







DAE-GAN: Dynamic Aspect-aware GAN for Text-to-Image Synthesis
公和众和号:EDPJ(添加 VX:CV_EDPJ 或直接进 Q 交流群:922230617 获取资料)
目录
0. 摘要
文本到图像合成是指从给定的文本描述生成图像,其关键目标在于照片逼真度和语义一致性。以前的方法通常使用句子嵌入生成初始图像,然后利用细粒度的单词嵌入进行精化。尽管取得了显著的进展,文本中包含的 “方面(aspect)” 信息(例如,红色的眼睛)通常被忽略,这些信息涉及到几个词而不是描述 “某物的特定部分或特征” 的一个词。“方面” 信息对合成图像的细节非常有帮助。如何更好地利用文本到图像合成中的方面信息仍然是一个未解决的挑战。为解决这个问题,本文提出了一种动态方面感知生成对抗网络(Dynamic Aspect-awarE GAN,DAE-GAN),从多个粒度综合地表示文本信息,包括句子级、单词级和方面级。此外,受人类学习行为启发,我们开发了一种新颖的方面感知动态重绘器(Aspect-aware Dynamic Re-drawer,ADR)用于图像细化,其中交替使用了一个关注全局细化(Attended Global Refinement,AGR)模块和一个方面感知局部细化(Aspect-aware Local Refinement,ALR)模块。AGR 利用单词级嵌入全局增强先前生成的图像,而 ALR 动态使用方面级嵌入从局部角度细化图像细节。最后,设计了相应的匹配损失函数,以确保不同级别上的文本-图像语义一致性。在两个经过广泛研究和公开可用的数据集(即CUB-200 和 COCO)上进行的大量实验证明了我们方法的优越性和合理性。
研究人员已经证明人眼具有中央视觉和周边视觉 [1,34,25]。中央视觉集中于一个人当前的需要,而周边视觉则利用对周围环境的观察来支持中央视觉。 通过中央视觉和周边视觉的动态运用,我们可以对文本和视觉内容进行深入的语义理解。
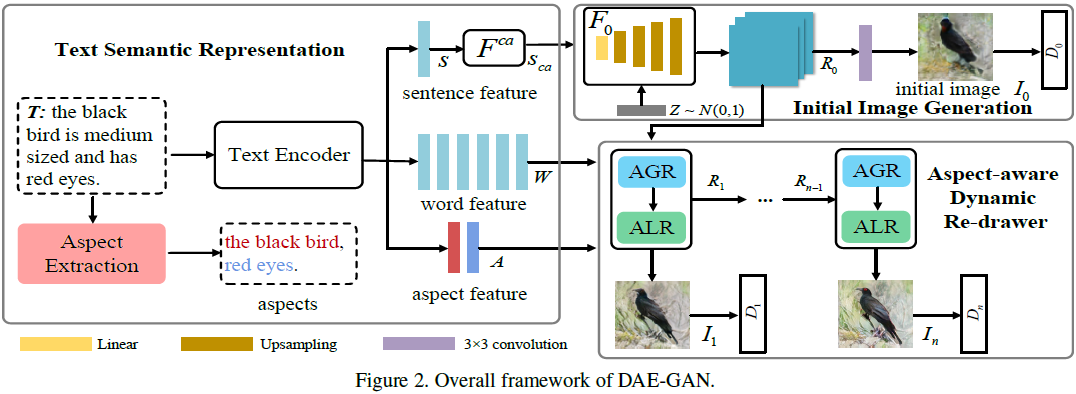
3. 动态方面感知生成对抗网络(DAE-GAN)
如图 2 所示,我们提出的 DAE-GAN 包含三个主要组件:1)文本语义表示:从多个粒度提取文本语义表示,即句子级别,词级别以及方面级别;2)初始图像生成:使用句子级别文本特征和随机噪声向量生成低分辨率图像;以及3)方面感知动态重绘器:以动态方式从全局和局部两个层面对初始图像进行优化,这也是本文的主要关注点。
3.1 文本语义表示
对文本语义的全面理解在文本到图像的合成中起着至关重要的作用。先前的方法主要从句子级别和词级别提取文本特征。然而,它们忽视了文本中包含的方面信息,该信息指的是与特定部分或特征相关的若干单词,而不是描述某物的一个单词,例如,“黑色的鸟体型中等,有红色的眼睛” 中的 ‘红色的眼睛’。方面级别信息的粒度介于句子级别和词级别信息之间。这对于图像细节的优化可能很有帮助,应该引起更多关注。 如图 2 所示,我们从多个粒度,即句子级别、词级别和方面级别,表示文本特征。我们使用长短时记忆(Long Short-Term Memory,LSTM)网络提取文本描述 T 的语义嵌入,其公式如下:
![]()
其中,T = {T_j | j = 0, 1, ..., 𝑙 - 1} 包含 𝑙 个单词。 W = {W_j | j = 0, 1, ..., 𝑙 - 1} ∈ ℝ^(𝑙×d_w) 表示从 LSTM 每个时间步的隐藏状态获取的词级特征。这里,d_w 表示文本嵌入的维度。s ∈ ℝ^d_w 表示来自 LSTM 最后隐藏状态的句子级语义特征。
我们进一步采用条件增强(Conditioning Augmentation,CA)[38] 来增强训练数据并通过从独立的高斯分布重新采样输入句向量来避免过拟合。具体而言,我们使用 CA 增强句子特征,表示如下:
![]()
其中,F^ca(·) 代表 CA 函数,s_ca 是使用 CA 增强的的句子语义表示。正如前面提到的,方面信息对生成的图像细节非常关键。然而,由于不同句子的焦点和描述不同,很难识别并提取每个句子的适当方面信息。为了解决这个问题,我们采用了句法结构。具体而言,我们首先采用 NLTK 对每个句子进行词性标注(POS Tagging)。然后,我们手动设计不同的规则来提取不同数据集的方面信息。之后,我们可以获得方面信息 {asp_i | i = 0, 1, ..., n - 1}。接下来,我们使用 LSTM 集成此信息并提取方面级特征,其公式如下:
![]()
其中 A 表示文本描述的方面级特征表示,n 是提取的方面数。
3.2 初始图像生成
按照通常的做法,我们首先在初始阶段生成一幅低分辨率图像。如图 2 所示,我们利用增强的句子嵌入 s_ca 和随机噪声向量 z 来生成初始图像 I_0。z 服从于正态分布 N(0,1)。在数学上,我们使用 R_0 来表示初始阶段的相应图像特征:
![]()
在这里,F_0 是初始生成阶段的图像生成器。如图 2 所示,它包括一个全连接层和四个上采样层。
3.3 方面感知动态重绘器
据我们所知,我们是第一个将给定句子中包含的方面信息引入到文本到图像合成中的研究者。因此,如何在图像细化阶段整合方面信息是我们应该解决的主要挑战。在这项工作中,受到人类学习行为的启发,我们开发了一种新颖的方面感知动态重绘器(ADR),在考虑句子中的方面信息的情况下完善图像。具体而言,我们设计了一种新颖的关注全局细化(AGR)模块,用于利用细粒度的单词级特征进行全局细化,以及一种新颖的方面感知局部细化(ALR)模块,用于利用方面级特征进行局部增强。通过以动态方式交替应用这两个组件,我们能够从全局和局部的角度细化图像细节。在下面的部分中,我们将以第 i 次细化操作为例介绍 AGR 和 ALR 的技术细节。
3.3.1 关注全局细化
为了合成具有照片般逼真和语义一致性的图像,有必要使用细粒度特征进一步全局细化图像。因此,AGR 是为了基于初始图像进行全局细化而开发的。
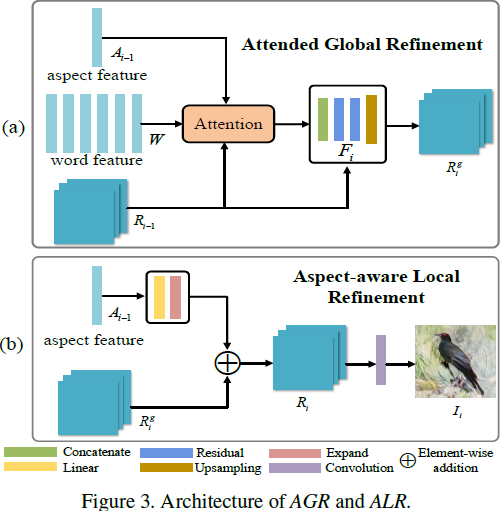
具体而言,我们使用单词级文本特征,通过考虑每个单词的贡献来帮助细化过程。当前的研究主要通过采用来自先前步骤的图像特征来选择重要单词的注意机制来更新单词级特征 [22]。不同地,我们进一步整合图像特征和方面级特征来更新和增强单词级特征,如图 3(a) 所示。这个过程可以数学上表示如下:
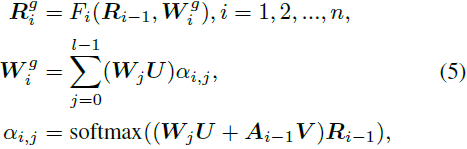
其中,R^g_i ∈ R^(d_r x N_i) 代表通过图像特征 R_(i−1) ∈ R^(d_r x N_(i−1)) 和关注的单词级特征进行全局丰富的图像特征。N_i 是第 i 步时 R^g_i 的大小。F_i(·, ·) 表示图像特征 transformer。W^g_i ∈ R^R^(d_r x N_(i−1)) 表示关注的全局特征。α_i,j 表示注意权重分数。U ∈ R^(d_w x d_r) 和 V ∈ R^(d_w x d_r) 是感知层,用于将单词嵌入 W 和方面嵌入 A 转换到视觉特征的潜在公共语义空间。
3.3.2 方面感知局部细化
在前面的部分中,我们介绍了如何利用单词级特征从全局角度完善图像。然而,一些特定图像局部细节的增强尚未完成。如上所述,文本描述中包含的方面对于合成相应的局部图像细节可能很重要。为此,如图 3(b) 所示,ALR 被开发用于通过方面级特征从局部角度完善图像。
在技术上,我们通过逐元素相加将方面特征 A_(i −1) 与全局细化的图像特征 R^g_i 结合,如下所示:
![]()
其中,操作
![]()
意味着重复连接 A_i N_i 次。为了合成逼真的图像,我们最终引入一个 3x3 卷积滤波器,将经过细化的图像特征 R_i 转换为第 i 次 ADR 细化操作中的图像 I_i。总而言之,AGR 和 ALR 交替应用。同时,在 ADR 的每个细化步骤中动态添加方面级特征。
3.4 目标函数
为了生成逼真的图像并确保文本描述与相应图像之间的语义一致性,我们精心设计了损失函数。在每一步中,生成器 G(例如 ADR)和鉴别器 D 交替训练。为了开始通用的做法,每个生成器在每一步的目标损失函数定义如下:
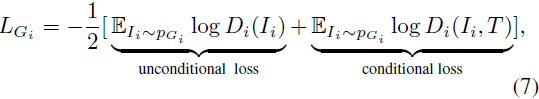
其中,第一个无条件损失项来自鉴别器,用于区分真实和虚假图像。第二项是一个有条件损失,使合成的图像与输入的句子相匹配。
传统上,有条件损失项包括句子-图像和单词-图像对。与以往的工作不同,我们通过生成过程引入了方面信息。为了确保生成的图像确实包含与相应方面匹配的局部细粒度细节,我们还在条件损失中包括了一个方面-图像匹配对,如下所示:
![]()
其中,D(I, s),D(I, W) 和 D(I, A) 分别计算图像与句子、单词和方面之间的匹配度。
在 [45, 36] 的基础上,我们进一步利用 DAMSM 损失 [36] 计算图像和文本描述之间的匹配度,数学上表示为 L_DAMSM。而 CA 损失被定义为标准高斯分布和训练文本的高斯分布之间的 Kullback-Leibler 散度,即:
![]()
生成器网络的最终目标函数由前面提到的三个项组成:
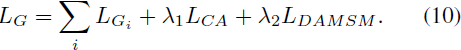
对于对抗学习,每个判别器 D_i 都被训练以通过最小化交叉熵损失来精确地识别输入图像是真实还是虚假。每个判别器 D_i 的对抗损失被定义为:
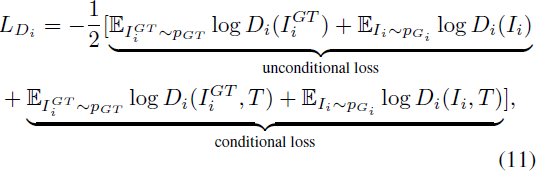
无条件损失负责区分合成图像和真实图像,有条件项确定图像是否与输入的句子匹配。I^GT_i 是从第 i 步的真实图像分布 p_GT 中采样得到的。判别器网络的最终目标函数是:
![]()
4. 实验结果
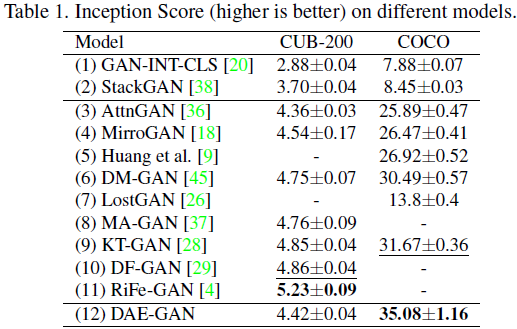
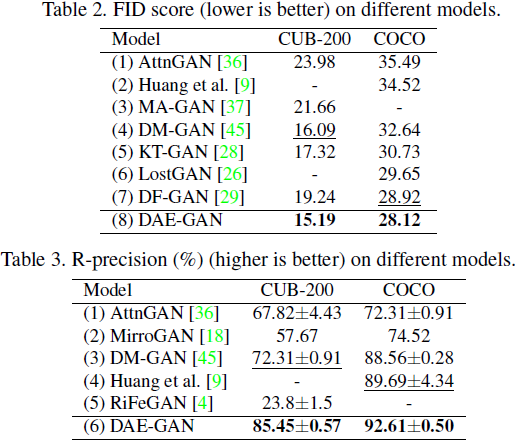
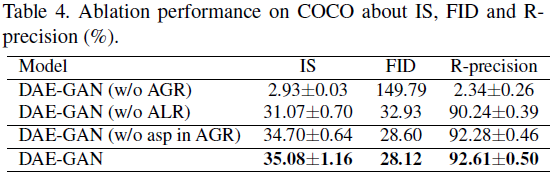
S. 总结
S.1 主要贡献
本文提出了一种动态方面感知生成对抗网络(Dynamic Aspect-awarE GAN,DAE-GAN),从多个粒度(句子级、单词级和方面级)综合地表示文本信息。此外,受人类学习行为启发,开发了一种新颖的方面感知动态重绘器(Aspect-aware Dynamic Re-drawer,ADR)用于图像细化,其中交替使用了一个关注全局细化(Attended Global Refinement,AGR)模块和一个方面感知局部细化(Aspect-aware Local Refinement,ALR)模块。AGR 利用单词级嵌入全局增强先前生成的图像,而 ALR 动态使用方面级嵌入从局部角度细化图像细节。最后,设计了相应的匹配损失函数,以确保不同级别上的文本-图像语义一致性。
S.2 方法
动态方面感知生成对抗网络(DAE-GAN)。
- 首先全面地从多个层次对文本信息进行编码,包括句子级、单词级和方面级。
- 然后,在两阶段的生成过程中,首先利用句子级嵌入在初始阶段生成低分辨率图像。
- 接下来,在细化阶段,通过将方面级特征视为中央视觉,单词级特征视为周边视觉,开发了一个方面感知动态重绘器(ADR),该重绘器交替应用了关注全局细化(AGR)模块和方面感知局部细化(ALR)模块进行图像细化。
- AGR 利用单词级嵌入全局增强先前生成的图像。ALR 动态利用方面级嵌入从局部角度完善图像细节。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









