







Regularizing generative adversarial networks under limited data
公众号:EDPJ
目录
0. 摘要
近年来见证了生成对抗网络 (GAN) 的快速发展。 然而,GAN 模型的成功取决于大量的训练数据。 这项工作提出了一种正则化方法,用于在有限数据上训练强大的 GAN 模型。 我们在理论上展示了正则化损失与称为 LeCam 散度的 f 散度之间的联系,我们发现它在有限的训练数据下更加稳健。 在几个基准数据集上进行的大量实验表明,所提出的正则化方案 1) 在有限的训练数据下提高了泛化性能并稳定了 GAN 模型的学习动态,以及 2) 补充了最近的数据增强方法。 当只有有限的 ImageNet 基准训练数据可用时,这些属性有助于训练 GAN 模型以实现最先进的性能。
1. 简介

GAN 方法的成功在很大程度上依赖于大量不同的训练数据,这些数据通常需要大量劳动力或收集起来很麻烦。如图 1 所示的 BigGAN 模型示例,在有限的训练数据下,性能显着下降。 因此,最近开发了几种方法来解决数据不足问题。 这个新兴研究方向的一个代表性任务旨在,在只有一小部分 ImageNet 数据 可用于训练时,学习稳健的类条件(class-conditional) GAN 模型。 通常,现有方法利用数据增强(常规或可微分增强)来增加有限训练数据的多样性。 这些数据增强方法在几个标准基准测试中显示出可喜的结果。
在本文中,我们从不同的角度解决了有限数据上的 GAN 训练任务:模型正则化。 尽管文献中有许多针对 GAN 模型的正则化技术,但它们都没有旨在提高在有限数据上训练的 GAN 模型的泛化能力。 相比之下,我们的目标是在有限的训练数据上学习健壮的 GAN 模型,这些模型可以很好地泛化到样本外数据。 为此,我们介绍一种新颖的正则化方案,用于调制鉴别器的预测以学习稳健的 GAN 模型。 具体来说,我们在真实图像的当前预测和跟踪生成图像的历史预测的移动平均变量之间施加 ℓ2 范数,反之亦然。 我们从理论上表明,在适当的假设下,正则化将 WGAN 公式转换为最小化 f-divergence(LeCam-divergence)。 我们发现 LeCam-divergence 在有限的训练数据设置下更加稳健。
我们进行了大量的实验来证明所提出的正则化方案的三个优点。
- 首先,它提高了各种 GAN 方法的泛化性能,例如 BigGAN 和 StyleGAN2。
- 其次,它在有限的训练数据设置下稳定了 GAN 模型的训练动态。
- 最后,我们的正则化方法在经验上与数据增强方法互补。如图 1 所示,我们通过结合我们的正则化(即 R_LC)和数据增强方法,在有限的(例如 10%)ImageNet 数据集上获得了最先进的性能。
2. 相关工作
生成对抗网络。 生成对抗网络 (GAN) 旨在使用对抗学习对目标分布进行建模。
已经提出了各种对抗性损失来稳定训练或提高 GAN 模型的收敛性,主要基于最小化真实数据分布和生成数据分布之间的 f 散度的想法。
- Goodfellow 等人提出了最小化两个分布之间的 JS 散度的饱和损失。
- LSGAN 公式导致最小化 X^2 散度
- EBGAN 方法优化了总变异距离(Total Variation distance)。
另一方面,一些模型旨在最小化积分概率指标 (IPM),例如 WGAN 框架。
在这项工作中,我们设计了一种新的正则化方案,可应用于不同的 GAN 损失函数,以在有限数据上训练 GAN 模型。
在有限的训练数据上学习 GAN。 为了减少数据收集工作量,一些研究提出了对训练 GAN 模型的数据不足的担忧。 在有限的数据上训练 GAN 模型具有挑战性,因为数据稀缺会导致训练动态不稳定、生成图像保真度下降以及记忆训练示例等问题。
为了解决这些问题,最近的方法利用数据增强作为增加数据多样性的手段,从而防止 GAN 模型过度拟合训练数据。
- Zhang 等人增强真实图像并引入一致性损失来训练鉴别器。
- DA 和 ADA 方法有一个相似的想法,即在真实图像和生成的图像上应用可微分(differential)数据增强,其中 ADA 进一步开发了一种自适应策略来调整增强的概率。
与之前的工作相比,我们从模型正则化的不同角度解决了这个问题。 我们表明我们的方法在概念上和经验上是对现有数据增强方法的补充。
GAN 的正则化。 大多数现有的 GAN 模型正则化方法旨在实现两个目标:1)稳定训练以确保收敛,以及 2)减轻模式崩溃问题。
- 由于 GAN 框架以不稳定的训练动态而闻名,因此已经做出了许多努力来解决问题,例如:使用噪声、梯度惩罚、谱归一化、对抗防御等。
- 另一方面,提出了多种正则化方法来缓解模型崩溃问题,从而增加生成图像的多样性。
与这些方法相比,我们的工作有一个不同的目标:提高在有限训练数据上训练的 GAN 模型的泛化能力。
稳健的深度学习。 稳健的深度学习旨在防止深度神经网络过度拟合或记忆训练数据。 最近的方法已成功克服训练数据偏差,例如标签噪声和有偏差的数据分布。 最近,有少量的方法被提出来学习鲁棒的 GAN 模型。 虽然这些方法旨在克服损坏的训练集中的标签或图像噪声,但我们改进了在有限的未损坏训练数据上训练的 GAN 模型的泛化能力。
3. 方法
3.1 生成对抗网络(GAN)
GAN 模型由判别器 D 和生成器 G 组成。令 V_D 和 L_G 分别表示判别器 D 和生成器 G 的训练目标。 GAN框架的训练一般可以表示为:
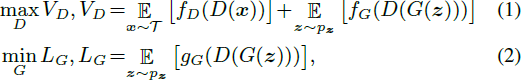
其中 p_z 是先验分布(例如 N(0, I)),T 是用于近似数据分布的训练集。 等式 (2) 中的符号 f_D、f_G 和 g_G,表示可以从中导出各种 GAN 损失的映射函数。
3.2 在有限数据下正则化 GAN
我们的目标是在训练集 T 仅包含有限数量的数据时提高 GAN 模型的性能,如图 1 所示的示例。与现有的数据增强方法不同,我们通过结合鉴别器的正则化解决这个问题。 我们在图 2 中概述了所提出的方法。

核心思想是在训练阶段正则化鉴别器预测。 具体来说,我们引入了两个指数移动平均变量 α_R 和 α_F,称为锚点,以跟踪鉴别器对真实图像和生成图像的预测。 补充文件中提供了锚点 α_R 和 α_F 的计算。 然后我们使用等式 (2) 中描述的目标 L_G 训练生成器,并最小化判别器的正则化目标 L_D:
![]()
其中 R_LC 是建议的正则化项:
![]()
乍一看,等式 (3) 中的目标似乎违反直觉,因为正则化项 R_LC 推动鉴别器混合真实图像和生成图像的预测,而不是区分它们。 然而,我们在第 3.3 节中展示了 R_LC 为优化更稳健的目标提供了有意义的约束。 此外,我们在第 4 节中凭经验证明,通过适当的权重 λ,这种简单的正则化方案 1) 改进了有限训练数据下的泛化,以及 2) 补充了现有的数据增强方法。
为什么是移动平均? 跟踪预测的移动平均值可以减少 mini-batches 之间的方差,并稳定等式(4)中描述的正则化项。直观上,当判别器的预测逐渐收敛到驻点时,移动平均变得稳定。 我们发现这适用于我们实验中使用的 GAN 模型(例如,图 8)。 我们在图 2 中说明了使用两个移动平均变量 α_R 和 α_F 的一般情况。在某些情况下,例如在理论分析中,我们可以使用单个移动平均变量来跟踪真实图像或生成图像的预测。
3.3 与 LeCam Divergence 的联系
我们展示了所提议的正则化与 WGAN 模型和称为 LeCam (LC)-divergence 或三角判别(triangular discrimination)的 f-divergence 的联系。 在温和的假设下,我们的正则化方法可以强制 WGAN 最小化加权的 LC 散度。 我们表明 LC-divergence 1) 可用于在有限训练数据下稳健地训练 GAN 模型,2) 与其他 GAN 模型中使用的 f-divergences 有密切关系。
我们首先重新审视 f-divergence 的定义。 对于两个离散分布 Q(x) 和 P(x),f 散度定义为:

如果 f 是凸函数且 f(1) = 0。f-divergence 在 GAN 中起着至关重要的作用,因为它定义了底层度量以对齐生成的分布 p_g (x) 和数据分布 p_d (x)。 例如,Goodfellow 等人表明饱和 GAN 最小化了两个分布之间的 JS-divergence [37]:
![]()
其中 C(G) 是当 D 固定为最优值时生成器的虚拟目标函数。
最近,不属于 f-divergence 系列的 Wasserstein 距离引入了不同的分布测量。 然而,当训练数据有限时,WGAN 和类似模型(例如 BigGAN)的性能会下降。 我们表明,将建议的正则化结合到这些 GAN 模型中可以提高泛化性能,尤其是在有限的训练数据下。 接下来,我们展示了正则化 WGAN 和 LC-divergence 之间的联系。
命题 1。对于 WGAN,考虑等式 (3) 中的正则化目标,其中 R_LC 具有单个锚点且 λ > 0。假设对于固定的生成器 G,锚点收敛到固定值 α (α > 0)。 令 C(G) 表示固定最优 D 的生成器的虚拟目标函数。我们有:

其中,△(P||Q) 是 LeCam (LC)-divergence,也就是 triangular discrimination,

由于散度是非负的,我们需要 λ < 1 / (2α),这表明正则化权重不应该太大。 证明在补充材料中给出。 我们注意到命题 1 中的分析仅使用单个锚点,是我们在第 3.2 节中描述的正则化器的简化。 为了获得更好的性能和更广泛的应用,我们在实验中使用 1) 两个锚和 2) 将正则化项应用于核心(hinge)和非饱和损失。 我们注意到这在文献中并不罕见。 例如,Goodfellow 等人从理论上表明饱和 GAN 损失最小化了 JS 散度。 然而,在实践中,他们使用非饱和 GAN 以获得更好的经验结果。
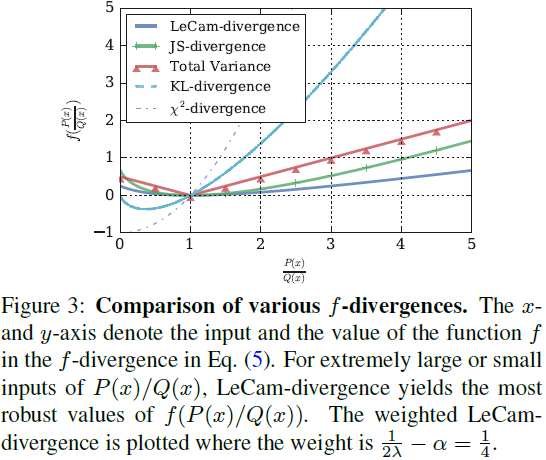
在描绘了 LC-divergence 和正则化 WGAN 之间的联系之后,我们证明了当可用数据有限时,LC-divergence 是一个稳健的 f-divergence。 图 3 说明了几种常见的 f 散度,其中 x 轴绘制了等式 (5)中函数 f 的输入,即 P(x)/Q(x),y轴表示f的函数值。 请注意,当可用的训练数据有限时,预计输入 P(x)/Q(x) 是错误的,并且可能包含极大/极小的值。 图 3 显示 LC 散度有助于获得更稳健的极端输入函数值。 此外,LC 散度是对称的,并且在 0 和 2 之间有界,当且仅当 p_d = p_g 时达到最小值。 这些特性表明,当可用的训练数据有限时,LC 散度是一种可靠的测量方法。 这一观察结果与第 4 节所示的实验结果一致。
命题 2(LeCam 散度的性质)。LC-divergence △ 是具有以下属性的 f-divergence:
- △是非负且对称的。
- △(p_d || p_g) 是有界的,当 p_d = p_g 时最小值为 0,当 p_d 和 p_g 不相交时最大值为 2。
- △-divergence 是 χ2-divergence 的对称版本,即 △(P||Q) = χ2(P||M) + χ2(Q||M),其中 M = 1/2 (P + Q)。
- 以下不等式成立:1/4 (P,Q) ≤JS(P,Q) ≤ 1/2 (P,Q) ≤ 1/2 TV (P,Q),其中,JS 和 TV 表示 JS-divergence 和Total Variation。
命题 2 表明 LC-divergence 与其他 GAN 方法中使用的 f-divergences 密切相关。 例如,它是 LSGAN 中使用的对称且平滑的 χ2-divergence。 饱和 GAN 中使用的 JS 散度的加权下限和 EBGAN 方法中使用的 Total Variation distance。
4. 实验结果
4.1 在 CIFAR10 和 CIFAR100 上的结果

如表 1 所示,所提出的方法提高了 BigGAN 模型的泛化性能。 其他 GAN 模型之间的比较显示了所提出方法的竞争性能,尤其是在有限的训练数据下。 这些结果证实我们的正则化方法最大限度地减少了有限训练数据上的合理差异。
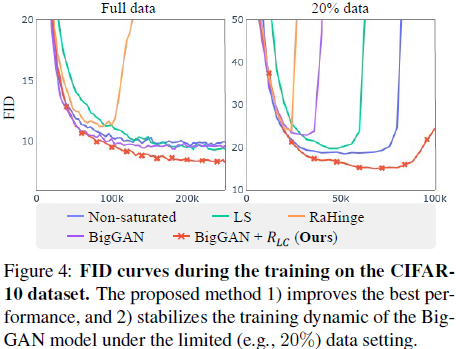
为了进一步了解对训练动态的影响,我们在图 4 中绘制了训练阶段的 FID 分数。所提出的方法稳定了有限数据的训练过程(即,FID 分数在后期恶化)并在最后一次迭代(100K)实现了最低的 FID 分数 。 这一结果表明我们的方法可以在有限数据上稳定 GAN 训练过程。
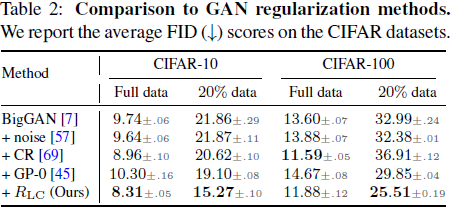
我们将我们的方法与三种正则化方法进行了比较:表 2 中的实例噪声、GP-0 和 CR。请注意,在 BigGAN 模型中默认使用谱范数正则化。对于 GP-0 方法,我们仅对真实图像应用梯度惩罚。 我们的正则化方案优于这些正则化方法,特别是在有限的数据设置下。 尽管在有限数据下有所改进,但 GP-0 方法在使用完整训练数据时会降低 FID 性能。 我们注意到 BigGAN 论文中提出了类似的观察结果。

在图 5 中,我们可视化了在训练阶段使用 GP-0 和我们的方法训练的模型的 GP-0 值。 有趣的是,本文方法也限制了 GP-0 值,尽管它没有明确地最小化 GP-0 损失。

最后,我们将我们的正则化方法与数据增强相结合,并表明它是对最近数据增强方法的补充。 如表 3 所示,所提出的方法提高了 DA 和 ADA 的性能,尤其是在有限的数据设置下。 请注意,数据增强方法从不同的角度解决了这个问题,并代表了这项工作之前有限训练数据的现有技术水平。
4.2 与 ImageNet 上的最新技术的比较

ImageNe 是一个具有挑战性的数据集,因为它包含更多类别和分辨率更高的图像。 考虑到模型性能的方差,我们遵循 BigGAN 论文中的评估协议。 具体来说,我们使用不同的随机种子运行训练/评估流程三次,然后报告平均性能。 我们在表 4 中给出了定量结果。所提出的方法提高了 BigGAN 模型对稀缺训练数据问题的抵抗力(例如,在 25% 的数据下,FID 下降了 3.75)。 值得注意的是,我们模型的性能方差在大多数情况下都降低了(例如,在 25% 的数据下,FID 2.59 → 1.73),表明其具有稳定训练过程的能力。

表 5 展示了与使用 DA 方法的最先进模型相比的定量结果。

图 6 中显示的定量结果和定性比较都证实了所提出的方法是对数据增强方法的补充。 通过结合我们的正则化和数据增强方法,我们在有限的(例如 10%)ImageNet 数据集上实现了最先进的性能。
4.3 与数据增强的比较

我们使用 StyleGAN 数据集进行实验。 补充文件中提供了实验细节。 如表 3 和表 6 所示,所提出的方法在所有情况下都提高了使用(和不使用)数据增强训练的 Style-GAN2 模型的性能。 我们注意到,与 BigGAN 不同,Style-GAN2 模型最小化了非饱和 GAN 损失,并在默认设置中使用梯度惩罚 GP-0。 这表明所提出的正则化方案可以与现有的正则化方法一起应用于其他 GAN 损失函数。

我们在表 7 中进行了比较,总结了数据增强和我们的方法的(缺点)优势。
首先,当训练数据极其有限时,数据增强方法比所提出的方法产生更显着的增益。 尽管如此,由于两种方法的互补性,我们的方法可以进一步提高数据增强的性能。
其次,当训练图像足够多样化(例如,完整数据集)时,数据增强方法可能会降低性能。 这与 [28] 中描述的观察结果一致。 相比之下,我们的正则化方法可能不会遇到同样的问题。
4.4 分析和消融研究
我们使用 BigGAN 模型和 CIFAR-10 数据集进行分析和消融研究。

R_LC 的正则化强度。 我们对正则化权重 λ 进行了研究。 如图 7(b) 所示,权重大于 0.5 会降低性能。 这与我们在等式 (7) 中的分析一致。 较大的权重 λ 导致性能下降。 通常,当权重 λ 在合理范围内时,所提出的方法是有效的,例如图 7(b) 中的 [0.1, 0.5]。

正则化真实与生成的图像预测。 我们的默认方法对真实图像 D(x) 和生成图像 D(G(z)) 的预测进行正则化。 在本实验中,我们研究了分别正则化两项 D(x) 和 D(G(z)) 的有效性。 如表 8 所示,对两项进行正则化可获得最佳结果。

鉴别器预测。 我们在图 8 中将训练期间的鉴别器预测可视化。如果没有正则化,真实图像和生成图像的预测会随着鉴别器过度拟合有限的训练数据而迅速偏离。 另一方面,所提出的方法,如等式 (4) 所示,惩罚真实图像和生成图像的预测之间的差异,从而将预测保持在特定范围内。 这一观察结果从经验上证实了鉴别器的预测逐渐收敛到固定点,移动平均变量 α_R 和 α_F 也是如此。
模型尺寸。 由于减少模型容量可能会缓解过度拟合问题,我们研究了对生成器和鉴别器使用较小模型尺寸的性能。 图 7(a) 显示了将生成器和鉴别器中的通道数量逐渐减半的结果。 我们的方法所做的改进随着模型大小的增加而增加,因为过拟合问题对于具有更高容量的模型更为严重。
5. 结论和未来工作
在这项工作中,我们提出了一种在有限数据设置下训练 GAN 模型的正则化方法。 所提出的方法通过在训练阶段对判别器施加正则化损失,为 GAN 模型实现更稳健的训练目标。
在实验中,我们对具有不同 GAN 主干的各种图像生成数据集进行实验,以证明所提出方案的有效性:
- 提高 GAN 模型的性能,特别是在有限的数据设置下
- 可以与数据增强结合以进一步提高性能。
未来,我们计划解决训练数据稀缺问题
- 条件 GAN 任务(如图像外推、图像到图像转换等)
- 大规模噪声训练数据的鲁棒 GAN 学习
参考
Tseng, Hung-Yu, et al. "Regularizing generative adversarial networks under limited data." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
S. 总结
S.1 核心思想
有限数据设置下,通过在训练阶段对判别器 loss 添加如下正则化项,使 GAN 模型实现更稳健的训练。
![]()
![]()
其中,α_R 和 α_F 是指数移动平均变量 ,称为锚点,用于跟踪鉴别器对真实图像和生成图像的预测。
很疑惑的一点,交换公式 4 中 α_R 和 α_F 的位置是否更为合理?因为直观地想法是,鉴别器对真实数据的评估应该接近其对真实图像预测。
S.2 分析
该正则化项有助于 GAN 模型实现更稳健的训练。如图 8 所示,随着训练的进行,鉴别器的预测逐渐收敛到固定点,移动平均变量 α_R 和 α_F 也是如此。
实验结果表明,随正则化项的权重的增加,模型性能先增后减,如图 7 所示。这是因为,该正则化项与 LeCam 散度相关,该散度限制正则化权重不宜过大。而直观地理解是,由于训练数据有限,权重过大时,容易发生过拟合。
另一方面,当模型参数过多时,也容易发生过拟合,造成性能下降,如图 7 所示。















 1098
1098











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









