






Generating Diverse High-Fidelity Images with VQ-VAE-2
公和Z与号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
目录
0. 摘要
我们探讨了矢量量化变分自编码器(Vector Quantized Variational AutoEncoder,VQ-VAE)模型在大规模图像生成中的应用。为此,我们对 VQ-VAE 中使用的自回归先验进行了缩放和增强,以生成比以前可能的合成样本具有更高一致性和保真度的样本。我们使用简单的前馈编码器和解码器网络,使我们的模型成为对编码和/或解码速度至关重要的应用的有吸引力的选择。此外,VQ-VAE只需要在压缩的潜在空间中对自回归模型进行采样,这比在像素空间中采样快一个数量级,特别是对于大图像。我们证明,VQ-VAE 的多尺度分层组织,加上对潜在代码的强大先验,能够生成质量与 ImageNet 等多方面数据集上现有技术的生成对抗网络相媲美的样本,同时不受 GAN 已知缺陷的困扰,如模态崩溃和缺乏多样性。
3. 方法
建议方法遵循两阶段方法:首先,我们训练一个分层的 VQ-VAE(见图 2a)来将图像编码到离散的潜在空间,然后我们在由所有数据引起的离散潜在空间上拟合一个强大的 PixelCNN 先验。
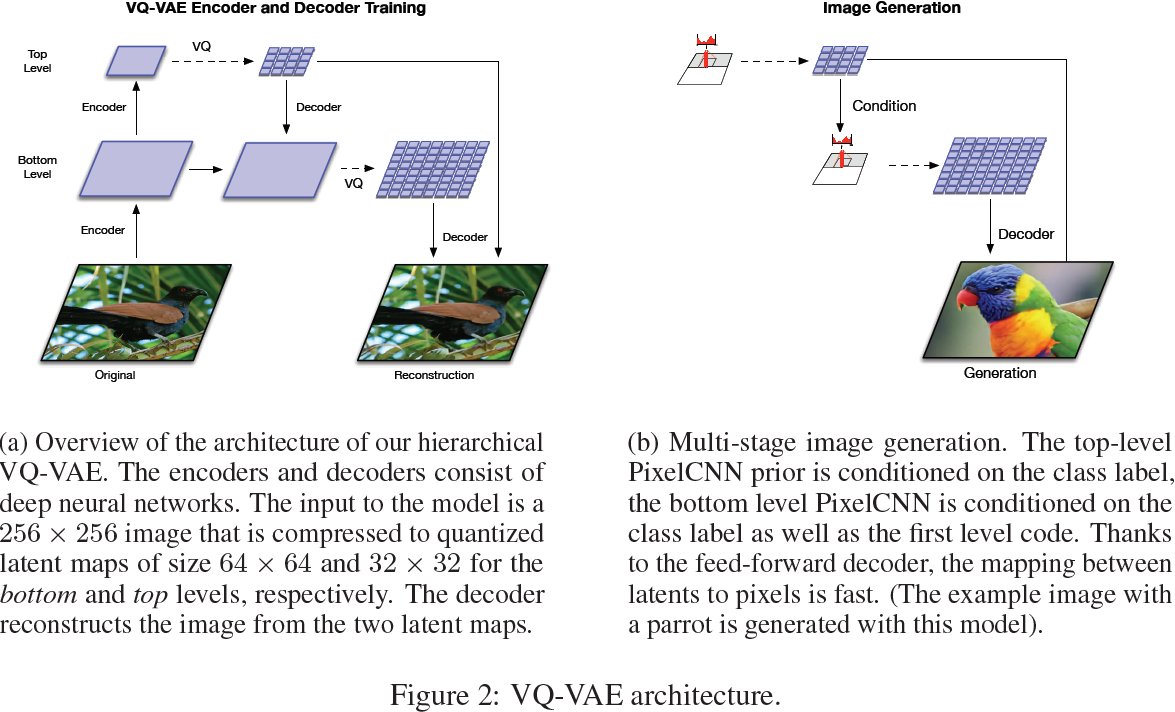

3.1 阶段 1:学习分层潜在编码
与普通的 VQ-VAE 不同,本工作使用分层的矢量量化编码来建模大图像。这背后的主要动机是分别建模局部信息(如纹理)和全局信息(如对象的形状和几何结构)。因此,每个级别上的先验模型可以定制以捕捉该级别存在的特定相关性。我们的多尺度分层编码器的结构如图 2a 所示,其中顶部潜在编码模型全局信息,底部潜在编码在顶部潜在编码的条件下负责表示局部细节(见图 3)。我们注意,如果我们没有将底部潜在编码置于顶部潜在编码的条件下,那么顶部潜在编码将需要编码来自像素的每个细节。因此,我们允许层次结构中的每个级别分别依赖于像素,这鼓励每个潜在图中的编码互补信息,有助于降低解码器中的重构误差。有关更多详细信息,请参见算法1。

![]()
![]()
对于 256x256 的图像,我们使用两个级别的潜在层次结构。如图 2a 所示,编码器网络首先将图像转换并缩小 4 倍,形成一个 64x64 的表示,然后对其进行量化以获得底层潜在图。然后,另一组残差块进一步将表示按 2 倍比例缩小,在量化后产生一个的 32x32 的顶层潜在图。解码器类似于一个前馈网络,其输入包括量化潜在分层的所有级别。它由一些残差块组成,后面跟随一些步幅转置卷积以将表示上采样回原始图像大小。
3.2 第二阶段:学习潜在编码的先验
为了进一步压缩图像,并能够从第1阶段学到的模型中进行采样,我们学习了潜在编码上的先验。使用神经网络从训练数据拟合先验分布已成为常见做法,因为它可以显著提高潜在变量模型的性能[5]。这个过程还减小了边缘后验和先验之间的差距。因此,在测试时从学到的先验中采样的潜在变量接近解码器网络在训练期间观察到的内容,从而产生更连贯的输出。从信息理论的角度来看,将先验拟合到学到的后验的过程可以看作是对潜在空间的无损压缩,通过使用更好地逼近其真实分布的分布来重新编码潜在变量,从而产生更接近 Shannon 熵的比特率。因此,真实熵与学到的先验的负对数似然之间的差距越小,从解码潜在样本中可以期望得到更真实的图像样本。
在 VQ-VAE 框架中,这个辅助先验是通过一个强大的自回归神经网络(如 PixelCNN)在事后的(post-hoc)第二阶段建模的。对顶级潜在图的先验负责建模结构全局信息。因此,我们使用多头自注意力层,如 [6, 23] 中所示,使其能够受益于更大的感受野,以捕捉在图像中相距较远的空间位置的相关性。相反,对于编码局部信息的底层潜在的条件先验模型将在更大的分辨率上运行。由于内存限制,使用与顶层先验相同的自注意力层在这个先验中并不实际。因此,我们发现使用大的条件堆栈(来自顶层先验)在这个层次上产生了良好的性能(见图 2b)。层次分解还允许我们训练更大的模型:我们分别训练每个先验,从而利用硬件加速器上所有可用的计算和内存。有关更多详细信息,请参见算法 2。
我们的顶层先验网络对 32x32 潜在变量进行建模。PixelCNN 的残差门控卷积层与每五层的因果多头注意力交叉。为了正则化模型,我们在每个残差块之后加入了 dropout,以及在每个注意力矩阵的 logits 上进行了 dropout。我们发现,在 PixelCNN 堆栈的顶部添加由 1x1 卷积组成的深度残差网络进一步提高了似然,而不会减缓训练或显著增加内存占用。我们的底层条件先验在 64x64 的潜在空间上运行。这在所需内存和计算成本方面显著更昂贵。正如之前所论,这个层次结构中编码的信息主要对应于局部特征,不需要大的感受野,因为它们是在顶层先验的条件下的。因此,我们使用一个没有自注意层的较弱网络。我们还发现,在这个层次上使用深度残差条件堆栈在很大程度上有助于性能。
3.3 以分类器为基础的拒绝采样权衡多样性
与 GAN 不同,用最大似然目标训练的概率模型被迫建模所有训练数据分布。这是因为 MLE 目标可以表示为数据和模型分布之间的前向 KL 散度,如果在训练数据中的一个示例被分配零质量,那么这个值将趋于无穷大。虽然这些模型中所有模式的覆盖是这些模型的吸引人之处,但这个任务比对抗式建模要困难得多,因为基于似然的模型需要拟合数据中存在的所有模式。此外,从自回归模型进行祖先采样实际上可能导致在长序列上积累错误,并导致质量降低的样本。最近的 GAN 框架[4, 1] 提出了自动化的样本选择程序来平衡多样性和质量。 在这项工作中,我们还提出了一种基于直觉的自动化方法,以平衡样本的多样性和质量,即我们的样本距离真实数据流形越近,它们被预训练分类器正确分类的可能性就越大。具体来说,我们使用在 ImageNet 上训练的分类器网络,根据分类器分配给正确类别的概率对我们模型生成的样本进行评分。
5. 实验
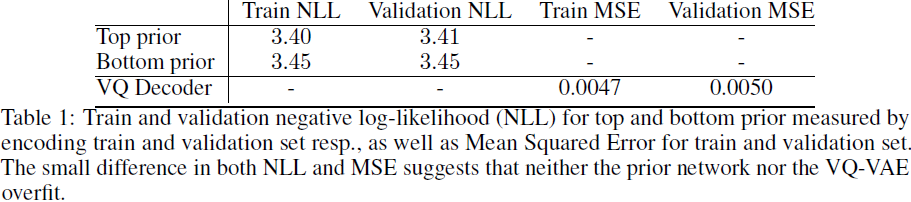


图 7b 显示了在不同拒绝率下,使用分类器拒绝采样('critic',见第 3.3 节)的 VQ-VAE 和 BigGAN 的 Precision-Recall 结果,以及不同截断水平下的 BigGAN-deep 结果。VQ-VAE 的Precision 略低,但 Recall 的值较高。
如图 7a 所示,我们使用基于分类器的拒绝采样作为在多样性和质量之间进行权衡的一种方式(见第 3.3 节)。对于 VQ-VAE,这提高了 IS 和 FID 分数,其中 FID 从大约 30 提高到 10 左右。对于 BigGAN-deep,拒绝采样(称为 critic)比 BigGAN 论文中提出的截断方法效果更好 [4]。我们观察到 Inception 分类器对 VQ-VAE 重建中引入的轻微模糊或其他扰动非常敏感,这由在简单压缩原始图像时的 FID 约为 10 而不是约为 2 所示。因此,我们还计算了 VQ-VAE 样本与重建之间的 FID(用 FID* 表示),表明相比 FID 所暗示, Inception 网络统计与真实图像数据更接近。

















 2263
2263

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









