







背景:使用机器学习模型,根据不同的病人数据,进行疾病分类,一个病人可能存在多条数据,需进行特征选择以及分组交叉验证
环境
scikit-learn 1.1.1
报错情况
原代码:
# k折-训练集,5折交叉
gkf = GroupKFold(n_splits=5)
gkfR = gkf.split(train_x, train_y, train_group)
# 前向特征选择
sfs = SequentialFeatureSelector(model,n_features_to_select="auto",n_jobs=4,cv=gkf,tol=1e-5,scoring='accuracy')
sfs.fit(train_x,train_y)
报错:
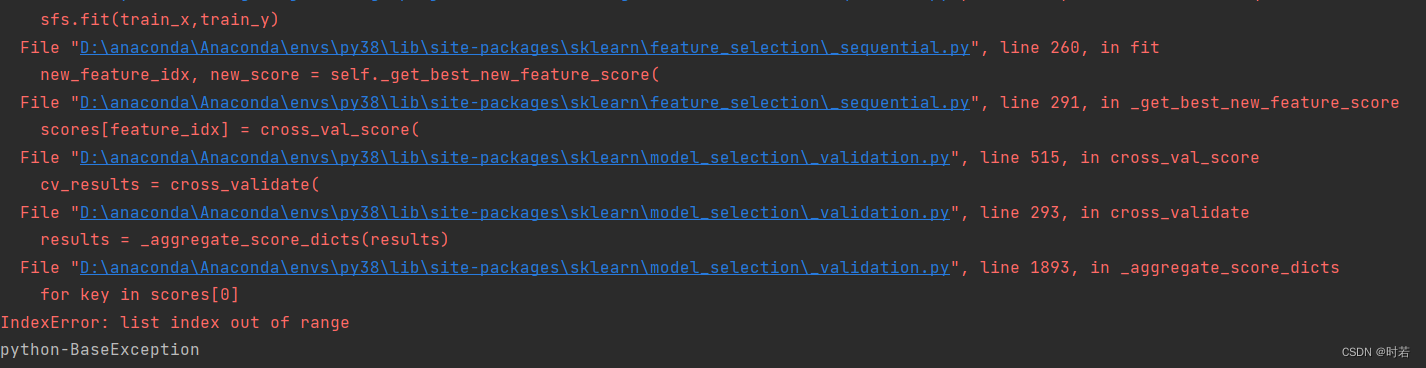
原因分析
在fit函数中,调用了sklearn\model_selection_validation.py的cross_validate方法,其中根据cv取训练集测试集的代码片段的groups字段检查的内容为None,导致GroupKFold交叉验证无法取出训练集和测试集
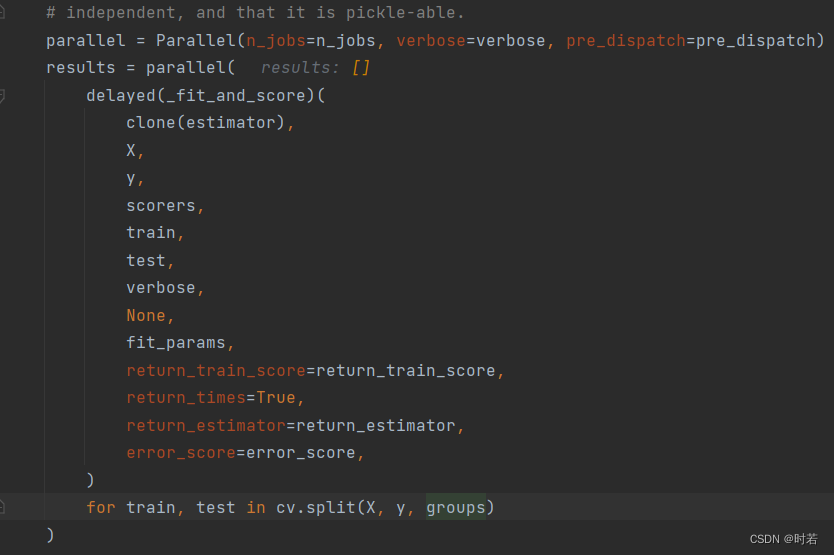
解决方法
修改SequentialFeatureSelector的fit函数,加入groups值,并逐个修改调用文件,直至_validation.py的cross_validate方法能正确传入一个groups字段。修改后的代码如下:
- 调用fit的main脚本:
# k折-训练集,5折交叉
gkf = GroupKFold(n_splits=5)
gkfR = gkf.split(train_x, train_y, train_group)
# 前向特征选择
sfs = SequentialFeatureSelector(model,n_features_to_select="auto",n_jobs=4,cv=gkf,tol=1e-5,scoring='accuracy')
sfs.fit(train_x,train_y,train_group)
- sklearn库文件:sklearn\feature_selection_sequential.py中fit()
def fit(self, X, y=None,groups=None):
"""Learn the features to select from X.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Training vectors, where `n_samples` is the number of samples and
`n_features` is the number of predictors.
y : array-like of shape (n_samples,), default=None
Target values. This parameter may be ignored for
unsupervised learning.
Returns
-------
self : object
Returns the instance itself.
"""
# FIXME: to be removed in 1.3
if self.n_features_to_select in ("warn", None):
# for backwards compatibility
warnings.warn(
"Leaving `n_features_to_select` to "
"None is deprecated in 1.0 and will become 'auto' "
"in 1.3. To keep the same behaviour as with None "
"(i.e. select half of the features) and avoid "
"this warning, you should manually set "
"`n_features_to_select='auto'` and set tol=None "
"when creating an instance.",
FutureWarning,
)
tags = self._get_tags()
X = self._validate_data(
X,
accept_sparse="csc",
ensure_min_features=2,
force_all_finite=not tags.get("allow_nan", True),
)
n_features = X.shape[1]
# FIXME: to be fixed in 1.3
error_msg = (
"n_features_to_select must be either 'auto', 'warn', "
"None, an integer in [1, n_features - 1] "
"representing the absolute "
"number of features, or a float in (0, 1] "
"representing a percentage of features to "
f"select. Got {self.n_features_to_select}"
)
if self.n_features_to_select in ("warn", None):
if self.tol is not None:
raise ValueError("tol is only enabled if `n_features_to_select='auto'`")
self.n_features_to_select_ = n_features // 2
elif self.n_features_to_select == "auto":
if self.tol is not None:
# With auto feature selection, `n_features_to_select_` will be updated
# to `support_.sum()` after features are selected.
self.n_features_to_select_ = n_features - 1
else:
self.n_features_to_select_ = n_features // 2
elif isinstance(self.n_features_to_select, numbers.Integral):
if not 0 < self.n_features_to_select < n_features:
raise ValueError(error_msg)
self.n_features_to_select_ = self.n_features_to_select
elif isinstance(self.n_features_to_select, numbers.Real):
if not 0 < self.n_features_to_select <= 1:
raise ValueError(error_msg)
self.n_features_to_select_ = int(n_features * self.n_features_to_select)
else:
raise ValueError(error_msg)
if self.direction not in ("forward", "backward"):
raise ValueError(
"direction must be either 'forward' or 'backward'. "
f"Got {self.direction}."
)
cloned_estimator = clone(self.estimator)
# the current mask corresponds to the set of features:
# - that we have already *selected* if we do forward selection
# - that we have already *excluded* if we do backward selection
current_mask = np.zeros(shape=n_features, dtype=bool)
n_iterations = (
self.n_features_to_select_
if self.n_features_to_select == "auto" or self.direction == "forward"
else n_features - self.n_features_to_select_
)
old_score = -np.inf
is_auto_select = self.tol is not None and self.n_features_to_select == "auto"
for _ in range(n_iterations):
new_feature_idx, new_score = self._get_best_new_feature_score(
cloned_estimator, X, y,groups, current_mask
)
if is_auto_select and ((new_score - old_score) < self.tol):
break
old_score = new_score
current_mask[new_feature_idx] = True
if self.direction == "backward":
current_mask = ~current_mask
self.support_ = current_mask
self.n_features_to_select_ = self.support_.sum()
return self
- sklearn库文件:sklearn\feature_selection_sequential.py中_get_best_new_feature_score()
def _get_best_new_feature_score(self, estimator, X, y, groups,current_mask):
# Return the best new feature and its score to add to the current_mask,
# i.e. return the best new feature and its score to add (resp. remove)
# when doing forward selection (resp. backward selection).
# Feature will be added if the current score and past score are greater
# than tol when n_feature is auto,
candidate_feature_indices = np.flatnonzero(~current_mask)
scores = {}
for feature_idx in candidate_feature_indices:
candidate_mask = current_mask.copy()
candidate_mask[feature_idx] = True
if self.direction == "backward":
candidate_mask = ~candidate_mask
X_new = X[:, candidate_mask]
scores[feature_idx] = cross_val_score(
estimator,
X_new,
y,
groups,
cv=self.cv,
scoring=self.scoring,
n_jobs=self.n_jobs,
).mean()
new_feature_idx = max(scores, key=lambda feature_idx: scores[feature_idx])
return new_feature_idx, scores[new_feature_idx]
- sklearn库文件:sklearn\model_selection_validation.py中cross_val_score(),仅需修改下面的函数头,后边内容不需要调整
def cross_val_score(
estimator,
X,
y=None,
groups=None,
*,
scoring=None,
cv=None,
n_jobs=None,
verbose=0,
fit_params=None,
pre_dispatch="2*n_jobs",
error_score=np.nan,
):














 4510
4510











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









