







最近在学习Michael Bowles著的《Python 机器学习预测分析核心算法》,记录一下学习过程。
1.关于预测的两类核心算法
解决函数逼近问题的两类算法为:惩罚线性回归和集成方法。
1.1 什么是惩罚回归方法
惩罚线性回归方法是由普通最小二乘法衍生出来的。最小二乘法的一个根本问题就是有时它会过拟合。
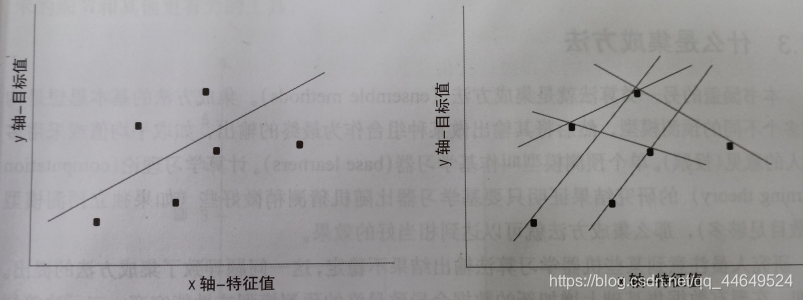
如上图左图,这是一个由6个点的数据集,通过普通最小二乘法拟合出的直线。如课本的假设,目标值为工资,特征值为男人的身高。那么这条直线就代表了对男人收入的最佳预测。
但是如果我们无法获取全部的点,假设只能获取六个点中的任意两个点,那么拟合出来的直线就取决于我们得到的两个点,如右图。
直线的自由度为2,而很明显,对在自由度与点数相同的情况下所做的预测并不能报以太大的信心。然而在很多时候点数甚至是小于自由度的,在这种情况下,惩罚线性回归就是最佳的选择了。
惩罚线性回归可以减少自由度使之与数据规模、问题的复杂度相匹配。尤其是在面对类似于基因问题或者是文本分类问题的时候,更是得到大量的使用。
1.2 什么是集成方法
集成方法的基本思想是构建多个不同的预测模型,然后将其输出做某种组合,如取平均值或采用多数人的意见(投票)。单个预测模型叫做基学习器。计算学习理论的研究结果证明只要基学习器比随机猜测稍微好些,集成方法就可以得到相当好的效果。
集成方法为了实现最广泛的应用通常将二元决策树作为它的基学习器。二元决策树通常如下图所示。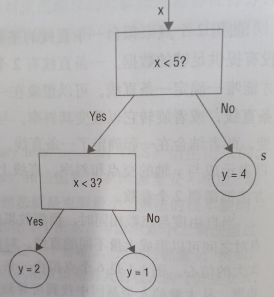
关于比较值和输出值,都是来自己基于输入数据的二元决策树的训练。给定输入数据的话,这些值都会是很确定的。
一种获得不同模型的方法是先对训练数据随机取样,然后基于这些随机数据自己进行训练,这种技术叫做投票(自举集成算法)。
1.4 算法的选择
线性模型倾向于训练速度快,并且经常能够提供与非线性集成方法相当的性能,特别是当能获取的数据受限时。因为训练时间短,在早期特征选取阶段训练线性模型是很方便的,然后可以大致估计针对特定问题可以达到的性能。
集成方法通常能提供更好的性能,也可以提供相对间接的关于结果的贡献的评估。















 638
638











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









