







Can VLMs Play Action Role-Playing Games? Take Black MythWukong as a Study Case

目录
0. 摘要
最近,基于大型语言模型(LLM)的智能体(agent)在多个领域取得了显著进展。其中,将这些智能体应用于电子游戏已成为最受关注的研究方向之一。传统方法通常依赖于游戏 API 来获取游戏内的环境和动作数据。然而,这种方法受制于 API 的可用性,并且无法反映人类玩游戏的方式。随着视觉语言模型(VLM)的出现,智能体的视觉理解能力得到增强,使其能够仅通过视觉输入与游戏交互。
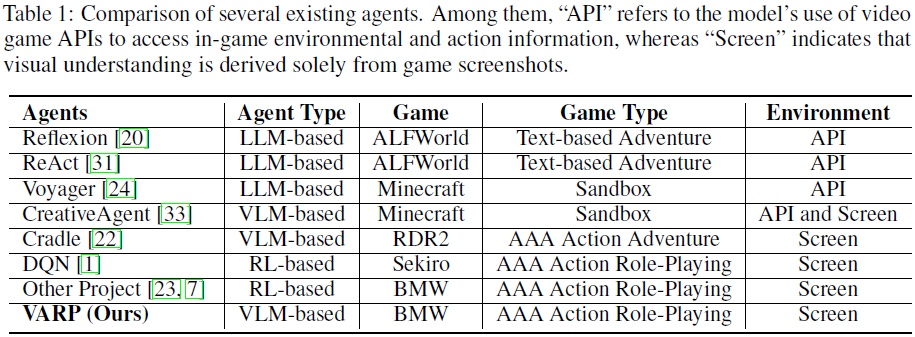
尽管取得了进展,但当前的方法在以动作为导向的任务中仍面临挑战,尤其是在动作角色扮演游戏(ARPG)中。此类游戏中常用的强化学习方法存在泛化能力差且训练需求高的缺点。为了解决这些局限性,我们选择了一款 ARPG 游戏《黑神话:悟空》(Black Myth: Wukong,缩写 BMW)作为研究平台,以探索在仅使用视觉输入和复杂动作输出的场景下,现有 VLM 的能力边界。
我们在游戏中定义了 12 项任务,其中 75% 与战斗相关,并将多种最新的 VLM 技术融入该基准测试。此外,我们将发布一个包含人类操作数据集的数据集,其中包括录制的游戏视频及操作日志(包括鼠标和键盘动作)。同时,我们提出了一种新颖的 VARP(Vision Action Role-Playing,视觉动作角色扮演)智能体框架,该框架由动作规划系统和视觉轨迹系统组成。我们的框架展示了执行基础任务的能力,并在 90% 的简单和中等难度战斗场景中取得成功。本研究旨在为在复杂动作游戏环境中应用多模态智能体提供新的见解和方向。
2. 方法
2.1 概述
我们提出了一种新颖的框架,称为 VARP 智能体,该框架以游戏截图作为直接输入。通过一组视觉语言模型(VLM)的推理,最终生成 Python 代码形式的动作,这些动作可直接操作游戏角色。每个动作由各种原子指令(atomic commands)的组合构成,这些原子指令包括轻攻击、闪避、重攻击、恢复生命值等。与此同时,VARP 智能体维护三个库:情境库、动作库和人类引导库。这些库可以被检索和更新,以存储用于自我学习和人类引导的深入知识。
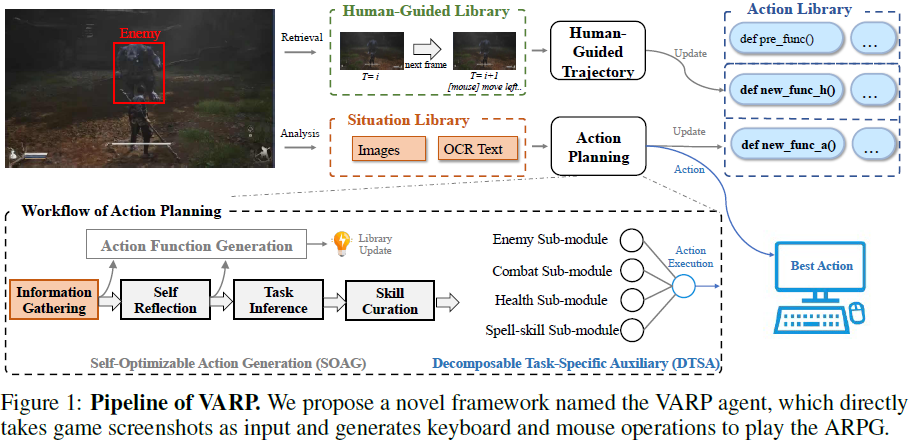
总体来说,VARP 智能体分为两个系统:动作规划系统和人类引导轨迹系统,如图 1 所示。在动作库中,“def new_func_a()” 代表由动作规划系统生成的新动作,“def new_func_h()” 代表由人类引导轨迹系统生成的新动作,而“def pre_func()” 则代表预定义动作。接下来的部分将详细说明每个系统。
2.2 动作规划系统
动作规划系统主要用于动作推理和生成。该系统利用情境库和可更新的动作库作为知识检索基础。通过输入的游戏截图,该系统使用一组 VLM 来选择或生成适合当前情境的动作。生成的情境和动作会被存储或更新到这两个库中。
- 此外,我们提出了可分解的任务专用辅助模块(decomposable task-specific auxiliary module,DTSA),用于将大任务分解为小的子任务,然后分配给多个 VLM,以减少模型遗忘和幻觉的发生。
- 我们还引入了一个可自我优化的动作生成模块(self-optimizable action generation module,SOAG),鼓励 VLM 生成针对某些困难任务的新动作,从而更高效、更高质量地完成复杂任务。
2.2.1 基础 VLM 组
受 Cradle [22] 启发,我们的主要流程延续了 Cradle 中的五个基础模块,其中部分模块调用 VLM 进行推理,形成一个基础 VLM 组。在初始化阶段,我们手动预定义了一些动作,并将其作为先验知识存入动作库。每个动作都是一个具有详细文本注释的 Python 函数,并计算了这些注释的嵌入用于存储。
- 信息收集模块(Information Gathering)负责从采样的游戏截图中收集信息,包括与情境和动作相关的文本和视觉信息。文本信息主要包括文本指引、文本标签和通知;视觉信息则主要包括环境位置、角色动作和界面图标。文本识别由 OCR 工具协助完成,视觉定位则使用目标检测工具实现。
- 自我反思模块(Self Reflection)从情境库中的最后一段视频中提取部分游戏截图作为输入,以评估上一次执行的动作是否成功产生正确效果,以及当前任务是否完成。如果执行失败,该模块需要提供失败原因,以指导下一步动作生成。
- 任务推断模块(Task Inference)基于前述模块的结果推断需要执行的当前任务,并生成任务描述。
- 技能管理模块(Skill Curation)计算任务描述的嵌入与动作库中文本注释嵌入的相似度,以寻找匹配的动作,构成候选动作集。
- 决策模块(Decision Making)利用思维链(Chain of Thought,CoT)[28] 方法,逐步推理并深入分析多个连续问题(例如是否需要进入战斗模式、恢复生命值或选择可用的技能等)。最终,该模块从候选动作集中推断出最适合的动作,执行对应的 Python 代码,并通过键盘和鼠标控制玩家角色完成任务。这五个基础模块将每个中间产物记录到情境库中。
2.2.2 自我优化动作生成模块
基础 VLM 组只能从预定义动作库或带有明确文本提示的游戏截图中获取动作。对于 ARPG 中某些文本指导较弱的任务(如实时战斗),这种方法难以学习新动作。因此,我们提出了一种自我优化动作生成模块(self-optimizable action generation module,SOAG),允许 VARP 智能体在战斗中总结敌人的动作,从而优化现有动作并生成新的动作以应对敌人攻击。新动作是两种原子指令(闪避和轻攻击)的组合,优化目标是最大化敌人攻击的躲避率和攻击敌人的能力,同时最小化玩家角色的生命值损失。
具体来说,SOAG 模块中引入了一个动作函数生成组件。该组件以信息收集和自我反思的结果,以及当前和上一帧游戏截图为输入,分析当前任务下敌人的特征(如名称、外观、武器等)。最重要的是,它需要分析敌人的当前和历史动作。例如,对于名为 “牛头护卫” 的强敌,其攻击动作大致可分为:“挥斧向前冲刺” 和 “三连下劈” 等。因此,该组件需要根据敌人当前的动作推理新的闪避和反击动作。例如,针对 “挥斧向前冲刺”,新动作应为闪避一次后连续攻击;而对于 “三连下劈”,新动作应为连续闪避三次后反击。
生成的新动作是原子操作 “闪避” 和 “轻攻击” 的排列组合。这些生成的动作将带有详细文本注释存储在动作库中。
2.2.3 可分解任务专用辅助模块
在 ARPG 游戏(尤其是《黑神话:悟空》中),VLM 推理涉及大量的标记(tokens),包括多张图片和长文本。VLM 的注意力机制会对长文本中的所有标记分配注意力,但随着输入长度的增加,注意力分布会变得越来越分散。在基础 VLM 组中,由于每个模块的输入标记过多,模型可能无法有效聚焦关键信息,导致遗忘和幻觉等错误。这一问题在决策模块中尤为明显,当 VLM 需要回答多个问题时,错误率会显著上升。
为了解决这一问题,我们将基础模块进行分解,并为特定任务增加了多个并行辅助子模块,最后由 VLM 整合这些子模块的输出。其结构类似于多层感知机(MLP)。具体而言,如图 1 所示的动作规划工作流,我们将原本处理多个任务的决策模块分解为以下 5 个子模块:
- 敌人子模块:用于分析敌人的状态(如生命值、位置等)和动作描述,帮助智能体获取敌人的详细信息。
- 战斗子模块:通过观察游戏屏幕右下角的重击状态,决定使用哪种战斗方式(如轻攻击或重攻击)。
- 生命值子模块:负责持续监控玩家的生命值条。如果生命值消耗过多,它会优先指导智能体执行恢复生命值的动作。
- 技能子模块:监控玩家法术技能的状态,同时分析战斗状态,决定在适当的时机使用可用的法术技能。
- 整合子模块:负责整合所有子模块的输出,推理出当前特定任务下的最佳动作,从候选动作集中选出并执行。
可分解任务专用辅助模块通过分解长标记并聚焦于每个单独问题,显著提高了决策模块的准确性。
2.3 人类引导轨迹系统
人类操作被视为宝贵的数据,蕴含了隐含的物理和游戏世界知识,可以用于生成复杂任务(如路径查找任务和高难度战斗任务)的高级动作组合。为了从这些隐含数据中学习人类经验,我们首先收集了一个人类数据集,并利用该数据集提升 VARP 智能体的性能。
数据收集过程(详见 3.1 节)包括记录鼠标键盘日志和游戏截图。在本节中,我们重点介绍如何利用该数据集实现人类引导轨迹系统。我们将带有注释的数据集称为人类引导库(human-guided library),它由游戏截图和人类操作组成,每对数据都有唯一的时间戳。
对于游戏中的高难度任务,我们首先截取当前游戏界面的截图。基于该截图,我们在人类引导库中查询最相似的截图。随后,我们将该截图及其后续的 n 帧截图和对应的操作输入到人类引导轨迹系统中。
该系统利用 VLM 分析并总结输入的图像和操作,最终输出一个新的人类引导动作。这个新动作将存储在动作库中,供动作规划系统选择和执行。
3. 实验
3.1 数据集收集
我们收集了一个人类操作数据集,包括鼠标和键盘日志以及游戏截图的记录。具体而言,我们招募了 200 名志愿者参与 BMW 游戏的游玩并记录他们的操作,其中约 70% 的志愿者是首次体验该游戏。
为确保数据集的质量,我们剔除了未完成任务的无效数据以及标注过程中存在冗余操作(如过多的鼠标点击和滚动)的数据。因此,部分志愿者会被要求重新玩游戏以确定最佳操作,这些优化后的数据将被标记为 “清洁数据”,并在我们发布的数据集中提供更多详情,请参见补充材料。

3.2 基准测试与任务定义
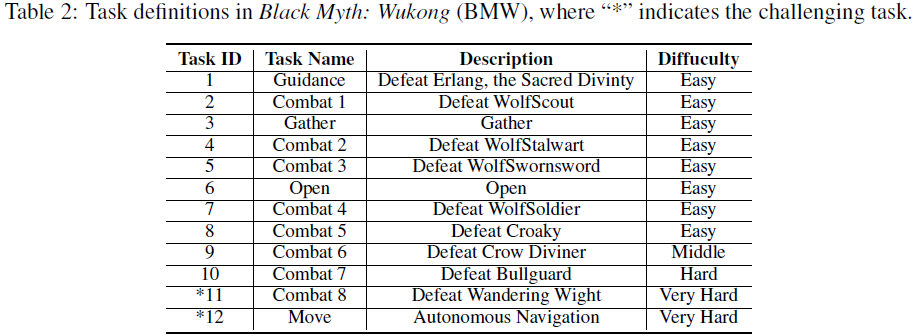
为研究现有 VLM 在动作游戏中的能力,我们定义了 10 个基础任务和 2 个具有挑战性的任务,这些任务与游戏叙事一致,其中 75% 的任务发生在战斗场景中。如表 2 和图 2 所示,所有任务均集中在游戏的第一章,这是因为 VLM 在理解和推理能力上的限制。
在基准测试(Benchmark)方面,我们允许智能体测试每个任务 5 次,并计算每个任务的成功率。对于战斗任务,如果玩家角色击败敌人,则任务成功;如果玩家角色被敌人击败并杀死,则任务失败。我们手动评估了 12 个任务的难度,并将其划分为简单、中等、困难和非常困难。由于 BMW 游戏中缺少地图和指引,并且存在大量 “隐形墙”,我们将任务 12(即在 5 分钟内从出生点移动到牛头护卫位置的自主导航任务)分类为非常困难。这对于人类新手而言也是一项极具挑战性的任务。我们利用此基准的成功率来评估 VARP 代理和各种 VLM 的性能。
3.3 实现细节
所有评估均在运行 Windows 操作系统且配备 NVIDIA RTX 4090 GPU 的机器上完成。我们使用了三种最流行的 VLM来 驱动我们的代理:GPT-4o-2024-05-13 [15],Claude 3.5 Sonnet [2] 和 Gemini 1.5 pro [8]。此外,我们还使用了 OpenAI 的 textembedding-ada-002 [21] 模型为每个动作生成嵌入向量。BMW 游戏的界面尺寸设为 1920 × 1080。在 VLM 推理期间,我们通过照片模式暂停游戏。我们采用了 Grounding DINO [14] 来检测游戏截图中的人物和物体,以帮助 VLM 更好地提取有用信息。
3.4 性能评估
为了评估 VARP 智能体在没有人为指导下的性能,我们在禁用 VARP 智能体的人类引导轨迹系统的情况下,对所提出的基准进行了实验。在本次性能评估中,我们仅测试了基准任务,并将 VARP 智能体与人类新手玩家进行了比较。
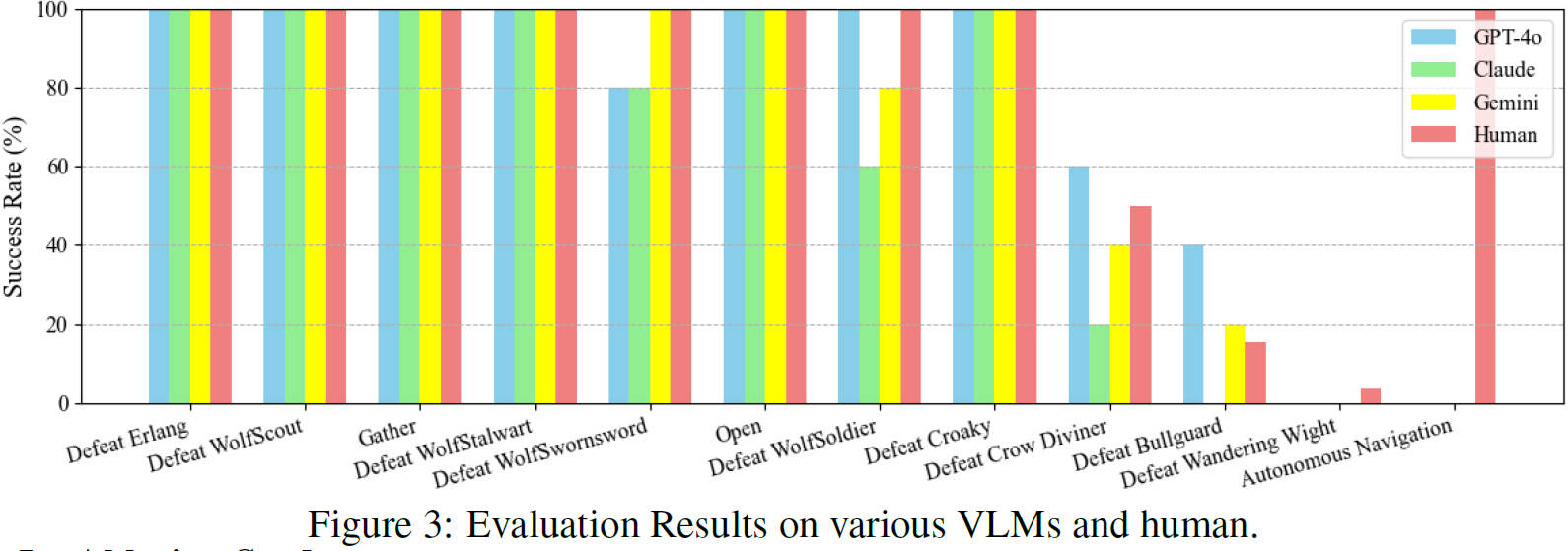
我们计算了由不同 VLM 驱动的 VARP 智能体和人类新手玩家完成各项任务的成功率。
- 如图 3 所示,VARP 智能体和人类新手玩家在任务 1 至任务 8 中均取得了较高的成功率,大多数任务的成功率接近 100%。
- 在任务 9 中,VARP 智能体的平均成功率为 40%,这一结果也证实了该任务的 “中等” 难度。
- 任务 10 的敌人是玩家在游戏中遇到的第一个 BOSS 级怪物。对于人类新手玩家,该任务的成功率为 15.63%,而 VARP 代理的平均成功率为 20%。
- 任务 11 被分类为 “非常困难”,因此人类新手和 VARP 智能体的成功率都非常低。具体来说,VARP 智能体受到 VLM 推理速度的限制,无法实时输入每一帧游戏画面,仅能以秒级间隔输入关键帧。在 ARPG 游戏中,这很容易导致错过敌人攻击的关键信息,因此任务 11 对代理而言特别具有挑战性。
- 在任务 12 自主导航任务中,人类可以轻松在五分钟内找到关卡中的最终 BOSS 敌人,但对于 VLM 来说,这几乎是不可能完成的任务。在没有人类指导的情况下,成功率为 0%。由于游戏在导航任务中不提供任何指引或提示,并且存在许多 “隐形墙”,VLM 在没有人类协助的情况下,缺乏感知 3D 场景中正确路径的能力。
综上所述,VARP 智能体在任务 1 至任务 11 中的表现已接近于人类新手玩家。然而,在 3D 场景感知和先验知识方面,VARP 智能体仍远远落后于人类。
3.5 消融实验
为了评估自优化动作生成模块(self-optimizable action generation module,SOAG)和可分解任务特定辅助模块(decomposable task-specific auxiliary module,DTSA)在动作规划系统中的有效性,我们分别去除这些模块进行实验,并计算基准任务的成功率。本部分实验中使用的 VLM 为GPT-4o-2024-05-13。
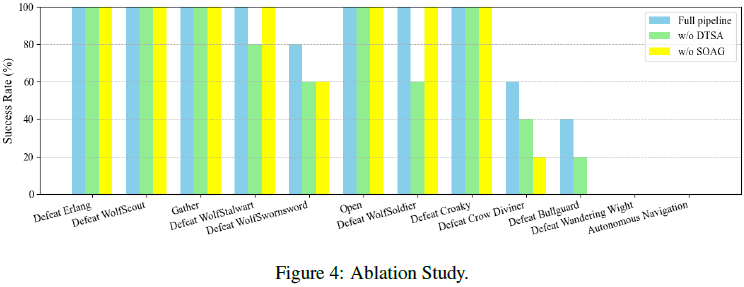
如图 4 所示,在没有 SOAG 的情况下,智能体在中等和困难任务中的性能显著下降。这是因为这些任务中的敌人具有较高的生命值,导致战斗时间延长。SOAG 的功能是持续学习敌人的攻击模式,从而帮助玩家躲避攻击并进行反击。因此,在中等和困难任务等长时间任务中,SOAG 的有效性尤为明显。
另一方面,DTSA 旨在将大型任务分解为较小的子任务,更加注重精准性。这种方法可以防止因局部问题(如 VLM 的遗忘和幻觉)导致的全局错误。因此,没有 DTSA 时,代理在一些简单任务中容易失败。
3.6 案例研究
对于 VARP 代理,新生成的动作主要来源于两个部分:一是人类引导的轨迹系统,二是动作规划系统中的 SOAG 模块。接下来,我们将分析一些新生成动作的案例。
为验证人类引导轨迹系统的有效性,我们引入了人类指导并对难度极高的任务 12 进行了案例研究。任务目标是让 VARP 代理控制玩家角色从 “土地庙” 出生点移动到敌人 “牛头护卫” 的位置,且时间限制为 5 分钟。实验中选择 GPT-4o 作为 VLM。实验结果显示,成功率达到了 40%。这表明人类指导显著提升了代理的决策准确性。
图 5 展示了人类引导轨迹系统在执行任务 12 期间为路径规划生成的新动作。此外,图 5 还显示了 SOAG 模块在任务 10 中对敌人 “牛头护卫” 生成的新动作。敌人的当前动作显示即将发动攻击:“连续三次向下挥动斧头”。因此,新生成的动作应该是连续躲避三次以上,然后进行反击。

4. 结论
在本研究中,我们探讨了当前视觉语言模型(VLMs)在复杂动作角色扮演游戏(ARPGs)中的应用边界,并以《黑神话:悟空》(BMW)作为实验平台。我们提出的框架 VARP,通过利用仅基于视觉的输入进行动作规划,提出了一种全新的游戏互动方法。VARP 框架在基本和中等难度的战斗场景中取得了 90% 的成功率,展示了 VLM 在传统上由强化学习主导的任务中也能有效应用。我们提出的基准测试能够有效评估视觉驱动代理在 BMW 游戏中的表现。此外,我们提供的人类操作数据集为未来的研究提供了宝贵的资源,支持在视觉复杂环境中研究类人游戏玩法和动作决策过程。我们的研究结果凸显了多模态智能体在增强游戏中动作任务的泛化能力和性能方面的潜力。展望未来,基于本研究获得的见解,可能为设计更加复杂的代理系统铺平道路,使其能够应对更广泛的 ARPG 及其他领域中的挑战。
论文地址:https://arxiv.org/abs/2409.12889
项目页面:https://varp-agent.github.io/
公和众人号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
加 VX 群请备注学校 / 单位 + 研究方向
CV 进计算机视觉群
KAN 进 KAN 群


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









