






Vision as LoRA
目录
1. 引言
本文提出了一种新范式 VoRA(Vision as LoRA),将视觉能力内置于 LLM 之中,以实现无需外部视觉编码器的多模态大语言模型(MLLM)。与主流 MLLM 依赖外部视觉模块不同,VoRA 通过直接将视觉专用的 LoRA 层集成进 LLM,使其在推理时可合并为标准模型,极大降低结构复杂度与计算开销。
- VoRA 支持任意分辨率输入,并借助块级蒸馏(block-wise distillation)策略,将视觉先验从预训练的 Vision Transformer(ViT)迁移至 LoRA 层,从而加速训练并注入视觉知识。
- 此外,VoRA 还引入双向注意力机制以更好捕捉图像上下文关系。
实验表明,在额外数据支持下,VoRA 性能可比拟传统基于编码器的 MLLM,表明 LLM 有望获得原生多模态能力而无需外部视觉模型。
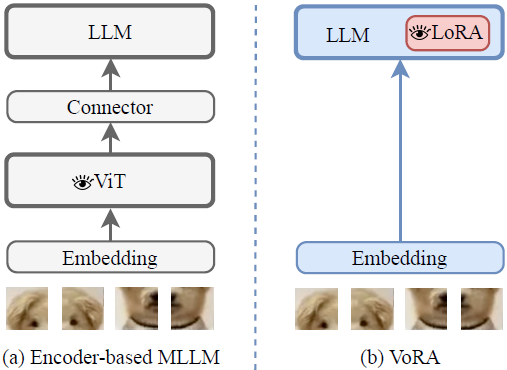
图1. VoRA 的高层次概览。图中带有眼睛图标的部分表示视觉参数。
- 主流的多模态大语言模型(MLLM)采用模块化、顺序式架构:首先由预训练的视觉编码器对原始图像像素进行处理,提取高级视觉特征,然后通过模态连接器与大语言模型(LLM)进行对齐,以执行视觉语言任务。
- 相比之下,VoRA 仅由一个 LLM 和一个轻量级的嵌入层构成。LoRA 层作为视觉参数直接集成进 LLM,可在推理时无缝合并,不会带来额外的计算成本或内存负担。
2. 相关工作
当前多模态大语言模型(MLLM)主要分为两大类:基于编码器与无编码器的模型架构。
- 尽管编码器方法在性能上占据主导,但它们通常面临计算开销大、灵活性差等问题;
- 而无编码器方法虽结构简洁,但训练稳定性和模态融合仍是关键挑战。
2.1 基于编码器的 MLLM
主流的 MLLM 架构通常包括三个模块:视觉编码器(如ViT)、大语言模型(LLM)与模态连接器(connector),用于桥接视觉与语言之间的模态差异。已有研究主要集中在 connector 设计的改进,从简单的 MLP 结构到层次化(hierarchical)特征融合模块再到复杂的模块组合,例如 BLIP2、LLaVA、MiniGPT 等模型。
尽管连接器方案多样,但该架构的根本问题在于对外部 ViT 的依赖。
- 首先,当扩展多个或更大的视觉模型时,训练与推理的计算资源消耗显著增加。
- 其次,ViT 的固定分辨率训练策略限制了输入图像的灵活性,迫使模型采用图像分块或强制缩放等替代方法,这可能造成信息丢失或性能退化。虽然部分研究尝试训练原生支持任意分辨率的 ViT,但往往依赖大规模私有数据和不透明的训练流程,难以复现。
这些限制推动了对更简洁、原生支持视觉建模的无编码器架构的研究探索。
2.2 无编码器 MLLM
为解决上述问题,部分研究探索在 Transformer 中直接处理图像与文本输入,从而省去外部视觉模型。
- Fuyu 作为首个无编码器 MLLM 尝试,展示了其可行性,但训练资源消耗巨大,技术细节披露有限。
- EVE 模型则引入一个单独 Transformer 块作为轻量视觉编码器,并通过蒸馏方式使其输出与 ViT 特征对齐,在主训练阶段训练全部 LLM 参数以学习视觉模态。
然而,这些方法将视觉与语言参数紧耦合,带来了严重的模态冲突,导致训练不稳定甚至语言能力的灾难性遗忘。
为缓解此类问题,Mono-InternVL 与 EVEv2 引入了参数解耦机制,借鉴 Mixture-of-Experts(MoE)思想,为视觉与语言分别保留独立的参数路径。这种方式在一定程度上避免了模态冲突,提升了训练稳定性。但该策略会使模型参数规模翻倍,显著增加了内存需求并损害结构简洁性。
相比之下,VoRA 采用了低秩适配(LoRA)策略,将视觉信息编码进 LLM 而不干扰原有语言能力,并在推理时将 LoRA 层无缝合并进 LLM,既保留了架构轻量性,又实现了模态解耦,是对现有无编码器方案的重要改进。
3. Vision as LoRA
本节介绍了 VoRA 的三大关键机制:通过 LoRA 集成视觉能力、使用块级蒸馏加速训练、引入双向注意力机制增强图像建模。
该设计突破传统 MLLM 结构,既实现模态解耦,又在不增加推理负担的前提下,赋予 LLM 以原生视觉理解能力。
3.1 稳定训练:视觉作为 LoRA
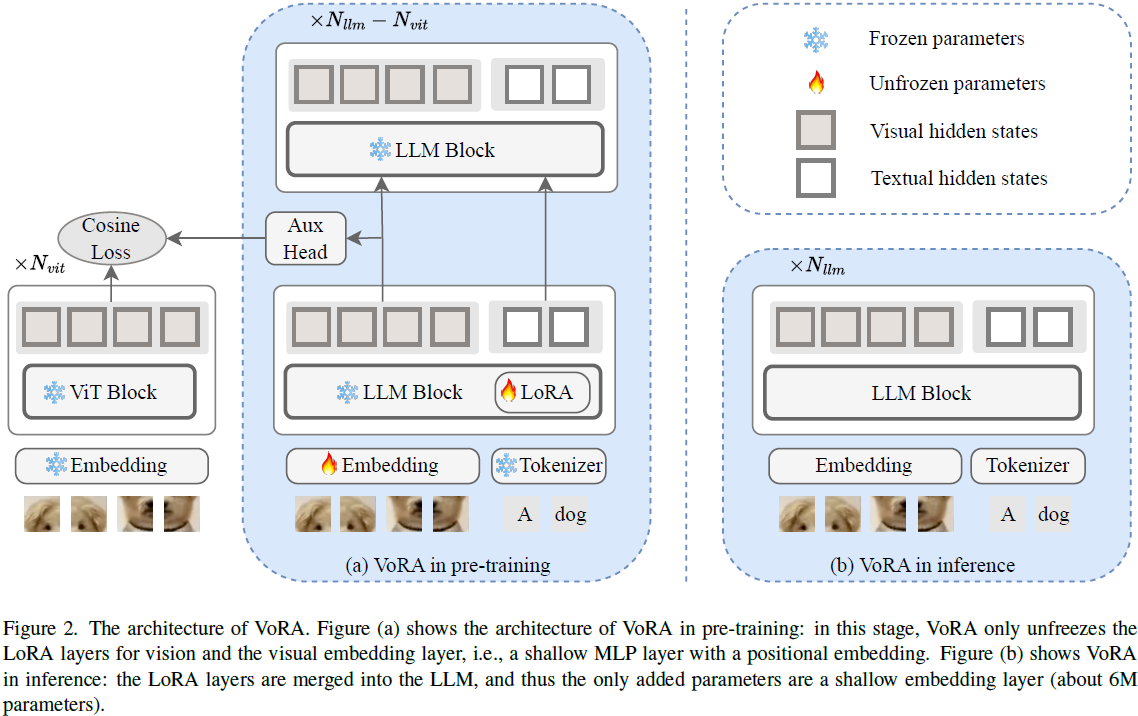
在训练阶段,如图 2(a) 所示,
- VoRA 首先利用一个轻量视觉嵌入(embedding)层(带位置编码的浅层 MLP,约 6M 参数)将图像像素转换为视觉嵌入向量。
- 这些视觉 token 随后与文本 token 一同输入 LLM。
- VoRA 在 LLM 前 N_vit 个 Transformer 块的所有线性层(包括 QKV 投影与前馈层)中插入 LoRA 模块,用于专门学习视觉表示。
训练过程中,仅更新 LoRA 层与视觉嵌入层,其余 LLM 参数保持冻结。该策略可视为 “模态解耦”:语言知识得以完整保留,而视觉能力通过LoRA附加进模型中,避免了全量训练中常见的训练不稳定与模态遗忘问题。
推理阶段,如图 2(b) 所示,训练后的 LoRA 参数可被无缝合并进 LLM 中,模型结构等同于原始 LLM,仅额外保留一个视觉嵌入层,从而实现 “零推理开销”。
3.2 加速训练:块级蒸馏
为了减少视觉学习对大规模图像数据的依赖,VoRA设计了一种 块级蒸馏(block-wise distillation)机制:将每一层(前 N_vit 层)LLM 中 LoRA 输出的视觉特征与 ViT 中对应块的输出对齐,从而实现视觉知识的迁移。具体方法如下:
蒸馏损失(Distillation Loss):对于 LLM 中第 i 层、第 s 个视觉 token,其输出通过一个辅助映射头 AuxHead(RMSNorm + 线性投影)后,与 ViT 中对应的特征计算余弦相似度,目标是最大化相似度。
蒸馏目标函数为:
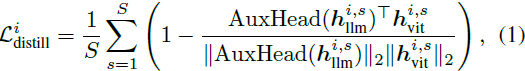
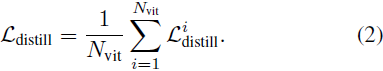
语言建模损失(Language Modeling Loss):通过交叉熵损失优化图文对中的文本生成:
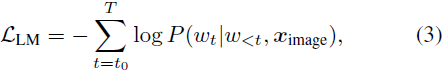
最终损失为两者之和:
![]()
与传统蒸馏不同,VoRA 只更新视觉相关 LoRA 层,而不涉及 ViT 或 LLM 主干参数,大大提高了训练效率。
3.3 双向注意力机制用于视觉
在 Transformer 中,文本生成常使用 因果掩码(causal mask),强制 token 仅关注前文内容。然而,对图像 token 而言,这种顺序性约束是多余且有害的,会妨碍图像上下文的整体建模。
为此,VoRA 在视觉部分引入 双向注意力掩码(bidirectional mask):所有图像 patch 之间可完全互见,支持全局上下文感知。文本 token 仍保持因果掩码,以确保语言生成质量。图 3 对比了这两种注意力结构。

实验证明,双向掩码显著降低了训练与蒸馏损失,并在多个基准任务上取得更优性能。这一发现与图像生成模型中的研究趋势一致,验证了 VoRA 结构在多模态生成与理解任务中的潜力。
4. 数据
本节介绍了 VoRA 在预训练阶段所使用的图像与文本数据来源、构建策略及其混合方式。
- 尽管 VoRA 的技术核心不依赖数据工程,但合理的数据构造仍对其性能表现至关重要。
- 为确保语言与视觉能力的平衡,构建了一个包含图文对与文本指令任务的多模态数据集。
4.1 数据收集与预处理
本文重点不在于数据工程优化,因此采用了简洁直接的数据处理策略,并参考了 EVE、Mono-InternVL 等研究中的实践。
图像数据来源:从 DataComp-1B 中选取图像,使用 Qwen2-VL-72B 自动生成图像描述,构建了约 29M 图像-文本对(DataComp29M-recap)。选图标准为图像长边大于 448 像素,以确保视觉质量。
该数据集在特定的世界知识方面存在缺失,特别是在地标、名人和艺术品等类别上。为弥补地标类数据的不足,从 Google Landmarks Dataset v2(GLDv2)中补充了大约 1.4M 张图像。
而对于其他类别,目前尚无合适的百万级公开数据集可用。此外,出于潜在伦理风险的考虑,选择不收集此类数据。因此,本方法在这些领域的表现可能不尽理想。然而,这一局限性在未来工作中可通过引入相关数据集来加以缓解。
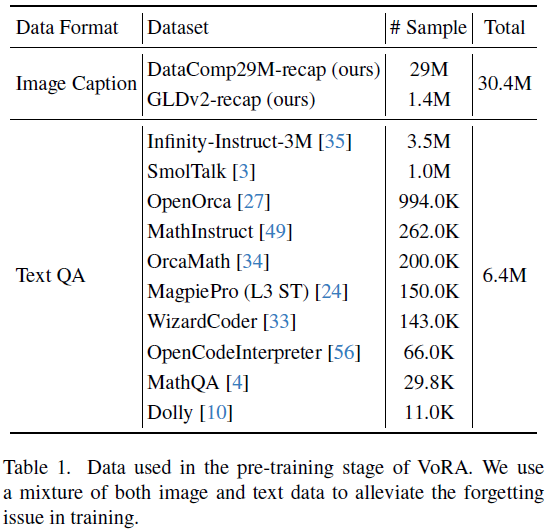
4.2 多模态数据混合
尽管 VoRA 在训练时语言参数被冻结,长期只使用图像-文本对训练仍会削弱 LLM 的指令跟随能力。因此,作为补充,在预训练数据中混合了多个指令任务文本数据(6.4M)。
数据配比:最终混合数据共包含约 30M 图像-文本对与 6.4M 文本任务数据,确保模型在获得视觉能力的同时,仍能保持语言理解与生成能力。
5. 实验
本节通过一系列实验验证 VoRA 各项设计的有效性,包括实现细节说明、消融实验分析及与现有方法的标准评估对比。
实验结果表明,VoRA 不仅在性能上接近甚至匹配主流 MLLM,还具有训练稳定、数据效率高、结构轻量等优点。
5.1 实现细节
训练配置:预训练阶段使用 AIMv2-Huge-448p 作为视觉教师模型,Qwen2.5-7B-Instruct 作为语言模型。学习率设为 0.0002,warm-up 步数为 100,batch size 为 256。其余超参数配置遵循文献 [29]。
微调策略:在微调阶段,所有 LoRA 层被合并进 LLM,蒸馏模块被移除,仅视觉嵌入层(6M 参数)与全量 LLM 保持可训练状态。对 VoRA-AnyRes 变体,保留固定分辨率下预训练权重,仅在微调时使用原始图像分辨率。
评估基准:模型在多个标准数据集上评估,包括:
-
VQAv2、TQA、AI2D(视觉问答)
-
SEED-Image、MMVet、MMBench(综合评估)
-
MME Perception、MME Cognition、POPE、SQA-Image、RQA、MMMU(世界知识与推理)
5.2 消融实验
本文通过消融实验分别验证了三项关键机制的贡献:LoRA 模块、块级蒸馏、双向注意力。
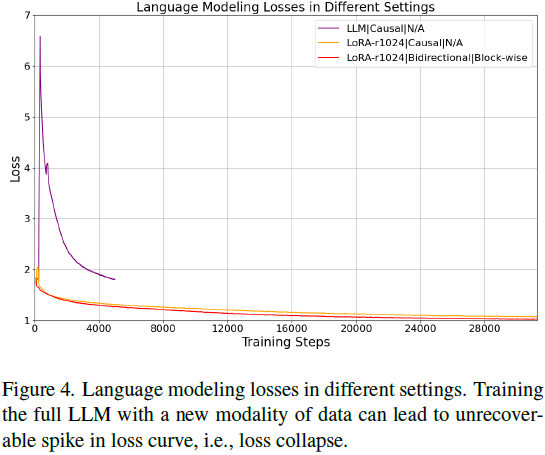
LoRA 稳定性与 Rank 影响:
- 全参数训练在引入视觉数据时极不稳定,如图 4 所示会出现损失 “塌陷”。
- 相比之下,使用 LoRA(如 rank=1024)显著提升训练稳定性。如图 5 所示,rank 越高(如从 512 增加至 1024),损失略有降低,蒸馏对齐也更充分。但 rank=1536 会出现不稳定,最终默认选择 rank=1024。
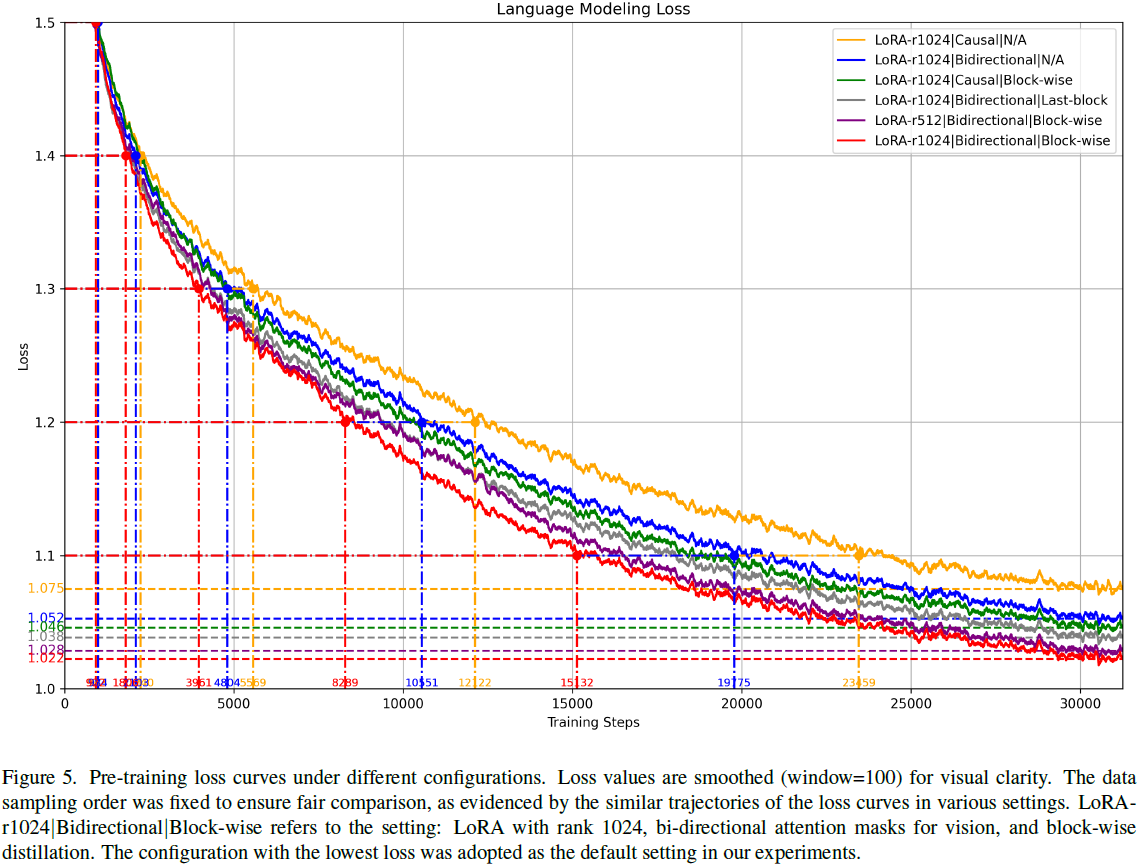
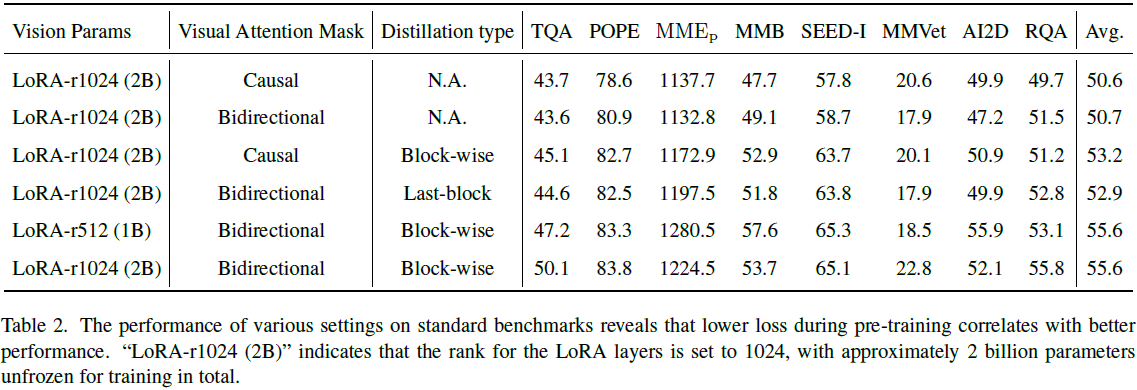
注意力掩码对比:在相同配置下,双向注意力 mask 显著优于因果 mask。表 2 显示切换为双向注意力后,平均得分提升达 2.4 分。同时,其平均蒸馏损失更低,说明视觉信息传递更充分。
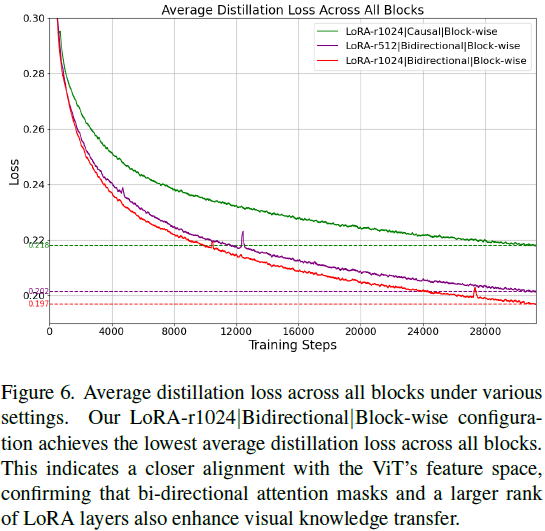
蒸馏策略比较:相比无蒸馏、只蒸馏最后一层的 “last-block” 方法,全块级蒸馏 “block-wise” 进一步提升性能。如表 2 所示,在双向注意力设定下,block-wise 相比 last-block 再提升 2.7 分,训练损失降低 0.016,蒸馏损失最低。
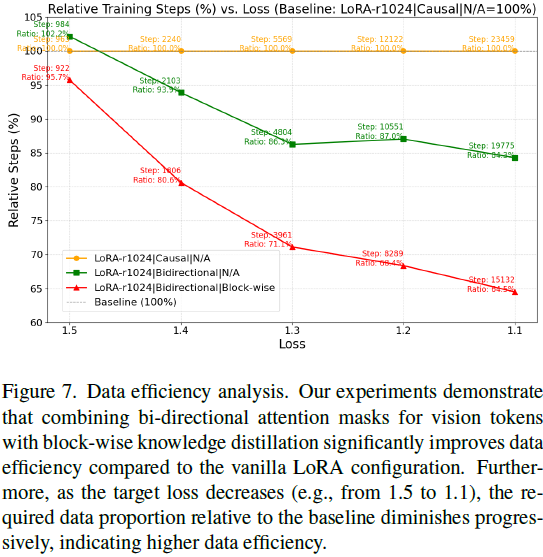
数据效率分析:以达到特定损失阈值所需训练步数评估效率。双向注意力+块级蒸馏配置在达到 loss = 1.1 时,仅需 vanilla LoRA 的 64.5% 步数,显示训练加速效果显著。如图 7 所示,目标 loss 越低,效率优势越明显。
5.3 标准评估
为确保公平性,未扩大微调数据,仅使用公开 LLaVA-665K 数据集微调,避免使用额外私有数据。
(2024|CVPR,LLaVA-1.5,LLaVA-1.5-HD,CLIP-ViT-L-336px,MLP 投影,高分辨率输入,组合能力,模型幻觉)通过视觉指令微调改进基线
对比模型设置:在相同框架下复现了 LLaVA-1.5 模型,使用相同的 Qwen2.5-7B 和 AIMv2-0.6B 作为基线,与 VoRA 做直接对比。
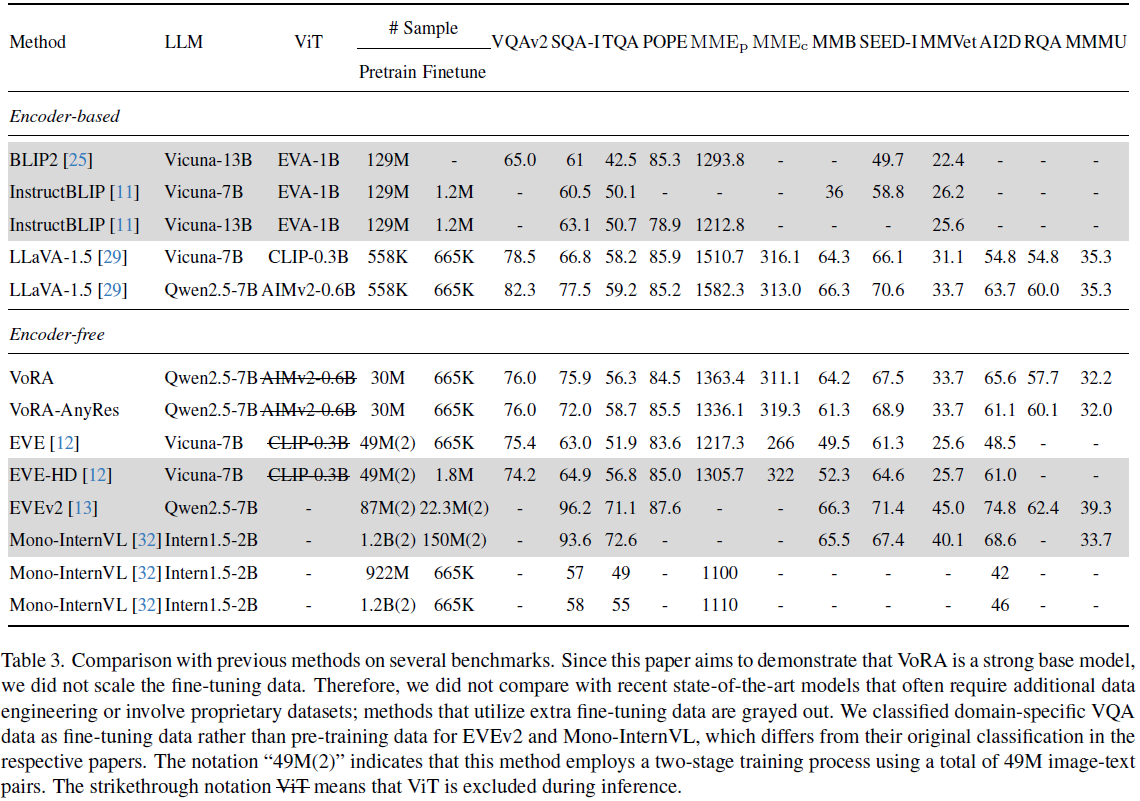
实验结果:如表 3 所示,VoRA 在多个任务上接近甚至匹配 LLaVA-1.5 的表现,尤其在 VQAv2、AI2D、RQA 等任务上表现优异。但在 MME Perception 上存在明显差距,主要源于预训练数据缺乏世界知识。
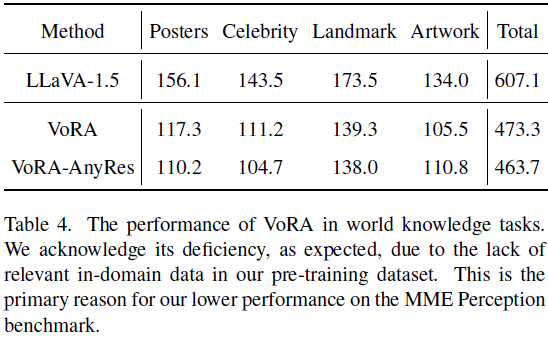
细分能力评估:表 4 显示,VoRA 在电影海报、名人、地标、艺术品识别方面分别落后 LLaVA-1.5 十几至几十点,验证了数据覆盖范围对世界知识任务性能的重要性。
6. 局限性
尽管 VoRA 在多项任务中展现出强大性能和结构优势,但当前方法存在的几个关键限制,主要集中在训练数据依赖、视觉 token 冗余与世界知识覆盖不足三个方面。
1)对额外预训练数据的依赖:
VoRA 完全去除了传统 MLLM 中的视觉编码器模块,因此其视觉能力必须从零学习。这意味着模型对高质量图像-文本对的预训练数据极为依赖。虽然 VoRA 利用块级蒸馏技术在一定程度上减轻了这种依赖,但如果缺少足够的数据支持,其视觉建模能力难以媲美已有的 ViT 编码器模型。
本文提出一个推测:由于省去了 ViT 的 “视觉信息压缩” 过程,VoRA 理论上可能比编码器模型具备更完整的视觉保真性,从而在规模扩展后有望实现性能反超。但目前尚无实验证据支持这一假设,主要原因在于训练资源和数据规模的限制。
2)缺乏视觉 token 压缩机制
与许多基于视觉编码器的 MLLM 不同,VoRA 在视觉输入上未采用任何 token 压缩策略(如动态采样、大 patch 划分、token pooling 等)。这导致在图像分辨率较高或序列较长时,计算量显著增加。
尽管本文为了公平性保留了 LLaVA-1.5 原有设置,未引入此类技术,但这一点在实际部署中可能成为性能瓶颈。
该问题可通过未来引入大 patch 策略、token 剪枝或融合技术加以缓解。
3)世界知识缺失带来的性能瓶颈
由于训练数据主要来自自动生成的图文对和通用图像,VoRA 在涉及世界知识(如地标、名人、艺术品识别等)方面表现不佳。表 4 数据显示,在此类任务中 VoRA 明显落后于 LLaVA-1.5。这种劣势并非架构层面的问题,而是预训练数据中未包含相关领域信息的结果。
该限制可通过后续引入专门数据集(如维基百科图像、开放名人数据等)加以弥补,从而提升模型在世界知识相关任务上的表现。
7. 结论和未来方向
本文提出了一个全新的多模态大语言模型构建范式 —— Vision as LoRA(VoRA),通过三个关键机制将视觉能力无缝集成到LLM中,避免了传统视觉编码器的结构复杂性与计算冗余:
1)视觉作为LoRA(Vision as LoRA):通过引入 LoRA 模块以适配视觉模态,同时冻结原有语言模型参数,VoRA 在推理时可将 LoRA 参数合并进 LLM,实现 “零推理开销” 的视觉集成。
2)块级蒸馏(Block-wise Distillation):利用预训练 ViT 作为教师模型,将其分层特征迁移到 LLM 前若干层的 LoRA 模块中,从而注入视觉先验并显著提升训练效率。
3)视觉双向注意力(Bidirectional Attention for Vision):针对图像 token 启用全局可见性注意力机制,增强视觉建模能力,同时保留文本 token 的自回归注意力以维持语言能力。
通过上述三项创新,VoRA 展示了无需外部视觉模型即可实现高质量视觉语言理解的能力,并具备高度的计算效率与结构灵活性。实验证明,VoRA 在多个视觉问答与多模态推理任务中取得了接近甚至匹敌传统 MLLM 的表现,验证了其作为统一架构的可行性。
未来方向:认为 VoRA 不仅限于视觉语言任务,其架构具备天然的模态泛化能力。未来的研究可围绕以下方向拓展:
-
跨模态泛化能力:通过替换视觉教师模型为音频、点云或生物医学信号模型,并使用相应模态的 LoRA 模块,VoRA 有望扩展为统一处理语音、3D 感知、生物信号等多模态任务的通用架构。
-
视觉 token 压缩优化:引入更高效的 token 压缩策略(如大 patch 划分、token 裁剪、聚合等)以进一步优化推理效率,特别是在高分辨率图像或视频处理任务中。
-
世界知识注入与领域扩展:融合包含丰富背景知识的数据(如百科图像、开放百科、医疗图像等),提升模型在现实世界复杂任务中的表现能力。
VoRA 是通往 “统一多模态智能(unified multimodal intelligence)” 的重要一步,一个架构可以处理多样模态与复杂任务,同时保持高效推理与可拓展性。
论文地址:https://arxiv.org/abs/2503.20680
项目页面:https://github.com/Hon-Wong/VoRA
进 Q 学术交流群:922230617 或加 CV_EDPJ 进 W 交流群


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









