










分位数回归
分位数回归实际上是一种特殊的 ℓ 1 \ell_1 ℓ1回归问题,特别地,当所求分位数 τ = 0.5 \tau=0.5 τ=0.5时就是中位数回归。
1 线性规划
1.1 将分位数回归看做是线性规划问题来求解
一般的,线性回归问题可以写为
ℓ
p
\ell_p
ℓp范数线性回归,简称为
ℓ
p
\ell_p
ℓp回归:
arg min
x
∈
R
n
∣
∣
A
x
−
b
∣
∣
p
\argmin_{x\in\mathbb{R}^n}||\boldsymbol{A}\boldsymbol{x}-\boldsymbol{b}||_p
x∈Rnargmin∣∣Ax−b∣∣p
其中
A
∈
R
m
×
n
,
b
∈
R
m
\boldsymbol{A}\in\mathbb{R}^{m\times n}, b\in\mathbb{R}^m
A∈Rm×n,b∈Rm,
∣
∣
v
∣
∣
p
=
(
∑
i
∣
v
i
∣
p
)
1
/
p
||v||_p=(\sum_i|\boldsymbol{v}_i|^p)^{1/p}
∣∣v∣∣p=(∑i∣vi∣p)1/p表示
ℓ
p
\ell_p
ℓp范数
那么从中位数回归的角度来看,损失函数就是绝对损失(
p
=
1
p=1
p=1):
arg min
x
∈
R
n
∣
∣
A
x
−
b
∣
∣
\argmin_{x\in\mathbb{R}^n}||\boldsymbol{A}\boldsymbol{x}-\boldsymbol{b}||
x∈Rnargmin∣∣Ax−b∣∣
考虑一个两参数的分位数回归优化问题
β
^
=
arg min
(
b
0
,
b
1
)
∈
R
2
{
∑
i
=
1
n
∣
y
i
−
b
0
−
b
1
x
i
∣
}
\begin{equation} \hat{\beta}=\argmin_{(b_0,b_1)\in \mathbb{R}^2}\left\{ \sum_{i=1}^n|y_i-b_0-b_1x_i|\right\} \end{equation}
β^=(b0,b1)∈R2argmin{i=1∑n∣yi−b0−b1xi∣}
τ
\tau
τ分位数时更一般的形式
β
^
(
τ
)
=
arg min
b
∈
R
m
×
n
∑
i
=
1
n
ρ
τ
(
y
i
−
x
i
⊤
b
)
\hat{\beta}(\tau)=\argmin_{\mathbf{b}\in\mathbb{R}^{m\times n}}\sum_{i=1}^n\rho_{\tau}(y_i-\boldsymbol{x}_i^{\top}\mathbf{b})
β^(τ)=b∈Rm×nargmini=1∑nρτ(yi−xi⊤b)
其中
τ
∈
(
0
,
1
)
\tau\in(0,1)
τ∈(0,1)是分位数.
ρ
τ
(
⋅
)
\rho_{\tau}(\cdot)
ρτ(⋅)是check function(又称检查函数):
ρ
τ
(
u
)
=
u
(
τ
−
I
(
u
<
0
)
)
\rho_{\tau}(u) = u(\tau-I(u<0))
ρτ(u)=u(τ−I(u<0))
定义
ε
i
=
y
i
−
x
i
⊤
b
\varepsilon_i=y_i-\boldsymbol{x}_i^{\top}\mathbf{b}
εi=yi−xi⊤b为第
i
i
i个残差,则优化目标
(
1
)
(1)
(1)可以转化为残差的形式
β
^
=
arg min
(
b
0
,
b
1
)
∈
R
2
{
∑
i
=
1
n
ε
i
}
\begin{equation} \hat{\beta}=\argmin_{(b_0,b_1)\in \mathbb{R}^2}\left\{ \sum_{i=1}^n \varepsilon_i \right\} \end{equation}
β^=(b0,b1)∈R2argmin{i=1∑nεi}
将上式改写:
∑
i
=
1
n
ρ
τ
(
ε
i
)
=
∑
i
=
1
n
τ
ε
i
+
+
(
1
−
τ
)
∣
ε
i
−
∣
\begin{equation} \sum_{i=1}^n\rho_{\tau}(\varepsilon{_i})=\sum_{i=1}^ n\tau\varepsilon_{i}^{+} + (1-\tau)|\varepsilon_i^{-}| \end{equation}
i=1∑nρτ(εi)=i=1∑nτεi++(1−τ)∣εi−∣
由于分位数回归使用的是绝对损失函数,残差恒正,所以将其拆分为正部
ε
i
+
=
u
i
=
ε
i
I
(
y
i
−
x
i
⊤
b
>
0
)
,
ε
i
−
=
v
i
=
ε
i
I
(
y
i
−
x
i
⊤
b
<
0
)
\varepsilon_{i}^{+} = u_i=\varepsilon_i I(y_i-\boldsymbol{x}_i^{\top}\mathbf{b}>0),\varepsilon_{i}^-=v_i=\varepsilon_i I(y_i-\boldsymbol{x}_i^{\top}\mathbf{b}<0)
εi+=ui=εiI(yi−xi⊤b>0),εi−=vi=εiI(yi−xi⊤b<0)
可见,回归残差的正部被赋予了
τ
\tau
τ权重,负部被赋予
(
1
−
τ
)
(1-\tau)
(1−τ)的权重,令
τ
=
0.5
\tau=0.5
τ=0.5就是等权,所以中位数回归又是分位数回归的一个特例。
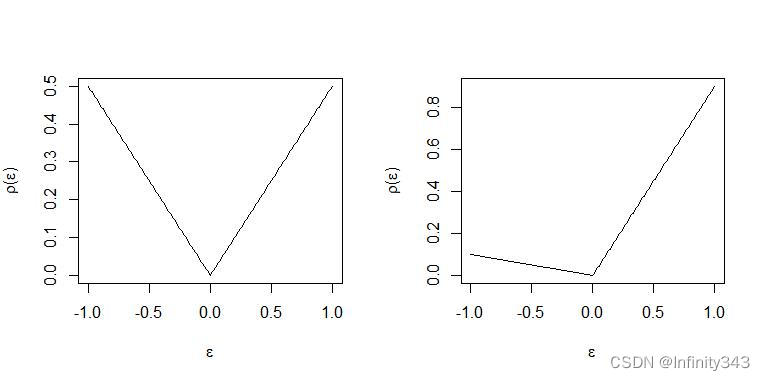
不难看出,
ℓ
1
\ell_1
ℓ1回归问题在零点处不可导,所以OLS方法不可用,但可以将其划为线性回归问题进行求解。对于一个线性规划问题其标准形式为
min
z
c
⊤
z
s
u
b
j
e
c
t
t
o
A
z
=
b
∗
,
z
≥
0
\min_{z} \,\,c^{\top}z \\ \mathrm{subject \,to} \,\,\mathbf{A}z=\mathbf{b}^*, z\ge0
zminc⊤zsubjecttoAz=b∗,z≥0
这里的
b
∗
b^*
b∗带上星号是为了区分开回归参数
b
b
b. 从定义来看,线性回归标准型要求所有决策变量大于零,显然残差是有正有负的,为满足上述条件,回忆之前对残差正负部的定义:
ε
i
=
u
i
−
v
i
\varepsilon_i=u_i-v_i
εi=ui−vi
其中正部
u
i
=
max
(
0
,
ε
i
)
u_i=\max(0,\varepsilon_i)
ui=max(0,εi)负部
v
i
=
max
(
0
,
−
ε
i
)
=
∣
ε
i
∣
I
ε
<
0
v_i=\max(0,-\varepsilon_i)=|\varepsilon_i|I_{\varepsilon<0}
vi=max(0,−εi)=∣εi∣Iε<0。
此时式(3)改写为
∑
i
=
1
n
ρ
τ
(
ε
i
)
=
∑
i
=
1
n
u
i
τ
+
v
i
(
1
−
τ
)
=
τ
1
n
⊤
u
+
(
1
−
τ
)
1
n
⊤
v
\sum_{i=1}^n\rho_{\tau}(\varepsilon_i)=\sum_{i=1}^nu_i\tau+v_i(1-\tau)=\tau\mathbf{1}_{n}^{\top}\boldsymbol{u}+(1-\tau)\mathbf{1}_{n}^{\top}\boldsymbol{v}
i=1∑nρτ(εi)=i=1∑nuiτ+vi(1−τ)=τ1n⊤u+(1−τ)1n⊤v
其中
u
=
(
u
1
,
…
,
u
n
)
⊤
,
v
=
(
v
1
,
…
,
v
n
)
⊤
\boldsymbol{u}=(u_1,\dots,u_{n})^{\top},\boldsymbol{v}=(v_1,\dots,v_n)^{\top}
u=(u1,…,un)⊤,v=(v1,…,vn)⊤,
1
n
\mathbf{1}_n
1n是
n
×
1
n\times1
n×1的全一向量。为记号方便,之后的向量或矩阵将不再加粗,而是通过取消下标来表示。若样本量为
N
N
N参数个数为
K
K
K,令
u
,
v
u,v
u,v为松弛变量,则会有
N
N
N个等式约束
y
i
−
x
i
⊤
b
=
ε
i
=
u
i
−
v
i
i
=
1
,
…
N
y_i-x_i^{\top}b=\varepsilon_i=u_i-v_i \quad i=1,\dots N
yi−xi⊤b=εi=ui−vii=1,…N
上式就可以改写为一个线性规划:
min
b
∈
R
K
,
u
∈
R
+
N
,
v
∈
R
+
N
{
τ
1
N
⊤
u
+
(
1
−
τ
)
1
N
⊤
v
∣
y
i
=
x
i
b
+
u
i
−
v
i
,
i
=
1
,
…
,
N
}
\min _{b \in \mathbb{R}^{K}, u \in \mathbb{R}_{+}^{N}, v \in \mathbb{R}_{+}^{N}}\left\{\tau \mathbf{1}_{N}^{\top} u+(1-\tau) \mathbf{1}_{N}^{\top} v \mid y_{i}=x_{i} b+u_{i}-v_{i}, i=1, \ldots, N\right\}
b∈RK,u∈R+N,v∈R+Nmin{τ1N⊤u+(1−τ)1N⊤v∣yi=xib+ui−vi,i=1,…,N}
注意到,上式中参数
b
∈
R
K
b\in\mathbb{R}^K
b∈RK不能保证非负,所以也需要将
b
b
b分解为正负部
b
=
b
+
−
b
−
b = b^+ - b^-
b=b+−b−
其中
b
+
=
max
(
0
,
b
)
,
b
−
=
max
(
0
,
−
b
)
b^+=\max(0, b), b^-=\max(0, -b)
b+=max(0,b),b−=max(0,−b), 该
N
N
N个等式约束以矩阵表达(更直观):
y
:
=
[
y
1
⋮
y
N
]
=
[
x
1
⊤
⋮
x
N
⊤
]
(
b
+
−
b
−
)
+
I
N
u
−
I
N
v
{y}:=\left[\begin{array}{c} y_{1} \\ \vdots \\ y_{N} \end{array}\right]=\left[\begin{array}{c} \mathbf{x}_{1}^{\top} \\ \vdots \\ \mathbf{x}_{N}^{\top} \end{array}\right]\left(b^{+}-b^{-}\right)+\mathbf{I}_{N} u-\mathbf{I}_{N} v
y:=
y1⋮yN
=
x1⊤⋮xN⊤
(b+−b−)+INu−INv
其中
I
N
=
d
i
a
g
(
1
N
)
\mathbf{I}_{N}=diag(\mathbf{1}_N)
IN=diag(1N).将
x
\mathbf{x}
x写为矩阵继续简化表达
X
(
b
+
−
b
−
)
+
I
N
u
−
I
N
v
=
[
X
,
−
X
,
I
N
,
−
I
N
]
[
b
+
b
−
u
v
]
\mathbf{X}\left(b^{+}-b^{-}\right)+\mathbf{I}_{N} u-\mathbf{I}_{N} v=\left[\mathbf{X},-\mathbf{X}, \mathbf{I}_{N},-\mathbf{I}_{N}\right]\left[\begin{array}{c} b^{+} \\ b^{-} \\ u \\ v \end{array}\right]
X(b+−b−)+INu−INv=[X,−X,IN,−IN]
b+b−uv
可以看到现在我们有
N
N
N个等式约束,
2
K
2K
2K个参数(因为参数被分为了正负部,所以乘2),另外还有
2
N
2N
2N个松弛变量:
A
:
=
[
X
−
X
I
N
−
I
N
]
A:=[\mathbf{X}\, -\mathbf{X}\quad \mathbf{I}_N \,\, -\mathbf{I}_N]
A:=[X−XIN−IN]
符合标准型的约束条件为:
b
∗
=
A
[
b
+
b
−
u
v
]
=
A
z
b^*=A \begin{bmatrix} b^+ \\ b^- \\ u \\ v \\ \end{bmatrix}=Az
b∗=A
b+b−uv
=Az
因为
b
+
b^+
b+和
b
−
b^-
b−仅通过约束影响最小化问题(优化目标中并不存在
b
b
b),所以必须引入维度为
2
K
×
1
2K \times 1
2K×1的
0
0
0 作为系数向量
c
c
c 的一部分,可以适当地定义为
c
=
[
0
τ
1
N
(
1
−
τ
)
1
N
]
c=\left[\begin{array}{c} \mathbf{0} \\ \tau \mathbf{1}_{N} \\ (1-\tau) \mathbf{1}_{N} \end{array}\right]
c=
0τ1N(1−τ)1N
这样目标函数就是
c
⊤
z
=
0
⊤
(
b
+
−
b
−
)
⏟
=
0
+
τ
1
N
⊤
u
+
(
1
−
τ
)
1
N
⊤
v
=
∑
i
=
1
N
ρ
τ
(
ε
i
)
.
c^{\top} z=\underbrace{\mathbf{0}^{\top}\left(b^{+}-b^{-}\right)}_{=0}+\tau \mathbf{1}_{N}^{\top} u+(1-\tau) \mathbf{1}_{N}^{\top} v=\sum_{i=1}^{N} \rho_{\tau}\left(\varepsilon_{i}\right) .
c⊤z==0
0⊤(b+−b−)+τ1N⊤u+(1−τ)1N⊤v=i=1∑Nρτ(εi).
1.1.1 编程实现
显然此时已经识别出了线性规划标准型的所有因素,利用R或python就可以实现求解
getwd()
setwd('C:/Users/beida/Desktop')
base=read.table("rent98_00.txt",header=TRUE)
attach(base)
library(quantreg)
library(lpSolve)
tau <- 0.5
# only one covariate
X <- cbind(1, base$area) #设计阵X
K <- ncol(X) #列数量,即参数个数
N <- nrow(X) #行数量,即样本量(等式约束量)
A <- cbind(X, -X, diag(N), -diag(N)) #优化系数
c <- c(rep(0, 2*ncol(X)), tau*rep(1, N), (1-tau)*rep(1, N)) #目标函数系数
b <- base$rent_euro #响应变量Y
const_type <- rep("=", N) #N个等式约束
linprog <- lp("min", c, A, const_type, b)
beta <- linprog$sol[1:K] - linprog$sol[(1:K+K)] #
beta
rq(rent_euro ~ area, tau=tau, data=base)
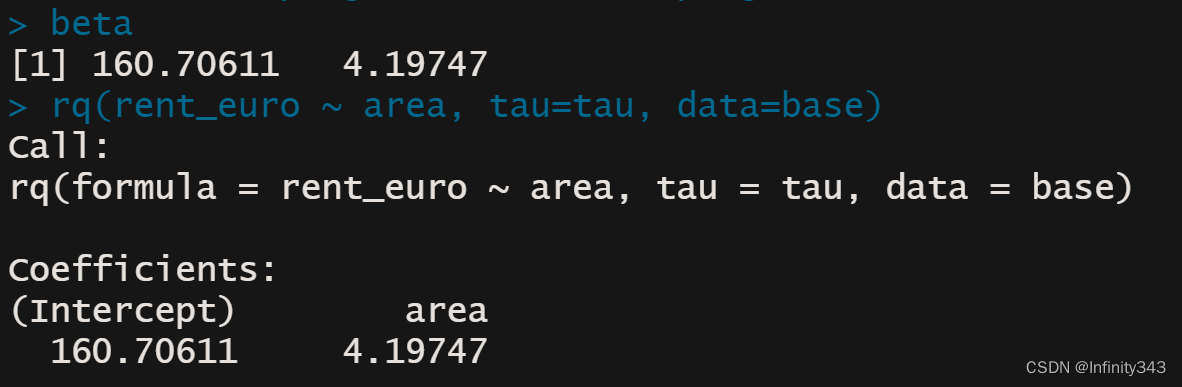
可以看到线性规划求解的结果与quantreg包的rq函数得到了相同的解。
python同理
import io
import numpy as np
import pandas as pd
import requests
np.
url = "http://freakonometrics.free.fr/rent98_00.txt"
s = requests.get(url).content
base = pd.read_csv(io.StringIO(s.decode('utf-8')), sep='\t')
tau = 0.5
from cvxopt import matrix, solvers
X = pd.DataFrame(columns=[0, 1])
X[1] = base["area"] # data points for independent variable area
#X[2] = base["year"] # data points for independent variable year
X[0] = 1 # intercept
K = X.shape[1]
N = X.shape[0]
# equality constraints - left hand side
A1 = X.to_numpy() # intercepts & data points - positive weights
A2 = X.to_numpy() * -1 # intercept & data points - negative weights
A3 = np.identity(N) # error - positive
A4 = np.identity(N) * -1 # error - negative
A = np.concatenate((A1, A2, A3, A4), axis=1) # all the equality constraints
# equality constraints - right hand side
b = base["rent_euro"].to_numpy()
# goal function - intercept & data points have 0 weights
# positive error has tau weight, negative error has 1-tau weight
c = np.concatenate((np.repeat(0, 2 * K), tau * np.repeat(1, N), (1 - tau) * np.repeat(1, N)))
# converting from numpy types to cvxopt matrix
Am = matrix(A)
bm = matrix(b)
cm = matrix(c)
# all variables must be greater than zero
# adding inequality constraints - left hand side
n = Am.size[1]
G = matrix(0.0, (n, n))
G[:: n + 1] = -1.0
# adding inequality constraints - right hand side (all zeros)
h = matrix(0.0, (n, 1))
# solving the model
sol = solvers.lp(cm, G, h, Am, bm, solver='glpk')
x = sol['x']
# both negative and positive components get values above zero, this gets fixed here
beta = x[0:K] - x[K : 2 * K]
print(beta)
- 思考
从R的运行情况来看,线性规划的求解速度显著慢于rq函数,这与求解方法有关。rq提供了以下方法来求解分位数回归:
the algorithmic method used to compute the fit. There are several options:
-
“br” The default method is the modified version of the Barrodale and Roberts algorithm for
l 1 l_1 l1-regression, used by l1fit in S, and is described in detail in Koenker and d’Orey(1987, 1994), default = “br”. This is quite efficient for problems up to several thousand observations, and may be used to compute the full quantile regression process. It also implements a scheme for computing confidence intervals for the estimated parameters, based on inversion of a rank test described in Koenker(1994). -
“fn” For larger problems it is advantageous to use the Frisch–Newton interior point method “fn”. This is described in detail in Portnoy and Koenker(1997).
-
“pfn” For even larger problems one can use the Frisch–Newton approach after preprocessing “pfn”. Also described in detail in Portnoy and Koenker(1997), this method is primarily well-suited for large n, small p problems, that is when the parametric dimension of the model is modest.
-
“sfn” For large problems with large parametric dimension it is often advantageous to use method “sfn” which also uses the Frisch-Newton algorithm, but exploits sparse algebra to compute iterates. This is especially helpful when the model includes factor variables that, when expanded, generate design matrices that are very sparse. At present options for inference, i.e. summary methods are somewhat limited when using the “sfn” method. Only the option se = “nid” is currently available, but I hope to implement some bootstrap options in the near future.
-
“fnc” Another option enables the user to specify linear inequality constraints on the fitted coefficients; in this case one needs to specify the matrix R and the vector r representing the constraints in the form Rb \geq rRb≥r. See the examples below.
-
“conquer” For very large problems especially those with large parametric dimension, this option provides a link to the conquer of He, Pan, Tan, and Zhou (2020). Calls to summary when the fitted object is computed with this option invoke the multiplier bootstrap percentile method of the conquer package and can be considerably quicker than other options when the problem size is large. Further options for this fitting method are described in the conquer package. Note that this option employs a smoothing form of the usual QR objective function so solutions may be expected to differ somewhat from those produced with the other options.
-
“pfnb” This option is intended for applications with large sample sizes and/or moderately fine tau grids. It uses a form of preprocessing to accelerate the solution process. The loop over taus occurs inside the Fortran call and there should be more efficient than other methods in large problems.
-
“qfnb” This option is like the preceeding one except that it doesn’t use the preprocessing option.
-
“ppro” This option is an R prototype of the pfnb and is offered for historical/interpretative purposes, but probably should be considered deprecated.
-
“lasso” There are two penalized methods: “lasso” and “scad” that implement the lasso penalty and Fan and Li smoothly clipped absolute deviation penalty, respectively. These methods should probably be regarded as experimental. Note: weights are ignored when the method is penalized.
可见求解方法之多,运行速度也不尽相同。但需要注意的是对于当前问题,单纯形法是很难甚至是无法求解的
simplex(c, A3 = A, b3 = b, maxi = TRUE, n.iter =200, eps = 1e-4)
> No feasible solution could be found
我们只选取了两个回归系数,样本量为4571,单纯形法的计算时间就超过了5分钟,且没有得到可行解(尽管降低了解的精度要求)。
后续将继续更新别的求解算法。
1.2 扩展(加权分位数回归)
加权分位数回归的思想是基于普通的线性分位回归,作为其的扩展新式,我们首先回顾分位回归的标准线性规划形式:
min
b
∈
R
K
,
u
∈
R
+
N
,
v
∈
R
+
N
{
τ
1
N
⊤
u
+
(
1
−
τ
)
1
N
⊤
v
∣
y
i
=
x
i
b
+
u
i
−
v
i
,
i
=
1
,
…
,
N
}
\min _{b \in \mathbb{R}^{K}, u \in \mathbb{R}_{+}^{N}, v \in \mathbb{R}_{+}^{N}}\left\{\tau \mathbf{1}_{N}^{\top} u+(1-\tau) \mathbf{1}_{N}^{\top} v \mid y_{i}=x_{i} b+u_{i}-v_{i}, i=1, \ldots, N\right\}
b∈RK,u∈R+N,v∈R+Nmin{τ1N⊤u+(1−τ)1N⊤v∣yi=xib+ui−vi,i=1,…,N}
其中残差的正负部除了被分配的
τ
\tau
τ和
1
−
τ
1-\tau
1−τ之外,系数为
1
N
⊤
\boldsymbol{1}_N^{\top}
1N⊤。思考这样一个问题,如果将系数改变,那么上述规划问题就成为了残差不等全问题:
min
(
b
,
u
,
v
)
∈
R
K
×
R
+
2
n
{
τ
w
T
u
+
(
1
−
τ
)
w
T
v
∣
x
⊤
b
+
u
−
v
=
y
}
\min _{(b, \mathbf{u}, \mathbf{v}) \in R^K \times R_{+}^{2 n}}\left\{\tau \mathbf{w}^{\mathrm{T}} \mathbf{u}+(1-\tau) \mathbf{w}^{\mathrm{T}} \mathbf{v} \mid \mathbf{x}^{\top}b+\mathbf{u}-\mathbf{v}=\mathbf{y}\right\}
(b,u,v)∈RK×R+2nmin{τwTu+(1−τ)wTv∣x⊤b+u−v=y}
其中
w
=
w
1
,
…
,
w
n
\mathbf{w}=w_1,\dots, w_n
w=w1,…,wn是
n
×
1
n\times 1
n×1的权重向量。
证明:
首先有目标函数
min
(
b
,
e
i
)
∈
R
K
×
R
+
n
{
∑
i
=
1
n
w
i
ρ
τ
(
y
i
−
x
i
⊤
b
)
∣
e
i
=
y
i
−
x
i
⊤
b
}
\min _{\left(b, e_{i}\right) \in R^K \times R_{+}^{n}}\left\{\sum_{i=1}^{n} w_{i} \rho_{\tau}\left(y_{i}-x_i^{\top}b\right) \mid e_{i}=y_{i}-x_i^{\top}b\right\}
(b,ei)∈RK×R+nmin{i=1∑nwiρτ(yi−xi⊤b)∣ei=yi−xi⊤b}
把
x
i
⊤
β
x_i^{\top}\beta
xi⊤β记为
q
q
q来简化表达,这样
u
u
u和
v
v
v的定义变为:
u
i
=
{
y
i
−
q
for
y
i
>
q
,
0
otherwise
v
i
=
{
−
(
y
i
−
q
)
for
y
i
<
q
,
0
otherwise
u_{i}=\left\{\begin{array}{ll} y_{i}-q & \text { for } y_{i}>q, \\ 0 & \text { otherwise } \end{array} \quad v_{i}=\left\{\begin{array}{ll} -\left(y_{i}-q\right) & \text { for } y_{i}<q, \\ 0 & \text { otherwise } \end{array}\right.\right.
ui={yi−q0 for yi>q, otherwise vi={−(yi−q)0 for yi<q, otherwise
则有损失函数(loss function):
R
(
q
)
=
∑
i
=
1
n
w
i
ρ
τ
(
y
i
−
q
)
=
∑
y
i
<
q
w
i
(
τ
−
1
)
(
−
v
i
)
+
∑
y
i
≥
q
w
i
(
τ
u
i
)
=
(
1
−
τ
)
∑
i
=
1
n
w
i
v
i
+
τ
∑
i
=
1
n
w
i
u
i
=
(
1
−
τ
)
w
T
v
+
τ
w
T
u
\begin{aligned} R(q) &=\sum_{i=1}^{n} w_{i} \rho_{\tau}\left(y_{i}-q\right) \\ &=\sum_{y_{i}<q} w_{i}(\tau-1)\left(-v_{i}\right)+\sum_{y_{i} \geq q} w_{i}\left(\tau u_{i}\right) \\ &=(1-\tau) \sum_{i=1}^{n} w_{i} v_{i}+\tau \sum_{i=1}^{n} w_{i} u_{i} \\ &=(1-\tau) \mathbf{w}^{\mathrm{T}} \mathbf{v}+\tau \mathbf{w}^{\mathrm{T}} \mathbf{u} \end{aligned}
R(q)=i=1∑nwiρτ(yi−q)=yi<q∑wi(τ−1)(−vi)+yi≥q∑wi(τui)=(1−τ)i=1∑nwivi+τi=1∑nwiui=(1−τ)wTv+τwTu
其中
w
=
(
w
i
,
…
,
w
n
)
⊤
,
u
=
(
u
1
,
…
,
u
n
)
⊤
\mathbf{w}=(w_i,\dots,w_ n)^{\top}, \mathbf{u}=(u_1,\dots,u_n)^{\top}
w=(wi,…,wn)⊤,u=(u1,…,un)⊤,
v
=
(
v
1
,
…
,
v
n
)
⊤
\mathbf{v}=(v_1,\dots,v_n)^{\top}
v=(v1,…,vn)⊤
e
i
=
y
i
−
q
=
u
i
−
v
i
,
i
=
1
,
…
,
n
.
e_i=y_i -q=u_i-v_i,\quad i=1,\dots,n.
ei=yi−q=ui−vi,i=1,…,n.
约束条件改为
{
e
1
=
y
1
−
q
e
2
=
y
2
−
q
⋯
e
n
=
y
n
−
q
→
{
u
1
−
v
1
=
y
1
−
q
u
2
−
v
2
=
y
2
−
q
⋯
u
n
−
v
n
=
y
n
−
q
→
{
q
+
u
1
−
v
1
=
y
1
q
+
u
2
−
v
2
=
y
2
⋯
q
+
u
n
−
v
n
=
y
n
→
{
1
n
q
+
u
−
v
=
y
}
\left\{\begin{array} { l } { e _ { 1 } = y _ { 1 } - q } \\ { e _ { 2 } = y _ { 2 } - q } \\ { \cdots } \\ { e _ { n } = y _ { n } - q } \end{array} \rightarrow \left\{\begin{array} { l } { u _ { 1 } - v _ { 1 } = y _ { 1 } - q } \\ { u _ { 2 } - v _ { 2 } = y _ { 2 } - q } \\ { \cdots } \\ { u _ { n } - v _ { n } = y _ { n } - q } \end{array} \rightarrow \left\{\begin{array} { l } { q + u _ { 1 } - v _ { 1 } = y _ { 1 } } \\ { q + u _ { 2 } - v _ { 2 } = y _ { 2 } } \\ { \cdots } \\ { q + u _ { n } - v _ { n } = y _ { n } } \end{array} \quad \rightarrow \left\{\mathbf{1}_{n} q+\mathbf{u}-\mathbf{v}=\mathbf{y}\right\}\right.\right.\right.
⎩
⎨
⎧e1=y1−qe2=y2−q⋯en=yn−q→⎩
⎨
⎧u1−v1=y1−qu2−v2=y2−q⋯un−vn=yn−q→⎩
⎨
⎧q+u1−v1=y1q+u2−v2=y2⋯q+un−vn=yn→{1nq+u−v=y}
所以有:
min
(
q
,
u
,
v
)
∈
R
×
R
+
2
n
{
τ
w
T
u
+
(
1
−
τ
)
w
T
v
∣
1
n
q
+
u
−
v
=
y
}
\min _{(q, \mathbf{u}, \mathbf{v}) \in R \times R_{+}^{2 n}}\left\{\tau \mathbf{w}^{\mathrm{T}} \mathbf{u}+(1-\tau) \mathbf{w}^{\mathrm{T}} \mathbf{v} \mid \mathbf{1}_{n} q+\mathbf{u}-\mathbf{v}=\mathbf{y}\right\}
(q,u,v)∈R×R+2nmin{τwTu+(1−τ)wTv∣1nq+u−v=y}
很明显加权是对于
u
\mathbf{u}
u和
v
\mathbf{v}
v而言的,那么1.1节中的规划算法仍然适用,而问题转变为了如何选择权重. Huang(2015)的建议是:
(i) For bivariate symmetrically distributed data, we suggest the first weighting scheme:
w
i
(
x
i
,
τ
)
=
{
e
x
i
T
1
,
τ
≤
0.5
,
e
−
x
i
T
2
,
τ
>
0.5
w_i\left(x_i, \tau\right)= \begin{cases}\frac{\mathrm{e}^{x_i}}{T_1}, & \tau \leq 0.5, \\ \frac{\mathrm{e}^{-x_i}}{T_2}, & \tau>0.5\end{cases}
wi(xi,τ)={T1exi,T2e−xi,τ≤0.5,τ>0.5
where
T
1
=
∑
i
=
1
n
e
x
i
,
T
2
=
∑
i
=
1
n
e
−
x
i
T_1=\sum_{i=1}^n \mathrm{e}^{x_i}, T_2=\sum_{i=1}^n \mathrm{e}^{-x_i}
T1=∑i=1nexi,T2=∑i=1ne−xi, and both ensure that all weights add up to 1 .
(ii) For multivariate data with positive values, we suggest the second weighting scheme:
w
i
(
x
i
)
=
∥
x
i
∥
T
,
w_i\left(\mathbf{x}_i\right)=\frac{\left\|\mathbf{x}_i\right\|}{T},
wi(xi)=T∥xi∥,
where
x
i
=
(
x
i
1
,
…
,
x
i
k
)
T
,
∥
x
i
∥
=
∑
j
=
1
k
x
i
j
2
\mathbf{x}_i=\left(x_{i 1}, \ldots, x_{i k}\right)^{\mathrm{T}},\left\|\mathbf{x}_i\right\|=\sqrt{\sum_{j=1}^k x_{i j}^2}
xi=(xi1,…,xik)T,∥xi∥=∑j=1kxij2, and
T
=
∑
i
=
1
n
∥
x
i
∥
T=\sum_{i=1}^n\left\|\mathbf{x}_i\right\|
T=∑i=1n∥xi∥. Here,
w
i
(
x
i
)
,
i
=
1
,
…
,
n
w_i\left(\mathbf{x}_i\right), i=1, \ldots, n
wi(xi),i=1,…,n are not dependent on
τ
\tau
τ.
1.2.1 R实现
还是使用相同的数据集与设定
getwd()
setwd('C:/Users/beida/Desktop')
base=read.table("rent.txt", header=TRUE)
library(quantreg)
library(lpSolve)
tau <- 0.5
# only one covariate
X <- cbind(1, base$area) #设计阵X
Y <- base$rent_euro
K <- ncol(X) #列数量,即参数个数
N <- nrow(X) #行数量,即样本量(等式约束量)
W = rep(1, N)
#W = exp(X[, 1])/sum(exp(X[, 1]))
TT = 0
for (i in 1:dim(X)[1]){
W_T = sqrt(X[i,1]^2 + X[i,2]^2)
TT = TT + W_T
}
for (i in 1:dim(X)[1]){
W[i] = sqrt(X[i,1]^2 + X[i,2]^2)/TT
}
A <- cbind(X, -X, diag(N), -diag(N)) #优化系数
c <- c(rep(0, 2*ncol(X)), tau*rep(1, N)*W, (1-tau)*rep(1, N)*W) #目标函数系数
const_type <- rep("=", N) #N个等式约束
linprog <- lp("min", c, A, const_type, Y)
beta <- linprog$sol[1:K] - linprog$sol[(1:K+K)] #
beta
rq('rent_euro ~ area', tau=tau, weights = W, data=base)
rq('rent_euro ~ area', tau=tau, weights = NULL, data=base)
plot(X[,2], Y)
abline(rq('rent_euro ~ area', tau=tau, weights = W, data=base), col='blue')
abline(rq('rent_euro ~ area', tau=tau, weights = NULL, data=base), col='red')
abline(lm(base$rent_euro ~ base$area), col='yellow')
为了对比计算结果,我们同时使用了rq函数,并给定相同的权重

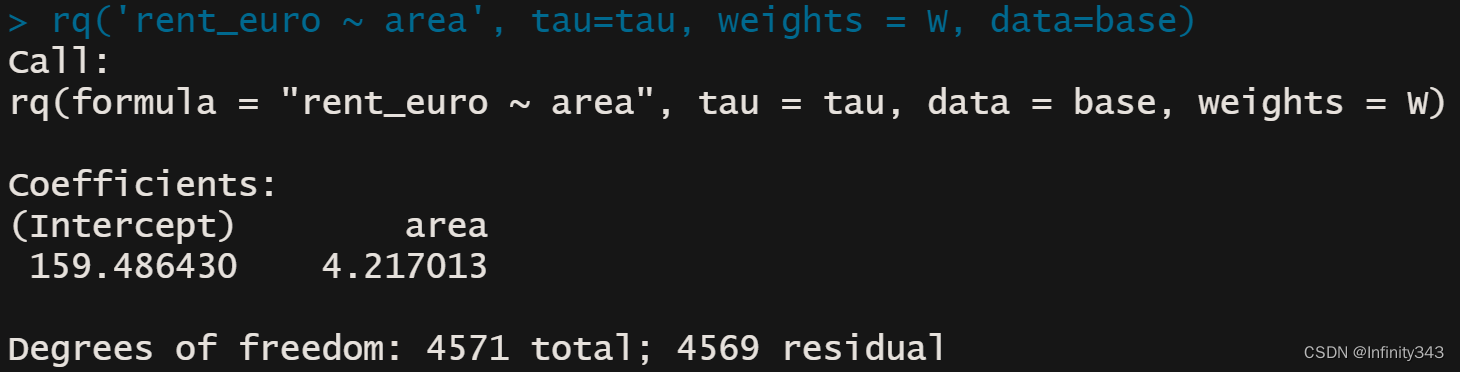
可见二者结果是相同的,将他们得到的回归直线画出来
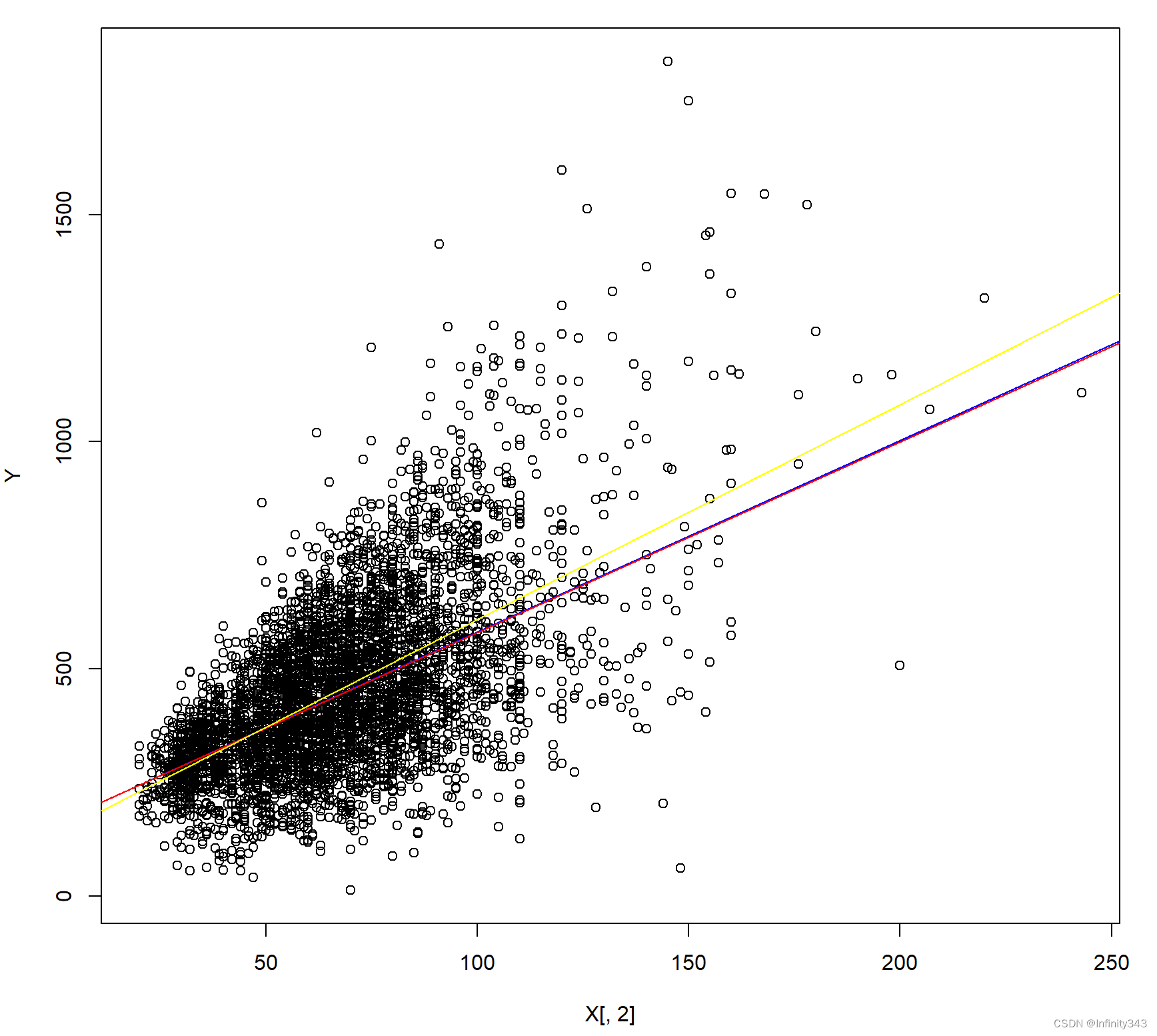
黄线是条件均值回归,蓝线是加权分位回归,红线是普通分位回归,由于后两者之间的斜率差距很小,直线差别不大
参考文献
- [1] Huang, M. L., Xu, X., & Tashnev, D. (2015). A weighted linear quantile regression. Journal of Statistical Computation and Simulation, 85(13), 2596-2618.
- [2] Koenker, R., & Hallock, K. F. (2001). Quantile regression. Journal of economic perspectives, 15(4), 143-156.
- [3] Koenker, R., Chernozhukov, V., He, X., & Peng, L. (Eds.). (2017). Handbook of quantile regression.
- [4] Koenker, R. (2017). Quantile regression: 40 years on. Annual review of economics, 9, 155-176.
2 GCD
本次将介绍另一个
ℓ
1
\ell_1
ℓ1回归问题的求解方法:贪婪坐标下降(Greedy Coordinate Descent, GCD)。
在这之前,先引入一些前导内容
2.1 拉普拉斯分布(Laplace disribution)
- pdf
一个服从 L a p l a c e ( μ , b ) \mathrm{Laplace}(\mu,b) Laplace(μ,b)的随机变量 X X X, 其pdf为:
f X ( x ∣ μ , b ) = 1 2 b exp ( − ∣ x − μ ∣ b ) f_X(x|\mu,b)=\frac{1}{2b}\exp{\left( -\frac{|x-\mu|}{b}\right)} fX(x∣μ,b)=2b1exp(−b∣x−μ∣)
其中 μ \mu μ是位置参数, b > 0 b>0 b>0是尺度参数. 很明显,当 μ = 0 , b = 1 \mu=0,b=1 μ=0,b=1拉普拉斯分布就是 θ = 1 / 2 \theta=1/2 θ=1/2的指数分布。 - cdf
F ( x ) = ∫ − ∞ x f ( u ) d u = { 1 2 exp ( x − μ b ) if x < μ 1 − 1 2 exp ( − x − μ b ) if x ≥ μ = 1 2 + 1 2 sgn ( x − μ ) ( 1 − exp ( − ∣ x − μ ∣ b ) ) \begin{aligned} F(x) &=\int_{-\infty}^{x} f(u) \mathrm{d} u=\left\{\begin{array}{ll} \frac{1}{2} \exp \left(\frac{x-\mu}{b}\right) & \text { if } x<\mu \\ 1-\frac{1}{2} \exp \left(-\frac{x-\mu}{b}\right) & \text { if } x \geq \mu \end{array}\right.\\ &=\frac{1}{2}+\frac{1}{2} \operatorname{sgn}(x-\mu)\left(1-\exp \left(-\frac{|x-\mu|}{b}\right)\right) \end{aligned} F(x)=∫−∞xf(u)du={21exp(bx−μ)1−21exp(−bx−μ) if x<μ if x≥μ=21+21sgn(x−μ)(1−exp(−b∣x−μ∣))
- 逆cdf:
F − 1 ( p ) = μ − b sgn ( p − 0.5 ) ln ( 1 − 2 ∣ p − 0.5 ∣ ) . F^{-1}(p)=\mu-b \operatorname{sgn}(p-0.5) \ln (1-2|p-0.5|) . F−1(p)=μ−bsgn(p−0.5)ln(1−2∣p−0.5∣).
2.2 MLE
n
n
n个iid样本的联合似然函数:
L
(
μ
,
b
)
=
(
1
2
b
)
n
exp
(
−
∑
i
N
∣
x
i
−
μ
∣
b
)
L(\mu,b)=\left(\frac{1}{2b}\right)^{n}\exp{\left( -\frac{\sum_{i}^N|x_i-\mu|}{b}\right)}
L(μ,b)=(2b1)nexp(−b∑iN∣xi−μ∣)
对数联合似然(joint log-likelihood):
l
(
μ
,
b
)
=
log
L
=
−
n
log
2
b
−
1
b
∑
i
N
∂
∣
x
i
−
μ
∣
∂
μ
l(\mu,b)=\log{L}=-n\log{2b}-\frac{1}{b}\sum_{i}^N\frac{\partial|x_i-\mu|}{\partial\mu}
l(μ,b)=logL=−nlog2b−b1i∑N∂μ∂∣xi−μ∣
其中需要绝对值求导:
∂
∣
x
∣
∂
x
=
∂
x
2
∂
x
=
x
(
x
2
)
−
1
/
2
=
x
∣
x
∣
=
s
g
n
(
x
)
\frac{\partial|x|}{\partial x}=\frac{\partial\sqrt{x^2}}{\partial x}=x(x^2)^{-1/2}=\frac{x}{|x|}=\mathrm{sgn}(x)
∂x∂∣x∣=∂x∂x2=x(x2)−1/2=∣x∣x=sgn(x)
对
μ
\mu
μ求偏导并等于0:
∂
l
(
μ
,
b
)
∂
μ
=
1
b
∑
i
=
1
N
s
g
n
(
x
i
−
μ
)
=
0
\frac{\partial l(\mu,b)}{\partial \mu}=\frac{1}{b}\sum_{i=1}^N\mathrm{sgn}(x_i-\mu)=0
∂μ∂l(μ,b)=b1i=1∑Nsgn(xi−μ)=0
此时的解只与
N
N
N有关。
- N N N是奇数,显然 μ ^ = m e d i a n ( x 1 , … , x N ) \hat{\mu}=\mathrm{median}(x_1,\dots,x_N) μ^=median(x1,…,xN)。因为 N − 1 2 \frac{N-1}{2} 2N−1个样本小于中位数,为 − 1 -1 −1, N − 1 2 \frac{N-1}{2} 2N−1个样本大于中位数,为 + 1 +1 +1。所以满足等式为 0 0 0。
-
N
N
N是偶数,解为
x
N
/
2
x_{N/2}
xN/2或
x
(
N
+
1
)
/
2
x_{(N+1)/2}
x(N+1)/2。
另外:
b ^ = 1 N ∑ i = 1 N ∣ x i − u ^ ∣ \hat{b}=\frac{1}{N}\sum_{i=1}^N|x_i-\hat{u}| b^=N1i=1∑N∣xi−u^∣
2.3 LAD回归(分位数回归的特例)
考虑一个简单的LAD线性回归问题,包括
N
N
N个观测
(
X
i
,
Y
i
)
(X_i,Y_i)
(Xi,Yi):
Y
i
=
a
X
i
+
b
+
U
i
,
i
=
1
,
2
,
…
,
N
Y_i=aX_i+b+U_i,\quad i=1,2,\dots,N
Yi=aXi+b+Ui,i=1,2,…,N
其中
a
a
a是直线斜率,
b
b
b是截距项。
U
i
U_i
Ui是服从零均值
f
(
U
)
=
(
1
/
2
λ
)
e
−
∣
U
∣
/
λ
f(U)=(1/2\lambda)e^{-|U|/\lambda}
f(U)=(1/2λ)e−∣U∣/λ的拉普拉斯分布,方差为
σ
2
=
2
λ
2
\sigma^2=2\lambda^2
σ2=2λ2。则此时的目标函数为
F
(
a
,
b
)
=
∑
i
=
1
N
∣
Y
i
−
a
X
i
−
b
∣
F(a,b)=\sum_{i=1}^N|Y_i-aX_i-b|
F(a,b)=i=1∑N∣Yi−aXi−b∣
对于如何求解
a
,
b
a,b
a,b有如下算法。先建立一个线性回归模型,其中固定
a
=
a
0
a=a_0
a=a0:
F
(
b
)
=
∑
i
=
1
N
∣
Y
i
−
a
0
X
i
−
b
∣
F(b)=\sum_{i=1}^N|Y_i-a_0X_i-b|
F(b)=i=1∑N∣Yi−a0Xi−b∣
对于之前设定的误差项
U
i
U_i
Ui,
b
b
b的解是极大似然估计量
b
∗
=
m
e
d
(
Y
i
−
a
0
X
i
∣
i
=
1
N
)
b^*=\mathrm{med}(Y_i-a_0X_i|_{i=1}^N)
b∗=med(Yi−a0Xi∣i=1N)
另一方面,如果固定
b
=
b
0
b=b_0
b=b0,目标函数为:
F
(
a
)
=
∑
i
=
1
N
∣
Y
i
−
b
0
−
a
X
i
∣
=
∑
i
=
1
N
∣
X
i
∣
∣
Y
i
−
b
0
X
i
−
a
∣
\begin{aligned} F(a)&=\sum_{i=1}^N|Y_i-b_0-aX_i| \\ &=\sum_{i=1}^N|X_i|\left| \frac{Y_i-b_0}{X_i}-a\right| \end{aligned}
F(a)=i=1∑N∣Yi−b0−aXi∣=i=1∑N∣Xi∣
XiYi−b0−a
由于随机误差项是拉普拉斯分布的,
{
(
Y
i
−
b
0
)
/
X
i
}
\{(Y_i-b_0)/X_i\}
{(Yi−b0)/Xi}也是拉普拉斯分布的,此时
a
a
a的解是
a
∗
=
m
e
d
(
∣
X
i
∣
△
Y
i
−
b
0
X
i
∣
i
=
1
N
)
a^*=\mathrm{med}\left( |X_i| \triangle \left.\frac{Y_i-b_0}{X_i}\right|_{i=1}^N \right)
a∗=med(∣Xi∣△XiYi−b0
i=1N)
其中
△
\triangle
△是复制运算符,对于正整数
∣
X
i
∣
|X_i|
∣Xi∣,
∣
X
i
∣
△
Y
i
|X_i|\triangle Y_i
∣Xi∣△Yi表示
Y
i
Y_i
Yi被复制|X_i|次,如果
∣
X
i
∣
|X_i|
∣Xi∣不是整数,计算加权中位数:
Y
=
m
e
d
(
W
i
△
X
i
∣
i
=
1
N
)
Y = \mathrm{med}\left( \left.W_i\triangle X_i \right|_{i=1}^N \right)
Y=med(Wi△Xi∣i=1N)
算法如下:
- 计算阈值 W 0 = ( 1 / 2 ) ∑ i = 1 N W i W_0=(1/2)\sum_{i=1}^N W_i W0=(1/2)∑i=1NWi
- 对样本排序 X ( 1 ) , … , X ( N ) X_{(1)},\dots,X_{(N)} X(1),…,X(N)并伴随相应的权重 W [ 1 ] , … , W [ N ] W_{[1]}, \dots, W_{[N]} W[1],…,W[N]
- 按顺序将 W [ 1 ] W_{[1]} W[1]向上求和
- 第一个满足 ∑ i = 1 j W [ i ] > W 0 \sum_{i=1}^j W_{[i]}>W_0 ∑i=1jW[i]>W0的 X ( j ) X_{(j)} X(j)就是加权中位数 Y Y Y
由此可以得到贪婪坐标下降算法的步骤:
(1). 令
k
=
0
k=0
k=0,设定初值
a
0
a_0
a0
(2). 令
k
=
k
+
1
k=k+1
k=k+1, 用
a
k
−
1
a_{k-1}
ak−1获得
b
b
b的估计
b
k
=
m
e
d
(
Y
i
−
a
k
−
1
X
i
∣
i
=
1
N
)
b_k=\mathrm{med}\left( \left.Y_i - a_{k-1}X_i \right|_{i=1}^N \right)
bk=med(Yi−ak−1Xi∣i=1N)
(3). 利用
b
k
b_k
bk获得
a
a
a的第
k
k
k次估计:
a
k
=
m
e
d
(
∣
X
i
∣
△
Y
i
−
b
k
X
i
∣
i
=
1
N
)
a_k=\mathrm{med}\left( |X_i|\triangle\left.\frac{Y_i-b_k}{X_i}\right|_{i=1} ^N\right)
ak=med(∣Xi∣△XiYi−bk
i=1N)
(4). 当
a
k
−
a
k
−
1
a_k-a_{k-1}
ak−ak−1和
b
k
−
b
k
−
1
b_k-b_{k-1}
bk−bk−1在允许误差范围时停止迭代,否则返回(2).
2.4 Python实现
data = pd.read_csv(r"C:\Users\beida\Desktop\sc\rent.csv")
n = len(data); p = 1
x = np.insert(np.matrix(data["area"],dtype=np.float64).reshape((n, p)), obj=0, values=np.ones(n), axis=1)
#x = np.matrix(data["area"][0:n]).reshape((n, 1))
y = np.matrix(data["rent_euro"],dtype=np.float64).reshape(n, 1)
#beta = np.matrix([100, 2.6]).reshape(p, 1)
我们还是使用第一章的数据,并且进行中位数回归
#np.set_printoptions(precision=8)
tau = 0.5
maxit = 100
toler = 0.0001
error = 10000
iteration = 1
p = 1
#beta = np.matrix([1, 1], dtype=np.float64).reshape(2, 1)
beta = np.linalg.pinv(x.T.dot(x)).dot(x.T).dot(y)
#print(beta, "ols")
while (iteration <= maxit) & (error>toler):
betaold = beta.copy()
#print(betaold, 'betaold')
uv = np.sort(y-x.dot(beta), axis = 0) #yes
quantile1 = (n-1)*tau - np.floor((n-1)*tau) #yes
#quantile2 = 1 - tau
#int(np.ceil((n-1)*tau)), int(np.floor((n-1)*tau))
#uv[80]*0.2 + uv[80]*0.8
u = quantile1*uv[int(np.ceil((n-1)*tau))] \
+ (1-quantile1)*uv[int(np.floor((n-1)*tau))] #yes
r = y - u - x.dot(beta) #yes
signw = (1 - np.sign(r))/2*(1-tau) + (np.sign(r)+1)*tau/2 #yes
for j in range(0, p+1):
z = (r + x[:,j]*beta[j])/x[:, j] #yes
order = z.A[:,0].argsort() #yes
sortz = z.A[order] #yes
newX = np.multiply(x[:,j], signw) #
newX = newX.astype('float64')
w = np.abs(newX[order]) #
index = np.where(np.cumsum(w) > (np.sum(w)/2))[1][0] #YES
beta[j] = sortz[index][0] #
#print(betaold, "betaold")
error = np.sum(np.abs(beta-betaold))
iteration = iteration + 1
print(beta)
按照算法编写代码,结果为:
> [[135.63724592]
[ 4.21550906]]
显然这和之前的线性规划、rq函数存在着差异,其中截距项差距较大,斜率差距仅为0.018. 可见坐标下降算法的优势在于计算速度较快(显著快于线性规划),但需要精度作为代价。
参考文献
3 IRWS(迭代重加权最小二乘)
求解分位数回归的另一个算法是迭代重加权最小二乘(Iteratively Reweighted Least Squares, IRLS). 也有学者称之为迭代加权最小二乘(Iteratively Weighted Least Squares, IWLS), 虽然它们最后指向同一个算法,但是实际上IWLS这个说法不准确,因为每次迭代过程中的权重矩阵是不相同,相当于每次重新进行了加权,所以称之为重加权(Reweighted)。
这个算法的适用范围较广,表达较为清晰简洁。
3.1 考虑一个 ℓ p \ell_p ℓp线性回归
寻找参数
β
=
(
β
1
,
…
,
β
k
)
⊤
\boldsymbol{\beta}=(\beta_1,\dots,\beta_k)^{\top}
β=(β1,…,βk)⊤来最小化:
arg min
β
∣
∣
y
−
X
β
∣
∣
p
=
arg min
β
1
,
…
,
β
k
∑
i
=
1
n
∣
y
i
−
X
i
β
∣
p
\argmin_{\boldsymbol{\beta}}||\boldsymbol{y}-\boldsymbol{X}\boldsymbol{\beta}||_p=\argmin_{\beta_1,\dots,\beta_k}\sum_{i=1}^n|y_i-X_i\boldsymbol{\beta}|^{p}
βargmin∣∣y−Xβ∣∣p=β1,…,βkargmini=1∑n∣yi−Xiβ∣p
对于第
t
+
1
t+1
t+1次迭代,IRLS算法求解的是一个加权最小二乘问题
β
(
t
+
1
)
=
arg min
β
∑
i
=
1
n
w
i
(
t
)
∣
y
i
−
X
i
β
(
t
)
∣
2
=
(
X
⊤
W
(
t
)
X
)
−
1
X
⊤
W
(
t
)
y
\begin{aligned} \boldsymbol{\beta}^{(t+1)}&=\argmin_{\boldsymbol{\beta}}\sum_{i=1}^nw_i^{(t)}|y_i-X_i\boldsymbol{\beta}^{(t)}|^{2}\\ &=(\boldsymbol{X}^{\top}\boldsymbol{W}^{(t)}\boldsymbol{X})^{-1}\boldsymbol{X}^{\top}\boldsymbol{W}^{(t)}\boldsymbol{y} \end{aligned}
β(t+1)=βargmini=1∑nwi(t)∣yi−Xiβ(t)∣2=(X⊤W(t)X)−1X⊤W(t)y
其中
W
(
t
)
W^{(t)}
W(t)是由权重组成的对角阵,初始值为
w
0
(
0
)
=
1
w_0^{(0)}=1
w0(0)=1
下次更新值
w
i
(
t
)
=
∣
y
i
−
X
i
β
(
t
)
∣
p
−
2
w_i^{(t)}=|y_i-\boldsymbol{X}_i\boldsymbol{\beta}^{(t)}|^{p-2}
wi(t)=∣yi−Xiβ(t)∣p−2
显然当
p
=
1
p=1
p=1时就是LAD回归
w
i
(
t
)
=
1
∣
y
i
−
X
i
β
(
t
)
∣
w_{i}^{(t)}=\frac{1}{\left|y_{i}-X_{i} \boldsymbol{\beta}^{(t)}\right|}
wi(t)=
yi−Xiβ(t)
1
为了避免分母为0:
w
i
(
t
)
=
1
max
{
δ
,
∣
y
i
−
X
i
β
(
t
)
∣
}
w_{i}^{(t)}=\frac{1}{\max \left\{\delta,\left|y_{i}-X_{i} \boldsymbol{\beta}^{(t)}\right|\right\}}
wi(t)=max{δ,
yi−Xiβ(t)
}1
其中
δ
\delta
δ是一个非常小的数。这个符号与稳健回归(Robust)中的Huber Loss Function中的
δ
\delta
δ是相同的。
3.2 Python实现
还是相同的数据集
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from tqdm.autonotebook import tqdm
data = pd.read_csv(r"C:\Users\beida\Desktop\sc\rent.csv")
X = np.array(data['area']) #解释变量
Y = np.array(data['rent_euro']) #响应变量
nobs = len(X) 样本量
constant = np.ones(nobs) #截距项列
X = np.column_stack((constant, X)) #设计阵
W = np.diag([1] * len(X)) #权重矩阵初始化
同样采用中位数回归
q = 0.5
for i in tqdm(range(100), colour='blue'):
beta = np.dot(np.dot(np.dot(np.linalg.inv(np.dot(np.dot(X.T, W), X)), X.T), W), Y)
resid = Y - np.dot(X, beta)
resid = np.where(resid < 0, q * resid, (1-q) * resid)
resid = np.abs(resid)
W = np.diag(1/resid)
print(beta)
由于目的是为了测试算法,所以直接使用了for循环,结果如下

statsmodels库也提供了分位数回归的接口
mod = smf.quantreg("rent_euro ~ area", data)
res = mod.fit(q=0.5)
print(res.summary())
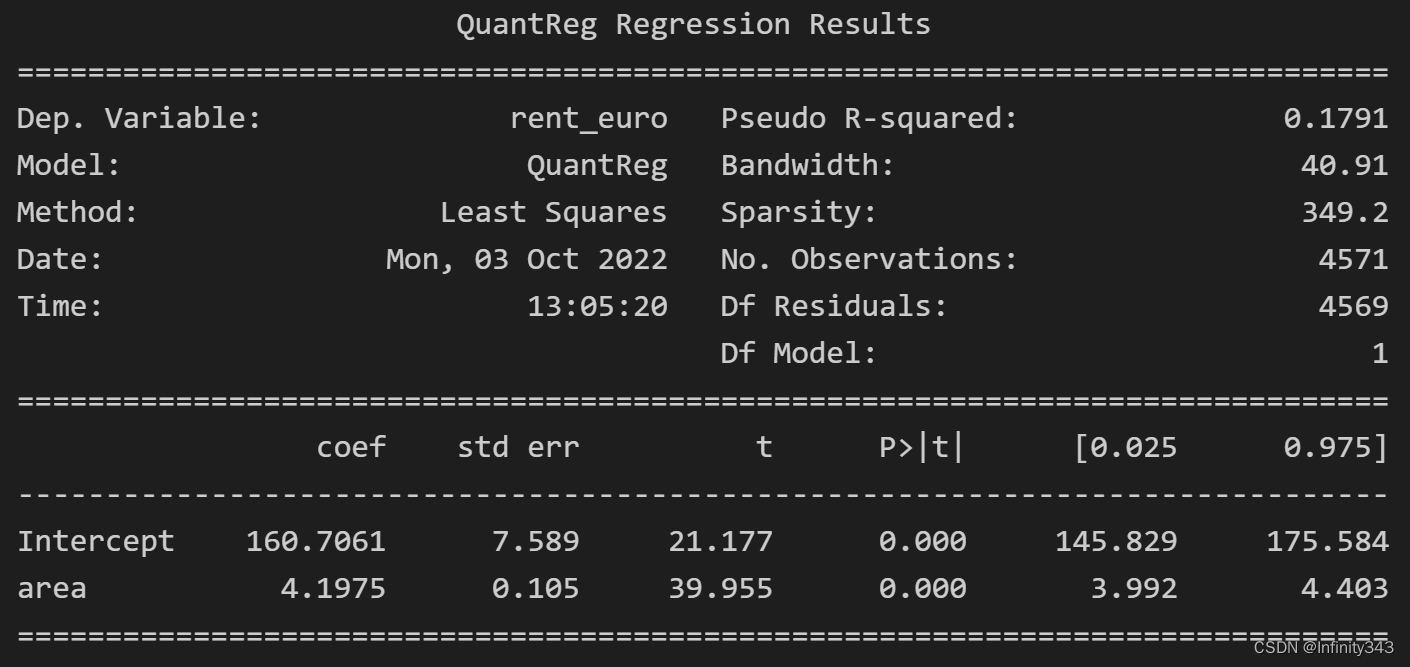
可见结果是完全相同的。
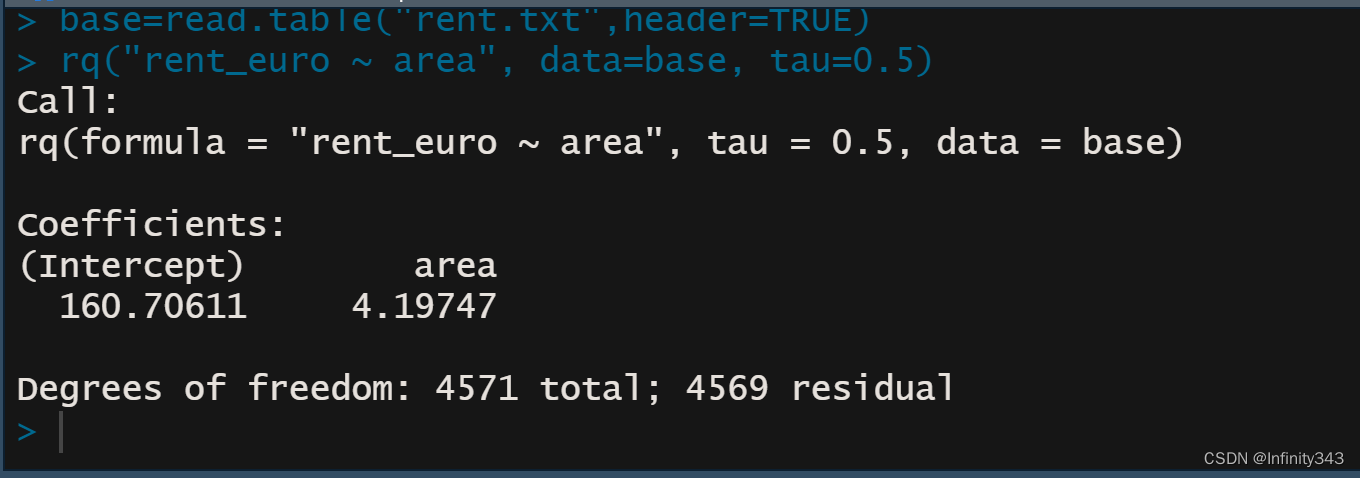
与R的结果也相同。
参考文献
4 MM算法
4.1 介绍
MM 算法是一种迭代优化方法,它利用函数的凸性来找到它的最大值或最小值。 MM 代表“Majorize-Minimization”或“Minorize-Maximization”,具体取决于所需的优化是最小化还是最大化。 尽管有这个名字,MM 本身并不是一个算法,而是描述了如何构造一个优化算法。
期望最大化算法(EM algorithm)可以被视为 MM 算法的一个特例。 但是,在EM算法中通常会涉及到条件期望,而在MM算法中,凸性和不等式是主要关注点,在大多数情况下更容易理解和应用。
MM 算法的工作原理是找到一个使目标函数最小化或重大化的替代函数。优化替代函数(surrogate function)要么提高目标函数的值,要么保持不变。取minorize-maximization 版本,令
f
(
θ
)
f(\theta)
f(θ) 为要最大化的目标凹函数。在算法的
m
m
m步骤,
m
=
0
,
1
…
m=0,1\ldots
m=0,1…,构造函数
g
(
θ
∣
θ
m
)
g\left(\theta\mid\theta_m\right)
g(θ∣θm)将被称为目标函数的小化版本(代理函数)在
θ
m
\theta_m
θm if
g
(
θ
∣
θ
m
)
≤
f
(
θ
)
for all
θ
g
(
θ
m
∣
θ
m
)
=
f
(
θ
m
)
\begin{aligned} &g\left(\theta \mid \theta_m\right) \leq f(\theta) \text { for all } \theta \\ &g\left(\theta_m \mid \theta_m\right)=f\left(\theta_m\right) \end{aligned}
g(θ∣θm)≤f(θ) for all θg(θm∣θm)=f(θm)
然后,最大化
g
(
θ
∣
θ
m
)
g\left(\theta\mid\theta_m\right)
g(θ∣θm) 而不是
f
(
θ
)
f(\theta)
f(θ),并让
θ
m
+
1
=
arg
max
θ
g
(
θ
∣
θ
m
)
\theta_{m+1}=\arg \max _\theta g\left(\theta\mid \theta_m\right)
θm+1=argθmaxg(θ∣θm)
上述迭代方法将保证
f
(
θ
m
)
f\left(\theta_m\right)
f(θm) 在
m
m
m 趋于无穷大时收敛到局部最优值或鞍点。由上述构造
f
(
θ
m
+
1
)
≥
g
(
θ
m
+
1
∣
θ
m
)
≥
g
(
θ
m
∣
θ
m
)
=
f
(
θ
m
)
f\left(\theta_{m+1}\right) \geq g\left(\theta_{m+1} \mid \theta_m\right) \geq g\left(\theta_m \mid \theta_m\right)= f\left(\theta_m\right)
f(θm+1)≥g(θm+1∣θm)≥g(θm∣θm)=f(θm)
θ
m
\theta_m
θm 和替代函数相对于目标函数的行进如图所示。 Majorize-Minimization 是相同的过程,但具有要最小化的凸目标。由于我们的重点是使用该算法来求解分位数回归,所以不对MM算法做过多解释。
4.2 分位回归中的MM算法
对于一个
p
p
p维的分位回归问题,我们需要最小化以下损失函数:
L
(
θ
)
=
∑
i
=
1
n
ρ
q
[
y
i
−
f
i
(
θ
)
]
L(\theta)=\sum_{i=1}^n\rho_q[y_i-f_i(\theta)]
L(θ)=i=1∑nρq[yi−fi(θ)]
为了简化记号,将第
i
i
i个残差定义为
r
i
(
θ
)
=
y
i
−
f
i
(
θ
)
r_i(\theta)=y_i-f_i(\theta)
ri(θ)=yi−fi(θ),通常记为
r
i
r_i
ri而忽略参数
θ
\theta
θ, 另外
x
i
x_i
xi是协变量
X
n
×
p
X_{n\times p}
Xn×p的第
i
i
i行,这样:
f
i
θ
)
=
x
i
θ
f_i\theta)=x_i\theta
fiθ)=xiθ. 需要假定每个
f
i
(
θ
)
:
R
p
→
R
f_i(\theta):R^{p}\to R
fi(θ):Rp→R拥有连续导数
d
f
i
(
θ
)
df_i(\theta)
dfi(θ), 我们的目标是用更简化的函数来逼近
ρ
q
(
r
)
\rho_q(r)
ρq(r),为此定义
ϵ
>
0
\epsilon>0
ϵ>0:
ρ
q
ϵ
(
r
)
=
ρ
q
(
r
)
−
ϵ
2
(
ln
ϵ
+
∣
r
∣
)
\rho_q^{\epsilon}(r)=\rho_q(r)-\frac{\epsilon}{2}(\ln{\epsilon+|r|})
ρqϵ(r)=ρq(r)−2ϵ(lnϵ+∣r∣)
逐项求和
L
ϵ
(
θ
)
=
∑
i
=
1
n
ρ
q
ϵ
(
r
i
)
L_{\epsilon}(\theta)=\sum_{i=1}^n\rho_{q}^{\epsilon}(r_i)
Lϵ(θ)=i=1∑nρqϵ(ri)
用上式来逼近
L
(
θ
)
L(\theta)
L(θ), 这表明对于给定第
k
k
k次迭代的残差
r
k
=
r
(
θ
k
)
r^{k}=r(\theta^k)
rk=r(θk),
ρ
q
ϵ
(
r
)
\rho_q^{\epsilon}(r)
ρqϵ(r)由以下二次函数来优化
ζ
q
ϵ
(
r
∣
r
k
)
=
1
4
[
(
r
)
2
ϵ
+
∣
r
k
∣
+
(
4
q
−
2
)
r
+
c
]
\zeta_{q}^{\epsilon}\left(r \mid r^{k}\right)=\frac{1}{4}\left[\frac{(r)^{2}}{\epsilon+\left|r^{k}\right|}+(4 q-2) r+c\right]
ζqϵ(r∣rk)=41[ϵ+∣rk∣(r)2+(4q−2)r+c]
c
c
c是一个常数使得
ζ
q
ϵ
(
r
k
∣
r
k
)
=
ρ
q
ϵ
(
r
k
)
\zeta_q^{\epsilon}(r^k|r^k)=\rho_q^{\epsilon}(r^k)
ζqϵ(rk∣rk)=ρqϵ(rk). 有了简化后的优化函数,MM算法的目标就变成了最小化这个相对简单的函数
Q
ϵ
(
θ
∣
θ
k
)
=
∑
i
=
1
n
ζ
q
ϵ
(
r
i
∣
r
i
k
)
Q_{\epsilon}\left(\theta \mid \theta^{k}\right)=\sum_{i=1}^{n} \zeta_{q}^{\epsilon}\left(r_{i} \mid r_{i}^{k}\right)
Qϵ(θ∣θk)=i=1∑nζqϵ(ri∣rik)
虽然我们目前研究的是线性分位数回归,但实际情况中
f
i
(
θ
)
f_i(\theta)
fi(θ)很难保证是线性的,对于线性的情况,最小化这个目标函数可以使用牛顿法,但是牛顿法需要Hessian矩阵正定,另一方面,
f
i
(
θ
)
f_i(\theta)
fi(θ)的二阶导数计算起来非常麻烦,而且一旦
f
i
(
θ
)
f_i(\theta)
fi(θ)非线性就无法计算了,所以采取了Gauss-Newton迭代(可以处理非线性回归,但只能处理二次函数,而目标函数又刚好是二次的,相比较牛顿法又抛弃了二阶导数项,所以好计算)
一阶导数
d
Q
ϵ
(
θ
∣
θ
k
)
d
θ
=
1
2
∑
i
=
1
n
[
r
i
ϵ
+
∣
r
r
k
∣
+
2
q
−
1
]
d
r
i
(
θ
)
=
1
2
v
ϵ
(
θ
)
d
f
(
θ
)
\begin{aligned} \frac{dQ_{\epsilon}(\theta|\theta^k)}{d\theta}&=\frac{1}{2}\sum_{i=1}^n\left[\frac{r_i}{\epsilon+|r_r^k|}+2q-1\right]dr_i(\theta) \\ &=\frac{1}{2}v_{\epsilon}(\theta)df(\theta) \end{aligned}
dθdQϵ(θ∣θk)=21i=1∑n[ϵ+∣rrk∣ri+2q−1]dri(θ)=21vϵ(θ)df(θ)
其中
v
ϵ
(
θ
)
=
(
1
−
2
q
−
r
1
(
θ
)
ϵ
+
∣
r
1
(
θ
)
∣
,
…
,
1
−
2
q
−
r
n
(
θ
)
ϵ
+
∣
r
n
(
θ
)
∣
)
v_{\epsilon}(\theta)=\left(1-2 q-\frac{r_{1}(\theta)}{\epsilon+\left|r_{1}(\theta)\right|}, \ldots, 1-2 q-\frac{r_{n}(\theta)}{\epsilon+\left|r_{n}(\theta)\right|}\right)
vϵ(θ)=(1−2q−ϵ+∣r1(θ)∣r1(θ),…,1−2q−ϵ+∣rn(θ)∣rn(θ))
二阶导数
d
2
Q
ϵ
(
θ
∣
θ
k
)
d
θ
2
≈
1
2
∑
i
=
1
n
1
ϵ
+
∣
r
i
k
∣
d
r
i
(
θ
)
⊤
d
r
i
(
θ
)
\begin{aligned} \frac{d^2Q_{\epsilon}(\theta|\theta^k)}{d\theta^2}&\approx\frac{1}{2}\sum_{i=1}^n\frac{1}{\epsilon+|r_i^k|}dr_i(\theta)^{\top}dr_i(\theta) \end{aligned}
dθ2d2Qϵ(θ∣θk)≈21i=1∑nϵ+∣rik∣1dri(θ)⊤dri(θ)
由于
d
r
i
(
θ
)
=
−
d
f
i
(
θ
)
dr_i(\theta)=-df_i(\theta)
dri(θ)=−dfi(θ)所以当
f
i
(
θ
)
f_i(\theta)
fi(θ)是线性的时候这个逼近是精确的。可以将上式改写为更简便的形式:
d
2
Q
ϵ
(
θ
∣
θ
k
)
≈
1
2
d
f
(
θ
)
t
W
ϵ
(
θ
k
)
d
f
(
θ
)
d^{2} Q_{\epsilon}\left(\theta \mid \theta^{k}\right) \approx \frac{1}{2} d f(\theta)^{t} W_{\epsilon}\left(\theta^{k}\right) d f(\theta)
d2Qϵ(θ∣θk)≈21df(θ)tWϵ(θk)df(θ)
这个时候GN迭代的方向就是
Δ
ϵ
k
=
−
[
d
f
(
θ
k
)
t
W
ϵ
(
θ
k
)
d
f
(
θ
k
)
]
−
1
d
f
(
θ
k
)
t
v
ϵ
(
θ
k
)
t
\Delta_{\epsilon}^{k}=-\left[d f\left(\theta^{k}\right)^{t} W_{\epsilon}\left(\theta^{k}\right) d f\left(\theta^{k}\right)\right]^{-1} d f\left(\theta^{k}\right)^{t} v_{\epsilon}\left(\theta^{k}\right)^{t}
Δϵk=−[df(θk)tWϵ(θk)df(θk)]−1df(θk)tvϵ(θk)t
其实这个形式在一维的时候就是:
β
k
+
1
=
β
k
−
f
′
(
x
)
f
′
′
(
x
)
\beta^{k+1} = \beta^{k}-\frac{f'(x)}{f''(x)}
βk+1=βk−f′′(x)f′(x)
特别的,当进行线性回归的时候
f
i
(
θ
)
=
x
i
θ
f_i(\theta)=x_i\theta
fi(θ)=xiθ,
d
f
(
θ
)
=
X
df(\theta)=X
df(θ)=X,此时迭代公式
θ
k
+
1
=
θ
k
+
Δ
ϵ
k
\theta^{k+1}=\theta^k+\Delta_{\epsilon}^k
θk+1=θk+Δϵk就是求解
d
Q
ϵ
(
θ
∣
θ
k
)
=
0
dQ_\epsilon(\theta|\theta^k)=0
dQϵ(θ∣θk)=0.
4.3 Python实现
还是使用相同的数据集和设定
data = pd.read_csv("//JOHNWICK/Users/beida/Desktop/sc/rent.csv")
n = len(data); p = 1
x = np.array(data[["cons", 'area']])
y = np.array(data["rent_euro"], dtype=np.float64)
beta = np.array([100, 2.6])
n = x.shape[0]
p = x.shape[1]
xt = x.T
iteration = 1
product = np.ones((p, n))
tau = 0.5
error = 10000
epsilon = 0.9999
maxit = 100
toler = 1e-3
while (iteration <= maxit) & (error > toler):
betaold = beta
r = y - x.dot(beta)
v = 1 - 2*tau - r / (np.abs(r)+epsilon)
w = 1/(epsilon+np.abs(r))
for i in range(0, n):
product[:,i] = xt[:,i]*w[i]
delta = np.linalg.solve(product.dot(x), xt.dot(v))
beta = beta - delta
iteration += 1
error = np.sum(np.abs(delta))
beta
结果
> array([160.3660159 , 4.19819691])
结果对比
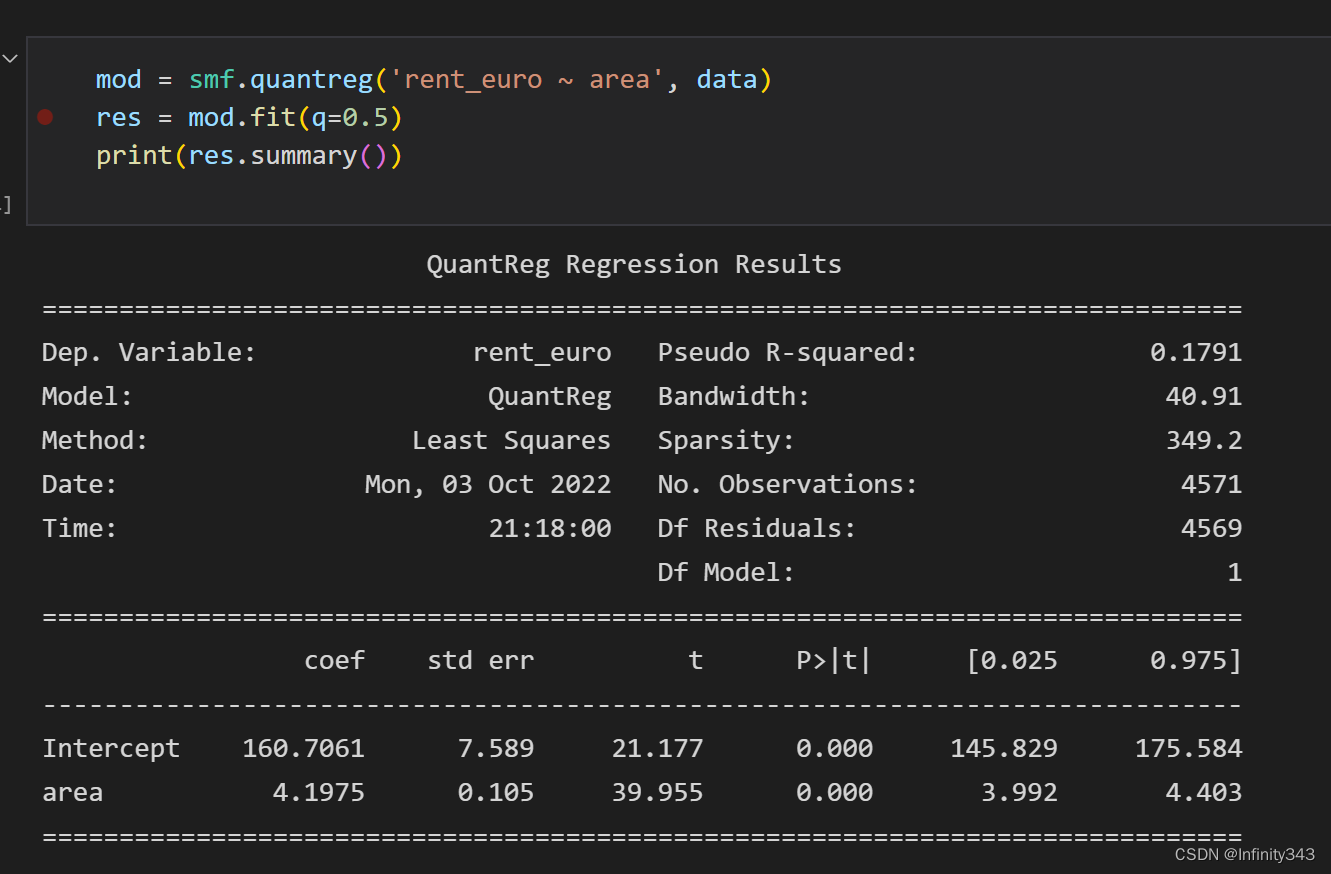
可以看到估计结果仅在截距项上存在着细微的差距。
参考文献
- [1] Hunter, D. R., & Lange, K. (2004). A tutorial on MM algorithms. The American Statistician, 58(1), 30-37.
- [2] Hunter, D. R., & Lange, K. (2000). Quantile regression via an MM algorithm. Journal of Computational and Graphical Statistics, 9(1), 60-77.
- [3] Lange, K., Chambers, J., & Eddy, W. (1999). Numerical analysis for statisticians (Vol. 2). New York: Springer.
5 ADMM算法
交替方向乘子法(Alternating Direction Method of Multipliers, ADMM)。由于该算法的内容较多且稍微复杂一些(需要一些凸优化方面的数学基础知识),所以我们直接介绍如何使用该算法来求解QR
5.1 求解LAD
对于LAD问题,我们之前已经证明了它可以写为一个线性规划的形式
m
i
n
i
m
i
z
e
∣
∣
z
∣
∣
1
s
.
t
.
A
x
−
b
=
z
\mathrm{minimize} ||z||_1\\ s.t.\quad Ax-b=z
minimize∣∣z∣∣1s.t.Ax−b=z
将上述规划写为增广拉格朗日形式(Augmented Lagrangian form):
L
(
x
,
y
,
z
)
=
∥
z
∥
1
+
y
T
(
A
x
−
b
−
z
)
+
ρ
/
2
∥
A
x
−
b
−
z
∥
2
2
L(x, y, z)=\|z\|_1+y^T(A x-b-z)+\rho / 2\|A x-b-z\|_2^2
L(x,y,z)=∥z∥1+yT(Ax−b−z)+ρ/2∥Ax−b−z∥22
将
y
y
y组合到
l
2
l_2
l2正则项中
L
(
x
,
y
,
z
)
=
∥
z
∥
1
+
ρ
/
2
∥
A
x
−
b
−
z
+
(
y
/
ρ
)
∥
2
2
L(x, y, z)=\|z\|_1+\rho / 2\|A x-b-z+(y / \rho)\|_2^2
L(x,y,z)=∥z∥1+ρ/2∥Ax−b−z+(y/ρ)∥22
用
u
u
u 来替换
y
/
ρ
y / \rho
y/ρ
L
(
x
,
y
,
z
)
=
∥
z
∥
1
+
ρ
/
2
∥
A
x
−
b
−
z
+
u
∥
2
2
L(x, y, z)=\|z\|_1+\rho / 2\|A x-b-z+u\|_2^2
L(x,y,z)=∥z∥1+ρ/2∥Ax−b−z+u∥22
为了更新
x
x
x,我们假定
z
k
z^k
zk和
u
k
u^k
uk已知
x
k
+
1
=
arg
min
x
L
p
(
x
,
z
k
,
u
k
)
x
k
+
1
=
arg
min
1
/
2
x
∥
A
x
−
b
−
z
k
+
u
k
∥
2
2
x^{k+1}=\underset{x}{\arg \min } L_p\left(x, z^k, u^k\right) \\ x^{k+1}=\underset{x}{\arg \min 1 / 2}\left\|A x-b-z^k+u^k\right\|_2^2 \\
xk+1=xargminLp(x,zk,uk)xk+1=xargmin1/2
Ax−b−zk+uk
22
计算一阶偏导数并令其等于零,来获得
x
(
k
+
1
)
x^{(k+1)}
x(k+1)
δ
L
(
x
k
+
1
,
z
,
u
k
)
δ
z
=
2
A
T
(
A
x
−
b
−
z
k
−
u
k
)
=
0
x
k
+
1
=
(
A
T
A
)
−
1
A
T
(
b
+
z
k
−
u
k
)
\begin{aligned} &\frac{\delta L\left(x^{k+1}, z, u^k\right)}{\delta z}=2 A^T\left(A x-b-z^k-u^k\right)=\mathbf{0} \\ &x^{k+1}=\left(A^T A\right)^{-1} A^T\left(b+z^k-u^k\right) \end{aligned}
δzδL(xk+1,z,uk)=2AT(Ax−b−zk−uk)=0xk+1=(ATA)−1AT(b+zk−uk)
类似的也可以更新
z
z
z
z
k
+
1
=
arg
min
z
L
p
(
x
k
+
1
,
z
,
u
k
)
z^{k+1}=\arg \min _z L_p\left(x^{k+1}, z, u^k\right)
zk+1=argzminLp(xk+1,z,uk)
考虑和
z
z
z相关的项
z
k
+
1
=
arg
min
z
∥
z
∥
1
+
(
ρ
/
2
)
∥
A
x
k
+
1
−
b
−
z
+
u
k
∥
2
2
z^{k+1}=\underset{z}{\arg \min }\|z\|_1+(\rho / 2)\left\|A x^{k+1}-b-z+u^k\right\|_2^2
zk+1=zargmin∥z∥1+(ρ/2)
Axk+1−b−z+uk
22
将
ρ
\rho
ρ带入公分母常数,进行一下变换
z
k
+
1
=
arg
min
z
∥
z
∥
1
+
(
1
/
(
2
/
ρ
)
)
∥
A
x
k
+
1
−
b
−
z
+
u
k
∥
2
2
z^{k+1}=\underset{z}{\arg \min }\|z\|_1+(1 /(2 / \rho))\left\|A x^{k+1}-b-z+u^k\right\|_2^2
zk+1=zargmin∥z∥1+(1/(2/ρ))
Axk+1−b−z+uk
22
考虑变量
v
v
v上的近端算子,其中某个常数 α 定义为,
prox
f
(
v
)
=
arg
min
(
f
(
x
)
+
1
/
2
α
∥
x
−
v
∥
2
2
)
≡
S
α
(
v
)
\operatorname{prox}_f(v)=\arg \min \left(f(x)+1 / 2 \alpha\|x-v\|_2^2\right) \equiv S_\alpha(v)
proxf(v)=argmin(f(x)+1/2α∥x−v∥22)≡Sα(v)
这样
z
(
k
+
1
)
\mathrm{z}^{(k+1)}
z(k+1)就有一个更加紧凑的形式
z
k
+
1
=
S
(
1
/
ρ
)
(
A
x
k
+
1
−
b
+
u
k
)
z^{k+1}=S_{(1 / \rho)}\left(A x^{k+1}-b+u^k\right)
zk+1=S(1/ρ)(Axk+1−b+uk)
由于
x
(
k
+
1
)
x^{(k+1)}
x(k+1)和
z
(
k
+
1
)
z^{(k+1)}
z(k+1)都有了,这样就可以更新
u
u
u
u
k
+
1
=
u
k
+
(
A
x
k
+
1
−
b
−
z
k
+
1
)
u^{k+1}=u^k+\left(A x^{k+1}-b-z^{k+1}\right)
uk+1=uk+(Axk+1−b−zk+1)
综上所述
x
k
+
1
=
(
A
T
A
)
−
1
A
T
(
b
+
z
k
−
u
k
)
z
k
+
1
=
S
(
1
/
ρ
)
(
A
x
k
+
1
−
b
+
u
k
)
u
k
+
1
=
u
k
+
(
A
x
k
+
1
−
b
−
z
k
+
1
)
\begin{aligned} x^{k+1}=\left(A^T A\right)^{-1} A^T\left(b+z^k-u^k\right)\\ z^{k+1}=S_{(1 / \rho)}\left(A x^{k+1}-b+u^k\right)\\ u^{k+1}=u^k+\left(A x^{k+1}-b-z^{k+1}\right)\\ \end{aligned}
xk+1=(ATA)−1AT(b+zk−uk)zk+1=S(1/ρ)(Axk+1−b+uk)uk+1=uk+(Axk+1−b−zk+1)
5.2 Python实现
还是相同的设定
data = pd.read_csv(r"D:\Desktop\RUC\第一学期\课程\统计计算\rent.csv")
n = len(data); p = 1
x = np.array(data[["cons", 'area']])
y = np.array(data["rent_euro"], dtype=np.float64)
#beta = np.matrix([100, 2.6]).reshape(p, 1)
A = xx # A is data
m, n = xx.shape
b = y
rho = 1
iteration = 1
maxit = 5000
x = np.zeros(n)
z = np.zeros(m)
u = np.zeros(m)
P = np.linalg.inv(A.T.dot(A)).dot(A.T)
tau = 0.9
toler = 1e-5
error = 10000
def shrinkage(x, kappa):
z = np.maximum(0, x - kappa) - np.maximum(0, -x - kappa)
w = np.multiply((1+np.sign(x - kappa))/2, (x - kappa)) - \
np.multiply((1+np.sign(-x - kappa))/2, (-u - v))
return z
# P = (A'A)^-1A'
while (iteration <= maxit) & (error > toler):
xold = x
x = P.dot(b + z - u)
e = A.dot(x)
# b is y, e is Ax, u is m×1 matrix
z = shrinkage(x=(e - b + u/rho + (2*tau - 1)/rho), kappa=(1/rho))
u = u + (e - z - b)
error = np.sum(np.abs(x - xold))
iteration += 1
x
> array([121.83857468, 7.86501805])
还是与rq函数进行比较
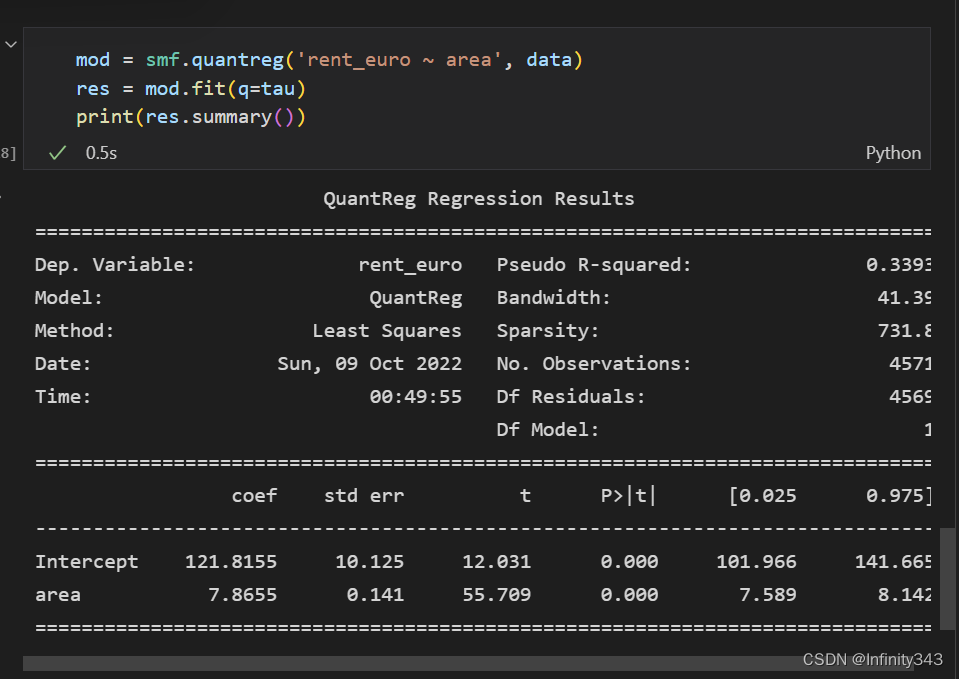
在我们提高了精度后结果基本一致。
参考文献
- Boyd, S., Parikh, N., Chu, E., Peleato, B., & Eckstein, J. (2011). Distributed optimization and statistical learning via the alternating direction method of multipliers. Foundations and Trends® in Machine learning, 3(1), 1-122.
- tip: Boyd是来自斯坦福大学的教授,是ADMM这方面的大佬


















 942
942

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











