




Wan: Open and Advanced Large-Scale Video Generative Models
目录
1. 引言
当前开源模型存在三大问题:性能与闭源模型差距大、应用场景有限、效率较低,限制了社区的发展。
本文提出了视频基础模型系列 Wan,旨在推动开放视频生成模型的边界。
- Wan 基于 Diffusion Transformer(DiT)和 Flow Matching 框架,设计高效架构,
- 通过创新的时空(spatio-temporal)变分自编码器(VAE)提升文本可控性与动态建模能力
- 模型使用超过万亿 tokens 的图像与视频训练,在运动幅度、质量、风格多样性、文本生成、摄像机控制等方面均展现强大能力
Wan 提供两个版本:适配消费级显卡的 1.3B 参数模型和能力强大的 14B 参数模型,支持包括图像生成视频、指令引导视频编辑和个性化视频生成在内的 8 项下游任务,是首个能生成中英视觉文本的模型。此外,Wan 1.3B 仅需 8.19GB 显存,显著降低部署门槛。
2. 相关工作
随着生成建模技术的发展,视频生成模型尤其是在扩散模型框架下取得了显著进展。相关工作主要可分为两个方向:闭源模型和开源社区贡献。
闭源模型方面,大厂主导的发展进度快速,目标是生成具备专业质量的视频。代表性模型包括:
-
OpenAI Sora(2024 年 2 月),标志性成果,极大推动视频生成质量;
-
Kling(快手)和Luma 1.0(Luma AI)(2024 年 6 月);
-
Runway Gen-3(2024 年 6 月)在 Gen-2 基础上优化;
-
Vidu(声树 AI,2024 年 7 月)采用自研 U-ViT 架构;
-
MiniMax Hailuo Video(2024 年 9 月)和 Pika 1.5(Pika Labs,2024 年 10 月);
-
Meta Movie Gen 和 Google Veo 2(2024 年 12 月)进一步增强物理理解与人类动态感知能力。
- 这些闭源模型借助强大算力与数据资源在生成质量、真实感、细节控制等方面具有优势。
开源社区方面,虽然起步略晚,但发展迅速,取得重要突破。现有视频扩散模型多数基于 Stable Diffusion 架构,由三个关键模块构成:
-
自动编码器(VAE):将视频压缩至潜空间,常见如标准 VAE(Kingma, 2013)、VQ-VAE(Van Den Oord, 2017)、VQGAN(Esser et al., 2021)等,近期 LTX-Video(HaCohen et al., 2024)更进一步提升重建质量;
-
文本编码器:多数使用 T5(Raffel et al., 2020)或结合 CLIP(Radford et al., 2021),如 HunyuanVideo 使用多模态大语言模型增强文本-视觉对齐;
-
扩散神经网络:多采用 3D U-Net 结构(VDM),或 1D 时间 + 2D 空间注意力结构(Zhou et al., 2022),最新架构则采用Diffusion Transformer(DiT)结构(Peebles & Xie, 2023),以 Transformer 替代 U-Net,在视觉任务中表现优越。
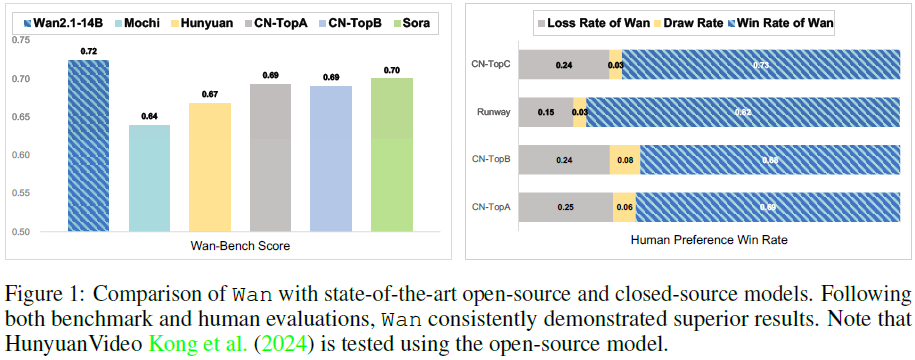
在此基础上,多个开源视频模型如 Mochi、HunyuanVideo、LTX-Video、CogVideoX 等相继发布。Wan 模型在此基础上精心选择与优化各核心组件,力求在生成质量上实现突破。
此外,开源社区也积极探索下游任务,包括图像补全、视频编辑、可控生成与参考帧生成等,常通过适配器结构或ControlNet增强用户控制能力。
Wan 不仅整合上述核心技术,还在多个下游任务上进行了系统设计与评估,推动生成模型从“能生成”向“能控制、高质量、可泛化”迈进。
3. 数据处理流程
高质量的大规模训练数据是生成模型性能的基石。Wan 构建了完整自动化的数据构建流程,以 “高质量、高多样性、大规模” 为核心原则,整理了数十亿级图像与视频数据。
数据分为 预训练(pre-training)数据、后训练(post-training)数据 和 视频密集描述(Dense Video Caption)三个阶段进行处理。
3.1 预训练数据
预训练阶段的数据来自内部版权素材与公开数据,通过以下四步筛选:
1)基础属性筛选:通过多维度过滤提升基础数据质量:
-
文本检测:使用轻量 OCR 过滤文字遮挡严重视频/图像;
-
美学评分:采用 LAION-5B 的打分器剔除低美感数据;
-
NSFW 评分:内部安全模型评估并移除违规内容;
-
水印 / LOGO / 黑边检测:裁剪干扰区域;
-
曝光异常检测:移除光感异常内容;
-
模糊与伪图检测:利用模型打分移除失焦和合成图(污染率 <10% 即可显著影响性能);
-
时长 / 分辨率限制:视频需大于 4 秒,且低分辨率视频按阶段剔除。
该流程去除约 50% 原始数据,为后续高语义挑选做准备。
2)视觉质量筛选:
- 数据首先聚类为 100 类,防止长尾数据缺失后影响分布,
- 再按每类选样本进行人工打分(1~5分),训练质量评估模型自动评分,选出高评分样本。
3)运动质量筛选:运动质量划分六档:
-
最优运动:运动幅度、视角、透视感良好,动作清晰流畅;
-
中等运动:运动明显但有遮挡或多主体;
-
静态视频:主要为访谈等高质量但动作少的视频,降低采样比例;
-
相机驱动运动:相机移动为主,主体静止,如航拍,采样比例较低;
-
低质量运动:场景混乱或遮挡严重,直接剔除;
-
抖动镜头:非稳定镜头导致的模糊失真,系统性剔除。
4)视觉文本数据构建:为提升视觉文本生成能力,结合两类数据来源:
-
合成路径:将中文字渲染在白底图上,构造数亿样本;
-
真实路径:从真实图像中提取中英文文本,结合 Qwen2-VL 生成详细描述。
- 该策略帮助模型学会生成稀有字词,显著增强视觉文字生成质量。
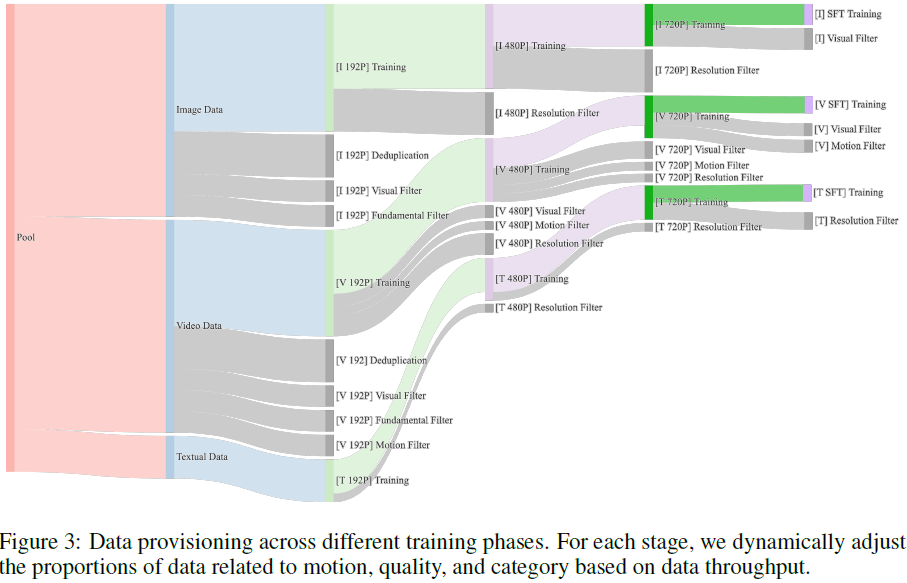
3.2 后训练数据
后训练阶段旨在提升模型生成视频的 清晰度与运动效果,分别对图像与视频数据采用不同处理策略。
-
图像数据:从评分较高图像中,采用专家模型选出前 20% 并手动补充关键概念,确保多样性与覆盖度,构成百万级高质量图像集。
-
视频数据:从视觉质量与运动质量双重评分中选取若干百万级视频,涵盖 “技术、动物、艺术、人类、交通” 等 12 大类,以强化泛化能力。
3.3 视频密集描述
为增强模型对指令的理解能力,Wan 构建了大规模密集视频描述数据集,涵盖图像与视频描述、动作识别、OCR 等多个维度,数据来源包括:
3.3.1 开源数据集
整合多种视觉问答、图像/视频描述数据集及纯文本指令数据,支持多维度理解与生成。
3.3.2 自建数据集
围绕若干核心能力设计:
-
名人/地标识别:通过 LLM 与 CLIP 筛选高质量图像;
-
物体计数:结合 LLM 与 Grounding DINO 进行一致性过滤;
-
OCR 增强:提取文本后再由模型生成描述;
-
相机角度与运动识别:人工标注+专家模型辅助增强控制能力;
-
细粒度类别识别:覆盖动物、植物、交通工具等;
-
关系理解:聚焦 “上下左右” 空间位置;
-
再描述:将短标注扩展为完整描述;
-
编辑指令生成:配对两图,生成描述差异的指令;
-
多图描述:先描述公共属性,再描述各自差异;
-
人工标注数据:最终训练阶段使用最高质量的图像 / 视频密集标注。
3.3.3 模型设计
(2023|NIPS,LLaVA,指令遵循,预训练和指令微调,Vicuna,ViT-L/14,LLaVABench)视觉指令微调
(2024|CVPR,LLaVA-1.5,LLaVA-1.5-HD,CLIP-ViT-L-336px,MLP 投影,高分辨率输入,组合能力,模型幻觉)通过视觉指令微调改进基线
(2024,LLaVA-NeXT(LLaVA-1.6),动态高分辨率,数据混合,主干扩展)
Wan 的描述生成模型采用 LLaVA 风格架构,结合视觉与语言多模态输入,设计要点如下:
-
视觉编码器:使用 ViT(Vision Transformer)提取图像和视频帧的视觉特征;
-
投影网络:视觉特征通过两层感知机投射至语言模型输入空间;
-
语言模型:使用 Qwen LLM(QwenTeam, 2024)作为生成器;
输入结构:
-
图像输入采用动态高分辨率切分为最多 7 块(patch),每块特征下采样为 12×12;
-
视频输入按每秒 3 帧采样,最多 129 帧;
Slow-Fast 编码机制:
-
每 4 帧保留原始分辨率;
-
其他帧采用全局平均池化;
-
显著提升长视频理解能力(如在 VideoMME 提升从 67.6% → 69.1%)。
该架构兼顾精度与效率,适配图像、视频、多图等不同输入类型。
3.3.4 模型评估
为自动化评估 Wan 的视频描述能力,团队设计了多维度评测流程,参考 CAPability(Liu et al., 2025b)方法:
评估维度(共10项):
-
动作(Action)
-
摄像机角度(Camera Angle)
-
摄像机运动(Camera Motion)
-
对象类别(Category)
-
对象颜色(Color)
-
计数能力(Counting)
-
OCR(视觉文字)
-
场景类型(Scene)
-
风格(Style)
-
事件(Event)
评估流程:
-
随机抽取 1000 个视频样本;
-
分别由 Wan 的模型与 Google Gemini 1.5 Pro 生成描述;
-
使用 CAPability 自动评分,计算每个维度的 F1 值。
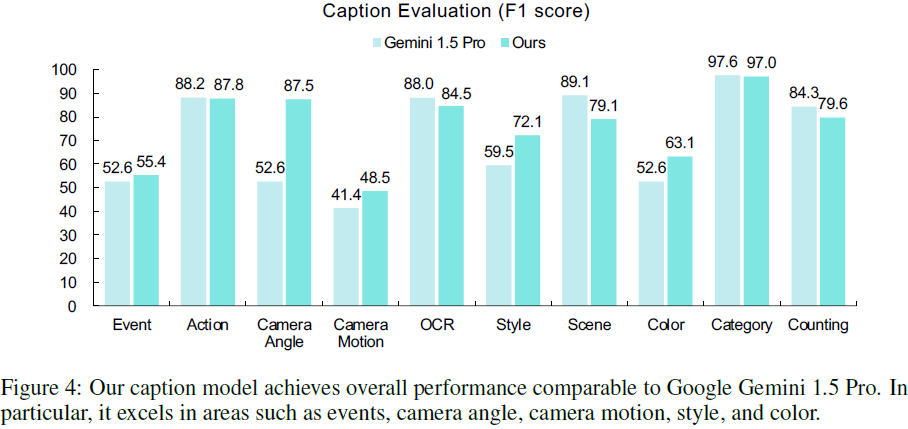
结果分析:
-
Wan 明显优于 Gemini 在:事件、摄像角度、摄像运动、风格、颜色;
-
Gemini 在 OCR、类别识别、动作理解等方面略占优势;
-
两者整体性能相近,Wan 在生成控制性与视频结构理解上表现更佳。
4. 模型设计与加速
Wan 模型基于 Diffusion Transformer(DiT)架构设计,包含自研时空变分自编码器 Wan-VAE、Diffusion Transformer 主干、文本编码器 umT5,以及一系列推理加速与内存优化机制。
4.1 时空变分自编码器
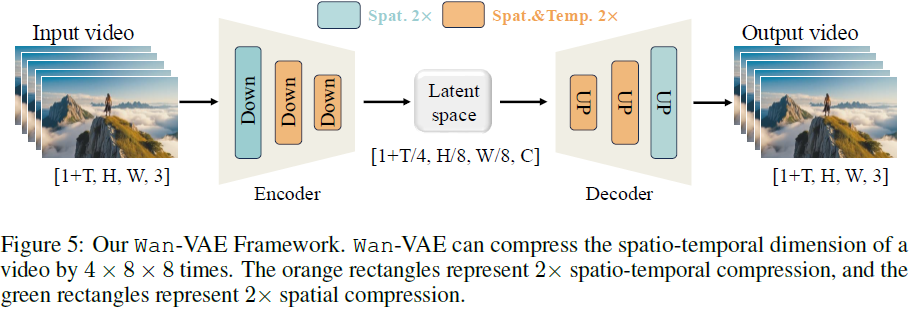
4.1.1 模型设计
为压缩高维度视频数据并保持时序一致性,Wan 设计了 3D 因果结构的 Wan-VAE,具备以下特点:
-
输入视频 V ∈ R^{(1+T) × H × W × 3} 经压缩得到潜变量 x ∈ R^{(1+T/4) × H/8 × W/8 × C},其中通道数 C = 16;
-
第一帧仅做空间压缩,参考 MagViT-v2;
-
所有 GroupNorm 替换为 RMSNorm 以保持时间因果性;
-
解码端特征通道减半,减少推理内存 33%。
Wan-VAE 参数量为 127M,显著小于同类模型。
4.1.2 训练
采用三阶段训练策略:
-
训练 2D VAE;
-
将其膨胀为 3D 结构,在低分辨率小帧数视频上训练;
-
微调至高分辨率、多帧数视频,加入 3D 判别器 GAN loss。
损失函数包括:
-
L1 重建损失;
-
KL 散度;
-
LPIPS 感知损失
-
加权系数:3,3e-6 ,3
4.1.3 高效推理

为支持长视频推理,引入 chunk-based 特征缓存机制:
-
每个 chunk 对应一组潜变量,缓存前一 chunk 的特征以实现上下文连续;
-
默认设置下使用 2 帧缓存,支持因果卷积;
-
对于 2× 时间下采样场景,采用 1 帧缓存与零填充。
该机制可推理任意长度视频,且在显存使用上优于传统方法。
4.1.4 评估
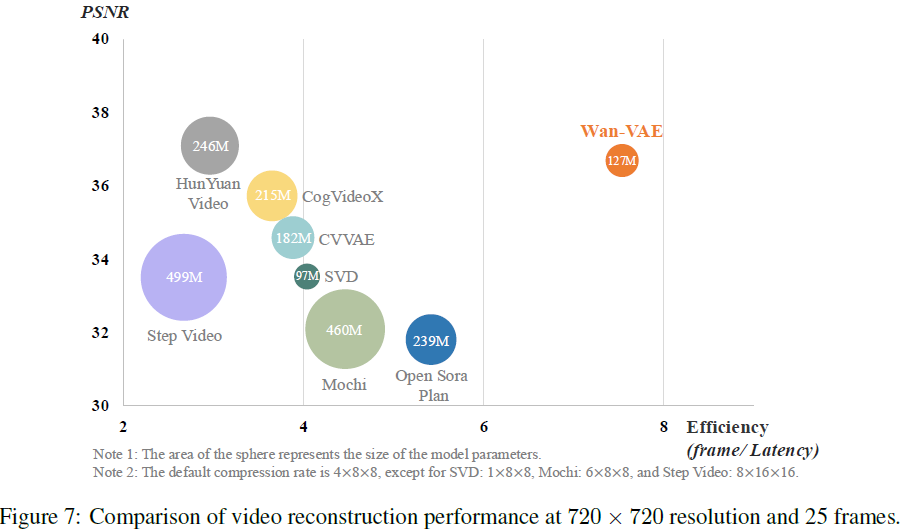
量化评估
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 176
176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









