







文章目录
一.商业理解
1.1 商业背景
在国内航空行业竞争日益激烈的情形下,获得一个新客户所付出的成本远远大于挽留一个老客户,因为获得一个新客户需要在宣传、项目、建立客户资料及维持客户关系方面耗费巨大的人力物力,而挽留一个老客户只需在维持客户关系方面提高他的忠诚度即可,所以留住一名现有客户比吸引一名新客户更具有价值,因此老客户的流失给公司带来的损失是非常巨大的。而客户为航空公司带来的利润主要是根据客户的生命周期决定的,客户的生命周期越长,给公司带来的利润就会越多,所以如何延长流失的客户的生命周期就成为了航空公司占领市场份额的决定性策略。然而,延长流失客户的生命周期的前提是航空公司能准确地预测即将流失的客户,因此分析客户的流失显得非常必要,根据分析得出航空公司客户流失的一些规则,基于流失客户的一些共同特征,航空公司可以据此提出相应对策和改进措施来保留客户和预防潜在客户流失,进而提高航空公司竞争力。
1.2 商业目标
对可能流失的高价值的客户做出相应的措施,帮助营销部门确定客户挽留市场活动的目标客户群体以及合适的营销方案,以延长生命周期,提高航空公司的上座率,增加公司收益。分成以下分目标:
- 预测那些用户可能会流失?
- 可能流失的客户特征是什么?
- 市场挽留活动的预计收益?
1.3 工具与技术的评估
开发工具:Mysql、Excel、SPPS Modeler、Python(Scipy、SK-learn)
应用Excel的筛选、频率图对数据的分布状况、是否缺少进行了解,并使用SPPS Modeler进行快速的数据处理和初步的数据探索性分析,并把最终数据集导入到Mysql数据库中,接着使用Python机器学习与matplotlib视图化方式,进行一步的探索与挖掘数据统计规律。
二、数据理解及数据准备
2.1 数据理解
数据集测量的时间窗口为某航空公司连续两年的运营数据,共有62986条会员数据个案,每个个案有56个变量,包括客户基本信息(例如:会员卡号、年龄、性别等),客户乘坐记录(例如:总乘坐次数、总飞行次数、总积分等)以及一个流失标记变量(流失记为1,未流失记为0)。
2.2 数据清洗及数据构建
利用Excel筛选、频率分布以及SPSS Modeler数据审核,确定缺失数据的变量,根据数据缺失占比以及对目标的影响程度,选择丢弃或填充;回绕业务目标,衍生反应客户行为的统计类指标,流程如下(图 2-1):
- 性别、年龄,第1第2年总票价缺失较少,对流失目标影响较小,选择丢弃处理;
- 衍生总票价以两年票价求和,作为衡量客户价值指标;

2.3 数据探索性分析
2.3.1 离散变量的探索性分析
(1)会员等级与流失标志

分析:从图2-3可知,会员等级4客户人数最多,达到了92.17%,同时也是流失人数比例最高,相对于会员等级5、6恰好相反,特别会员等级5流失率最低,形成向中间等级流失率低的趋势,可以适当调整会员等级的划分,特别是提高有价值的会员等级4客户。
(2)客户性别与流失标志

分析:从图 2-4可知,主要客户群体为男性客户,占到了四分之三,女性客户相对较少,并且流失比例也是最高的,反应了航空公司对女性客户的服务可能存在不足,建议航空公司推出一些关爱女性的活动,以吸引女性客户,提高女性客户的忠诚度和满意度。
2.3.2 连续变量的探索性分析

分析:统计指标中的平均乘机时间间隔、入会时长、总票价、观测窗口总基本积分、观测窗口总飞行公里数、飞行次数等,总的流失趋势为上述指标取值越小,流失的可能性就越高。
三、建立模型
3.1 建模前的特征选择
特征集数量较多,并且目标变量为离散型变量,因此选择的树模型和随机稀释模型为分类类型的,并运用集合(Set)交集运算,SelectFromModel模块确定特征,如图 3-1。

代码如下:
'''去除方差小的特征'''
from sklearn.feature_selection import VarianceThreshold
'''RFE_CV'''
from sklearn.ensemble import ExtraTreesClassifier
'''随机稀疏模型'''
from sklearn.linear_model import RandomizedLogisticRegression
'''特征选择'''
from sklearn.feature_selection import SelectFromModel
class FeatureSelection(object):
def __init__(self,DataFrame):
self.train_test=DataFrame.drop(['会员卡号','流失标志'],axis=1) # features #
self.label =DataFrame['流失标志'] # target #
self.feature_name = list(self.train_test.columns) # feature name #
def variance_threshold(self): #方差选择
sel = VarianceThreshold(threshold=(.8 * (1 - .8)))
feature_num=sel.fit_transform(self.train_test,self.label).shape[1]
feature_var = list(sel.variances_) # feature variance #
features = dict(zip(self.feature_name, feature_var))
features = list(dict(sorted(features.items(), key=lambda d: d[1])).keys())[-feature_num:]
return set(features) # return set type #
def tree_select(self): #树模型选择
clf = ExtraTreesClassifier(n_estimators=300, max_depth=7, n_jobs=4).fit(self.train_test,self.label)
model= SelectFromModel(clf, prefit=True) #feature select#
feature_num= model.transform(self.train_test).shape[1]
feature_var = list(clf.feature_importances_) # feature scores #
features = dict(zip(self.feature_name, feature_var))
features = list(dict(sorted(features.items(), key=lambda d: d[1])).keys())[-feature_num:]
return set(features) # return set type #
def rlr_select(self): #随机稀释模型选择
clf = RandomizedLogisticRegression()
feature_num= clf.fit_transform(self.train_test,self.label).shape[1]
feature_var = list(clf.scores_) # feature scores #
features = dict(zip(self.feature_name, feature_var))
features = list(dict(sorted(features.items(), key=lambda d: d[1])).keys())[-feature_num:]
return set(features) # return set type #
def return_feature_set(self, variance_threshold=False,tree_select=False,rlr_select=False):
names = set([])
if variance_threshold is True:
name_one = self.variance_threshold()
names = names.union(name_one)
if tree_select is True:
name_two = self.tree_select()
names = names.intersection(name_two)
if rlr_select is True:
name_three = self.rlr_select()
names = names.intersection(name_three)
return list(names)
3.2 聚类分析 – 刻画用户流失特征
3.2.1 初步聚类
根据业务目标,划分为低中高流失率的客户聚体,确定聚类数为3,选择衡量客户价值的“会员卡级别、总票价,总累计积分”等指标,对客户群体进行聚类。
代码如下:
from sklearn.cluster import KMeans
new_df = df
feature = new_df[['会员卡级别','总票价','总累计积分']]
#初步聚类
kmean = KMeans(n_clusters=3, random_state=10).fit(feature)
new_df['jllable'] = kmean.labels_
#绘制图表比较
Mean = feature.groupby(kmean.labels_).mean()
figsize=11,12
index=Mean.index
colors=['r','y','b']
fig,ax=plt.subplots(nrows=3,ncols=1,figsize=figsize,facecolor='w',edgecolor='blue',sharex=True, sharey='row') #返回figure、axes对象
#会员卡级别
ax[0].bar(index,Mean['会员卡级别'],color=colors)
ax[0].set_title('会员卡级别',fontstyle='italic',fontsize=12)
for x,y in zip(index,Mean['会员卡级别']):
ax[0].text(x,y,'%.2f'%y,ha='center',va='bottom',fontsize=12)
#总票价
ax[1].bar(index,Mean['总票价'],color=colors)
ax[1].set_title('总票价',fontstyle='italic',fontsize=12)
for x,y in zip(index,Mean['总票价']):
ax[1].text(x,y,'%.2f'%y,ha='center',va='bottom',fontsize=12)
#总积分
ax[2].bar(index,Mean['总累计积分'],color=colors)
ax[2].set_title('总累计积分',fontstyle='italic',fontsize=12)
for x,y in zip(index,Mean['总累计积分']):
ax[2].text(x,y,'%.2f'%y,ha='center',va='bottom',fontsize=12)
plt.xticks(index,['聚类0','聚类1','聚类2'],fontsize=16)
plt.gcf().savefig('Cluster_select.png')
plt.show()
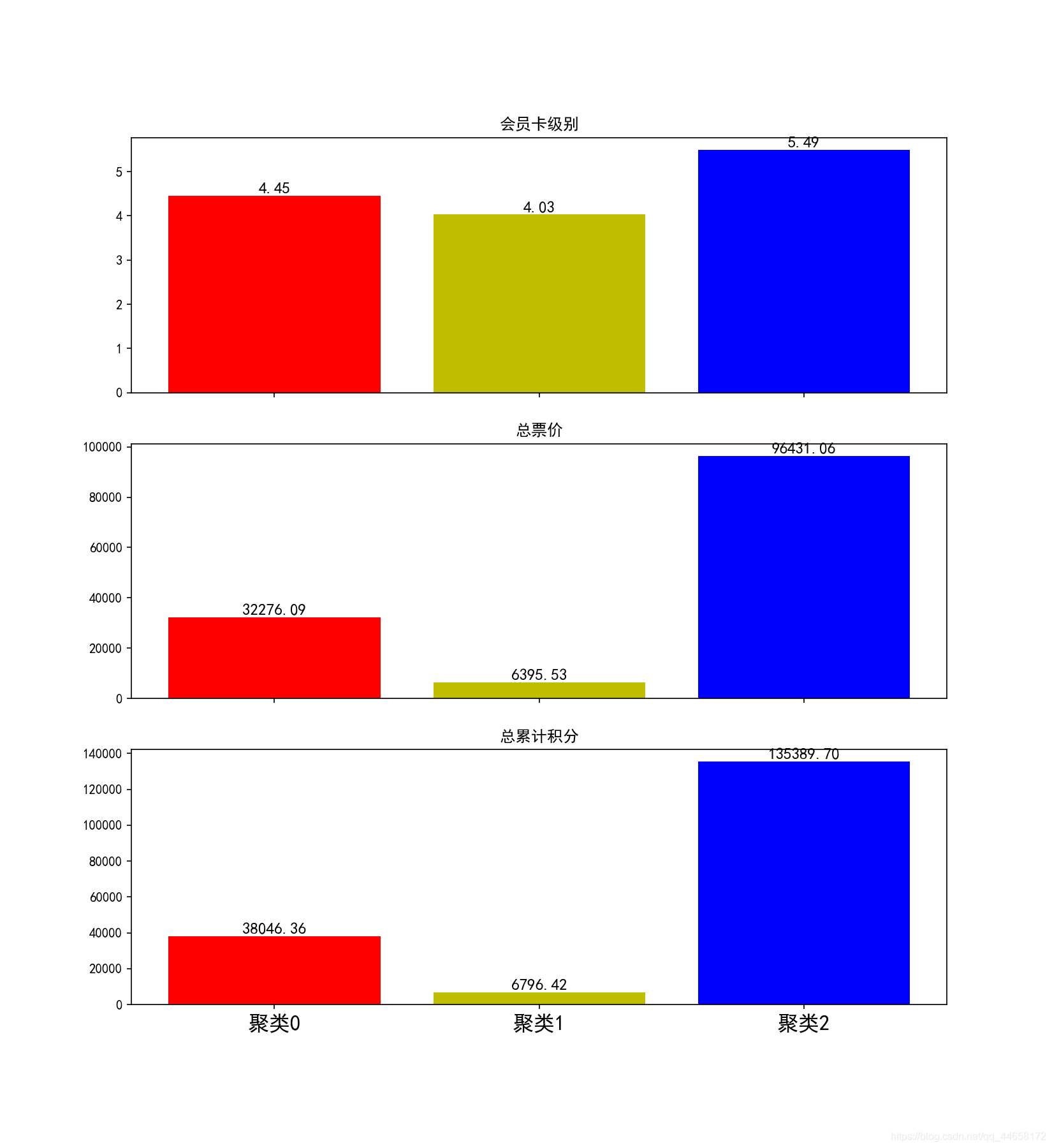
分析:从图中可知,会员等级、总票价、总累计积分最高的为聚类2,确定为高价值客户聚体,对其进行进一步分析。
3.2.2 进一步聚类
本次聚类选择高价客户(聚类2),根据经验法则,选取聚类数返回从2到8,使用 Calinski-Harabasz分数值确定最佳聚类数,为了获得更多的用户特征,在特征选择上只进行方差形式的特征筛选。
代码如下:
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
import pandas as pd
import numpy as np
from sklearn import metrics
import matplotlib.pyplot as plt
class Cluster(object):
##定义全局属性##
__Colors=['r','y','b','c','m','g','k','w'] #颜色
__Markers=['+','s','*','^','x','o','v','x'] #标记
__kmean_df=None #聚类结果
__k=None #聚类数
def __init__(self,DataFrame,min_k=3,max_k=9): ## 1.初始化建立聚类##
##特征选择及数据准备
new_order = np.random.permutation(len(DataFrame))
new_df = DataFrame.take(new_order)
f = FeatureSelection(new_df)
feature_names = f.return_feature_set(variance_threshold=True,tree_select=True)
feature = new_df[feature_names]
#K均值聚类
Kmeans=[]
for k in range(min_k,max_k):
kmean = KMeans(n_clusters=k, random_state=10).fit(feature)
Kmeans.append((k,metrics.calinski_harabaz_score(feature,kmean.labels_),kmean))
Best_kmean=sorted(Kmeans,key=lambda d: d[1])[-1] #选择最好聚类
feature['jllable']=Best_kmean[-1].labels_
feature['流失标志']=new_df['流失标志']
self.__k = Best_kmean[0]
self.__kmean_df = feature
self.Cluster_assess(Kmeans) #输出效果
print('分成了%s个聚类!'%self.__k)
def Cluster_assess(self,Kmeans): ## 2.1聚类效果评价##
plt.figure(figsize=(13,5))
plt.subplot(1,2,1)
plt.title('Calinski-Harabasz分数值评估')
plt.xlabel('K')
plt.ylabel('Scores')
plt.plot(np.array(Kmeans)[:,0],np.array(Kmeans)[:,1])
plt.subplot(1,2,2)
feature=self.__kmean_df.drop(['流失标志','jllable'],axis=1)
pca = PCA(n_components=2)
new_pca = pd.DataFrame(pca.fit_transform(feature))
plt.title('聚类效果分布散点图降维(二维)')
for i in range(self.__k):
d = new_pca[self.__kmean_df['jllable']==i]
plt.plot(d[0], d[1], self.__Colors[i]+self.__Markers[i])
plt.legend(np.char.add('聚类',list(map(str,range(self.__k)))))
plt.gcf().savefig('Cluster_assess.png')
plt.show()
def Cluster_rate(self): ## 3.1聚类流失率分析##
plt.figure(figsize=(13,5))
Ser_count_type=self.__kmean_df['jllable'].value_counts()
Ser_runoff_rate=self.__kmean_df['流失标志'].groupby(self.__kmean_df['jllable']).mean()
df_runoff_rate=pd.concat([Ser_count_type,Ser_runoff_rate],axis=1,keys=['客户数量','流失率'])
labels=np.char.add('聚类',list(map(str,df_runoff_rate.index)))
values_count=df_runoff_rate['客户数量']
values_rate=df_runoff_rate['流失率']
plt.subplot(1,2,1)
plt.title('航空客户数量饼图')
explode=[0]*self.__k
explode[values_rate.idxmax()]=0.3
plt.pie(values_count,labels=labels,colors=self.__Colors[:self.__k],explode=explode,startangle=180,
shadow=True,autopct='%1.2f%%', pctdistance=0.5,textprops = { 'fontsize': 14, 'color': 'k'},
wedgeprops = { 'linewidth': 1.5, 'edgecolor': 'w'})
plt.axis('equal')
plt.subplot(1,2,2)
plt.title('航空客户流失率条形图')
plt.bar(labels,values_rate,color=self.__Colors[:self.__k])
plt.grid(True)
for x,y in zip(labels,values_rate):
plt.text(x,y,'%.3f'%y,ha='center',va='bottom',fontsize=14)
plt.gcf().savefig('Cluster_rate.png')
plt.show()
def Cluster_cmp(self): ##3.2聚类特征变量对比(Z标准化)
new_df=self.__kmean_df.drop(['流失标志','jllable'],axis=1).groupby(self.__kmean_df['jllable']).mean()
result=new_df.copy()
def f(x):
return (x-np.mean(x))/np.std(x)
new_df=new_df.apply(f).T
barh=new_df.plot(kind='barh',figsize=(17,30),fontsize=20,grid=True,color=self.__Colors[:self.__k])
barh.legend(np.char.add('聚类',list(map(str,new_df.columns))),fontsize=16,loc=2)
plt.gcf().savefig('Cluster_cmp.png')
plt.show()
return result

分析:从左图可知,当聚类数为5时, Calinski-Harabasz分数值评估值最高(最佳聚类数),因此最终确定聚类数为3。右图为最佳聚类时所绘制的二维散点图,图中每个聚类都形成了自己的局域块,相对比较集中,可进行下一步分析。
3.2.3 聚类结果分析
(1)聚类流失率

分析:从图中可知,流失率最高的为聚类1,其次是聚类聚类0,与及对应的客户人数成反比,这与实际的高价值低流失率相符合,可进一步比较分析。
(2) 聚类特征变量比较分析





结论:客户流失的最重要特征为“总基本积分少,非(其他)乘机积分高,积分总换次数多”,属于热衷积分的高价值客户,因此,营销活动部门可以根据这一客户特征,提前发现即将流失的客户,采取相应的营销活动挽留客户,以延长客户的使用生命周期,增加航空公司收益。
3.3 决策树分析–获取用户流失规则
3.3.1 确定相关参数及建立决策树
根据数集有50多个特征6万多条数据记录(训练集80%,测试集20%),类别分布有一定的偏倚,类别权重设为平衡,为获得最简易的流失规则,应用全部特征选择,初步确定最大深度为3,最小划分节点样本数为6,数据预排序。
代码如下:
from sklearn import tree
import os
import numpy as np
import pandas as pd
from IPython.display import Image
import pydotplus,math
os.environ["PATH"] += os.pathsep + 'D:\\Program Files (x86)\\Graphviz2.38\\bin'
class Tree(object): ##1.初始化建立决策树
def __init__(self,DataFrame,max_depth=3):
#特征选择
new_order=np.random.permutation(len(DataFrame))
new_df=DataFrame.take(new_order)
f=FeatureSelection(new_df)
self.column_names=f.return_feature_set(variance_threshold=True,tree_select=True,rlr_select=True)
feature=new_df[self.column_names]
target=new_df['流失标志']
#准备训练和测试数据
breakPoint=math.floor(len(feature)*0.2)
feature_Train=feature[:-breakPoint]
target_Train=target[:-breakPoint]
self.feature_Test=feature[-breakPoint:]
self.target_Test=target[-breakPoint:]
#分类决策树
self.clf = tree.DecisionTreeClassifier(max_depth=max_depth,min_samples_split=6,
min_samples_leaf=3,class_weight='balanced',presort=True)
self.clf = self.clf.fit(feature_Train,target_Train)
print('模型准确率为:%2.2f %%'%(self.clf.score(feature_Train,target_Train)*100))
print('决策完成!')
def Tree_assess(self): ##2.模型准确率评价
pre_Test=self.clf.predict(self.feature_Test)
df_result=pd.DataFrame(np.column_stack((pre_Test,np.array(self.target_Test))),
columns=['$C-流失标志','流失标志'])
def a(x):
if x[0]==x[1]:
return 1
else:
return 0
df_result['判断']=df_result.apply(a,axis=1)
preRate=df_result['判断'].groupby(df_result['流失标志']).mean()
preRT=df_result['判断'].mean()
preCount=df_result.groupby([df_result['流失标志'],df_result['判断']]).count()
DT=pd.DataFrame([[preCount['$C-流失标志'][0.0,0],preCount['$C-流失标志'][0.0,1],preRate[0.0]],
[preCount['$C-流失标志'][1.0,0],preCount['$C-流失标志'][1.0,1],preRate[1.0]],
[preCount['$C-流失标志'][0.0,0]+preCount['$C-流失标志'][1.0,0],
preCount['$C-流失标志'][0.0,1]+preCount['$C-流失标志'][1.0,1],preRT]],
columns=['错误数','正确数','准确率'],index=[0,1,'总计']).round(2)
return DT
def Tree_view(self): ##3.1模型结果透视化
transform=pd.read_csv('中英互释.csv',engine='python',index_col='中文名')
dot_data = tree.export_graphviz(self.clf, out_file=None,
feature_names=list(transform['英文名'][self.feature_Test.columns]),
class_names=['0','1'],
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf("TreeView.pdf")
return Image(graph.create_png())
def Tree_feat_import(self): ##3.2特征变量重要性
clf=self.clf
feature_name=self.column_names
feature_var = list(clf.feature_importances_) # feature scores #
features = dict(zip(feature_name, feature_var))
features = dict(sorted(features.items(), key=lambda d: d[1]))
index=list(features.keys())
values=list(features.values())
plt.figure(figsize=(13,7))
plt.title('决策树特征重要性条形图',fontsize=24)
plt.barh(index,values,alpha=0.7)
plt.xlabel('特征重要性',color='gray',fontsize=16)
plt.ylabel('特征变量名',color='gray',fontsize=16)
plt.xticks(fontsize=14)
plt.yticks(fontsize=14)
plt.gcf().savefig('Tree_feature_importances.png')
plt.show()
3.3.2 模型评价
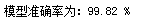

分析:从图可知,对检验数据集,模型的预测准确率达到了98.82%, roc曲线覆盖了整个页面上方,AUR等于1,因此,模型效果不错,可以继续流失规则分析。。
3.3.3 结果分析


分析:从图可知, “最后一次乘机时间至观察窗口末端时长”成为最重要的流失划分因素。
- a) 最后一次乘机时间至观察窗口末端时长 > 167.5 并且 观察窗口内最大乘机间隔<=200.5 基尼指数(Gini)=0.059
- b) 最后一次乘机时间至观察窗口末端时长 <= 12.5 并且 观察窗口内最大乘机间隔 <=31.5 并且 基尼指数(Gini)=0.17
结论: 营销部门可以根据以上所得的流失规则(特别是“最后一次乘机时间至观察窗口末端时长”是否小于167.5),对客户进行规则匹配,得出流失可能会流失的客户,并对其给予一定的优惠,达到挽回客户,增加收益的目的。
3.4 流失评分–确定挽留目标客户
3.4.1建立流失评分
目标变量为离散型,呈现为非线性模型,树模型具有较好拟合,此次客户流失评分使用分类决策数模型,并通过以下规则转换为1到100的流失评分标准。

代码如下:
from sklearn import tree
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import math
class Score(object):
def __init__(self,DataFrame,max_depth=5): ##1.初始化决策树评分
#特征选择及数据准备
new_order=np.random.permutation(len(DataFrame))
new_df=DataFrame.take(new_order)
f=FeatureSelection(new_df)
column_names=f.return_feature_set(variance_threshold=True,tree_select=True)
feature=new_df[column_names]
target=new_df['流失标志']
#准备训练和测试数据
breakPoint=math.floor(len(feature)*0.2)
feature_Train=feature[:-breakPoint]
target_Train=target[:-breakPoint]
self.feature_Test=feature[-breakPoint:]
self.target_Test=target[-breakPoint:]
Test_df=new_df[-breakPoint:]
#分类决策树
clf = tree.DecisionTreeClassifier(max_depth=max_depth,min_samples_split=6,
min_samples_leaf=3,class_weight='balanced',presort=True)
clf = clf.fit(feature_Train,target_Train)
print('模型准确率为:%2.2f %%'%(clf.score(self.feature_Test,self.target_Test)*100))
def h(x):
if x[0]==0:
return np.round((0.5 - x[1]/2)*100,2)
else:
return np.round((0.5 + x[2]/2)*100,2)
runoff=clf.predict(self.feature_Test)
Arr=np.column_stack((runoff,clf.predict_proba(self.feature_Test)))
sore=np.apply_along_axis(h,axis=1,arr=Arr)
Test_df['$C-流失标志']=runoff
Test_df['$C-流失评分']=sore
self.Score_df=Test_df
print('评分完成!')
def Score_assess(self): ##2.评分效果分析
plt.figure(figsize=(13,5)) # 第一张图
plt.subplot(121) # 第一张子图
plt.title('流失评分直方图',fontsize=16)
pop=self.Score_df['$C-流失评分']
plt.hist(pop,bins=20)
plt.xlabel('计数')
plt.ylabel('评分')
plt.subplot(122) # 第二张子图
new_df=self.Score_df
result=new_df['$C-流失评分']
bins=list(range(0,101,5))
bins[-1]=101
cat=pd.cut(result,bins,right=False)
new_df['划分']=cat
new_Ser=new_df.groupby(['划分','流失标志']).count()['会员卡号']
new_df=new_Ser.unstack()
index=np.arange(1,len(new_df)+1)
Ser1=new_df[0]
Ser2=new_df[1]
plt.axis([0,len(new_df)+1,0,7800])
plt.title('流失评分与实际流失情况',fontsize=16)
plt.bar(index,Ser1,color='b')
plt.bar(index,Ser2,color='r',bottom=Ser1)
plt.legend(['0','1'],title='流失标志',fontsize=12)
plt.xticks(index,list(new_df.index),rotation=90)
plt.xlabel('评分')
plt.ylabel('计数')
plt.gcf().savefig('Score_assess.png')
plt.show()
def Score_marketing(self,dimRspRate=0.7,dtmDiscount=0.8,dtmCost=500): ##3.1营销演绎-生成相关指标
#过滤重命名
columns=['会员卡号','总票价','流失标志','$C-流失评分']
new_df=self.Score_df[columns]
recolumn={'总票价':'客户价值','$C-流失评分':'流失评分'}
new_df=new_df.rename(columns=recolumn)
#排序
new_df
new_df=new_df.sort_index(by='流失评分',ascending=False)
#添加
new_df['目标客户']=(np.arange(1,len(new_df)+1)/len(new_df))*100
new_df['营销活动响应']=np.random.random(len(new_df))<=dimRspRate
lisEarning=[]
lisCost=[]
earning=0
cost=0
for runoff,rsp,value in zip(new_df['流失标志'],new_df['营销活动响应'],new_df['客户价值']):
if runoff==1 and rsp==True:
earning+=value*(1-(1-dtmDiscount))
lisEarning.append(earning)
else:
lisEarning.append(earning)
if value>0:
cost+=dtmCost
lisCost.append(cost)
else:
lisCost.append(cost)
new_df['挽留收益']=np.round(lisEarning,2)
new_df['挽留成本']=np.round(lisCost,2)
new_df['挽留活动净收益']=new_df['挽留收益']-new_df['挽留成本']
lisRSCP=[]
lisNTC=[]
netEarning=-99999
for ne,rs,tc in zip(new_df['挽留活动净收益'],new_df['流失评分'],new_df['目标客户']):
if ne>=netEarning:
lisRSCP.append(rs)
lisNTC.append(tc)
netEarning=ne
else:
lisRSCP.append(lisRSCP[-1])
lisNTC.append(lisNTC[-1])
new_df['流失评分临界点']=lisRSCP
new_df['营销活动目标客户']=lisNTC
self.result_df=new_df
self.Score_View()
self.Score_To_CSV()
print('营销演绎完成!')
return self.result_df
def Score_View(self): ##3.2营销演绎--成本、收益、净收益
new_df=self.result_df
index=new_df['目标客户']
y1=new_df['挽留收益']
y2=new_df['挽留成本']
y3=new_df['挽留活动净收益']
x_point=round(max(new_df['营销活动目标客户']),2)
y_point=round(max(y3),0)
plt.title('挽留收益、成本、净收益折线图',fontsize=14)
plt.xlabel('目标客户')
plt.ylabel('收益,成本,净收益')
plt.plot(index,y1)
plt.plot(index,y2)
plt.plot(index,y3)
plt.legend(['收益','成本','净收益'])
plt.annotate(r'最高点:(%s,%s)'%(x_point,y_point),xy=[x_point,y_point],xycoords='data',
xytext=[20,30],fontsize=12,textcoords='offset points',
arrowprops=dict(arrowstyle="->",connectionstyle='arc3,rad=0.2'))
plt.gcf().savefig('Score_earning.png')
def Score_To_CSV(self): ##3.3营销演绎--导出挽留目标客户
new_df=self.result_df
result_df=new_df[new_df['目标客户']<=max(new_df['营销活动目标客户'])]
result_df=result_df[['会员卡号','流失标志','客户价值','流失评分']]
result_df.to_csv('挽留活动目标客户.csv',index=None,encoding='gbk')
print("导出完成!")
3.4.2 模型评价



分析:从图可知,最佳隐藏层数为7,模型准确率达到了99.0%,再结合得出的评分图,从左图中,未流失率的人数占比最多,流失的人数占比较少,跟实际的航空客户流失情况一致,从右图中,流失评分越低的实际的流失占比越低,流失评分越高的实际的流失占比约高,因此,总体流失评分模型是可以接受的,可进一步分析。
3.4.3 营销演绎
(1)建立
根据挽留活动净收益最大化确定流失评分临界点、营销活动目标客户。默认设置 – 活动响应率=70%;折扣率=80%;成本=500

(3)结果透视化和导出

分析:从图中可知,当营销活动的目标客户从0到41.27时,挽留净收益呈上升趋势,从41.27到100.0呈下降趋势,41.27时营销净收益达到最高值,建议对41.27前的目标流失客户群体,进行挽留活动。
(3)结果导出

结论: 在本次营销演绎中,提供了三个可变的参数,分别为响应比率、营销活动单位成本、折扣,可以供市场营销部门的同事根据市场活动的实际情况进行调整。同时,在输出客户目标时,也提供了每个用户的会员卡号、流失标志、客户价值、流失评分作为市场营销挽留活动的参照指标。
四、结果部署
本次项目遵循数据挖掘方法论—CRISP-DM(跨行业数据挖掘标准流程),对航空客户流失问题进行探索,采用了数据挖掘的聚类,决策数,神经网络等,得出以下分析的结果,对于航空业务具有一定的推动作用。
从初步探索性分析中发现,会员等级划分不合理,会员等级 4的客户占比大且流失率最高,可相应部分高价值的客户;在性别方面,女性客户相对于男性具有较大的流失率,因此应该提高女性客户的服务质量,如关爱女活动等。
从聚类模型中,发现高价值客户中” 总基本积分少,非(其他)乘机积分高,积分总换次数多” — 喜欢积分消费的客户,是用户流失的主要特征;从决策数模型中,发现“最后一次乘机时间至观察窗口末端时长”是否大于167.5,成为匹配用户是否流失主要流失规则。可结合这两个结果,对用户进行流失前及时发现与挽回。
从流失评分营销演绎中,得出了客户的流失评分临界点(利润最大化),以及结合实际情况可调整的响应比率、营销活动单位成本、折扣,最终确定市场营销活动目标客户的名单。

















 2230
2230

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









