








目录
0. 摘要
我们提出了一种简单而高效的方法——超连接(Hyper-Connections),可以作为残差连接(Residual Connections)的替代方案。该方法专门针对残差连接变体中常见的缺点进行优化,例如梯度消失与表示崩溃(representation collapse)之间的拉锯效应(seesaw effect)。从理论上讲,超连接允许网络调整不同深度特征之间连接的强度,并动态地重新排列层结构。我们在 LLM 的预训练中进行了实验,包括稠密和稀疏模型(dense and sparse),结果表明超连接相比残差连接具有显著的性能提升。此外,在视觉任务上的额外实验也展示了类似的改进效果。我们预计,这种方法将在广泛的人工智能问题中具有广泛的应用价值和益处。
1. 简介
深度学习在多个领域取得了巨大成功,其中残差连接(Residual Connections)(He等人,2016)在现代神经网络架构中发挥了关键作用,包括 Transformer 和卷积神经网络(CNNs)。残差连接有助于缓解梯度消失问题,从而实现对非常深的网络的有效训练。然而,需要认识到残差连接并非万能解决方案,其仍然存在一些未解决的局限性。
残差连接的两种主要变体——前归一化(Pre-Norm)和后归一化(Post-Norm)——在梯度消失与表示崩溃之间各自作出了不同的权衡。前归一化在每个残差块之前对输入应用归一化操作,有效缓解了梯度消失问题(Bengio等人,1994;Glorot & Bengio,2010)。然而,这种方法可能导致深层表示的崩溃问题(Liu等人,2020),即深层的隐藏特征变得高度相似,随着层数增加,额外层(additional layers)的贡献逐渐减弱。相比之下,后归一化在每个残差块输出之后应用归一化操作,削弱了残差的 “强度”。这种方法可以缓解表示崩溃问题,但同时又重新引入了梯度消失的问题。梯度消失与表示崩溃如同跷跷板的两端,这两种变体分别在这些问题之间做出了相应的取舍。核心问题在于,无论是前归一化还是后归一化,残差连接都预先定义了层内输入与输出之间连接的强度。
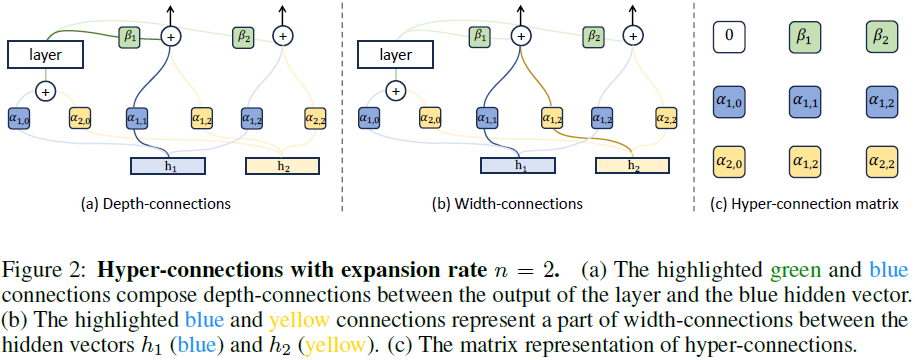
超连接(Hyper-Connections)的核心思想是提出可学习的深度连接(Depth-Connections)和宽度连接(Width-Connections),如图 2 所示。深度连接可以被视为残差连接的广义形式,为每一层的输入和输出之间的连接分配权重。为了使网络能够同时建模不同的深度连接,我们将网络的输入扩展为 n 个副本,每个副本都有其独立的深度连接(见图 2 (a))。此外,我们在 n 个隐藏向量之间建立宽度连接,实现同一层内隐藏向量之间的信息交换(见图 2 (b))。最后,我们可以将超连接形式化为一个矩阵,如图 2 (c) 所示。
研究发现,超连接不仅能够学习调整残差的强度,还可以学习重新排列层次结构(顺序或并行),如 § 3.2 中所讨论的。此外,我们引入了动态超连接(Dynamic Hyper-Connections, DHC),使网络能够根据输入动态调整连接权重。值得注意的是,尽管超连接似乎将网络的宽度扩展了 n 倍,但额外的参数和计算成本几乎可以忽略不计。

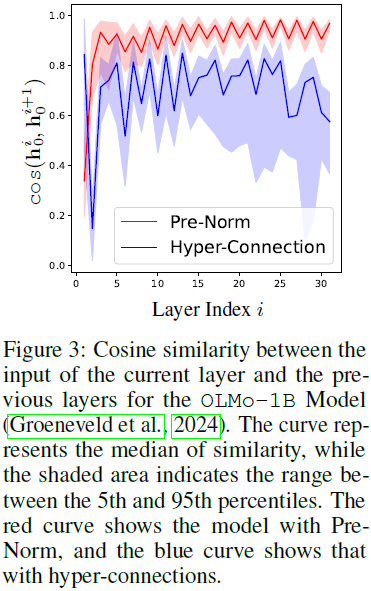
根据我们的可视化分析(如图 3 所示),基线模型倾向于出现表示崩溃的现象,其特征是相邻层之间的特征具有高度相似性。相比之下,采用超连接的模型在相邻层之间表现出显著较低的特征相似性,并具有更广泛的相似性范围。这表明超连接增强了每一层的影响力。
2. 方法
2.1 静态超连接
假设隐藏向量 h^{k−1} ∈ R^d(或 h^{k-1} ∈ R^{d x 1} )作为第 k 层的输入,网络的初始输入为 h^0。首先,将初始向量 h^0 ∈ R^d 复制 n 次,形成初始超隐藏矩阵(hyper hidden matrix) H^0 = (h^0 h^0 ⋯ h^0)^T ∈ R^{n×d}。其中,n 称为扩展率(expansion rate)。
对于第 k 层,其输入由前一层的超隐藏矩阵
![]()
构成。最终,我们对最后一层的超隐藏矩阵按行求和,得到所需的隐藏向量,并将其传递到最终投影层(如 Transformer 中的归一化层和嵌入解除层),以生成网络的最终输出。
为了简化后续分析中的符号表示,我们省略层索引,仅用 H = (h_1 h_2 ⋯ h_n)^T 表示超隐藏矩阵。
超连接可以用矩阵 HC 表示,其中每个元素定义连接权重。该矩阵的结构如下:
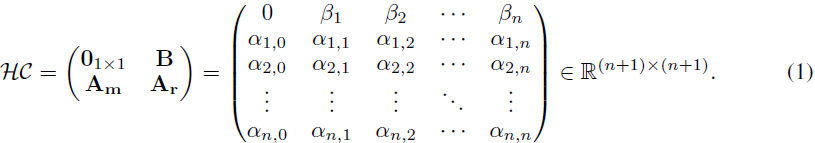
考虑一个网络层,记为 T,它将自注意力层和前馈网络集成到 Transformer 中。超连接的输出记为 ^H,可以简单地表示为:
![]()
【注:第一项表示上一层隐矩阵 H 加权(网络权重 A)后,通过本层网络,然后本层网络加权(网络权重 B)见公式(3);第二项,上一层的残差,见公式(4)】
我们使用 A_m 作为权重,对输入 H = (h_1, h_2, …, h_n)^T 进行加权求和,以获得当前层 T 的输入 h_0,其表示为:
![]()
而 A_r 用于连接 H 并将其映射为一个残差超隐藏矩阵 H′,其表示为:
![]()
随后,输出由以下公式给出:
![]()
【注:此处有误,公式(2)是正确的。T 和 h_0 是列向量,(h_0)^T 是行向量】
深度连接可以分解为以下矩阵,如图 2(a) 所示:

其中,第一行 B 表示当前层 T 输出的权重,最后一行 diag(A_r) 表示输入的权重。我们使用 diag(A_r) 来表示 A_r 对角线条目的展平向量(flatten vector)。
【注:看图中实线。h1,h2 是同一隐藏状态的不同复制体,而不是不同状态】
宽度连接矩阵的定义如下(如图 2 (b) 所示):
![]()
超连接算法的具体实现见算法 1。

2.2 动态超连接
超连接矩阵 HC 的元素可以动态依赖于输入 H。动态超连接(DHC)的矩阵表示定义如下:
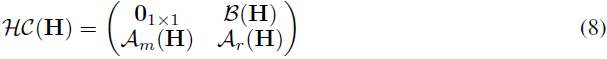
相似的,给定网络层 T 和输入 H,动态超连接的输出可以表示为:
![]()
在实践中,我们结合动态矩阵和静态矩阵来实现动态超连接。动态参数通过线性变换获得。为了稳定训练过程,在线性变换之前引入归一化操作,并在之后应用 tanh 激活函数,乘以一个小的初始可学习因子进行缩放。以下公式详细说明了这些动态参数的计算过程:
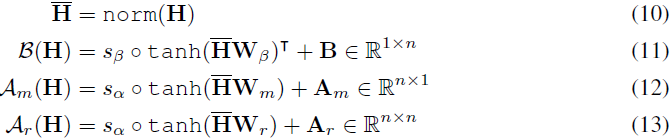
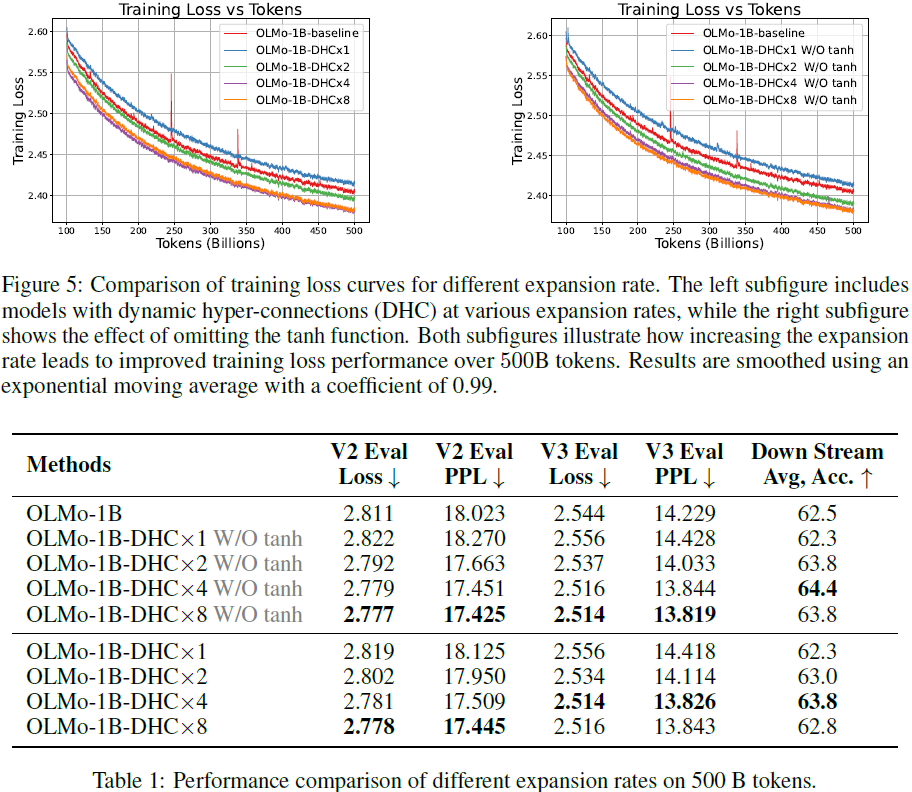
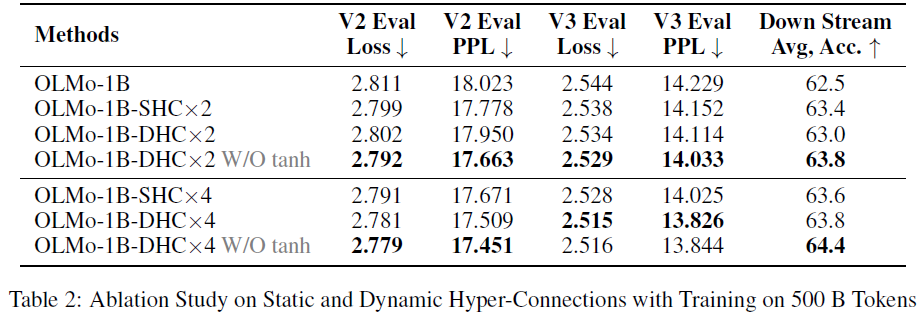
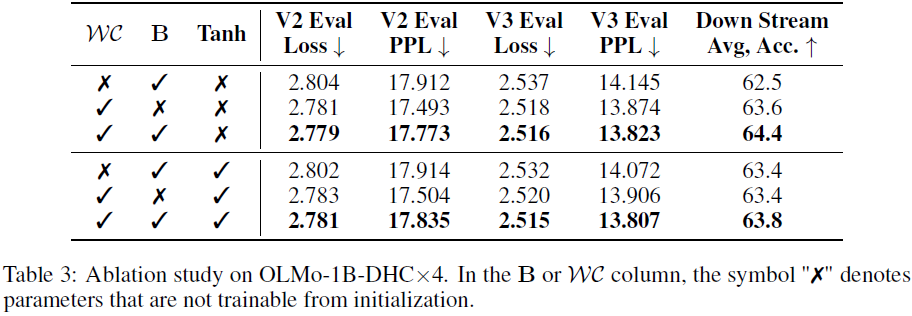
实验结果(见 §4)表明,动态超连接在语言建模任务中优于静态超连接。静态和动态超连接的 PyTorch 实现见算法 2。
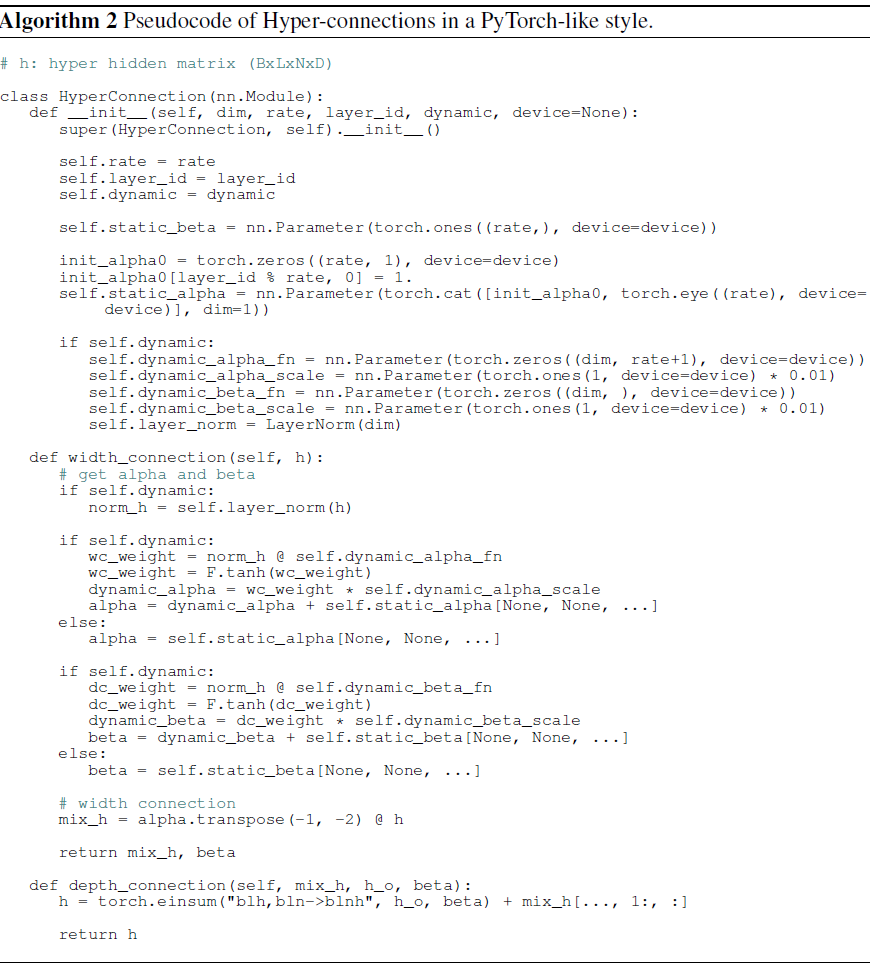
2.3 初始化
为了使超连接的初始化等价于前归一化残差连接,我们采用以下初始化策略:
在公式 (11)、(12) 和 (13) 中,动态参数 W_β, W_m, W_r 初始化为 0,而静态矩阵初始化如下:
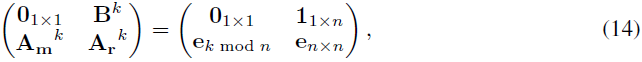
其中 k 是层的索引,mod 表示取模运算。
3. 为什么使用超连接
在本节中,我们阐明了使用超连接的理论依据。我们探讨了残差连接(residual connections)的变体——即前归一化(Pre-Norm)和后归一化(Post-Norm)——如何可以视为非可训练的超连接,并引入了 “顺序-并行二元性”(sequential-parallel duality)的概念,展示了超连接如何通过动态优化层级排列来提升网络性能。此外,§4.5 中还通过展开视角对超连接进行了可视化分析。
3.1 残差连接作为非可训练的超连接
前归一化和后归一化的残差连接可以通过如下扩展率 n=1 的超连接矩阵进行表示:
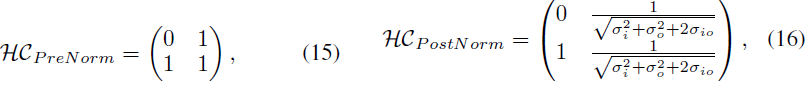
其中,σ_i 和 σ_o 分别表示神经网络层输入和输出的标准差,而 σ_{io} 表示两者之间的协方差。
对于前归一化(Pre-Norm),其超连接矩阵是一个 2×2 的矩阵,其中右下三角部分填充为 1,其余部分为占位符 0。而后归一化(Post-Norm)的权重依赖于输入和输出的方差及协方差,构成一个 2×2 的矩阵。因此,这些超连接矩阵是非可训练的。
在本研究中,我们提出了超连接,可以是 (n+1)×(n+1) 的矩阵,其权重是可训练的,甚至可以根据输入进行预测。完整的推导详见附录 E。
3.2 顺序-并行二元性
对于一系列神经网络模块,我们可以选择将它们按顺序或并行排列。然而,超连接提供了一种方法,能够学习如何重新排列这些层,以实现顺序与并行组合的混合配置。
在不失一般性的情况下,我们将扩展率设为 n=2。如果学习到的超连接为以下矩阵形式,则神经网络将按顺序排列:

在这种情况下,深度连接退化为残差连接,如图 4(a) 所示。
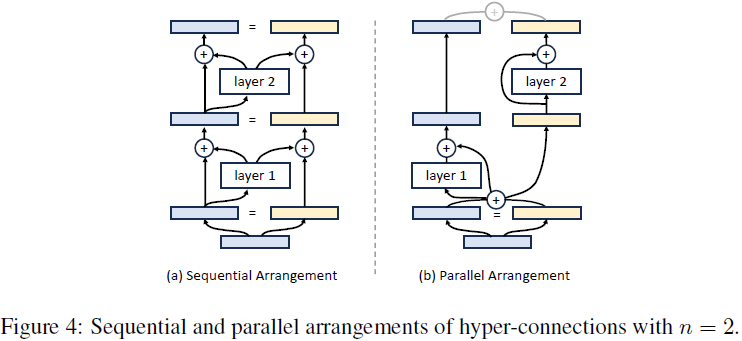
当奇数层和偶数层的超连接矩阵(层号从 1 开始)定义为以下形式时,神经网络每两层将以并行方式排列,类似于 Transformer 中的并行 Transformer 块(Wang, 2021),如图 4(b) 所示:

因此,通过学习不同形式的超连接矩阵,可以创建超越传统顺序和并行配置的层级排列,形成软混合甚至动态排列。对于静态超连接,在训练后网络中的层级排列保持固定;而动态超连接则允许网络的排列对每个输入 token 动态调整。
4. 实验
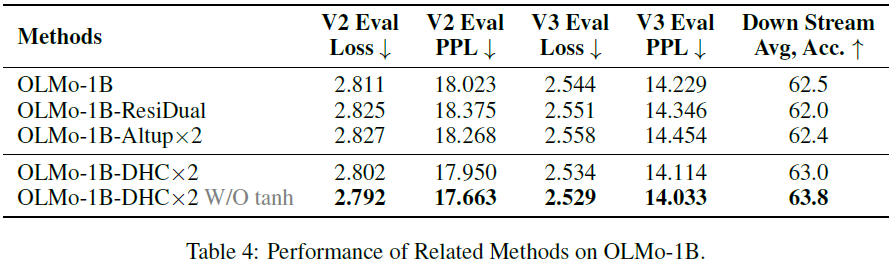
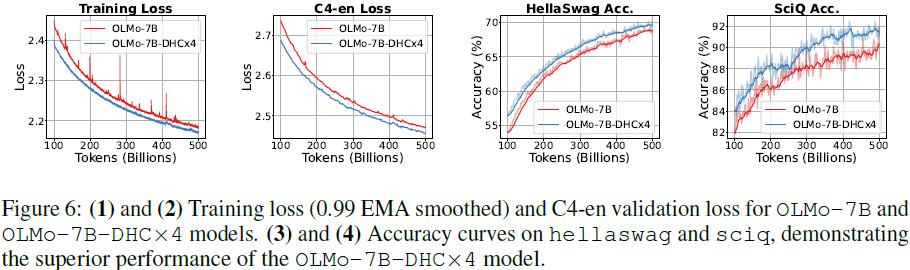
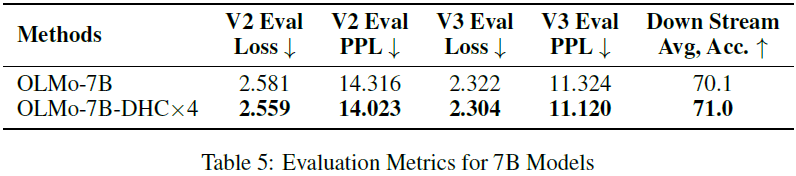
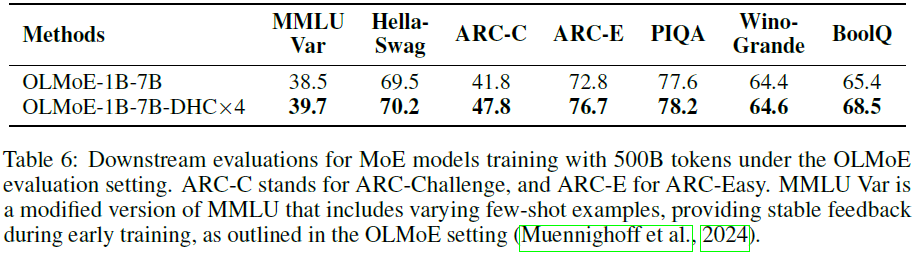
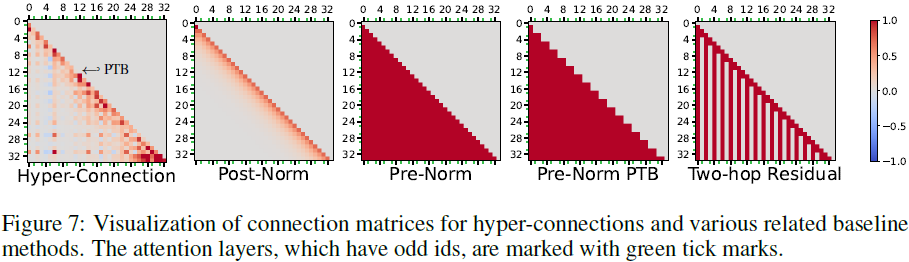
基线方法的连接模式。
- 对于 前归一化(Pre-Norm) 基线,其连接矩阵是一个对角元素被抹去的下三角矩阵,因为每个 Transformer 层均等地加入了残差。
- 在 前归一化并行 Transformer 块(PTB) 基线中,连接矩阵呈现锯齿状,因为 FFN 层的输入不依赖于上一层注意力层的输出。
- 对于 后归一化(Post-Norm) 基线,连接仅限于相邻层,因为残差通过后归一化层时,其权重对底层的依赖会逐渐衰减。
- 在 双跳残差(Two-hop Residual) 基线中(Ma 等,2024),注意力层的输出不会被添加到残差中,仅对下一层 FFN 产生贡献,导致连接矩阵中形成垂直条纹模式。
Λ 形连接模式。
- 在超连接的连接矩阵中,可以观察到一种 长期衰减模式,即各层通常倾向于依赖于少数几个相邻层的输出。此外,底层(例如第 0 层和第 2 层)的输出被大多数后续层频繁使用。这两种模式共同形成了 Λ 形连接模式。
- 需要注意的是,长期衰减模式是一种 后归一化风格 的模式,而底层频繁访问模式则属于 前归一化风格,这表明超连接可以实现前归一化和后归一化架构的自由混合。
输入词嵌入对模型输出的影响。从连接矩阵的第一列可以看出,输入词嵌入对大多数层都有贡献,除了最后一层。最后一层生成模型输出,用于预测下一个 token。在大多数情况下,在模型输出中保留输入嵌入的成分会对下一个 token 的预测产生不利影响,尤其是在使用诸如 OLMo-1B 的共享词嵌入时。类似的结果也在之前的研究中发现(Ma 等,2023)。
并行 Transformer 块的观察。正如 §3.2 所讨论的,并行 Transformer 块(PTB)是一种超连接的特例。在实践中,超连接学习到了类似 PTB 的模式,这可以通过局部锯齿状模式观察到。例如,第 11 层对第 12 层输入的贡献最小(参见超连接矩阵的第 12 行)。这表明第 11 层和第 12 层可以并行操作,从而形成一个 PTB 模块。
注意力层的长期连接较少。观察发现底部的注意力层几乎没有长期贡献,这种趋势持续到第 17 层。检查超隐藏状态的连接矩阵(参见附录图 10)可以发现,FFN 层的输出在量级上显著大于注意力层的输出。这种模式类似于双跳残差连接设计,其中注意力层的输出对后续的 FFN 层输入有贡献,但不会加入主残差路径。
6. 结论
综上所述,我们提出了超连接(Hyper-Connections),作为 Transformer 中残差连接的一种有效替代方案。我们的分析表明,超连接不仅克服了残差连接的局限性,还能够实现网络架构的动态调整。实验结果验证了超连接在各种任务中的显著优势,包括大规模语言模型的预训练、图像生成以及图像分类任务。
论文地址:https://arxiv.org/abs/2409.19606
项目页面:尚未开源
OpenReview:https://openreview.net/forum?id=9FqARW7dwB


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









