







Distillation Scaling Laws
![]()
目录
1. 引言
随着计算资源的增加,计算最优模型的规模也在增长,但推理成本随之升高,带来高昂的运行费用和碳排放。为降低推理成本,研究者提出了“过度训练”策略,然而蒸馏作为一种知识转移方法,能够在训练小型高性能模型时提供更好的性能。尽管如此,关于蒸馏是否始终优于监督学习的争论仍在继续。
本文通过对 143M 到 12.6B 参数模型的大规模实验,提出了一种 蒸馏缩放定律,通过计算预算及其在学生和教师之间的分配,来估计蒸馏模型的性能,从而降低大规模使用蒸馏的风险,解决了蒸馏有效性及“容量差距”等关键问题,实现计算资源的最优配置以提升学生模型性能。
本文给出了两种情况下的计算最优蒸馏方法:(1)已有教师模型;(2)需要训练的教师模型。结果显示,当存在多个学生或已有教师时,蒸馏在学生规模依赖的计算阈值内优于监督预训练。而当仅需训练一个学生且需要训练教师时,监督学习更为合适。
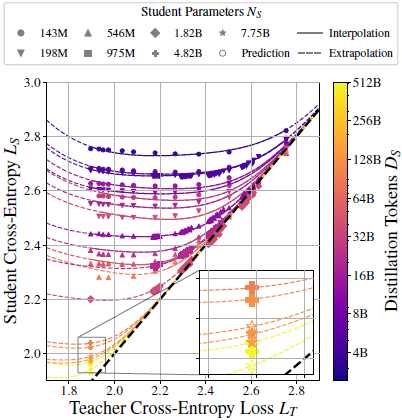
图 1. 蒸馏缩放定律的外推。
- 蒸馏缩放定律(公式 8)适用于一系列损失为 L_T 的教师的弱学生(L_S > 2.3)。
- 实线:对于给定学生配置(插值),预测的未见过的教师模型行为
- 虚线:见过的教师之外和强学生区域(L_S ≤ 2.3)的预测模型行为。
- 如图所示,学生可以胜过老师(详情见图 2、3 和 41)。
1.1 关键词
蒸馏缩放定律、语言模型、计算预算、学生模型、教师模型、容量差距、知识蒸馏
2. 背景
在语言模型规模化训练中,性能预测对于合理分配计算资源尤为关键。通常,模型性能通过交叉熵(L)衡量,并随着参数数量(N)和训练数据量(D)呈幂律下降。
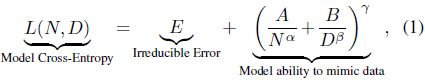
计算最优的语言模型保持固定的 “数据-参数” 比值(D / N),这虽然简化了训练配置,但限制了实验自由度。
Hoffmann 等提出的两种训练策略为识别缩放系数提供了可靠途径。
- (固定模型,变化数据)训练 token 的数量对于固定的模型系列是变化的。
- (IsoFLOP 配置)模型大小和训练 token 都根据总计算约束而变化。
本文旨在预测通过蒸馏得到的学生模型的交叉熵,从而确定在给定计算预算下的最优蒸馏配置。这对于确定蒸馏的价值、计算资源的合理分配及最大化学生模型性能具有重要意义。
3. 预备知识
本文使用标准序列表示法,并关注语言模型任务,其中训练目标是通过最大化观测数据的似然来预测序列的下一个标记(Next Token Prediction,NTP)。
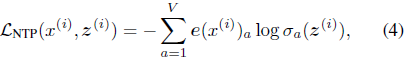
其中,x^(i) 表示输入序列,z^(i) 表示下一个标记分类器输出。
通常还会使用以下 token 级 Z-loss 来提高训练稳定性:
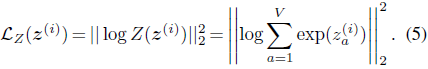
教师模型(T)生成的概率分布作为学生模型(S)的训练目标,使用知识蒸馏损失进行优化。
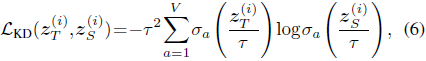
将这些损失加在一起,就得出了学生的总 token 级损失:
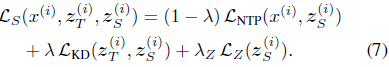
蒸馏温度(τ)和权重系数的选择在实验中经过严格验证,确保了训练的稳定性和一致性。
4. 蒸馏缩放定律
µP 参数化 方法能够跨模型大小进行学习率的超参数迁移,从而简化缩放定律实验设置。
本文的实验基于 Gunter 等人的模型框架,采用多头注意力机制、预归一化方法(Pre-Normalization,RMSNorm)和旋转位置编码(RoPE),并使用 C4 数据集进行训练。
学生模型和教师模型的规模从 143M 到 12.6B 参数不等,训练序列长度为 4096。为了消除数据干扰,所有蒸馏训练均使用不同的数据集切分进行。实验包括以下几种方案(M = D / N):
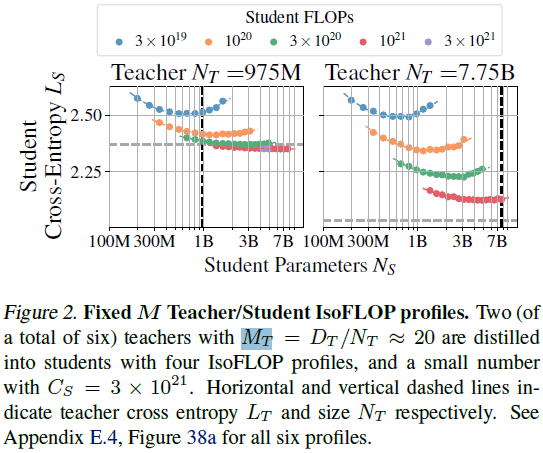
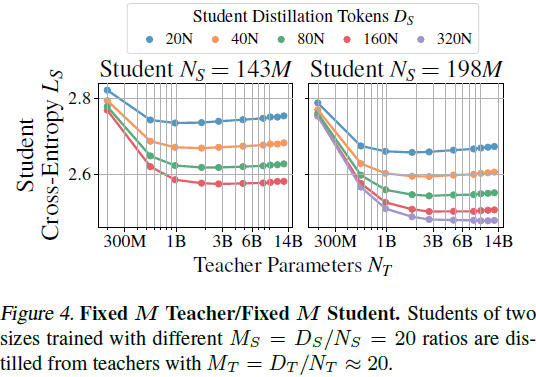
1)固定 M 教师,IsoFLOPs 学生:在不同教师固定比率的训练下,观察学生在相同计算预算(FLOP)下的性能变化,发现学生模型在某些情况下可超越教师模型。
2)IsoFLOP 教师,固定 M 学生:通过固定学生配置并改变教师的训练数据量,分析教师性能对学生性能的独立影响。
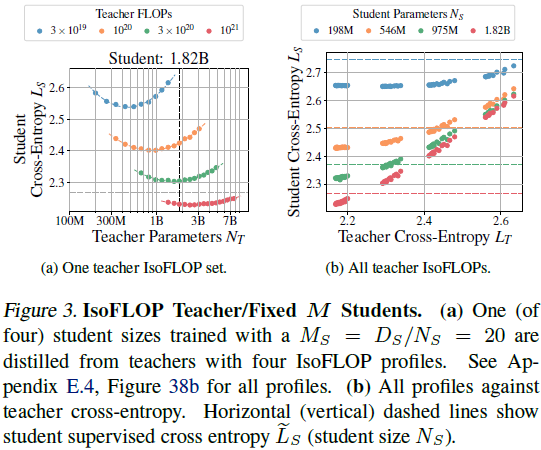
3)固定 M 教师,固定 M 学生:在尽可能广的范围内探索学生交叉熵的变化,观察到 “容量差距” 现象,即 更强的教师并不总能提高学生性能,反而可能增加学生训练难度。
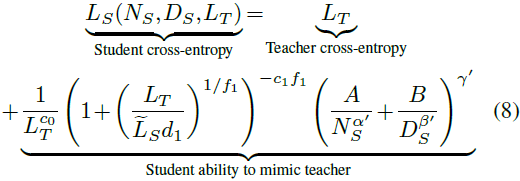
研究发现,蒸馏缩放定律的关键在于 教师的交叉熵,它由教师模型的规模和训练数据量决定。本文提出的定律遵循分段幂律关系,反映了学生和教师学习能力之间的转变。
学生的交叉熵由教师交叉熵和学生规模、蒸馏数据量的组合决定,且存在“容量差距”:当教师的学习能力显著高于学生时,学生的性能反而下降。
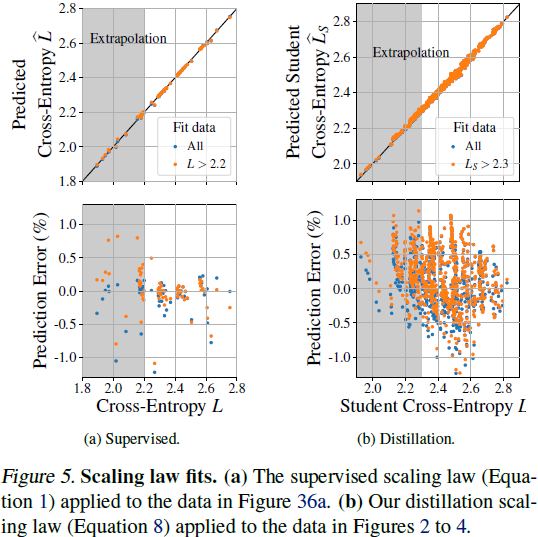
实验得出的缩放定律在 1% 以内的误差范围内成功预测了不同规模下学生模型的性能,包括从弱模型到强模型的外推验证。此外,在固定模型规模的无限数据训练下,蒸馏的表现与监督学习一致,进一步验证了该定律的适用性和准确性。
5. 蒸馏应用
本文应用蒸馏缩放定律分析了多种实际场景:
1)在固定数据或计算预算下:监督学习在足够多的数据或计算资源条件下始终优于蒸馏,但在中等数据量下,蒸馏更为高效。
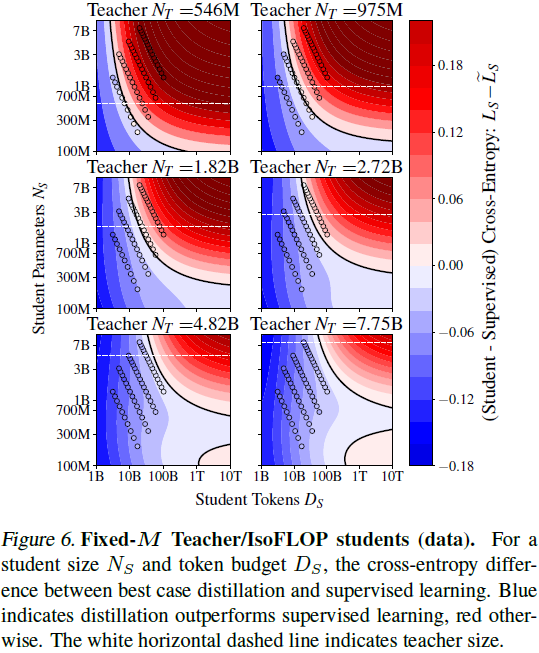
2)考虑教师推理成本:在已有教师模型的情况下,教师推理成本成为关键因素,教师规模需要随着学生规模的增加而降低其交叉熵。
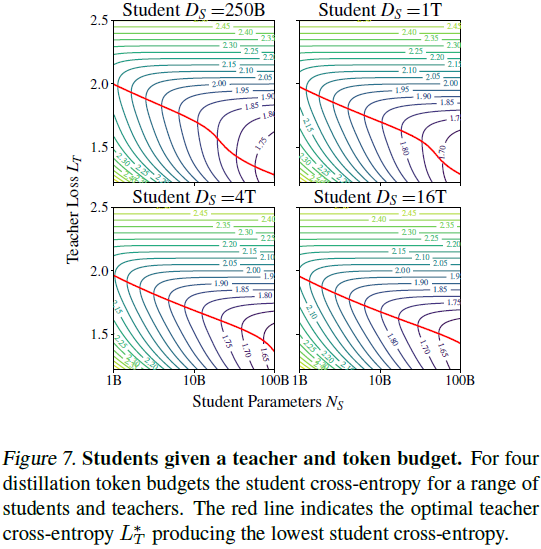
3)计算最优的蒸馏配置:在较低的计算预算下,应更多地投入到教师训练中;而在较高的预算下,应在学生训练和教师推理之间进行均衡分配。
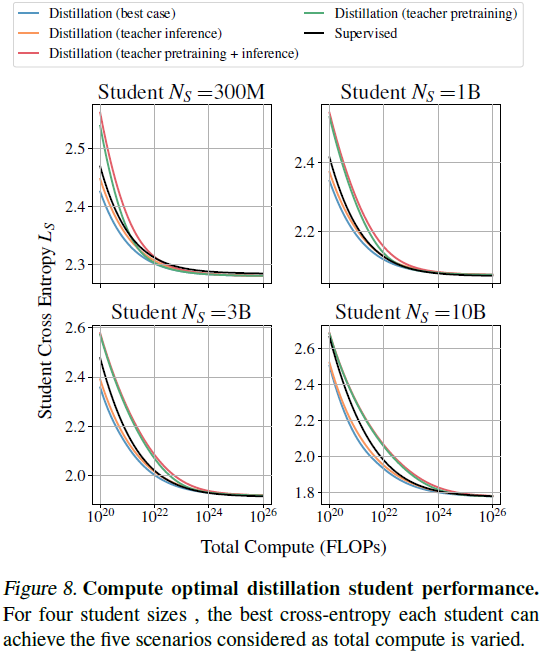
6. 结论
本文提出的蒸馏缩放定律为计算最优的蒸馏训练提供了理论基础。研究表明,蒸馏仅在学生计算资源未超过规模依赖阈值且已有教师模型或教师具备多重用途时才比监督学习更高效。此外,本文还提供了计算最优的蒸馏配置方案,支持生产高性能的小型模型,降低推理成本和碳排放,提高测试时间规模化的可行性。
论文地址:https://arxiv.org/abs/2502.08606
进 Q 学术交流群:922230617 或加 V:CV_EDPJ 进 V 交流群


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









