









准备工作
import re #正则表达式
import requests #获取页面信息
import pandas as pd #数据处理
import time
页面分析
直接get无法获得任何信息, 我们采取另一种思路:
来到network, 查看ajax请求, 同时下拉搜索内容

可以看到, 当不断下拉刷新内容时, 产生了形如https://m.weibo.cn/api/container/getIndex?containerid=100103type%3D1%26q%3D%E6%96%B0%E7%96%86%E6%97%85%E6%B8%B8&page_type=searchall&page=5的xhr文件, 且在当我们想要浏览新的内容时才会发送这个请求, 那么我们是否需要先手动下滑页面再请求xhr文件?答案是否定的, 因为经常做爬虫的人就会发现上述url有一个显著的特征: page=5. 因此我们只需求改page中的数字即可.
实际上, 我们也可以先访问这个url, 观察是否存在着我们需要的内容.

显然这是js代码, 且非常混乱, 我们可以通过这个网站将js代码格式化(在线js格式化).

将js内容复制到该网站并点击格式化校验、Unicode转中文, 就可以得到格式化的js代码

可以看到, 诸如此类的内容就表达了一位用户的id、内容(text)、内容长度(textLength)等等.
Code
- 完整代码
import re
import requests
import pandas as pd
import time
#headers中一定要带入自己的cookie和user-agent否则会403
headers = {
'User-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
'Cookie' : 'SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9W5Mjupe16Kiyb7vm281Dcv85NHD95QfSo.Neo2peKn0Ws4DqcjiKgLu9-DadJH0; SUB=_2A25MhkCXDeRhGeNI4lUT8S_Nwz-IHXVviWDfrDV6PUJbktCOLRDFkW1NS--oPUYVkqHq8aiZOlUnWJs3Mwsd7vcO; SSOLoginState=1635922120; WEIBOCN_FROM=1110006030; MLOGIN=1; BAIDU_SSP_lcr=http://localhost:8888/; _T_WM=25310073472; XSRF-TOKEN=ccf606; M_WEIBOCN_PARAMS=oid%3D4698870880408410%26luicode%3D10000011%26lfid%3D231522type%253D1%2526t%253D10%2526q%253D%2523%25E6%2596%25B0%25E7%2596%2586%25E6%2597%2585%25E6%25B8%25B8%2523',
'_xsrf' : 'ccf606'
}
main = "https://m.weibo.cn/api/container/getIndex?containerid=231522type%3D1%26t%3D10%26q%3D%23%E6%96%B0%E7%96%86%E6%97%85%E6%B8%B8%23&isnewpage=1&luicode=10000011&lfid=100103type%3D1%26q%3D%E6%96%B0%E7%96%86%E6%97%85%E6%B8%B8&page_type=searchall&page="
number = []
url = []
n = 10
for i in range(1, n):
url.append(main + str(i))
count = 0
code = []
URL = []
NEW = []
for Url in url:
res = requests.get(Url, headers=headers)
count += 1
print("第{0}次请求, 页面状态码:{1}".format(count, res.status_code))
print("地址:{0}".format(Url))
code.append(res.status_code)
URL.append(Url)
for i in range(20):
try:
string = res.json()["data"]['cards'][i]["mblog"]["text"] #正文内容被保存在以下标签中
#通过正则表达式提取str中的中文
pre = re.compile(u'[\u4e00-\u9fa5-\,\。]') #设定提取中文、标点符号的规则
res = re.findall(pre, string) #按上述规则进行查找
res1=''.join(res)
res1.split("-") #查询结果会带有--, 因此将其分割开
newlist = [i for i in res1.split("-") if i != ''] #分割后的列表存在空值, 去除列表中的空值
NEW.append(newlist)
print(newlist)
except:
pass
time.sleep(1.5) #加入休眠, 实践证明, 小于1.5s的休眠在100次爬取时就会403.
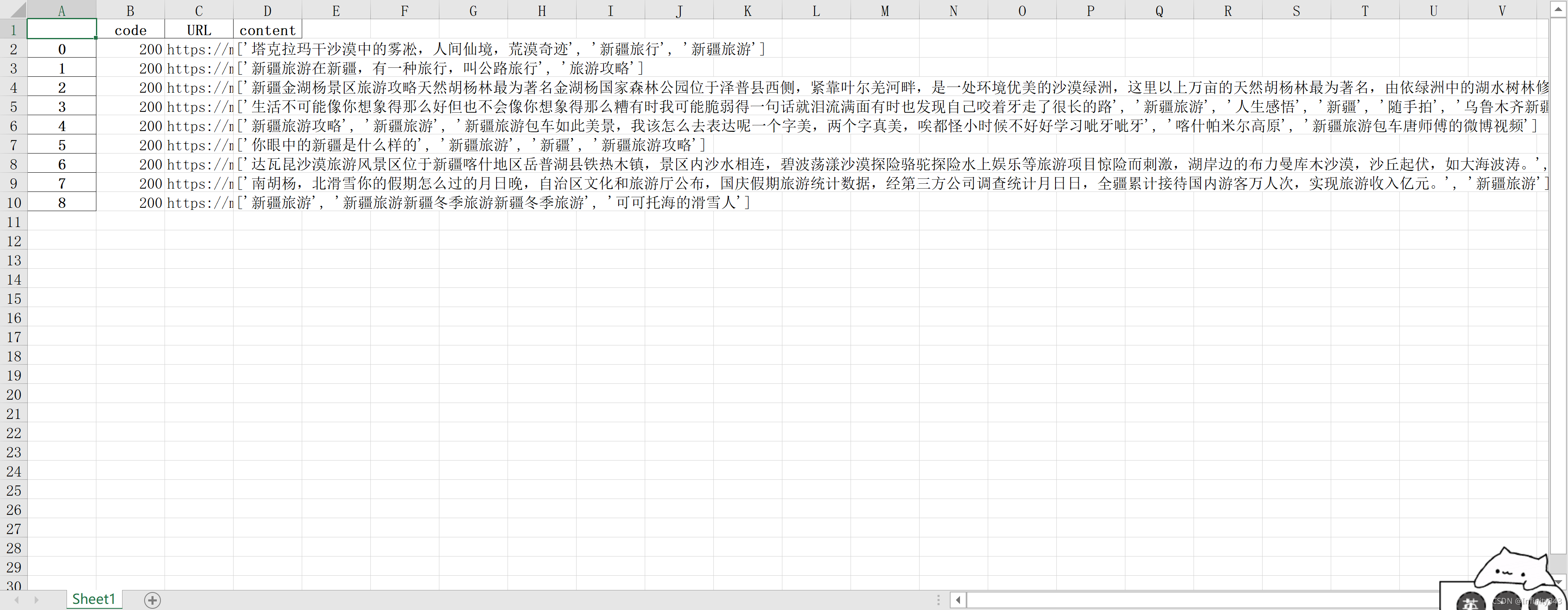
data = {"code":code, "URL":URL, "content": NEW} #将爬取结果存为字典以便导出
pd = pd.DataFrame(data)
pd.to_excel("D://Desktop//weibo.xlsx") #将结果保存为excel表格, 因为带有中文csv格式通常中文会乱码
- 爬取结果
















 7665
7665











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











