






案例名称:爬取王者荣耀英雄资料图片
案例需求:
1.使用request爬虫爬取王者荣耀的英雄资料的数据(包括英雄名称和皮肤)
2.使用xpath来解析获取到的数据
3.将图片保存在对应英雄文件夹下面
分析:
1.判断
采集目标-所有英雄信息(皮肤图片)
如果采集英雄 在采集地址当中肯定会有一个id 我们只需要做id的动态切换就可以采集所有的英雄
2.验证
1.在所有的英雄的列表页 进行抓包
结论:
1.英雄数据是同步加载
3.由于在英雄列表页是观察不到英雄的皮肤数据 所以需要进入英雄的详情页去观察
1.详情页进行抓包
2.在xhr里面没有找到相关的请求包
3.通过观察img执行过滤 找到地址 浏览器进行访问
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/505/505-bigskin-4.jpg ---(大)
https://game.gtimg.cn/images/yxzj/img201606/heroimg/505/505-mobileskin-1.jpg--(小)
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/504/504-bigskin-1.jpg--直接修改
数据就可以
4.通过对地址的分析观察 发现只需要替换英雄的id即可下载对应的英雄的皮肤图片
4.图片的地址是属于异步加载 但是生成位置没有找到
1.图像地址拼接规律
"//game.gtimg.cn/images/yxzj/img201606/heroimg/" + heroid + "/" + heroid + ".jpg";
2.皮肤图片替换
"//game.gtimg.cn/images/yxzj/img201606/heroimg/"+ heroid + "/"+ heroid +"-myskin-"+ skinid +".jpg";
#模拟重现
皮肤:https://game.gtimg.cn/images/yxzj/img201606/heroimg/505/505-myskin-4.jpg
头像:https://game.gtimg.cn/images/yxzj/img201606/heroimg/505/505.jpg
重要代码:
解析数据
def parse_start_url(self):
'''爬虫原理第二步:发送请求获取响应'''#requests_html 自带了解析功能 直接进行解析
response=seesion.get(self.start_url,headers=self.headers).html
#提取所有英雄的详情地址 从详情地址中 提取英雄的id
src_url_list=response.xpath('//div[@class="herolist-content"]/ul/li/a/@href')
#提取英雄名称
hero_name=response.xpath('//div[@class="herolist-content"]/ul/li/a/text()')
# print(src_url_list,hero_name)
#遍历两个列表
for src_url_lists,hero_names in zip(src_url_list,hero_name):
#src_url_lists:英雄详情页地址
#hero_names:英雄名称
#提取英雄的id 通过下标切片
hero_id = src_url_lists[11:-6]
#补全英雄的地址
src_url_lists='https://pvp.qq.com/web201605/'+src_url_lists
#解析英雄详情页发送请求 获取响应
response=seesion.get(src_url_lists,headers=self.headers).html
#类中 函数方法之间的调用
self.parse_info_response_data(response,hero_id,hero_names) def parse_info_response_data(self,response,hero_id,hero_name):
'''爬虫原理第三步:解析响应,数据提取'''
#response:英雄详情页的响应对象
#hero_id:英雄的id
#hero_name:英雄名称
#1.提取英雄皮肤的图片名称
hero_name_1= ''.join(response.xpath('//div[@class="pic-pf"]/ul/@data-imgname'))
# print(hero_name_1)
#执行数据过滤
# print(hero_name_1.split('|'))
a = hero_name_1.split('|')
hero_name_list=[]
for i in a:
hero_name_list.append(i.split('&')[0])
print(hero_name_list)#英雄名称搞定
'''通过遍历hero_name_list,可以得到英雄图片的数量'''
for num ,name in enumerate(hero_name_list):
#num:name元素在hero_name_list列表中的下标
#name :英雄皮肤名称
#皮肤图片地址拼接
img_url= f'https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{hero_id}/{hero_id}-bigskin-{num+1}.jpg'
data = seesion.get(img_url).content
self.parse_save_data(data,hero_name,name)保存数据
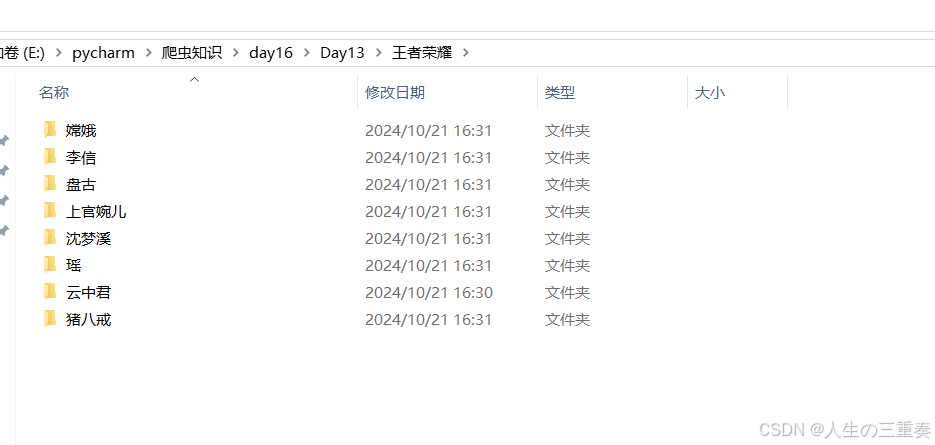
os_path = self.os_path+f"/{hero_name}/"#每个英雄名称都创建一个文件夹
if not os.path.exists(os_path):
os.mkdir(os_path)
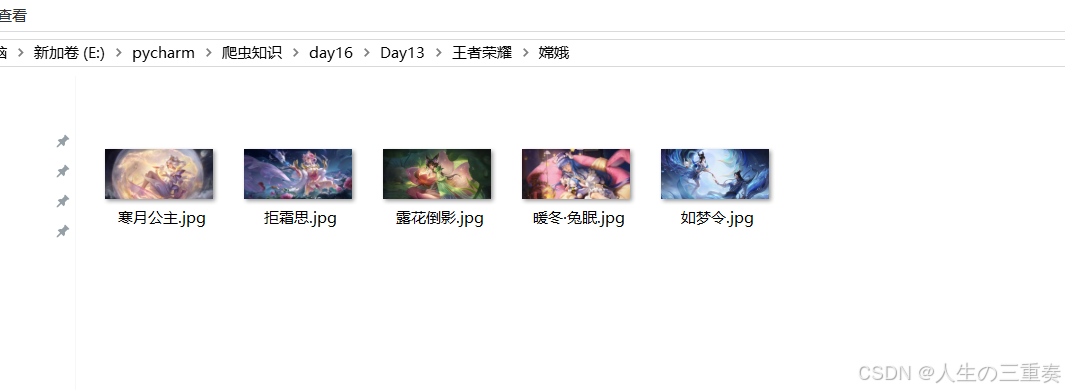
with open( os_path+name + '.jpg','wb')as f:
f.write(data)
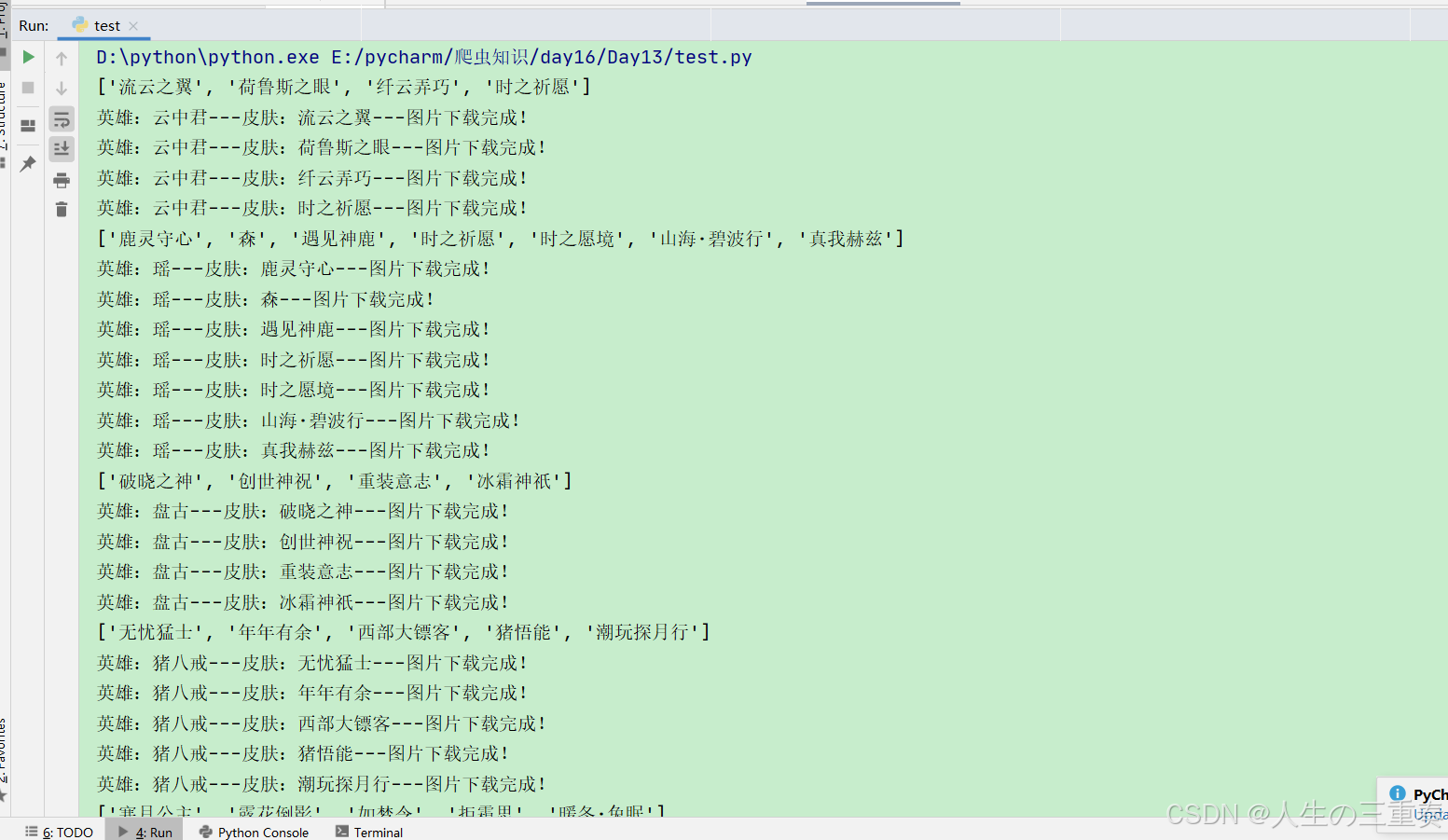
print(f'英雄:{hero_name}---皮肤:{name}---图片下载完成!')运行结果:

















 1498
1498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









