







Dynamic Prompting of Frozen Text-to-Image Diffusion Models for Panoptic Narrative Grounding

目录
Dynamic Prompting of Frozen Text-to-Image Diffusion Models for Panoptic Narrative Grounding
0. 摘要
全景叙事接地 (Panoptic Narrative Grounding, PNG) 的核心目标是实现精细的图文对齐,即根据叙述性标题生成目标对象的全景分割。
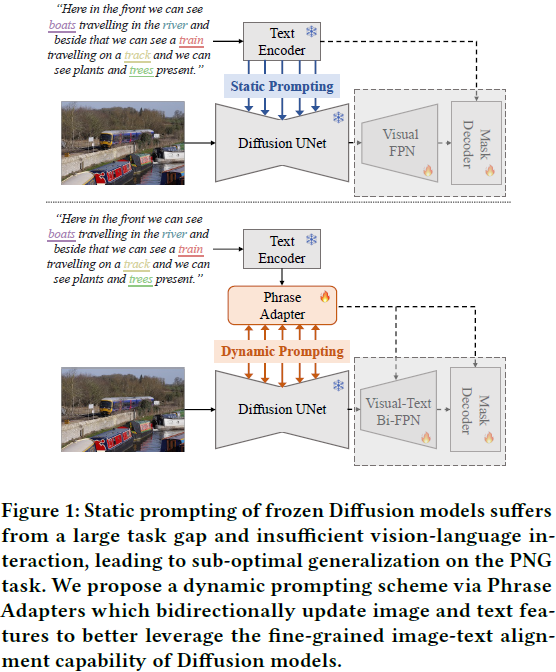
此前的判别方法通过全景分割预训练或 CLIP 模型适配,仅能实现弱或粗粒度的对齐。随着文本生成图像扩散模型的最新进展,一些研究表明,这些模型通过交叉注意力图能够实现精细的图文对齐,并提升分割性能。然而,直接使用短语特征作为静态提示(prompts)来将冻结的扩散模型应用于 PNG 任务,仍存在任务差距大和视图-语言交互不足的问题,导致性能较差。
因此,我们提出了一种提取-注入短语适配器(Extractive-Injective Phrase Adapter, EIPA),它在扩散 UNet 中引入旁路动态更新短语提示,结合图像特征并将多模态线索注入回模型中,从而更充分地利用扩散模型的精细图文对齐能力。此外,我们设计了多层次互聚(Multi-Level Mutual Aggregation, MLMA),以融合多层次的图像和短语特征,进一步优化分割效果。大量的实验表明,我们的方法在 PNG 基准上达到了新的性能水平。
2. 相关工作
2.1 全景叙事接地(PNG)
- 全景叙述定位(PNG)的任务首次由 [8] 提出,并伴随一个基准测试和一个两阶段基线模型,该模型通过短语与离线生成的掩码之间的匹配进行操作。他们进一步设计了更新的基线模型PiGLET [9],其中使用了 MaskFormer [2] 的掩码嵌入。
- PPMN [5] 和 EPNG [36] 提出了一阶段的端到端模型,直接为每个名词短语找到匹配的像素,而不依赖于离线提案,从而在性能和速度上都有提升。
- DRMN [21] 利用可变形注意力迭代地采样多尺度像素上下文以更新特征,并缓解短语到像素的匹配问题。
- PPO-TD [13] 进一步在一阶段模型中引入了基于对象的上下文建模和对比学习,通过耦合对象和像素上下文增强短语特征的判别能力,从而显著提高性能。
在本文中,我们提出了一种与以往方法显著不同的新流程,该流程通过动态更新的短语提示适配冻结的文本到图像扩散模型,从而充分利用其强大的细粒度图文对齐能力。
2.2 指代表达分割(RES)
指代表达分割(Referring Expression Segmentation,RES)[11] 的目标是对单句主语指定的特定对象进行分割。
- 早期基于 FCN 的方法 [25] 通过多样的注意力机制 [6, 7, 12, 14, 16, 23] 进行多模态特征融合。
- 一些基于 Transformer 的方法 [34] 主要探索语言query的动态更新 [4, 45]、多模态融合位置 [15, 44] 以及主干网络中的自适应前景分类 [18]。
- PolyFormer [22] 将目标分割表示为连续多边形生成问题。
- CRIS [40] 通过完全微调判别性的 CLIP 模型以利用其多模态预训练知识。
- BarLeRIa [39] 提出了一种双向交织的视觉语言高效调优框架用于 RES。
相比之下,我们的方法通过适配冻结的文本到图像扩散模型,将其生成预训练知识转移到 PNG 任务,该任务需要定位多个短语而不是单一的句子。
3. 方法
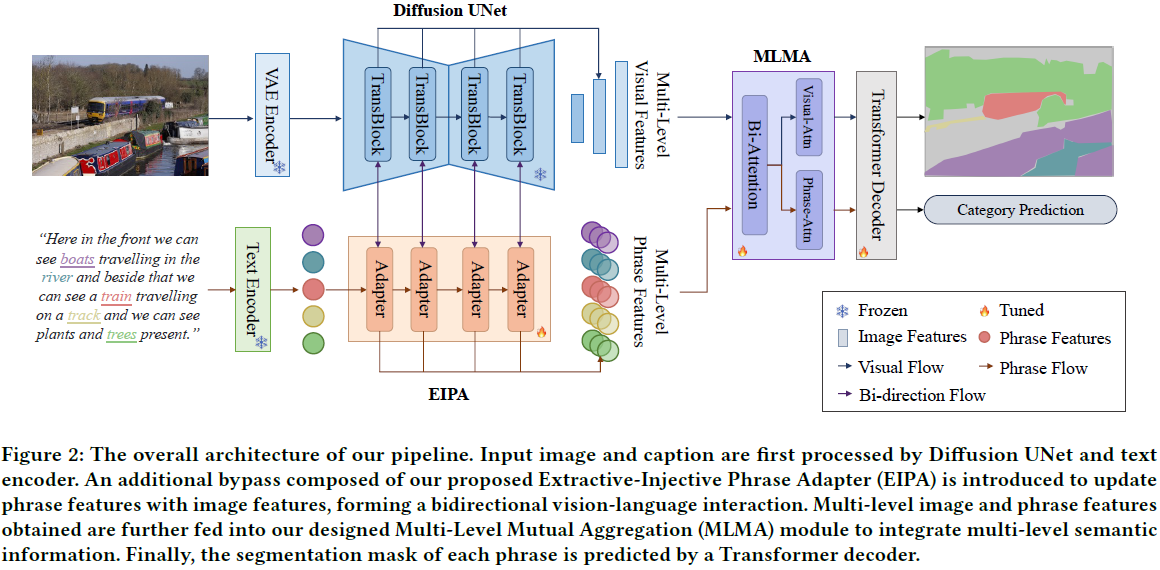
我们的总体架构如图 2 所示。
- 输入的图像和叙述性标题(caption)分别通过 Diffusion UNet [31] 和 CLIP 文本编码器 [28] 编码,获得图像和短语特征。
- 为了充分利用文本到图像扩散模型的细粒度图文对齐能力,我们提出了抽取-注入短语适配器(Extractive-Injective Phrase Adapter, EIPA),该适配器在 Diffusion UNet 旁并行设置了一个额外的适配器旁路,用于通过图像特征更新短语特征。
- 更新后的短语特征作为动态文本提示输入扩散模型,以获得更好对齐的图像和短语特征,从而将生成预训练知识转移到判别型 PNG 任务中。
- 这些多模态特征随后输入我们设计的多层级互聚模块(Multi-Level Mutual Aggregation, MLMA),以融合视觉和语言模态的多层语义信息。
- 最后,任务解码器基于优化后的多模态特征预测每个短语的分割掩码。
3.1 扩散模型的静态提示
我们的基线模型直接使用静态短语特征作为文本提示对冻结的文本到图像扩散模型进行提示操作。具体来说,输入包括一幅图像 I ∈ R^{H^0 × W^0 × 3} 和由 M 个单词组成的叙述性标题 T。
对于输入标题,我们采用 CLIP 文本编码器 [28] 提取单词特征嵌入 R_w ∈ R^{M × C_t},并对对应的单词简单求平均以获得短语特征嵌入 R ∈ R^{N × C_t},其中 N 表示标题中的短语数量,C_t 为短语特征的通道数。
对于输入图像 I,我们首先将其送入 VAE 编码器,图像被降采样到 1/8 分辨率并拥有少量通道(如 4 个)。随后,该图像特征经过由 L 个块组成的 Diffusion UNet [32] 处理。通常,每个 UNet 块包含一个残差卷积块(ResBlock)[10]、一个 Transformer 块(TransBlock)[34] 以及可选的上采样或下采样块。为简化表示,我们选择 UNet 核心操作(ResBlock 和 TransBlock)来表示第 l 层 UNet 块,省略其他细节:
![]()
![]()
其中,F^(l−1) 和 F^(l) 分别表示第 l 层 UNet 块的输入和输出图像特征。
UNet 块的内部操作公式如下:
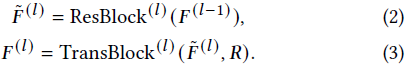
Transformer 块的核心操作是交叉注意力层 [34],其中图像特征作为 query,短语特征作为 key 和 value。其通用公式为:
![]()
将其具体化为图像和短语特征:
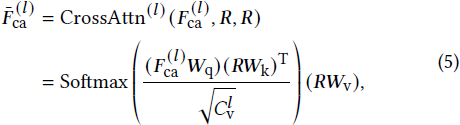
其中,F^(l)_ca 和 ˉF(l)_ca 分别表示交叉注意力层的输入和输出图像特征。在静态提示(Static Prompting)中,我们利用 UNet 中 query 和 key 之间的交叉注意力图来获得每个短语的最终分割掩码预测,这一模块被称为扩散掩码头(Diffusion Mask Head)。
对于生成任务,一个噪声预测器通常被用来估计特定时间步长下的潜在噪声(latent noise)。而在我们的判别型 PNG 任务中,我们移除了噪声预测器,并将时间步长设置为 1,以避免进一步的信息丢失。
3.2 动态提示与提取-注入短语适配器(EIPA)
之前的静态提示可以看作是以零样本的方式将扩散模型直接应用于 PNG 任务。然而,扩散模型的预训练任务与 PNG 模型的下游任务之间存在显著差距,在不引入任何可学习参数到扩散主干网络的情况下,难以将扩散模型的生成知识迁移到判别性的 PNG 任务中。此外,在扩散模型中,信息仅从语言领域单向流向图像领域,导致在 PNG 任务中图像只能捕捉模糊的语言概念,从而限制了知识迁移的有效性。因此,我们提出了一种提取-注入短语适配器(Extractive-Injective Phrase Adapter,EIPA),通过利用图像特征更新短语特征,填补从视觉领域到语言领域的信息流。我们的 EIPA 通过动态更新文本提示,充分利用了文本到图像扩散模型的细粒度图文对齐能力。
具体而言,我们在第 l 层 UNet 块中引入短语适配器,为 UNet 构建一个并行的旁路。由于 UNet 块与短语适配器之间的视觉-语言交互是双向的,它们的输入和输出相互依赖,可以表示为:
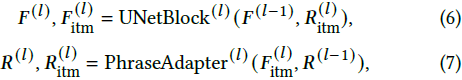
其中,F^(l)_itm 和 R^(l)_itm 是 UNet 块和短语适配器中 Transformer 块的自注意力层的中间输出。通过对比方程 (1) 与方程 (6),可以观察到输入到 UNet 块的短语特征是经过迭代更新的。对于方程 (7) 中的第 l 层短语适配器,我们可以将其内部操作展开如下:
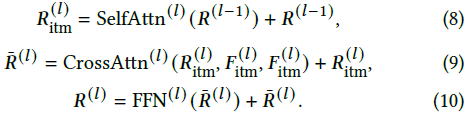
短语适配器的输入和输出特征的通道数量进行了缩放,以减少参数量,这部分细节在此省略。此外,我们利用扩散模型中的分割掩码预测(参见方程 (5) 的讨论),作为 EIPA 中短语 query 的交叉注意力层的注意力掩码。因此,每个短语的关注区域可以被限制在预测的前景区域,以根据文献 [1] 减少噪声。同时,我们将 EIPA 中所有的交叉注意力图结合起来,预测每个短语的分割掩码,这被称为适配器掩码头,提供了另一种中间监督。
第 l 层 UNet 块中 Transformer 块的内部操作可以类似于方程 (8)-(10) 进行展开,其中交叉注意力层使用 F^(l)_itm 作为 query,R^(l)_itm 作为 key 和 value。我们提出的 EIPA 的计算过程也如图 3 所示,提供了更多细节。
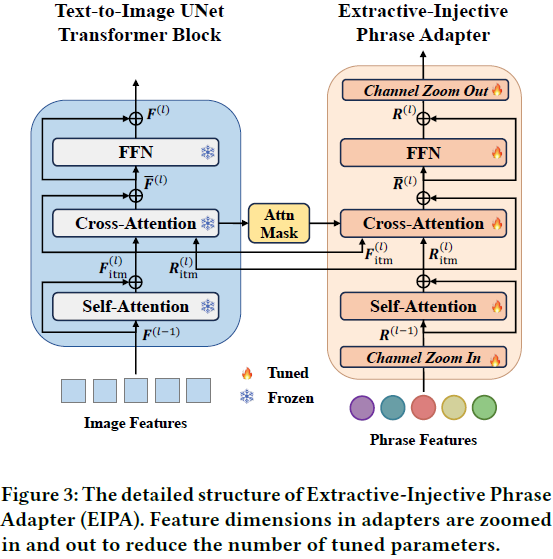
受益于双向的视觉-语言交互,我们的 EIPA 从图像特征中提取全局上下文,动态更新文本提示,然后将任务特定的多模态线索重新注入图像特征,从而实现更充分的知识迁移。
3.3 多层次互聚合(MLMA)
由于 EIPA 引入了多层次的短语特征,可以与多层次的图像特征进行聚合,以结合低层次的细节和高层次的概念,我们还提出了对它们进行聚合,以进行层间的多模态上下文建模。因此,我们设计了一个多层次互聚合(Multi-Level Mutual Aggregation,MLMA)模块,利用双向注意力 [19] 互相融合图像和短语特征的多层次信息,从而更全面地建模图像与文本的语义对应关系,以提高分割质量。
具体而言,我们从扩散 UNet 的不同块中获得三层图像特征,并将它们的特征通道投影到相同的数量,表示为
![]()
![]()
{F_i}^5_{i=3} 的分辨率分别是输入图像的 1/8、1/16和 1/32。相应地,我们从 EIPA 的不同块中获得多层次短语特征
![]()
这些特征包含与相应图像特征层次相关的语义信息。
与交叉注意力不同,双向注意力 [19] 先计算一次注意力图,并分别在像素数或短语数维度上应用 Softmax 归一化,然后与图像或短语特征相乘进行双向融合。我们的 MLMA 利用 {R_i}^5_{i=3} 在短语数维度上的拼接作为 query,并将 {F_i}^5_{i=3} 在像素数维度上的拼接作为 key 来计算双向注意力图。value 是 {R_i}^5_{i=3} 或 {F_i}^5_{i=3} 的拼接,分别用于两个方向的多层次信息聚合。
双向注意力后,我们将多层次图像特征输入到可变形注意力层(deformable attention layer) [48] 中,将多层次短语特征输入到自注意力层中进行模态内细化。
此外,UNet 之后的图像特征输入到 VAE 解码器中,以获得原始图像 1/4 分辨率的特征 ^F_2。我们 MLMA 输出的 1/8 分辨率图像特征 ^F_3 进一步上采样并与 ^F_2 融合,得到最终的掩码特征 F_m。我们 MLMA 的最后一层输出的短语特征 ^R_5 和多层次图像特征 {^F_i}^5_{i=3} 进一步输入到 Transformer 解码器 [1] 中,生成最终的短语 query。每个短语的分割掩码是通过每个短语 query 和掩码特征 F_m 之间的矩阵乘法来预测的,这被称为解码器掩码头(decoder mask head),提供最终的监督。
3.4 损失函数
如前所述,我们的模型包含三个掩码头用于损失监督。扩散掩码头(mask heads)通过加权求和融合所有 UNet 块中经过 Softmax(方程(5))的交叉注意力图,得到预测的分割掩码 Y^dif ∈ R^{N × H_0 × W_0}。给定真实的分割掩码 Y* ∈ R^{N × H_0 × W_0},我们在 Y^dif 和 Y* 之间应用交叉熵(CE)损失:
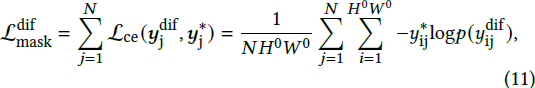
其中,y^dif_j ∈ R^{H_0 × W_0} 和 y*_j ∈ R^{H_0 × W_0} 分别是扩散掩码头的分割预测和每个短语的真实分割。对于适配器掩码头和解码器掩码头,我们采用 Mask2Former [1] 中的掩码分类损失:
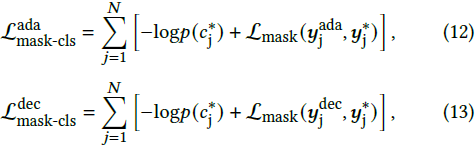
其中,c*j 是每个短语的真实类别,用于利用短语中的类别先验,L_mask 是二进制交叉熵损失和Dice 损失 [33] 的组合。我们在每个 EIPA 的短语适配器块中应用 L^ada_{mask-cls}。然后,我们的模型的总损失被计算为上述三个单独损失的总和:
![]()
4. 实验
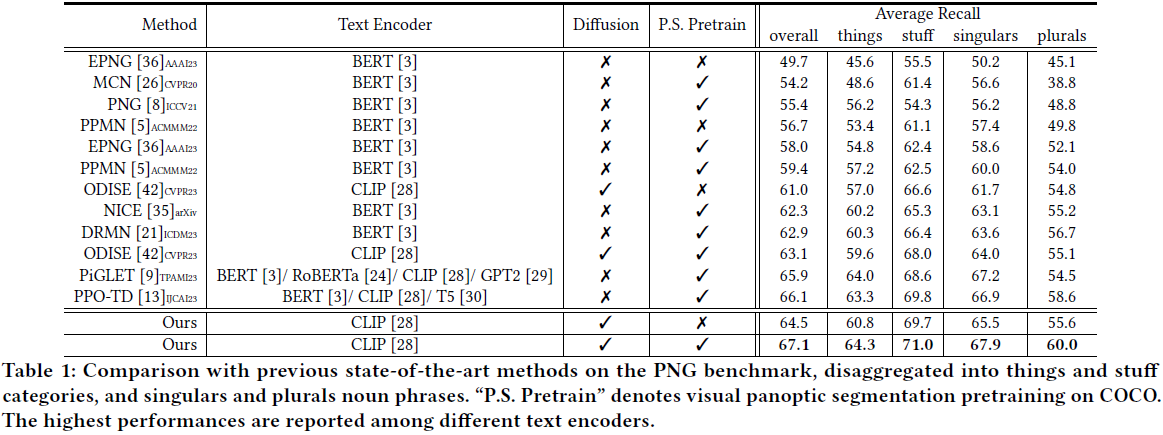
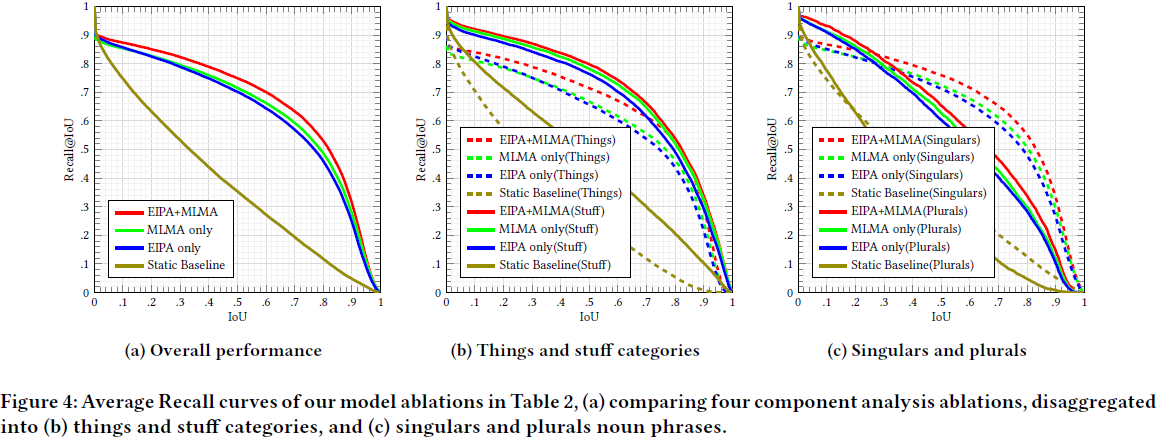
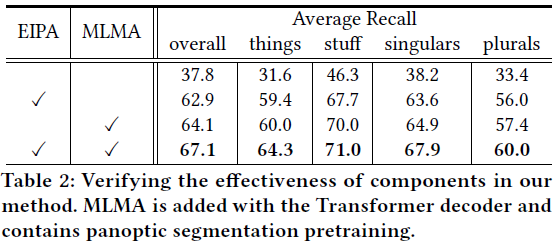
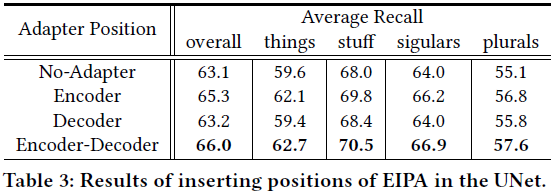
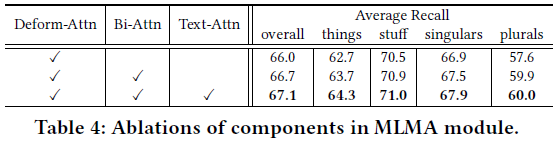

5. 结论
我们研究了 PNG 任务,在该任务中,之前的判别性方法仅通过全景分割预训练或适配 CLIP 模型实现了弱或粗糙的对齐。近年来,许多研究已证明文本到图像的扩散模型在实现精细化图像-文本对齐方面的成功。然而,使用固定短语特征的扩散模型静态提示在适应 PNG 任务时仍然存在较大的任务差距和不足的视觉-语言交互。因此,我们提出了一个 EIPA 旁路,通过图像特征动态更新短语提示并将多模态线索重新注入,从而实现更充分的精细化图像-文本对齐。我们还开发了一个 MLMA 模块,通过多层次特征的互相融合来细化分割质量。我们的方法在 PNG 基准上取得了最先进的性能。
论文地址:https://arxiv.org/abs/2409.08251
进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群
加 VX 群请备注学校 / 单位 + 研究方向
CV 进计算机视觉群
KAN 进 KAN 群


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









