







AdaFV: Accelerating VLMs with Self-Adaptive Cross-Modality Attention Mixture

目录
AdaFV: Accelerating VLMs with Self-Adaptive Cross-Modality Attention Mixture
0. 摘要
视觉语言模型(VLM)的成功通常依赖于一种动态的高分辨率模式,该模式自适应地将输入图像扩展为多个裁剪区域,从而保留图像的细节。然而,这种方法会产生大量冗余的视觉 token,显著降低了 VLM 的效率。
为了在不引入额外训练成本的情况下提高 VLM 的效率,许多研究致力于通过筛选无信息的视觉 token 或聚合其信息来减少视觉 token。一些方法根据 VLM 的自注意力机制(self-attention)来减少视觉 token,但由于这种注意力机制存在偏差,可能导致不准确的响应。
这些仅依赖视觉线索的 token 减少方法与文本无关,未能聚焦于与问题最相关的区域,尤其是在查询的对象在图像中并不显著的情况下。在本研究中,我们首先通过实验表明,原始文本嵌入与视觉 token 是对齐的,对尾部(tailed)视觉 token 没有偏差。
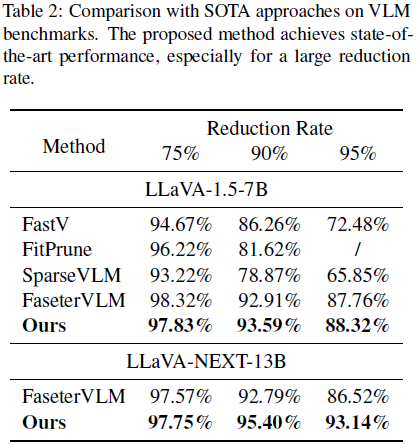
随后,我们提出了一种 自适应的跨模态注意力混合(self-adaptive cross-modality attention mixture)机制,该机制在 LLM 之前的(pre-LLM)层中动态地结合了 视觉显著性(visual saliency)和文本到图像相似性(text-to-image (T2I) similarity) 的有效性,从而选择具有信息性的视觉 token。广泛的实验表明,该方法在无需额外训练的情况下,实现了目前最先进的 VLM 加速性能,尤其是在 token 减少率较大的情况下。
1. 简介
LLaVA-NEXT 模型在单图像任务中包含 2880 个视觉 token,而现代 VLM(如 InternVL-2.5)在每个任务中包含超过 8000 个视觉 token,这可能远远超过文本提示的长度。为了解决这个问题,许多研究提出了通过修剪冗余视觉 token 来实现无需训练的 VLM 加速方法。例如,
- FastV 分析了 VLM 层中的注意力权重,发现视觉 token 的注意力权重分布在前向传播过程中显著下降。视觉 token 根据注意力权重进行排序,仅保留排名靠前的 token。
- 类似地,SparseVLM 首先选择与视觉 token 高度相关的文本 token,然后根据对应于所选文本 token 的自注意力矩阵评估视觉 token的 重要性,并逐渐从隐藏状态中修剪不相关的视觉 token。
- FasterVLM 发现文本到图像的注意力权重存在偏差,无法完全反映视觉 token 的重要性。相反,从视觉编码器中提取的视觉显著性可以避免这种偏差,并且可以作为视觉 token 修剪的有效指标。
2. 相关工作
2.1 视觉语言模型(VLM)
视觉语言模型在近几年取得了显著的进展。
LLaVA 是首个结合了大型语言模型(LLM)与基础视觉模型优势的方法。继 LLaVA 之后,一系列 VLM 被提出,展现了强大的多模态能力。最初的 LLaVA 系列模型仅使用一张图像作为输入,对 336×336 的图像产生 576 个视觉 token。然而,这种策略可能导致显著的信息丢失,从而降低模型的能力。
为了解决这一问题,许多 VLM 引入了动态高分辨率策略。尽管这些策略取得了成功,但也显著增加了视觉 token 的数量。例如,LLaVA-NEXT 模型在相同任务中需要多达 2880 个视觉 token。
2.2 通过 token 修剪实现 VLM 加速
Token 修剪是加速 Transformer 模型最直观的解决方案。
- 由于信息可以合并到更少的 token 中,修剪冗余 token 可以在对模型性能影响较小的情况下,安全地加速 Transformer 模型,并显著降低计算成本。一些方法利用这一发现来加速 VLM。Chen 等人(2024a)和 Ye 等人(2024)提出,根据从 LLM 中提取的自注意力衡量视觉 token 的重要性。
- 为了进一步加速模型,一些方法将 token 修剪过程置于 LLM 的编码器层之前。例如,FasterVLM 指出,LLM 层的文本到图像注意力存在偏差,从而导致不准确性,并提出利用视觉 token 的视觉显著性作为度量指标,以修剪非显著 token。
- 为了增强修剪的效果,一些方法进一步对 VLM 进行微调。例如,VisionZip 通过微调 MLP 投影模块,提高文本到图像注意力的对齐效果。
(2025,GlobalCom^2,MLLM,高分辨率图像理解,Token 压缩,LLaVA-Next,AnyRes)
3. 文本到图像对齐分析
3.1 在预训练 LLM 层中的文本到图像相似性分布
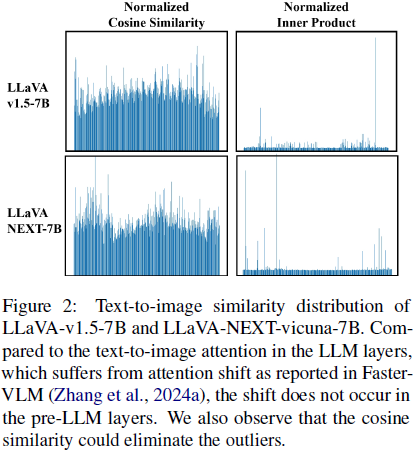
FasterVLM 对 VLM 的文本到图像注意力进行了全面评估,揭示了一个现象:VLM 的 LLM 层中存在 注意力偏移(attention shifts)问题,即后续的视觉 token 比前面的 token 获得更多的注意力。这种特性使得基于文本到图像注意力的 token 选择变得无效。然而,这种注意力偏移问题并未出现在 CLIP 模型和开放词汇检测/分割任务中。因此,我们推测,注意力偏移是由 LLM 中的注意力层引起的,而原始输入嵌入(包括系统嵌入、视觉嵌入和文本嵌入)本身并不包含这种偏移。
为了验证这一点,我们在 LLaVA 数据集的一个子集上进行实验,衡量 文本嵌入 token 与 视觉嵌入 的文本到图像相似性的分布。
我们使用了两种度量方式来评估对齐情况:归一化余弦相似度 和 归一化内积。
我们将实验结果可视化在图 2 中,结果显示,在预训练 LLM 层中不存在注意力偏移。
- 然而,归一化内积 的结果显示出显著的异常值(outliers),这可能会降低模型性能。
- 相比之下,归一化余弦相似度 更加均匀,有效地缓解了异常值问题,因此更可靠。
3.2 文本嵌入是否与视觉嵌入充分对齐?
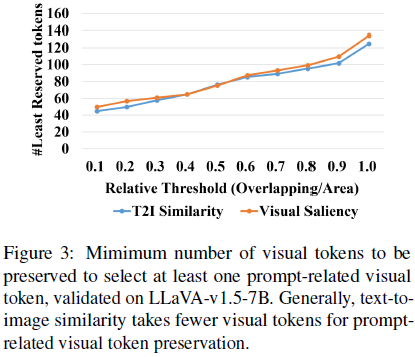
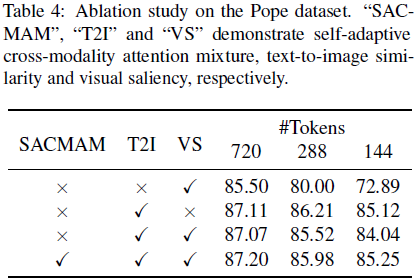
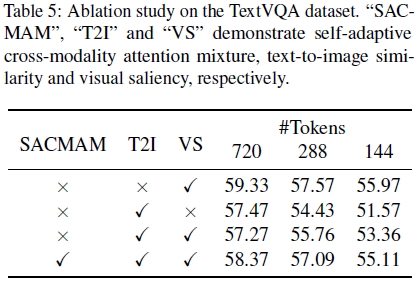
在揭示了预训练 LLM 层中的文本到图像相似性不存在注意力偏移后,我们进一步探讨文本嵌入是否与视觉嵌入充分对齐,以便在信息丰富的视觉 token 选择中加以利用。由于需要移除冗余的视觉 token,我们采用需要保留的最小视觉 token 数量作为验证的度量标准。因此,如果至少选择了一个与提示(prompt)相关的图像 token,则称其为成功选择,并利用所需保留的最小视觉 token 数量验证文本嵌入与视觉嵌入的对齐情况。
根据 FasterVLM,我们在 LLaVA 数据集的一个子集上进行了验证。
- 首先,使用最先进的 Segment-Anything-Model-2(Ravi等人,2024)对提示文本相关的对象进行分割,生成可靠的与提示相关的视觉 token 的真实值。
- 然后,我们将图像分割成 14×14 的窗口,并计算每个窗口与分割掩码的重叠区域面积。
- 我们设置多个阈值来判断图像块是否与文本提示相关。如果重叠面积大于阈值,则认为该块与提示相关。
- 接下来,根据显著性度量(例如视觉显著性和文本到图像相似性)对视觉 token 进行排序,保留排名靠前的 token,直到包含至少一个与提示相关的 token 为止。
我们将最少保留 token 的数量可视化在图 3 中。总体上,相较于视觉显著性,文本到图像相似性需要保留更少的视觉 token 以覆盖至少一个相关的视觉 token。这表明,文本到图像相似性是视觉 token 保留的一个有效度量。
【注:两条线有相似的趋势,说明和视觉显著性相似,文本到图像相似性是视觉 token 保留的一个有效度量。
图像显著性(Saliency)是图像中重要的视觉特征,体现出人眼对图像各区域的重视程度。
图像显著性模型旨在模拟人类视觉系统对图像中感兴趣区域的注意力分配。
显著图(Saliency map)是显示每个像素独特性的图像,其目标在于将一般图像的表示简化或是改变为更容易分析的样式。】
4. 方法
4.1 固定跨模态注意力混合
如上述实验所示,仅依赖视觉显著性不足以涵盖问题所需的必要信息【怎么看出来的?虽然直觉上,这个结论是对的,但是上述实验并不足以说明这个结论】。这表明文本到图像注意力对于信息保留非常重要。为了解决这个问题,我们利用视觉显著性和文本到图像注意力的能力来进行 token 修剪。一个直接的解决方案是根据视觉显著性和文本到图像相似性选择前 K 个 token。
形式化表示,设输入的文本嵌入为 T_E ∈ R^{N_T, D},视觉嵌入为 T_V ∈ R^{N_img, N_I, D},[CLS] token为 C ∈ R^{N_img, D},其中 N_T, N_img, N_I 分别表示文本 token 的数量、图像的数量,以及每张图像的视觉 token 的数量。
如 ViT 中所述, [CLS] token 用于图像分类,因此涵盖了全局信息。因此,我们利用 [CLS] token与视觉嵌入之间的注意力来表示视觉显著性,因为注意力的大小指示了每个视觉嵌入对全局信息的贡献。因此,视觉显著性 可以通过以下公式计算:
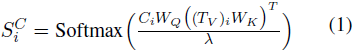
文本与图像之间的相似性 可以通过以下公式计算:
![]()
然后,我们按照以下公式对视觉 token 进行采样:
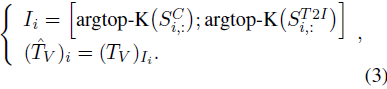
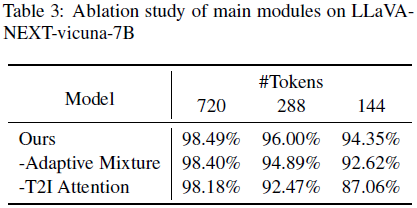
4.2 自适应跨模态注意力混合(SACMAM)
虽然固定方法可以利用全局和文本相关的信息,但简单地混合这两者是次优的。为了使模型能够根据视觉显著性(突出显示显著图像 token)和文本-图像相似性(query latents 与问题相关的图像 token)的分布动态确定 token 的保留,我们提出根据视觉显著性和文本-图像相似性自适应分配 token 预算。
如前所述,我们采用余弦相似性来选择与文本对齐的视觉 token。然而,余弦相似性的分布与视觉显著性不可比,这限制了 token 的混合选择。为了解决这一问题,我们引入一个温度参数 τ 对相似性进行重新加权,公式如下:
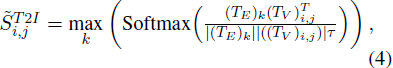
其中 τ 是一个超参数。经过重新加权后,文本-图像相似性可以与视觉显著性进行比较。
为了简化讨论,假设图像的维度和每张图像的 token 数合并。在这种情况下,S_C 和 ~S^{T2I} 的形状为 (N_img × N_I, 1)。要在预算为 K 的情况下选择最具信息量的视觉 token,一个简单的解决方案是选择前 K 个 token,公式如下:
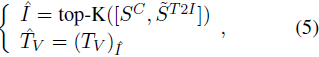
这相当于优化以下目标:
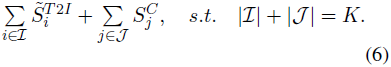
然而,由于文本-图像相似性和视觉显著性的分布不同,并且只选择了少量 token,模型可能仅依赖于单一的注意力分数进行选择,这并不是预期的结果。
为了解决这一问题,我们利用所选 token 的文本-图像相似性和视觉显著性的几何平均值来衡量所选 token 的平均重要性,公式如下:
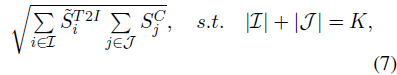
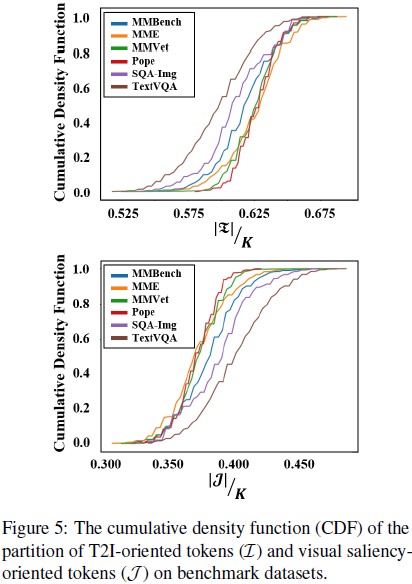
其中 I 和 J 分别表示根据文本-图像相似性和视觉显著性选择的视觉 token 索引集合。
为实现上述目标,我们首先对 ~S^{T2I} 和 S_C 进行排序,记排序后的分数为 ^S^{T2I}。然后,我们计算 ^S^{T2I} 和 ^S^C 的累加和 a 和 b,公式如下:
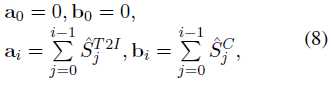
然后我们计算总体指标,公式如下:
![]()
为了避免选择无效的索引,我们利用一个掩码 M 将 O 中对应于这些索引的元素设置为零。具体而言,掩码 M 可计算如下:
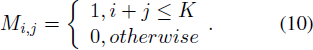
接着,通过如下公式确定根据文本-图像相似性和视觉显著性选择的 token 数量:
![]()
在确定每种重要性测量方式下选择的 token 数量后,我们选择最高值的索引以进行视觉 token 索引,公式如下:
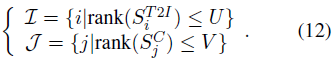
最终,所选择的视觉 token 可表示为:
![]()
注意,为了保持图像上的正确空间关系,所选 token 根据其在图像中的原始位置进行排序。为简化计算,我们允许重复的视觉 token。
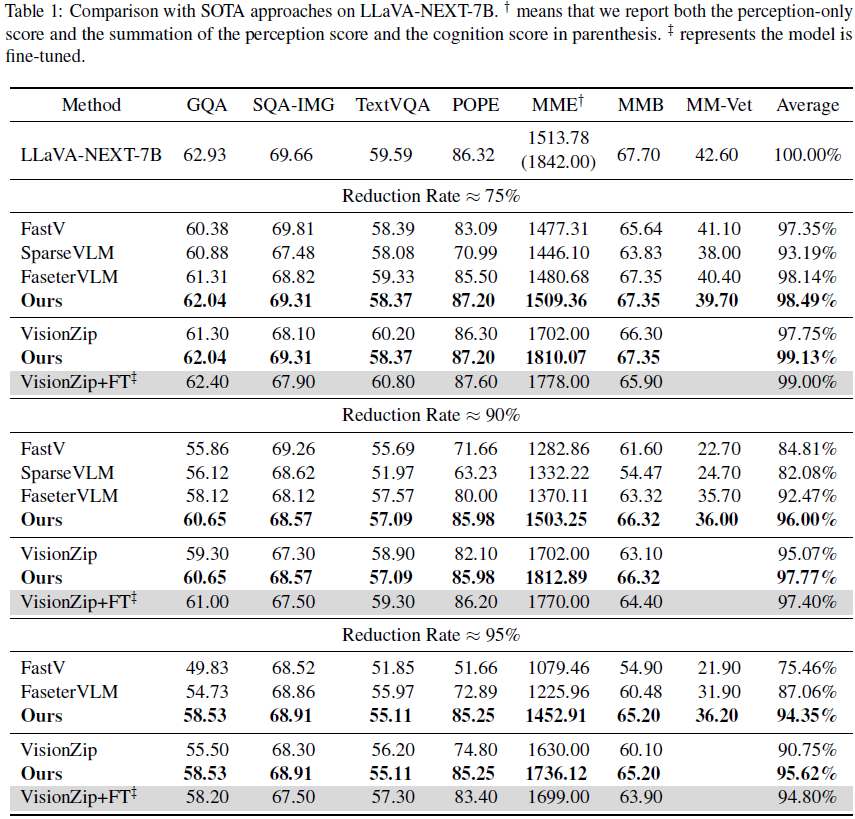
5. 实验

6. 结论
在本研究中,我们首先分析了预训练语言模型(pre-LLM)层中的文本-图像相似性,揭示了原始文本嵌入与视觉嵌入在自然图像问答任务中具有充分的对齐性,这表明在 LLM 自注意力机制之前进行 token 剪枝是有效的。随后,我们提出了一种视觉显著性与文本-图像相似性的自适应混合方法,在不引入额外计算成本的情况下选择信息量高的视觉 token。大量实验表明,所提出的方法显著增强了视觉语言模型(VLMs)的加速鲁棒性,并与其他方法相比实现了最先进的性能。
论文地址:https://arxiv.org/abs/2501.09532
进 Q 学术交流群:922230617


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









