







pandas
pandas是数据分析的核心框架,集成了数据结构化和数据清洗以及数据分析的一些方法。pandas在numpy的基础上新增了3个数据结构,Series、DataFrame、Pannel
2. DataFrame
一个DataFrame由以下三部分构成:
行索引:index
列索引:columns
值:values
模块导入
from pandas import DataFrame
2.1 DataFrame的创建
最常用的方法是传递一个字典来创建。DataFrame以字典的键作为每一列的列名,以字典的值(一维数组)作为每一列
- 用字典创建一个DataFrame,字典中的一个键值对就是一个列,键是列名,值是列上的值
如果用字典创建时不加cloumns这个属性,创建出来的列是没有 “姓名”,“语文”,“数学”,“外语”,“综合” 这样的顺序的,随机排列,因为字典是无序的

属性:shape、size、index、columns和values

- 用数组来创建

2.2 DataFrame的索引
2.2.1 对列进行索引

- 索引列时候用键值的方式,DataFrame的键是列名

- 用属性的方式来索引,DataFrame的列名也称为属性

- 如果列索引用列表来表示,那么返回出来是一个DataFrame
如果用一个键(属性)来表示返回出来的是一个Series

扩展:
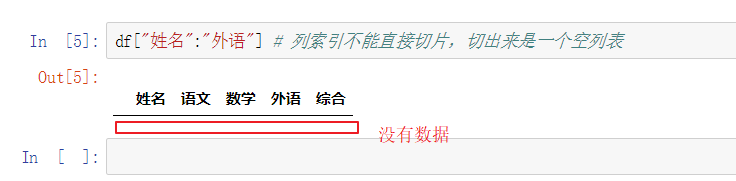
- 列索引能不能切片?
列索引不能直接切片,切出来是一个空列表- 列索引能不能隐式?
直接报红,列索引只有显式,没有隐式- 列索引能不能重复?
df1
把C变成B
所以 列索引可以重复



2.2.2 对行进行索引
行索引分为隐式索引和显式索引两种

1. 显式索引 .loc[ ]
根据index来索引
- 索引单行
- 索引多行
- 连续索引多行



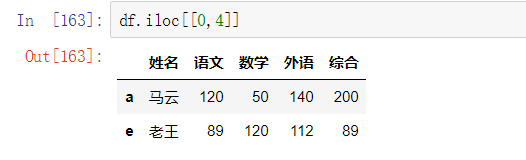
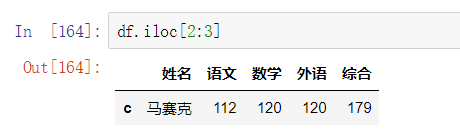
2. 隐式索引 .iloc[ ]
根据index对应的下标来索引
- 单行索引
索引下标值为0的信息
- 多行索引
- 连续索引多行
为什么这里只有1行呢?因为区间是前闭后开的,所以只取到下标值为2的信息

3.索引具体某些元素

方法一、分层索引,首先索引行或者列得到一个Series,再从Series中继续查找

方法二、直接定位,按照目标的行标与列标直接定位到具体元素
直接定位不能先列后行,因为数组查找的时候只能先行后列,否则会报错
比如 : 数学是列,b是行
正确的方式,先行后列


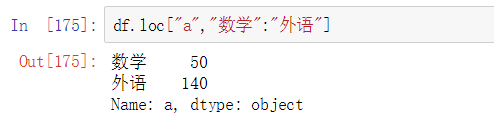
多层切片
只想要索引为a的数学和综合的成绩
前面说了列索引不能直接切片,但是,根据多层切片,列索引可以间接切片
比如,索引 数学 外语 综合 的成绩

2.3 DataFrame的运算
首先创建两个DataFrame对象

2.3.1 DataFrame之间的运算
和Series一样遵从自动补齐机制
df1+df2 只有在两个DataFrame对象里都有的元素(交集)才会显示,且元素会相加比如java 58=44+14
其余没有交集的都用NaN补齐

如果不想补NaN,想让其显示,可以使用函数的方式
这样依旧是df1+df2,但为什么还是有NaN呢?因为这些就是在df1和df2中都不存在的元素,
比如,df1中的d这一行,没有数学这个属性,而df2中没有d这一行
这里fill_value=0的方式,表示以0去补,为什么NaN不是变成0?仔细观察一下,那是df1中或者df2中的存在的元素
换种方式更好理解,将fill_value=0改为fill_value=1,看一下变化
本来 a这一行的 ruby=3的变为了ruby=4
这个ruby=3是df1中a行的元素,而df2中没有ruby这个属性,然后fill_value=0将df2中凭空弄出一个0去和df1中的a行的ruby=3相加
所以fill_value=0的作用不是将NaN变成一个数,而是将其中一个对象中不存在的对象指定为0,去和另一个对象中存在的元素去相加


除了加运算,还有其他的一些运算
运算符和对应的函数:
+ add()
- sub(),subtract()
x mul(),multiply()
/ div(),divide()
// floordiv()
% mod()
** power()
2.3.2 Series与DataFrame之间的运算

- 取到一行的值
取a这一行,得到的是一个Series,index部分是df1的列标,values部分是这一列的值

- 取到一列的值
取python这一列,得到的是一个Series,index部分是df1的行标,values部分是这一行的值

3)Series和DataFrame相加减的时候,默认将Series加到DataFrame的每一个行上,即DataFrame对应的列上的元素每个都加上Series对应列的值
将df1和a这一行的数据s_row相加


- 当把Series加到行上的时候如果index不对应就会启动自动补全机制

- 用函数来表示运算符
当我们用函数来表示运算符的时候,可以用axis表示加的方向
axis默认=1,此时会把Series加到DataFrame的每一个行上
axis=0的时候,此时会把Series加到DataFrame的每一个列上当axis=1,
此时会把Series加到DataFrame的每一个行上,即a,b,c,d四行都加了Series [44 67 51 3]这些值
df1.add(s_row,axis=1)就相当于df1+s_row
当axis=0,
此时会把Series加到DataFrame的每一个列上
即




练习6:
假设ddd是期中考试成绩,ddd2是期末考试成绩,请自由创建ddd2,并将其与ddd相加,求期中期末平均值。
假设张三期中考试数学被发现作弊,要记为0分,如何实现?
李四因为举报张三作弊立功,期中考试所有科目加100分,如何实现?
后来老师发现有一道题出错了,为了安抚学生情绪,给每位学生每个科目都加10分,如何实现?
期中考试
期末考试
期中期末平均值
作弊记为0分
李四所有科目加100分
给每位学生每个科目都加10分






2.4 数据缺失的处理
2.4.1 在pandas中None和np.nan都看做是np.nan (NaN)

pandas中默认就有有nan-safe操作,在进行聚合运算的时候,遇到nan会直接忽略,也就是说NaN不参与运算
例如上面的计算就只计算显示出来的数的和

2.4.2 DataFrame中对缺失数据的处理

查看缺失:isnull,notnull
isnull 缺失显示 True

notnull 不缺失显示True

对于二维数据:在判断缺失的时候,一般是判断某一行或者某一列的缺失情况,而不是具体元素的缺失情况
isnull和notnull要配合一下两个函数来使用
any()某一行(或者列),如果有True则返回True
all()某一行(或者列),全为True则返回True
axis值默认是0,代表判断列上是否有True
axis=1的时候,代表判断行上是否有缺失


删除缺失的行或者列
axis代表在哪个维度上进行删除
how代表如何删除,取all这一行(列)全为缺失的时候删除,取any这一行(列)存在缺失就删除

填补缺失
- 用具体的指定的数值来填补
- 向前填充
axis=0 method='bfill’的时候,拿后面的行标对应的数值填充到前的而缺失
axis=1 method="bfill"的时候,拿后面的列标向对应的前面的缺失处填充
- 向后填充
当axis=0 method=‘ffill’的时候,拿前面的行标向后填
当axis=1 method=‘ffill’的时候,拿前面的列标向后填



















 6026
6026











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









