






【AI时代工具】零代码打造你的专属数字人:揭秘个人实现全流程与前沿技术实战
有任何个性化实现需求的可以私信我合作
目录
前言
你是否曾幻想过拥有一个能替你发言、帮你直播,甚至成为你“数字分身”的智能伙伴?在2025年的今天,这已不再是科幻电影的专属情节。AI数字人技术的飞速发展,正让每个人都能以零代码、低成本的方式,打造属于自己的虚拟形象。无论你是想为社交媒体增添个性内容,还是为企业降本增效;无论你是渴望尝试前沿科技的极客,还是追求便捷生活的普通人——定制数字人的时代,已经为你敞开大门。
过去,创造虚拟形象需要专业团队和动辄数十万的预算,但如今,深度学习、自然语言处理与实时渲染技术的突破,让数字人从“实验室专属”走向大众指尖。只需上传一张照片、录制一段语音,AI便能生成与你神似的虚拟形象;输入文案,数字人即可自动完成口播、直播甚至实时互动。这些工具不仅支持调整外貌、声音、性格,还能赋予数字人专业领域的知识库,让TA成为你的“24小时智能助手”。
更令人兴奋的是,这项技术正在重塑我们的生活场景:
内容创作者用它批量生成短视频,效率提升10倍;
小微企业主借虚拟主播实现7×24小时直播带货;
教育工作者通过数字讲师生动演绎课程;
普通用户甚至能克隆已逝亲人的音容,留存永恒记忆
1 核心技术模块
1.1 Wav2Lip
Wav2lip是如今数字人最核心的技术,是一个让“哑巴视频开口说话”的AI工具,它能将任意一段语音与任意人物面部视频的唇形动作精准同步。比如把郭德纲的相声配音到《新闻联播》主持人的视频上,让主持人“说出”相声内容,且口型完全匹配。
实现原理(通俗版):
(1)“模仿者”生成器
生成器像一个“模仿演员”,它的任务是:
输入:一段音频 + 一张静态人脸图片(或视频中的某一帧)。
学习内容:根据音频中每个发音对应的嘴唇形状,调整图片中人物的口型。
输出:生成与语音完全同步的唇形动画视频。
(2)“裁判”判别器
判别器则像一个严格的“裁判”,负责判断生成的唇形是否自然、是否与音频同步:
训练阶段:先用大量真人说话视频训练判别器,让它学会识别“真实同步”和“虚假不同步”的唇形。
生成阶段:生成器不断调整口型,直到判别器认为“足够逼真”为止
注意:不是一定要通过GAN来做wav2lip,这种只是最常用的手段。记住目标就是在语音的基础上对一张图片中的人脸部分的嘴型生成和替换
比较好的论文工作有:
《A Lip Sync Expert Is All You Need for Speech to Lip Generation In The Wild》
首次提出通过预训练判别器解决口型同步问题,支持非受限场景(如侧脸、复杂背景)
SadTalker(CVPR 2023):结合3D头部运动生成,使数字人更生动
MuseTalk(腾讯2024):通过图像修复技术提升唇形清晰度,支持实时生成
EMAGE框架(清华大学):统一面部表情与肢体动作生成标准,解决全身协调性问题
EchoMimicV2(蚂蚁集团):音频驱动的半身动画生成,半身动作(面部+手势+身体)
1.2 TTS
语音合成工作主要涉及到两个方面:
(1)文本转语音:即将自己的文案转成语音,用于后续输入给数字人做口播的语音内容。
(2)伪造音频:即ZeroShot的TTS,希望合成的语音是由自己或目标音色来决定的。比如Google的Tacotron系列、DeepMind的WaveNet等
2 口播平台
以下观点仅为本人自己的用户体验,我本人是个不太会用工具的普通人,不是专业使用数字人产品
2.1 HeyGen
数字人heygen使用场景和体验,如讲解一个ppt视频课,步骤为

先上传一段ppt,就会获得按页的编辑界面
选择模板库中的数字人放到每一页中的任意位置
按页进行编辑,如上传第一页要说课程介绍的文字,选择国家语音、语速
问题:按页编辑非常麻烦,我不需要按页去选择语速或者调整人物大小和位置(希望有个自动分页的,人物固定在视频中哪一部分即可),免费版1分钟超过1分钟的分几次生成然后再找软件拼接到一起,而且生成速度也不快。太多模块了编辑的步骤实在太多
2.2 禅镜
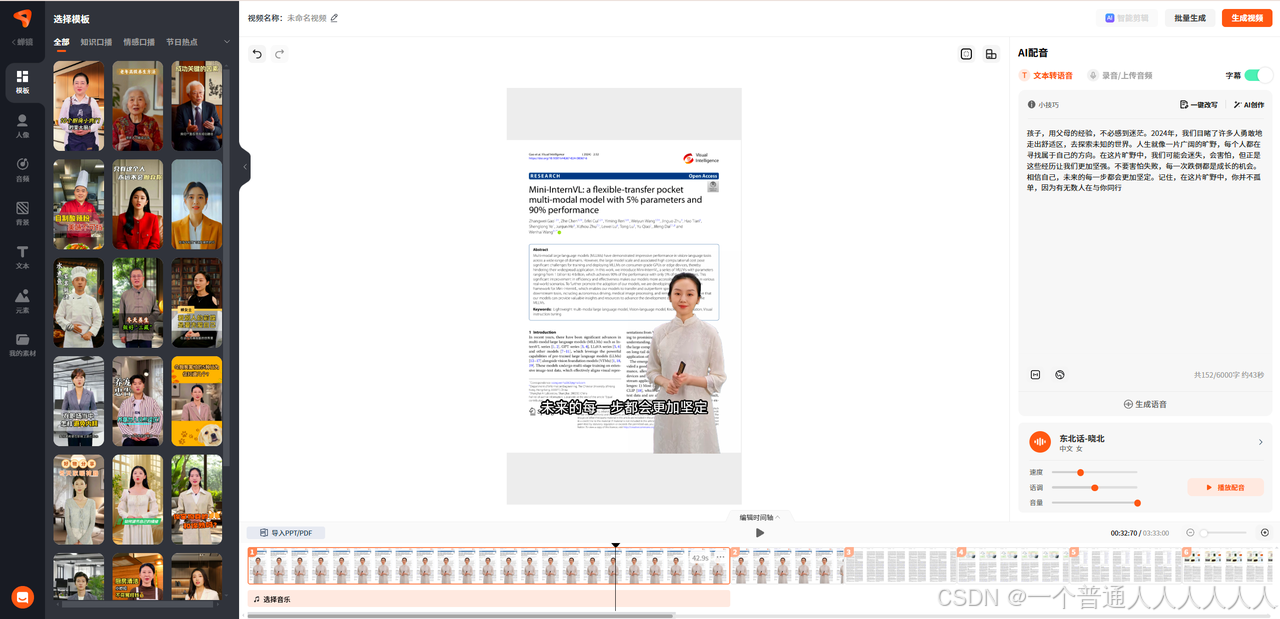
禅镜,不如heygen的自由度高,但优点是更简单,如上传ppt才会进入视频编辑界面。如果没有ppt没有图片插入可以直接用模板快速出片。有ppt或图片可以单独按页进行编辑制作。
2.3 有言
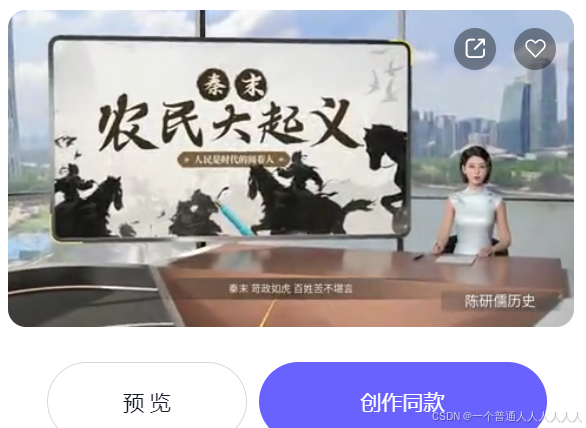
非真人的数字人,比较假,但有自动运镜,就是最开始是由全景转为这个的。适合做新闻或者课程演讲。
2.4 Video Ocean
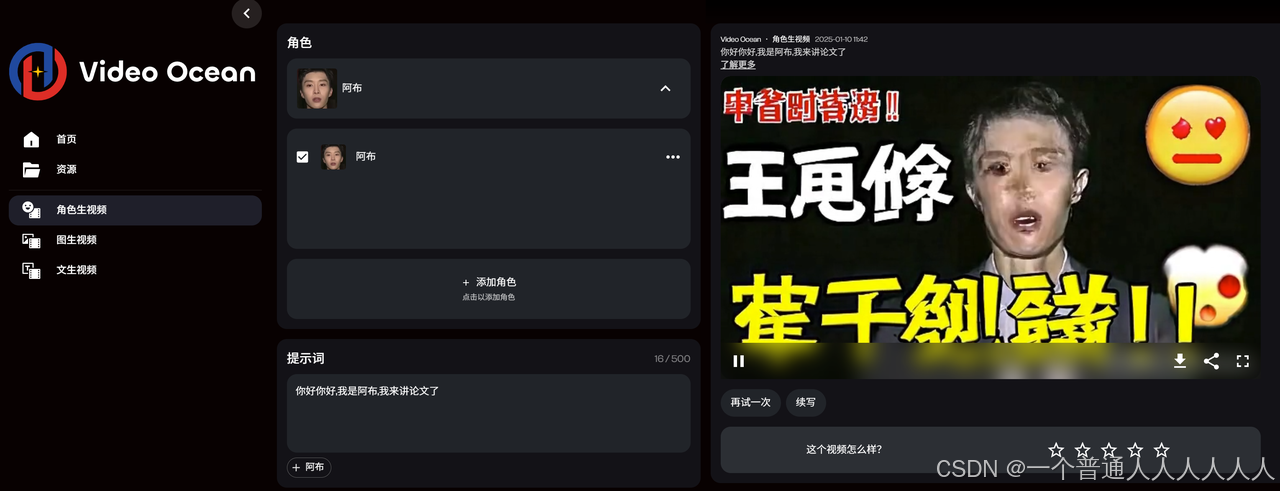
潞晨科技推出的多功能AI视频平台:效果上不可用。上传一张脸,不过支持角色生视频,即上传一张图片然后给出文字可以生成一张图片
2.5 寻光
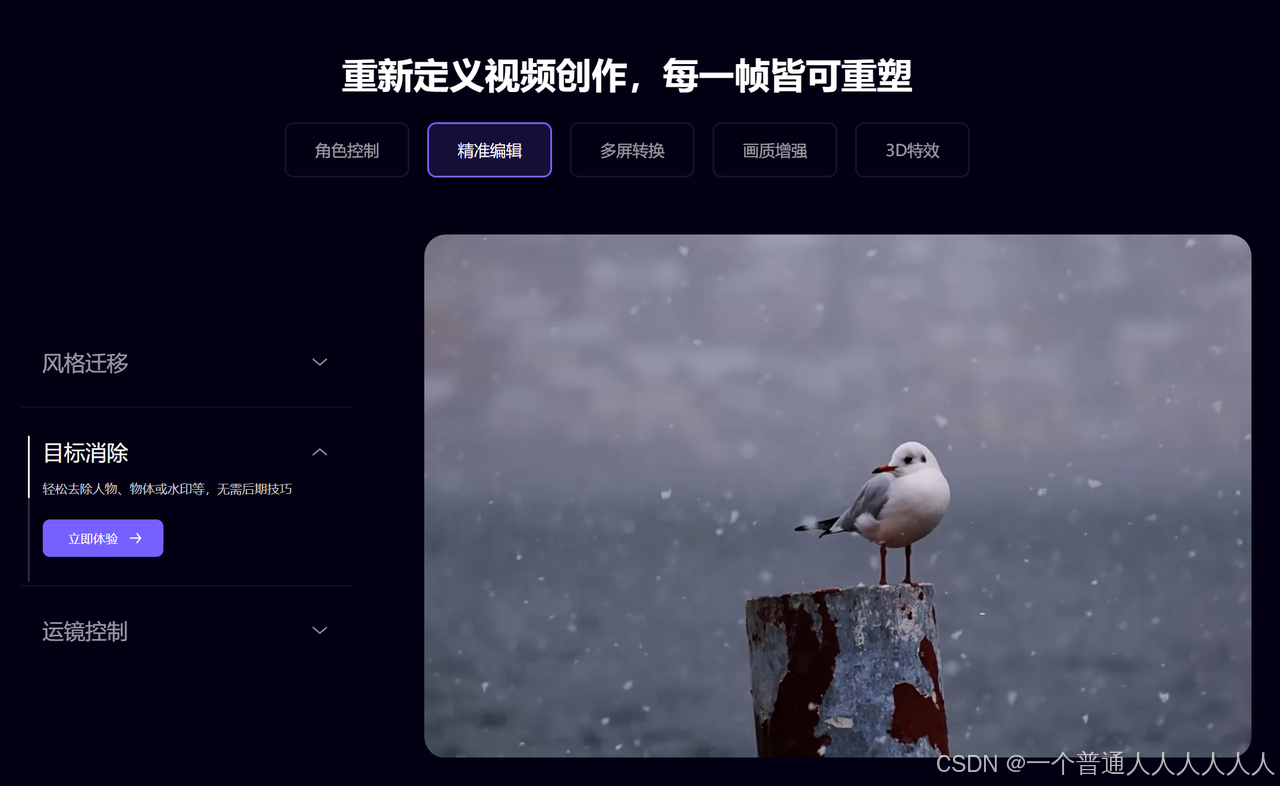
阿里达摩院的全流程AI视频创作工具。Demo上功能做的最多
角色控制 = 对口型 + 换脸
精准编辑 = 风格迁移 + 目标清除 + 运镜3D 自动生成平滑流畅的运镜轨迹
多屏转换 = 横屏转竖屏 9:16/3:4等多端适配
画质增强 = 超高清/4K等
3D特效 = 3D场景生成及重建和3D动作迁移
注意:这个我本人是没有真正使用过的,只是看产品页面demo的功能都很实用。试用是申请制
3 个人实现手段

3.1 输入素材准备:你的数字分身“原始基因”
视觉素材选择
静态图片:高清正脸照(推荐1024×1024分辨率),可借助即梦AI生成虚拟形象;
动态视频:真人出镜口播片段(5-10秒),侧脸/遮挡需规避,建议使用可灵AI增强稳定性。
案例:教育博主“羊羊”用自拍生成商务风虚拟形象,日均产出50条教学视频。
音频内容处理
文本驱动:通过DeepSeek-V3生成爆款文案,再调用豆包AI/Tacotron2转为语音;
语音克隆:上传3分钟录音,用FishSpeech的FakeWAV技术生成个性化音色。
3.2 音画时长对齐:让数字人“说话不卡壳”
静态图片处理
使用FFmpeg生成循环背景视频(示例命令)
ffmpeg -loop 1 -i input.jpg -c:v libx264 -t 10 -pix_fmt yuv420p static_bg.mp4
技巧:叠加高斯模糊动态背景提升专业感。
动态视频适配
超长裁剪:ffmpeg -ss 00:00:00 -i input.mp4 -t 00:00:05 -c copy output.mp4
过短扩展:
插帧方案:RIFE算法实现4倍慢动作(需NVIDIA GPU);
拼接方案:镜像翻转+过渡特效,适合快速处理。
行业参考:武汉万睿科技的MOJOY平台已实现毫秒级自动对齐。
3.3 唇形同步生成:AI赋能的“灵魂注入”
基础方案(Wav2Lip)
运行开源模型(需Python环境)
python inference.py --checkpoint_path wav2lip_gan.pth --face input_video.mp4 --audio input_audio.wav
局限:仅支持唇部动作,背景易模糊。
进阶方案如EchoMimicV2等(蚂蚁集团2024年开源的下一代引擎)
优势:支持4K渲染与实时生成,RTX 4090显卡可流畅运行。
4. 后期精修:专业级成片加工
字幕添加
ffmpeg -i output.mp4 -vf "subtitles=subtitle.srt" final.mp4
工具替代:度加剪辑APP支持AI自动生成字幕。
多轨道合成
# 使用MoviePy插入产品图片
final_clip = CompositeVideoClip([main_clip, product_img.set_position((0.8,0.7))])
商业案例:义乌商户用此法实现“虚拟主播+商品展示”自动化直播。
3.4 技术升级路线:从个人玩具到商业级应用
1. 动态增强:让数字人“活起来”
肢体动作库:接入OpenMotion数据集,实现自然手势(如讲解时指屏幕);
环境交互:用YOLOv8检测画面元素,触发对应动作(如看向新出现的产品)。
2. 智能决策:告别“人工编剧”
实时交互:集成DeepSeek-7B大模型,实现直播弹幕即时应答;
情感计算:通过acoustic特征分析音频情绪,同步调整面部表情。
3. 多语言扩展
# 使用Meta的SeamlessM4T实现36语种互译
translated_audio = pipeline('text-to-speech', text=text, target_lang='ja')
跨境电商实测:日本TikTok店铺转化率提升37%
现在轮到你了!
这套方案本人已经实操可用,你可以
今日尝试: 用手机自拍+录音生成第一条数字人视频;
进阶探索: 部署EchoMimicV2实现口播效果;
商业变现: 接入抖音开放平台,开启自动化内容生产流水线。


















 1307
1307

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











