







Seedream 3.0 Technical Report
目录
1. 引言
(2025|字节,ByT5,DiT,LLM,SFT,RLHF,RoPE)Seedream 2.0:中英双语图像生成基础模型
Seedream 3.0 是一个中英双语图像生成基础模型,相较于 Seedream 2.0,解决了以下关键挑战:
-
提示词对齐不足,特别是数字精度与多物体空间关系;
-
字体排版能力有限,难以生成小尺寸文字与复杂排版;
-
图像美感和保真度不足;
-
图像分辨率低,仅支持 512×512。
Seedream 3.0 采用了从数据构建到模型推理的系统性优化,包括:
-
数据量翻倍,结合图像分布与语义平衡的采样策略;
-
引入混合分辨率训练、跨模态 RoPE、表示对齐损失与分辨率感知的时间步采样;
-
使用多样化美学描述与基于 VLM 的奖励模型;
-
采用一致性噪声期望(consistent noise expectation)与重要性时间步采样(importance-aware timestep sampling)实现 4-8 倍推理加速。
模型在文本渲染、写实肖像、高分辨率输出方面表现尤为优异。
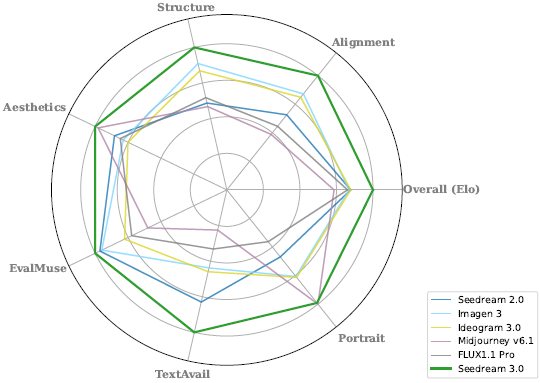
图 1:Seedream 3.0 在各项评估维度中均表现优异。
- 由于数据缺失,Imagen 3 的人像生成结果和 Seedream 2.0 的整体评分使用了其他模型的平均值进行替代。
- 此外,在 Artificial Analysis 图文生成模型排行榜上,Seedream 3.0 以 17,000 次曝光时的 Arena ELO 评分 1158 位列第一。

2. 技术细节
2.1 数据
在 Seedream 2.0 中,采用严格的数据过滤策略,排除带有水印、叠加文字、字幕(captions)、马赛克等轻微缺陷的图像数据。由于这些问题样本在原始数据集中占比高达约 35%,这一策略显著限制了可用训练数据的规模。
为解决这一问题,Seedream 3.0 引入了创新的缺陷感知(defect-aware)训练范式:
-
训练一个缺陷检测器(基于 15,000 个由主动学习(active learning)引擎筛选并人工标注的样本),通过边界框定位图像中的缺陷区域;
-
若缺陷区域占图像总面积不足 20%(该阈值可调),则保留此样本,并在潜空间中进行掩码(mask)优化;
-
在扩散损失计算时使用空间注意掩码(spatial attention mask),排除缺陷区域的特征梯度,从而在保持模型稳定性的前提下,扩充有效训练数据约 21.7%。
此外,Seedream 3.0 采用了双轴协同(dual-axis collaborative)数据采样框架,从视觉形态与语义分布两个维度优化数据选择:
-
视觉维度:继续使用分层聚类方法,确保不同视觉模式(patterns)的均衡分布;
-
语义维度:利用词频-逆文档频率(term frequency and inverse document frequency,TF-IDF)策略平衡描述文本,缓解长尾语义问题。
同时,引入了跨模态检索系统建立图文联合嵌入空间,并通过以下机制进一步动态优化数据:
- 通过概念检索注入专家知识;
- 利用相似度加权采样实现分布校准;
- 使用检索得到的邻近对样本进行跨模态增强。
这些数据构建方法大幅提升了训练数据的多样性、质量与模态对齐能力。
2.2 模型预训练
2.2.1 模型架构
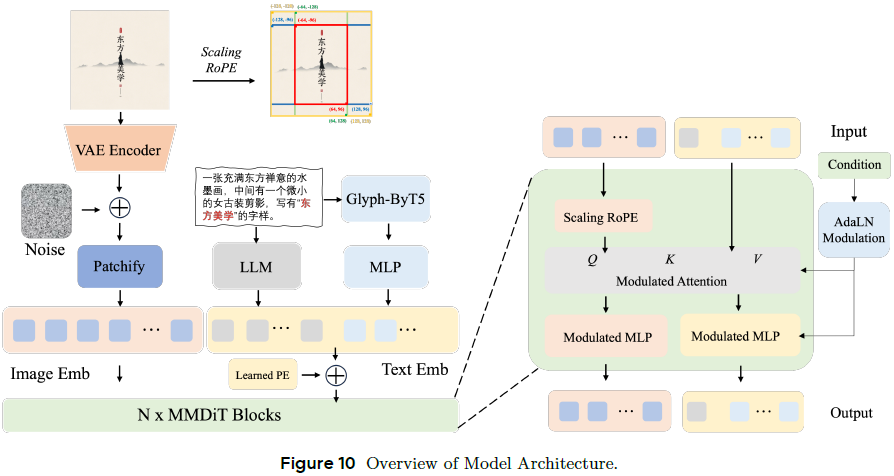
基于 Seedream 2.0 的 MMDiT 架构(如图 10 所示),在此基础上新增:
-
混合分辨率训练:预训练使用多尺寸图像(256² 到 2048²),结合尺寸嵌入(size embedding)提升泛化;
-
跨模态 RoPE(Cross-modality RoPE):与 Seedream 2.0 中使用的 Scaling RoPE 不同,跨模态 RoPE 将文本 token 视作二维嵌入,与图像 token 合并位置编码,提升模态对齐与文本渲染能力。
2.2.2 模型训练细节
采用流匹配损失(Flow Matching)结合表示对齐损失(representation alignment,REPA),后者基于 DINOv2-L 计算余弦相似度;
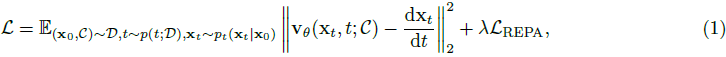
![]()
提出分辨率感知的时间步采样(Resolution-aware Timestep Sampling)策略:当在高分辨率训练时,偏移(shift)分布以增加在低 SNR 采样的概率;
- 在训练时,计算数据集 D 的平均分辨率,以确定偏移的时间步分布。
- 在推理时,根据目标分辨率和纵横比计算偏移因子。
2.3 模型后训练
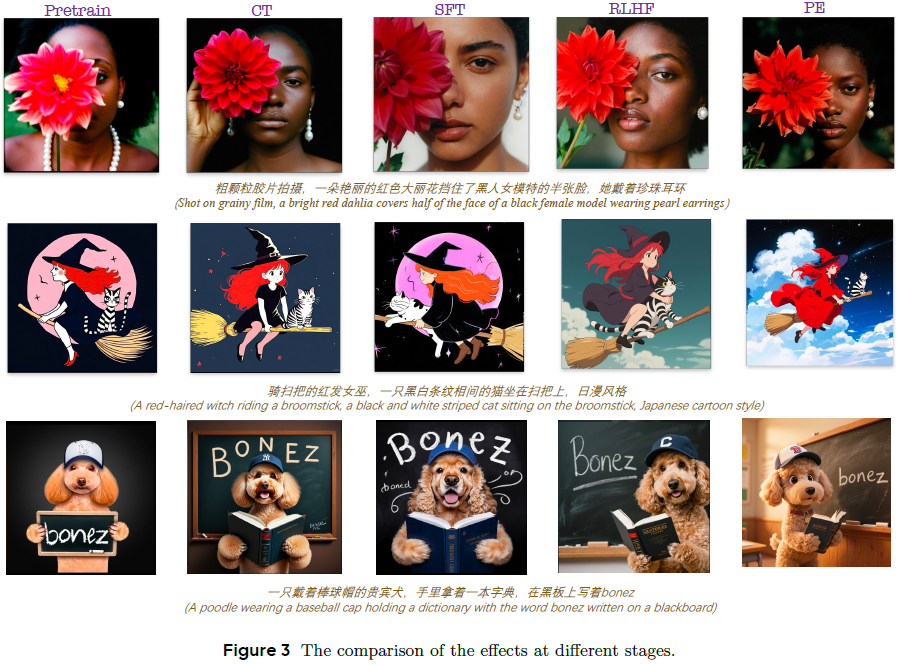
Seedream 3.0 的后训练包括四个阶段:持续训练(CT)、监督微调(SFT)、人类反馈强化学习(RLHF) 和 提示工程(PE),不再使用 Refiner 阶段,因模型已支持原生高分辨率生成(512²–2048²)。

2.3.1 美学注释
专门为 CT 和 SFT 阶段的数据训练了多个版本的描述生成模型。
如图 4 所示,这些模型能够在美学、风格和布局等专业领域提供准确描述,从而使主模型能更有效地响应相关提示,提升模型的可控性及其在提示工程后的表现。
2.3.2 模型训练细节
为确保模型在不同分辨率下均有良好表现,在训练过程中对数据应用了分辨率均衡(resolution balancing)策略。该策略保证了不同分辨率下的训练样本数量充足,从而提升了模型在多种场景中对提示词的响应能力。
2.3.3 奖励模型扩展
使用多尺寸 VLM 作为奖励模型,借助 LLM 的指令问答范式计算 “是” 响应的概率评分,并首次引入奖励模型的参数扩展(从 1B 到 20B+),实现显著性能提升。
2.4 模型加速
提出自适应生成轨迹(adaptive generative trajectory)替代传统高斯扩散路径,显著减少生成步骤,同时保持高质量输出:
- 一致性噪声期望(Consistent Noise Expectation):利用预训练模型估计统一噪声期望向量,作为所有时间步的参考,提升采样稳定性,减少图像失真,实现更少步数下的高质量生成。
- 重要时间步学习(Learning to Sample Important Timesteps):不再均匀采样时间步,而是通过 Stochastic Stein Discrepancy(SSD)结合神经网络,动态预测最关键的时间索引,聚焦有效训练阶段,提升收敛速度并降低计算开销。
整体框架支持少步高效采样,可在远低于 50 步的情况下生成媲美基线的图像质量,在美学、结构和文本对齐方面均表现优秀。其他加速手段(如量化)继承自 Seedream 2.0。
3. 模型性能
3.1 Artificial Analysis 排行
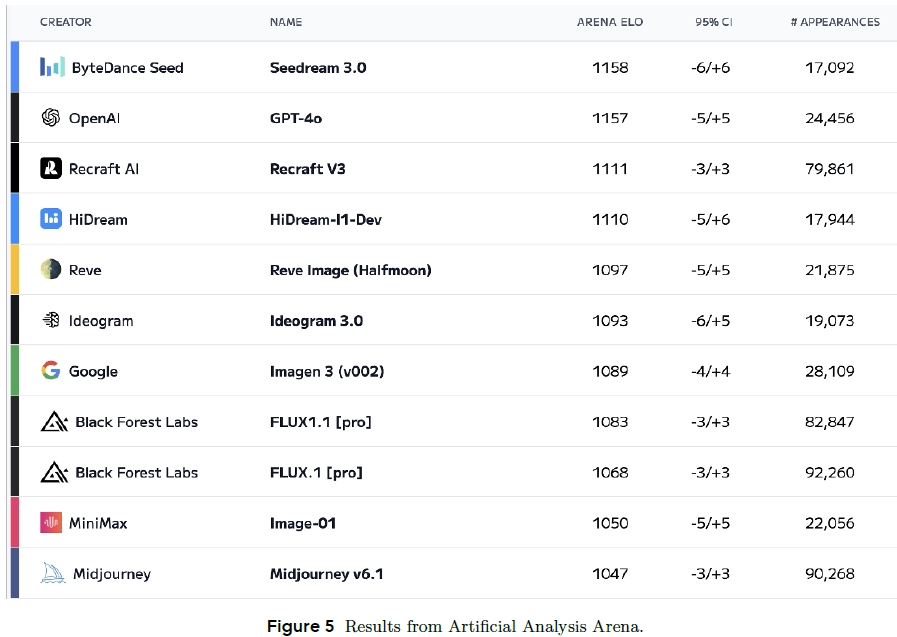
Seedream 3.0 在主流排行榜(如 Artificial Analysis)中领先 GPT-4o、Midjourney v6.1 等所有主流模型,在风格(写实、二次元、传统艺术)与主体(Subject,人物、幻想、空间等)类别均占据榜首。
3.2 综合评估
3.2.1 人类评估
构建 Bench-377 提示集,涵盖电影、艺术、娱乐、美学设计、实用设计五大场景。
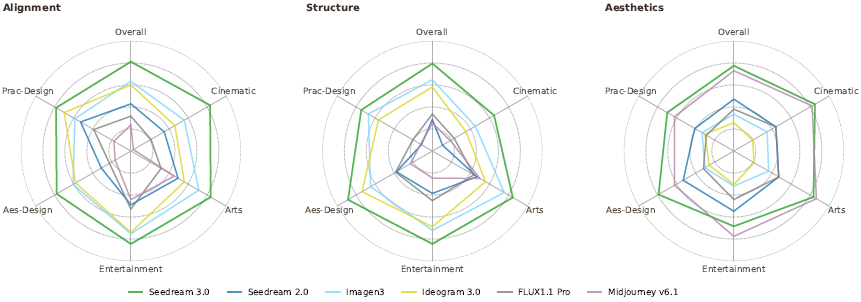



Seedream 3.0 在文本对齐、结构合理性和美学得分方面全面领先,特别在 “设计” 类应用中超越 Midjourney。
3.2.2 自动评估
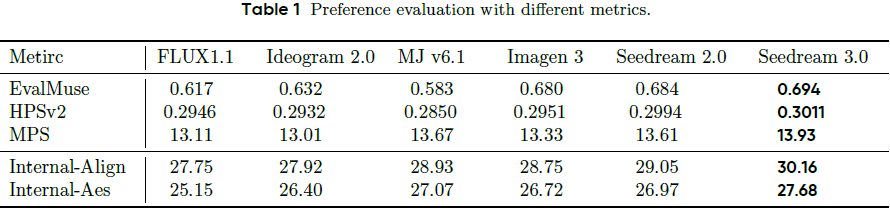
在文本对齐与图像质量方面全面领先:
-
文本对齐 EvalMuse 指标最高;
-
HPSv2 超过 0.3,首次达成人类偏好一致性高标准;
-
MPS、美学评分全面胜过 Midjourney 与 Seedream 2.0。
3.3 文本渲染
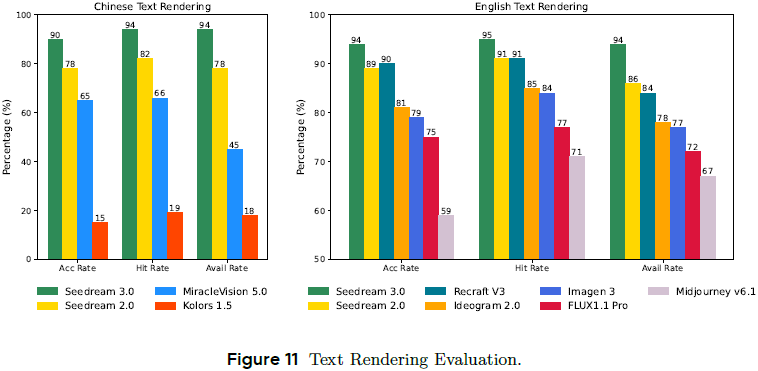
在 180 个中英文提示中,Seedream 3.0 实现:
-
中文文本可用率从 78% 提升至 94%,准确率与命中率均显著提升(定义见原论文);
-
在密集文本(如长标题、海报)渲染中表现优于 GPT-4o,特别是在排版、字体细节方面;
-
消除了图文分离或后期合成常见的排版错误。


3.4 写实人像生成
构建 100 个提示词集,聚焦细节纹理与情感表达:
-
Seedream 3.0 与 Midjourney v6.1 并列第一;
-
支持 2048×2048 原生输出,纹理清晰,展现自然皮肤特征(毛孔、皱纹、疤痕);
-
图像真实度媲美专业摄影,具备商业应用潜力。


3.5 与 GPT-4o 的比较
3.5.1 密集文本渲染

GPT-4o 擅长英文字符与 LaTeX 渲染,但中文排版与整合不足;Seedream 3.0 在中英文混排、美学排版方面明显优于 GPT-4o。
3.5.2 图像编辑

对比 SeedEdit(Seedream 分支)与 GPT-4o:
-
GPT-4o 功能丰富但易损原图 ID;
-
SeedEdit 保持人物一致性与高图文一致性;
-
Gemini 2.0 保持像素一致但存在色彩与质量问题。

SeedEdit 继承了 Seedream 3.0 的文本处理能力,表现令人满意。
- 它能够准确识别图像中的文本,从而实现精确的删除或修改操作。同时,在添加文本时,SeedEdit 会考虑整体布局,使新文本自然融入原图。
- 相比之下,尽管 GPT-4o 也能完成文本编辑任务,但无法很好地保留原图内容,限制了其实用性。
3.5.3 生成质量

GPT-4o 图像偏黄、存在噪点;Seedream 3.0 色彩自然、清晰度高,整体生成质量更优。
4. 结论
Seedream 3.0 通过系统性技术创新,在以下方面全面领先:
-
原生支持高分辨率图像输出;
-
出色的中英文文本渲染,涵盖密集排版场景;
-
真实感强、情感丰富的人像生成能力;
-
在评测榜单中排名领先,性能全面超越 GPT-4o、Midjourney 等主流模型;
-
在 Doubao、集梦等平台落地,具备广泛生产力应用前景。
论文地址:https://arxiv.org/abs/2504.11346
项目页面:https://team.doubao.com/tech/seedream3_0
进 Q 学术交流群:922230617 或加 CV_EDPJ 进 W 交流群

















 1378
1378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









