







Tinygnn:学习高效的图神经网络
《TinyGNN: Learning Efficient Graph Neural Networks 》 2020-08-23
作者是 Bencheng Yan, Chaokun Wang, Gaoyang Guo, 和 Yunkai Lou 清华大学软件学院
论文地址见文末
摘要
近年来,图神经网络( Graph Neural Networks,GNNs )引起了广泛的研究兴趣,并在处理基于图的数据方面取得了巨大的成功。GNNs的基本思想是迭代地聚合邻居信息。经过k次迭代后,一个k层的GNN可以捕获节点的k跳局部结构。通过这种方式,更深层的GNN可以访问更多的邻居信息,从而获得更好的性能。然而,当一个GNN更深入时,邻域的指数级扩展会导致批量训练和推理的昂贵计算。这使得更深层的GNN远离了许多应用,例如实时系统。在本文中,我们尝试学习一个小型的GNN (称为TinyGNN ),它可以在较短的时间内获得较高的性能并推断节点表示。然而,由于较小的GNN不能像较深的GNN那样探索更多的局部结构,因此较深的GNN和较小的GNN之间存在一个邻居信息间隙。为了解决这个问题,我们利用对等节点信息对局部结构进行显式建模,并采用邻居蒸馏策略从更深层的GNN中隐式地学习局部结构知识。大量的实验结果表明,TinyGNN是经验性有效的,并且与更深层的GNN相比,取得了相似甚至更好的性能。同时,TinyGNN在所有数据集上获得了7.73 × - 126.59 ×的推理加速比。
1、引言
图结构数据在现实世界中无处不在,例如社交网络[ 7、16 ]、引文网络[ 8 ]和基于图的分子[ 21 ]。对图数据进行分析可以帮助我们理解图中对象之间的关系,提取有用的信息。近年来,许多工作都致力于利用图神经网络( Graph Neural Networks,GNNs )来分析基于图的问题。GNNs的目标是为图中的每个节点学习一个表示向量。然后,学习到的向量可以应用于许多基于图的应用,例如链接预测,节点分类和推荐系统[ 7、16、17、19、22]。
GNNs的一般思想是迭代地聚合每个节点的邻居信息。例如,GCN [ 12 ]通过加权平均邻居的信息来聚合邻居。GraphSAGE [ 8 ]提出了多种类型的聚合函数,包括均值聚合、LSTM聚合和池化聚合。GAT [ 21 ]采用自注意力机制[ 20 ],根据邻居对中心节点的重要性自适应地聚合邻居信息。经过k次聚合迭代后,学习到的节点表示向量可以捕获节点的k跳网络结构。这意味着更深层的GNN可以更好地表征局部结构,更有可能学习到更好的节点表示[ 12、24、27]。
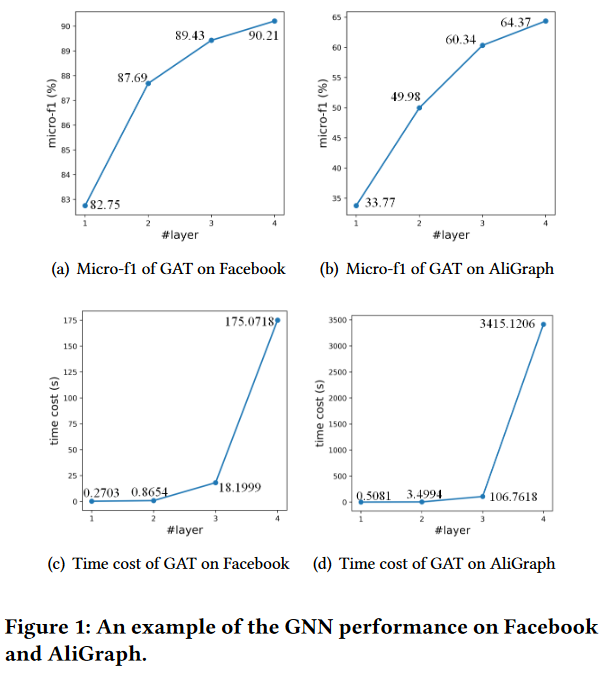
图1:GNN在Facebook和Ali Graph上的性能示例。
如图1 ( a ) ( b )所示。当增加GNN层数时,实例GNN (即GAT)的节点分类性能显著提高。具体图的细节( Facebook和AliGraph)可以在5.1节中找到。值得注意的是,由于过平滑问题[ 14、24] (见第5.6节)的存在,较深的GNN并不总能取得较好的性能。
虽然更深层的GNNs通常可以获得更多的邻居信息,从而获得更好的性能,但在批量训练和推理中,跨层邻域的递归扩展会导致昂贵的计算。图1 ( c ) ( d )给出了一个例子。当GNN更深时,推理的时间成本几乎呈指数增长。具体而言,在Ali Graph和Facebook上, 4层GNN的时间开销分别是1层GNN的近6721倍和648倍 。这表明更深层次的GNN很难应用于实际应用,尤其是实时系统。事实上,大多数现有的工作[ 3,13]在应用中只采用了1层GNN。
正如上文所讨论的,存在一个困境,即更深的GNN可以提供更高的性能,而对效率的要求则倾向于开发一个小的GNN。 在本文中,我们重点训练一个新的小型GNN,它可以很好地表征每个节点的局部结构,并且与现有的更深层次的GNN相比,可以获得相似甚至更好的性能 。面临的挑战是,一个小的GNN和一个更深的GNN之间存在着巨大的邻居信息鸿沟。例如,假设图中每个节点平均有10个邻居节点,4层GNN中每个节点的邻居数量是1层GNN中邻居数量的1000 × (包含重复节点)倍。这样的信息鸿沟导致了GNN之间的性能差距。为了解决这个问题, 我们提出了节点感知模块( 4.1节)和邻居蒸馏策略( 4.2节)来学习尽可能多的局部结构 。对于前者,它利用对等节点信息对局部结构进行显式建模 。对于后者,它采用蒸馏策略对局部结构进行隐式建模 。
本文的主要贡献总结如下:
( 1 )提出了一种小型、高效的GNN (称为TinyGNN) ,能够在较短的时间内获得较高的性能并推断节点表示。
( 2 )为了解决小GNN和大GNN之间的邻居信息鸿沟问题,我们提出了**对等感知模块( PAM )和邻居蒸馏策略( NDS )**来分别显式和隐式地建模局部结构。
( 3 )大量的实验结果表明,TinyGNN与更深层的GNN相比,可以获得相似甚至更好的性能,并且在所有数据集上的推理速度提高了7.73 × ~ 126.59 × 。
本文余下部分结构安排如下:第二节回顾了相关工作。第三部分是预备知识。第4节提出TinyGNN。第五部分报告了实验结果。第六部分对本文进行了总结。
2、相关工作
在这一部分,我们讨论了与本文相关的一些工作,包括图神经网络和知识蒸馏。
2.1 图神经网络
近年来,图神经网络( Graph Neural Networks,GNNs )方法在图表示学习中的应用引起了广泛关注。GCN [ 12 ]是针对图上半监督节点分类任务的开创性工作。在该模型中,作者将图滤波[ 2、5]中的切比雪夫多项式截断为一阶,并且通过归一化的图拉普拉斯自然地收集邻居信息。GraphSAGE [ 8 ]扩展了GCN的思想,提出了一种基于聚合的表示学习方法。基于GraphSAGE提出的框架,GAT [ 21 ]使用基于多头的自注意力机制过滤掉邻居中不重要的信息,并通过不同的权重来整合邻居信息。Graph AE [ 25 ]试图学习跨图的自适应节点表示。RECT [ 23 ]考虑了节点表示中的不平衡情况。
此外,也有一些工作关注GNNs中的效率问题。由于该问题的关键因素是递归的邻域扩展,因此这些工作大多试图设计一种更有效的策略来获取邻居。Ying等人[ 26 ]通过创建一个只包含中心节点及其邻居的子图来缓解这个问题,然后使用基于并行计算的策略来进一步提高效率。Chen等[ 4 ]提出了一种分层重要性采样来探索邻居,避免了指数增长的邻居。Huang等人[ 10 ]提出了一种逐层的自适应采样方法来考虑上层的节点。Bojchevski等人[ 1 ]将基于pagerank的值引入到邻域扩展中,并在一个(非递归)步骤中融入多跳邻域信息。实际上,他们大多试图通过设计新的邻居探索策略来解决这一问题。在本文中,我们提出了一个新的方向来解决这个问题,即训练小型图神经网络。此外,所提出的节点感知模块和邻居蒸馏策略是通用的方法,可以很容易地集成到现有的GNNs (包括上述效率导向的GNNs)中。
2.2 知识蒸馏
知识蒸馏[ 9 ]旨在将具有大量参数的网络中的知识压缩为一个紧凑且快速执行的模型。其核心思想是通过模仿深度模型(称为教师网络)生成的软目标(或类概率)来训练一个小型网络(称为学生网络)。这项技术有几种变体。例如,Romero等人[ 18 ]将教师网络学习到的中间表示作为额外的提示来提高学生网络的训练过程和最终表现。Huang等人[ 11 ]将知识蒸馏过程看作是特征分布的匹配,并采用了领域自适应[ 6、15]中的最大均值差异( Maximum Mean Discrepancy,MMD )思想。受知识蒸馏的启发,我们提出了一种邻居蒸馏策略( 4.2节)来隐式地从教师网络中学习每个节点的局部结构。
3、预备知识
3.1 注意事项
设图G = ( V、E),其中 V 为节点集,E 为边集。每个节点v∈V都有一个特征向量 xv和一个关联标签yv。定义N ( v )为节点 v∈V 的 1 跳邻居节点集合。进一步,我们将GNN层中节点v的N ( v )采样的节点定义为对等节点(见图2 ( b )),颜色相同的节点互为对等节点)。
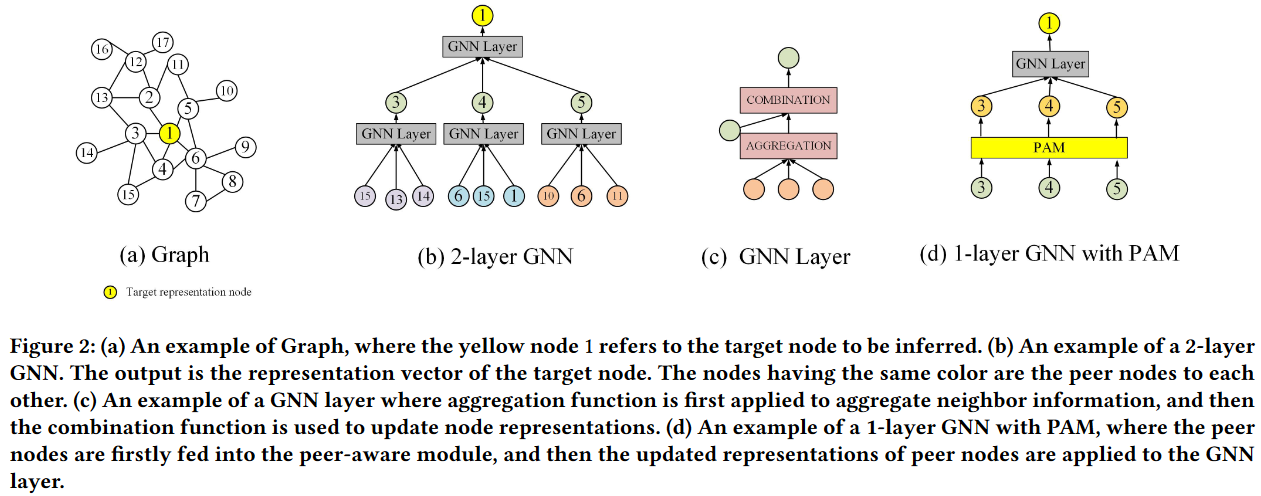
图2:( a )图的一个例子,其中黄色节点1指的是要推断的目标节点。( b )一个2层GNN的例子。输出为目标节点的表示向量。具有相同颜色的节点是彼此的对等节点 。( c )一个GNN层的例子,首先使用聚合函数来聚合邻居信息,然后使用组合函数来更新节点表示。( d )一个基于PAM的1层GNN的例子,首先将对等节点输入到对等节点感知模块,然后将对等节点的更新表示应用到GNN层。
对等节点 :
对等节点(peer nodes)指的是在图网络中与目标节点(center node)相邻的同一层的节点。在GNN的同一层中,与目标节点通过上层节点相连的节点。这些节点在没有直接连接的情况下,通过共同的上层节点相互关联。
假设我们有一
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 560
560











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











