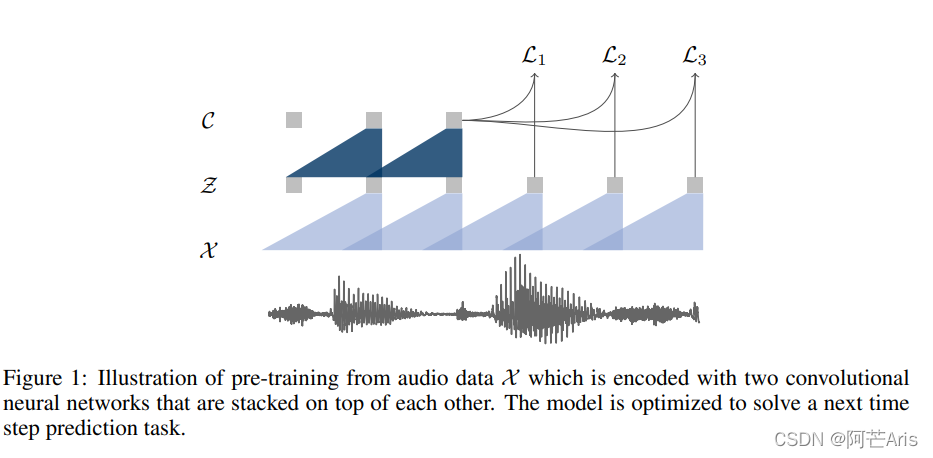
Fig1:来自音频数据X被两层卷积网络编码。模型被优化解决下一段的预测任务。
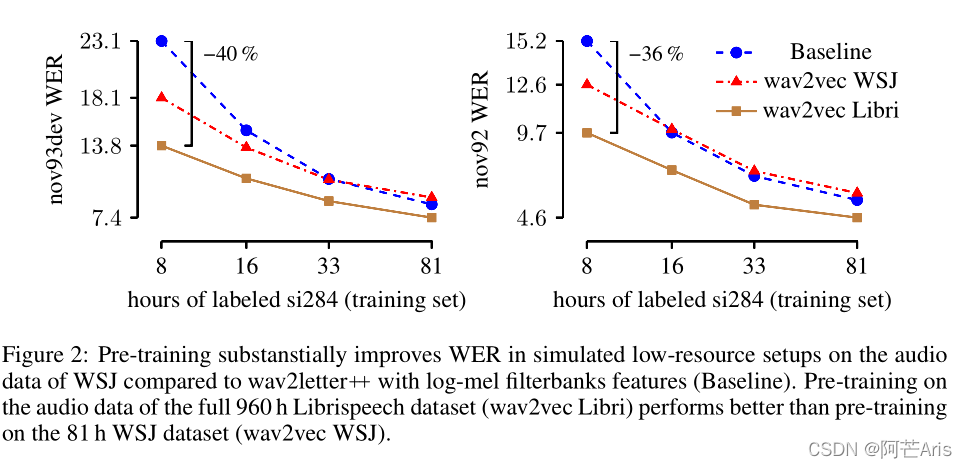
在(WSJ)华尔街日报上的基线实验结果证明在1000小时无标签音频数据上的预训练语音特征能够大幅度优化基于字符的ASR任务,并超过了SOTA,比DeepSpeech2提高WER从3.1%到2.43%。在TIMIT数据集上,同样SOTA。在一个仅有8小时的转录数据上,比起仅使用有监督数据的基线模型,wav2vec降低了WER高达36%。
个人总结:ASR语音识别任务上,预训练模型应用较少,本文中也仅提到了DeepSpeech2做对比。无监督的预训练语音模型wav2vec能够提高有监督语音识别的下游任务,并且wav2vec完全依赖CNN卷积网络,可以并行使用。
思考:怎么做语音的无监督训练,也像文字一样做自监督学习么,那该怎么分段,直接等分音频片段是不合理的。
2 PRE-TRAINING APPROACH 预训练方法
个人翻译:将一段音频信号作为输入,从给定的信号段预测未来的信号段。一个常见的问题是对数据分布 p ( x ) p(x) p(x)的精准建模很有挑战。为避免这个问题,采用直接对原始语音样本x在较低频率下进行编码得到一种特征表示z如Fig1所示,然后使用类似隐式模拟建模 p ( z i + k ∣ z i . . . z i − r ) / p ( z i + k ) p(z_{i+k}|z_i...z_{i-r})/p(z_{i+k}) p(zi+k∣zi...zi−r)/p(zi+k)
————————————————————————————————————————————
个人补充:隐式模拟建模这种方法类似于(Representation Learning with Contrastive Predictive Coding),在大量无标注数据样本下,通过编码器E将每个样本x编码为一个好的向量表示z,怎样衡量表示是否好,自编码器AutoEncoder告诉我们希望编码出的向量能够重构原始样本。因此加入一个解码器D得到重构的
x
′
x'
x′与x做MSE loss
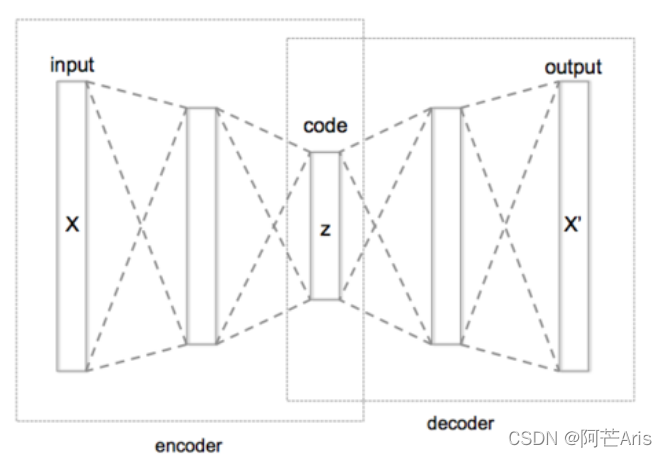
但这样直接的自编码有这样的问题,一个好的样本表示应该是能够从大量数据中辨别出该样本,也就是样本的“本质特征”,而非能够直接生成原始样本的“模仿特征”。而怎样得到衡量这样一个辨别样本的”本质特征“呢,就是最大化互信息。
令X表示所有样本集合,x表示其中一个样本。Z表示所有编码向量的集合,z表示其中一个编码向量。X与Z的互信息表示为:
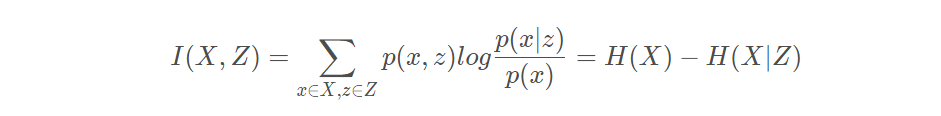
可以解释为由X引入而使Z的不确定度减小的量,I(X;Z)越大说明两者关系越密切。
为最大化原始数据X和表示Z的互信息,如果样本X是固定的,那么最小化条件熵
H
(
X
∣
Z
)
H(X|Z)
H(X∣Z),即给定一个表示z,其对应的样本x的不确定性越低,z就越能从大量样本X中辨别x。
为此提出对比预测编码CPC(Contrastive Predictive Coding)

如图所示,代表输入的音频序列,首先经过一个非线性编码器,它将输入序列编码成隐空间的序列,这时时间的分辨率会随之降低;然后,再用一个自回归模型将时刻之前的隐空间序列整合,得到当前状态的内容隐空间表示。
这篇论文认为,在预测未来数据的特征时,由于输入数据维度很高,再加上用单峰损失函数可能得不到细节信息,直接用一个基于的生成式模型去获得数据特征的方法不是最有效的。因此在CPC中,对和的密度比建模,构造了一个概率密度函数:使用双线性模型,对每个k时刻进行线性映射,这个过程对非线性网络和循环神经网络也同样适用。同时函数和、的互信息成正比,通过最大化两者的互信息来解析输入数据在隐空间的共有特征。
网络使用了重要性采样(importance sampling)和对抗噪声估计等技巧避免了直接对高维数据建模,直接从和中采样得到正负样本,再进行计算。
和都可以作为下游任务的输入,需要获取过去输入信号的信息时更适用,不需要时更适用(比如图像分类)。
作者:快乐的二叉树
链接:https://www.jianshu.com/p/62b328127d62
来源:简书
损失函数等请自行参照该论文学习,与本文跑题,不再阐述。
————————————————————————————————————————————
2.1 Model 模型
个人翻译:模型使用原始音频数据作为输入,并将其输入到两层网络中。编码器将音频信号编码在隐空间中,上下文网络结合了编码器多个时间序列(如Fig1所示)。两层网络都被用于计算目标函数
基于原始音频样本
x
i
x_i
xi,将其应用在编码器f上:X->Z,参数为5层卷积神经网络,也可以使用其他架构。编码器有kernel核 (10, 8, 4, 4, 4)、及步长(5, 4, 2, 2, 2)。编码的输出是低频特征表示
z
i
z_i
zi,主要编码16kHz30ms的音频,并每10ms表示一次
z
i
z_i
zi
接下来,我们将上下文网络g:Z->C作为编码器的输出并混合多个
z
i
.
.
.
z
i
−
v
z_i...z_{i-v}
zi...zi−v至一个简单结合上下文的向量
c
i
=
g
(
z
i
.
.
.
z
i
−
v
)
c_i=g(z_i...z_{i-v})
ci=g(zi...zi−v)中,接受域大小为v。上下文网络有kernel=3、步长stride=1的九层网络。上下文网络的总接受域大约为210ms。
编码器和上下文网络的层均由一个512通道的因果卷积、组归一层和一个ReLU非线性层组成。并对每个样本的特征和时间都进行了标准化相当于做了组标准化。同时发现对输入的缩放和偏移量的归一化是很重要的。这种操作使得特征表示可以跨数据集使用。
对于更大数据集上的训练,也考虑了一种增加容量的模型wav2vec large,在编码器层使用两层额外的线性变换以及有着不断增加的核大小(2,3,…,13)的12层上下文网络。在此引入skip connections跳跃链接以帮助收敛。最后的上下文网络总接受域增加至约810ms。
2.2 Objective 目标函数
个人翻译:模型训练的目标是在建议分布(proposal distribution)
p
n
p_n
pn中抽取的干扰样本
z
T
z^{T}
zT区分真实样本
z
i
+
k
z_{i+k}
zi+k,即未来的第k步,通过减小k={1,…,K}的每次对比损失。损失函数如下
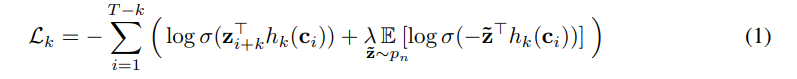
上式中
σ
(
z
i
+
k
T
+
h
k
(
c
i
)
)
σ(z^T_{i+k}+h_k(c_i))
σ(zi+kT+hk(ci))是
z
i
+
k
z_{i+k}
zi+k成为真实样本的可能性。考虑到一个特定步长k的映射变化
h
k
(
c
i
)
=
W
k
c
i
+
b
k
h_k(c_i)=W_kc_i+b_k
hk(ci)=Wkci+bk。实验中,通过每个音频序列中均匀选择干扰物来负采样10个例子来逼近期望,使得
p
n
(
z
)
=
1
/
T
p_n(z)=1/T
pn(z)=1/T其中T是序列长度,
λ
\lambda
λ是负样本个数。
训练后,我们将上下文网络产生的声学特征
c
i
c_i
ci作为声学模型的输入而非log-mel梅尔滤波特征。
类比word2vec,只要把c看作context,z看作word,那么这样构造loss就很自然了
个人总结:
1.输入数据直接对音频信号端到端处理;
2.预训练模型,由两个部分组成:其一是编码器部分,由5层卷积神经网络组成,其二是上下文网络部分,编码器和上下文网络的层均由一个512通道的因果卷积、组归一层和一个ReLU非线性层组成,并对音频输入进行了归一化处理;
3.损失函数是干扰样本
z
T
z^{T}
zT和真实样本
z
i
+
k
z_{i+k}
zi+k的对比损失。
3 Experimental Setup 实验准备
3.1 Data 数据
个人翻译:论文作者们使用到如下数据集:
(1)在TIMIT数据集的音素识别任务上,使用标准的训练、测试和验证集,训练数据仅包含了三小时多的音频数据。
(2)WSJ华尔街日报包含约81小时的转录数据。
(3)在si284上训练,nov93dev上验证,nov92上做测试
(4)Librispeech (Panayotov等人,2015)包含总共960小时的干净和嘈杂的语音训练。在训练前,论文作者们使用完整的81小时的华尔街日报语料库,80小时的干净的Librispeech子集,完整的960小时的Librispeech训练集
为训练基线模型,计算了步幅为10ms的25ms滑动窗口的80个log-mel滤波器组系数。最后的模型根据单词错误率WER和字母错误率LER来评估。
3.2 Acoustic Models 声学模型
个人翻译:论文笔者们使用wav2letter++ (Pratap et al., 2018)工具包完成训练和验证
TIMIT任务上遵循Zeghidour等人(2018a)的基于字符的wav2letter++的设置,它使用七个连续的卷积块(核大小为5,1000个通道),然后是PReLU非线性和0.7的dropout。最后的表示被投射到39维音素概率。利用自动分割准则(ASG;Collobert等人,2016)对模型进行训练并使用带动量的SGD优化。
WSJ华尔街日报的基线模型是Collobert et al. (2019)的wav2letter++,该模型预测了31个字素的概率,包括标准英语字母表、撇号和句号、两个重复字符(例如,单词ann被转录为an1)和用作单词边界的沉默标记(|)。
所有的声学模型在8 NVIDIA V100 GPUs上使用fairseq和wav2letter++的分布式训练实现。在WSJ上训练声学模型时,学习率5.6和梯度裁剪,并以64个音频序列的总批大小训练1000个epochs,并基于验证集的WER来停止和选择模型。对于TIMIT,使用学习率0.12,动量0.9,在8个GPU上训练1000个epochs,批大小为16个音频序列。
3.3 Decoding 解码
个人翻译:对于声学模型的解码,论文作者们使用了一个词典和一个单独的语言模型,该模型仅在WSJ语言模型数据上训练。并考虑到了的KenLM语言模型(Heafield等人,2013年)、一个基于单词的卷积语言模型(Collobert等人,2019年)和一个基于字符的卷积语言模型(Likhomanenko等人,2019年)。从上下文网络c或log-mel滤波器组的输出中解码单词序列y,使用Collobert等人(2019)的波束搜索解码器,通过最大化如下公式:
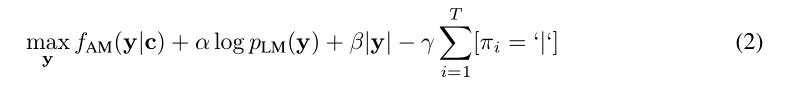
f
A
M
f_{AM}
fAM是声学模型,
p
L
M
p_{LM}
pLM是语言模型,
π
=
π
1
,
.
.
.
,
π
L
\pi=\pi_1,...,\pi_L
π=π1,...,πL是y的字母序列。超参数
α
,
β
,
γ
\alpha,\beta,\gamma
α,β,γ是语言模型、词惩罚系数、沉默(单词边界的沉默标记(|))惩罚系数的权重值。
在WSJ上解码时,对于
α
,
β
,
γ
\alpha,\beta,\gamma
α,β,γ使用了随即搜索的方法,并最终找到了最好的超参数。对于基于单词的语言模型,使用了4000个波束大小和250个波束评分阈值,对于基于字符的语言模型,使用了1500个波束大小和40个波束评分阈值
3.4 Pre-Training Models 预训练模型
个人翻译:训练模型是通过PyTorch的fairseq工具包实现的。使用了Adam优化和余弦学习率 (Loshchilov& Hutter, 2016),省略实验训练参数细节。
4 Results 实验结果
个人翻译:不同于van den Oord et al. (2018),论文作者们直接在下游语音识别任务上评估预训练模型效果。在WSJ基线模型上评估语音识别效果并模拟各种低资源配置(见4.1)。同样还评估了TIMIT音素识别任务,并筛选了各种模型组合(见4.3)。
训练细节省略。
5 Conclusions 结论
创造了Wav2vec,第一个将无监督预训练模型应用到语音识别上并完全使用卷积模型。在WSJ华尔街日报的测试集上实现了2.43%的WER词错误率,该结果优于基于字符的语音识别模型(Amodei等人,2016)。并发现更多的训练数据可以提高性能,这种方法不仅可以改善资源匮乏的设置,还能改善WSJ所有训练数据的设置。在未来工作中,研究进一步提高性能的不同架构。


















 201
201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











