







文章目录
一.理清关系
- 深度学习 ——》机器学习——》人工智能
- 这是一个由小到大的从属关系
二.机器学习基础
- 机器学习的核心是“使用算法解析数据,从中学习,然后对世界上的某件事情做出决定或预测”。这意味着,与其显式地编写程序来执行某些任务,不如教计算机如何开发一个算法来完成任务。
2.1监督学习
简单来说就是给你一个输入向量X,给你一个输出向量Y;一个X对应一个Y,然后经过你的训练,对于任意一个测试集X,都能得到相应的Y
2.1.1 回归
- 建立一个连续的线性映射关系,实际上就是预测
2.1.2 分类
- 建立一个离散的映射关系
2.1.3打标签
2.2非监督学习
只有一个X,没有Y,需要你对X进行处理得出你未知的结果。也就是有两个数据,从一个推测出另一个,前提是有样例作为参考,作为学习的“教材”。
2.2.1 聚类
- 将观察到的事务聚成一个一个的组
2.2.2 降维
- 将数据降维可以有效减小运算量甚至是计算的可能性,在大数据处理中是尤为重要的。一个重要的应用便是PCA(主成分分析)
2.3半监督学习
- 使用的数据,一部分是标记过的,而大部分是没有标记的
2.4强化学习
- 首先,它使用的未被打标签的数据。而强化学习使用机器的个人历史和经验来做出决定。强化学习的经典应用是玩游戏。与监督和非监督学习不同,强化学习不涉及提供“正确的”答案或输出。相反,它只关注性能。这反映了人类是如何根据积极和消极的结果学习的。很快就学会了不要重复这一动作。
三.深度学习基础
3.1神经网络
3.1.1特点:
1.并行分布处理。
2.高度鲁棒性和容错能力。
3.分布存储及学习能力。
4.能充分逼近复杂的非线性关系。
3.1.2基本模型
1.人工神经元模型 M-P模型(最基本模型)


2.感知机————最简单的神经网络结构
基本结构(类似于M-P模型)

多层感知机

单层感知机易于处理线性可分问题,对于非线性问题,则无法处理。于是采用多层感知机。所谓多层感知器,就是在输入层和输出层之间加入隐藏层,,以形成能够将样本正确分类的凸域。
3.前馈神经网络
- 分为 单层与多层 前馈网络
- 常见的如:感知机,BP神经网络,RBF径向基网络
4.卷积神经网络 CNN
- 包含有卷积层,池化层———适用于大型图像处理,以及语音识别等。
- 本质是一种前馈神经网络
- 基本组成
- 输入层,隐藏层(卷积层,池化层),输出层
- 常用层
- Dense 全连接层,y=wx+b
- Activation 激活层
- Dropout 失活层
- Flatten 展开层(将高位的张量展开成向量)
- 卷积层
- 做数据扫描,进行特征提取
- 池化层
- 降低复杂度 ,减少冗余信息,参数减少,增强鲁棒性
- 分类:
- 平均池化
- 最大池化
3.2概念解释
3.2.1欠拟合与过拟合
-
过拟合(overfitting):学习能力过强,以至于把训练样本所包含的不太一般的特性都学到了。
-
欠拟合(underfitting):学习能太差,训练样本的一般性质尚未学好。
-
以下图中,中间的图是正常的,左图为欠拟合,右图为过拟合
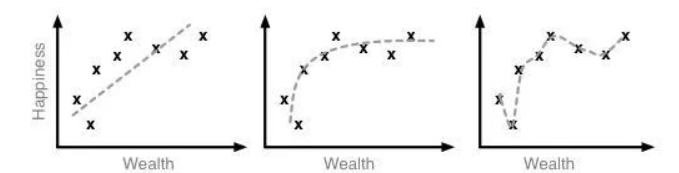
对于欠拟合的解决方法(提高泛化能力)
- 增加特征值
- 构造复杂多项式
- 减少正则化参数
对于过拟合的解决方法
- 增大训练的数据量
- 采用正则化方法(目标函数尾部加上范数)
- Dropout方法(前向传播时,随机选取和丢弃指定层次之间的部分神经连接)
3.2.2反向传播
用于参数调优,其实就是复合函数求导的过程
3.2.3损失与优化
- 损失函数
- 均方误差 MSE
- 均方根误差 RMSE
- 平均绝对误差 MAE
- 优化函数
- 梯度下降 GD
- 批量梯度下降 BGD
- 随机梯度下降 SGD
- Adam (自适应时刻估计方法,自动改变学习速率大小,智能化)
3.2.4距离公式
-
闵可夫斯基距离
-
马氏距离
-
余弦相似度
-
数据标准化(归一化)
- Min-Max标准化
- Z-score标准化
-
正则化
- L0范数 ||x||0 x向量中的各个非零元素个数
- L1范数 ||x||1 x向量中的各个元素的绝对值之和
- L2范数 ||x||2 x向量中的各个元素平方和的1/2次方
- Lp范数 ||x|| x向量中的各个元素的P次方和的1/p次方
-
Droput
- 以概率p舍弃神经元,并让其余神经元一概率q=1-p保留
-
成本函数
3.2.5 激活函数
- Sigmoid
- tanh
- ReLU (修正线性单元)
















 678
678











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











