







(GFKD)无图知识蒸馏
《Graph-Free Knowledge Distillation for Graph Neural Networks 》 2021
作者是 Xiang Deng 和 Zhongfei Zhang,来自纽约州立大学宾汉姆顿分校
论文地址见文末
摘要
知识蒸馏(Knowledge Distillation, KD)通过强制学生网络模仿在训练数据上预训练老师网络的输出,从而将知识从老师网络转移到学生网络。然而,在许多情况下,由于数据规模大、隐私或保密等原因,数据样本并不总是容易获取。对于卷积神经网络(CNNs),尽管已经做出了许多努力来解决这个问题,但这些基于CNN的方法往往忽略了图神经网络(GNNs),后者**处理的是非网格数据,具有不同的拓扑结构,位于离散空间内。**由于它们输入之间的固有差异,这些基于CNN的方法并不适用于GNNs。**在本文中,据我们所知,我们首次提出了一种专门的方法,用于在没有图数据的情况下从GNN中提取知识。我们提出的无图知识蒸馏(Graph-Free Knowledge Distillation, GFKD)通过将图拓扑结构建模为多变量伯努利分布来学习图拓扑结构,以实现知识转移。**然后,我们引入了一个梯度估计器来优化这个框架。本质上,关于图结构的梯度是仅通过使用GNN前向传播而不是反向传播来获得的,这意味着GFKD与现代GNN库(如DGL和Geometric)兼容。此外,我们提供了处理图数据或GNNs中不同类型的先验知识的策略。广泛的实验表明,GFKD在没有训练数据的情况下从GNNs中提取知识方面达到了最先进的性能。
代码: https://github.com/Xiang-Deng-DL/GFKD
1、引言
KD的目的是将一个训练有素的教师网络中的知识转移到一个更紧凑、更快速的学生网络中,以便在资源有限的设备上部署。然而,KD的一个强假设是训练数据集或某些代表性样本是可用的,这在数据不可用的情况下严重限制了其应用。
作者指出,尽管在卷积神经网络(CNNs)上已经做出了一些努力来解决数据不可用的问题,但在处理非网格数据和具有不同拓扑结构的离散空间数据的图神经网络(GNNs)上,这些基于CNN的方法并不适用。这是因为GNNs的输入不仅包括节点特征,还包括图的拓扑结构,而GNN的输出对于输入图的拓扑结构是不可见的。
为了解决这个问题,作者提出了一种名为图自由知识蒸馏(Graph-Free Knowledge Distillation, GFKD)的新方法,据他们所知,这是第一个专门为没有图数据的GNN量身定制的数据无关知识蒸馏方法。**GFKD通过模拟图的拓扑结构的多变量伯努利分布来学习图结构,并通过引入梯度估计器来优化框架。**这种方法避免了直接对图结构进行反向传播,因此与现有的GNN库兼容。
总结贡献:
- 我们引入了一个新的框架,即GFKD,用于从没有可观察的图数据的GNN中提取知识。据我们所知,这是第一个专门为GNN定制的无数据KD方法。我们还提供了处理图数据不同先验的策略(或正则化器),包括如何处理one - hot特征和degree特征。
- 我们利用多元伯努利分布开发了一种从预训练GNN中学习图结构的新策略,并引入梯度估计器对其进行优化,为从无可观测图的预训练GNN中提取知识铺平了道路。值得注意的是,当前的GNN库不支持输入图结构的梯度计算。GFKD避免了这一问题,因为GFKD中的结构梯度只使用GNN前向传播,而不使用后向传播。GFKD因此得到了这些库的支持。
- 我们使用两种不同的GNN架构,在不同的设置下,在不同领域的6个基准数据集上对GFKD进行了评估,并证明了GFKD在不同的数据集上都取得了最好的性能。
one - hot:
对于一个具有 n 个可能类别的离散特征,One-hot编码会创建一个长度为 n 的二进制向量,向量中只有一个位置是1,其余位置都是0。这个1表示该类别的存在,而0表示其他类别的缺失。
2、相关工作
- 图神经网络(GNNs):GNNs 是一种专门处理图结构数据的深度学习模型,近年来在多个应用领域显示出巨大潜力。作者们提到了几种不同的GNN架构,包括使用Chebyshev多项式、Weisfeiler-Lehman测试泛化的GINs,以及其他处理节点特征和拓扑结构的不同策略的模型。
- 知识蒸馏(KD):KD 是一种技术,旨在将教师模型的知识转移到学生模型中。Hinton等人在2015年提出了KD的概念,通过惩罚教师和学生之间软化的对数几率差异来实现。后续工作如FitNet和AT通过特征对齐进一步协助知识转移。还有研究提出了保持局部结构的模块,专门用于从GNN中提取知识。
- 数据无关的知识蒸馏:由于训练数据可能不可用,研究者们提出了不依赖于训练图像的知识蒸馏方法。这些方法通过生成假图像来实现知识转移,例如使用元数据、生成器-解码器框架、生成对抗网络(GANs)或通过逆向传播CNN和使用批量归一化统计数据生成假图像。
- GNNs的数据无关知识蒸馏:尽管上述方法在CNNs上取得了成功,但它们并不适用于处理非网格数据的GNNs。GNNs的数据不仅包括特征,还包括图的拓扑结构。因此,开发一种专门针对GNNs的数据无关KD方法是必要且迫切的。
3、框架
在这一部分中,我们首先对GNNs进行了简要的概述。然后,我们提出了GFKD和处理关于图数据的不同类型先验知识的策略。最后,介绍了GFKD的优化方案。
3.1 图神经网络
与处理网格数据的CNNs不同,GNNs可以将非网格数据作为输入。一个非网格数据可以表示为一个图G = { V,E }和一组特征h,其中V和E分别表示节点和边。其中,V和E分别表示节点和边。
公式1描述了图神经网络(GNN)中一个典型的层级操作,用于更新节点的特征表示。下面是公式1的具体内容以及解释:
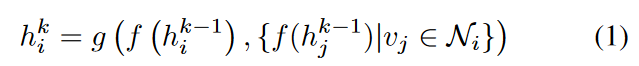
使用特征转换函数 𝑓转换该节点和该节点的邻居节点在k-1层的特征,再通过函数 g( ) 来聚合起来,形成当前节点在k层的特征。
这个过程通常被称为“邻居聚合”,是GNNs的核心机制之一,它允许网络通过图结构捕捉节点之间的复杂关系,从而学习到节点或图的高级表示。这种表示可以用于各种下游任务,如节点分类、图分类等。
3.2 无图知识提取
假设一个参数为W的教师GNN模型T ( . )在数据集( X , Y)上通过最小化正则交叉熵损失进行训练,其中X和Y分别为图数据和标签:
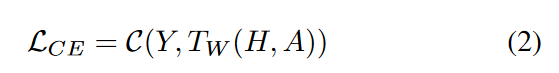
其中,
C ( . )表示损失函数,如交叉熵或均方误差;
H表示图X的节点特征;
A表示X的图结构信息,可以表示为由0s和1s组成的邻接矩阵。
当训练数据不可用时,但已知参数 W,目标是生成假的图数据样本,这些样本能够最大化教师网络输出的类条件概率,从而实现知识转移。遗憾的是,这并不适用于GNNs,因为从( 1 )式可以看出,LCE与图结构A不可微。
学习具有随机结构的图拓扑
在没有可观察图数据的情况下,我们需要找到一种方法来生成假的图数据,这些数据能够捕捉教师GNN的知识。由于GNN的输出对于输入图的拓扑结构是不可微分的,我们不能直接对图结构进行优化。
- 图结构的随机建模:**使用多变量伯努利分布来随机生成图的拓扑结构。**每个伯努利分布的参数 θij决定了节点 vi和 vj之间是否存在边。(以一定概率在两个节点之间生成连边)
- 节点特征的生成:为生成的图结构中的每个节点生成节点特征。这些特征可以是从先验知识中获得的,也可以是通过优化问题学习得到的,以便它们能够最大化教师GNN的输出概率。
- 标签的随机采样:为生成的图结构随机分配标签,这些标签用于训练学生网络,使其模仿教师网络的输出。
- 优化和迭代:通过最小化特定的损失函数来迭代地优化节点特征和图结构的参数,这个损失函数通常包括交叉熵损失和正则化项。
- 知识转移:使用生成的假图数据和相应的标签,通过知识蒸馏技术(如KL散度损失)将教师网络的知识转移到学生网络。
在论文中提到的假图数据(fake graph data)实际上是一个合成的数据集,它不是从真实世界中直接获取的,而是通过算法生成的。这些数据在结构和特征上模拟了真实图数据的特性,但它们并不对应于任何实际的图结构或节点特征。
生成这样的假图数据集的目的是在没有访问真实训练数据的情况下,依然能够从预训练的教师网络中提取和转移知识到学生网络。
先验知识的正则化器
什么叫先验知识?
先验知识,也称为priori knowledge,是指在学习或推理之前已经具备的知识。
在文中先验知识(Prior Knowledge)指的是在模型训练之前已经知道或假设的信息。
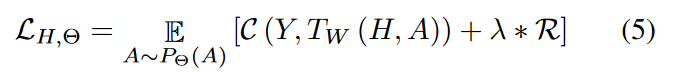
式中的H是特征矩阵
式( 5 )中的R ,也就是正则化器,处理了关于目标任务的图数据的不同类型的先验知识。我们提供了处理共同先验的策略。
正则化器:
正则化器的核心作用是控制模型的复杂度,以防止过拟合,并提高模型的泛化能力。正则化器作为损失函数的一部分,惩罚模型的某些特性,而不是直接衡量距离。
图神经网络中的先验
与卷积神经网络类似,许多GNN也受益于批量归一化( BN )。BN包含了数据的统计信息,因为它在训练过程中积累了均值的移动平均值和特征的方差。类似于CNNs [ Yin et al , 2020]中的情况,迫使假图数据具有与从真实图数据中积累的GNNs中相似的特征均值和方差是合理的:
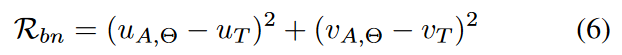
式中:UA,Θ和VA,Θ分别表示生成图特征的均值和方差;UT和VT分别是教师GNN中的均值和方差。
在论文中提到的GFKD方法中,批量归一化统计信息被用作一种先验知识,以帮助生成与真实数据具有相似统计特性的假图数据。这样做可以提高假图数据的质量,从而提高知识蒸馏的效果。
关于目标-任务图数据的先验
( 1 )one-hot特征:
One-hot特征(One-hot Encoding)是一种在机器学习和自然语言处理中常用的表示离散特征的方法,其实它的本质就是一种数据表示形式。它将离散特征的每个类别表示为一个二进制向量,除了表示该类别的一个位置是1之外,其余位置都是0。
许多任务的图数据具有one-hot特性,例如MUTAG上的分类任务。在这种情况下,直接最小化( 5 )不能导致one-hot特征。为了解决这个问题,我们首先用softmax函数σ ( ω )对式( 5 )中的H进行重新参数化,其中ω是可学习的参数,然后最小化σ ( ω )的熵:

(熵:一种用于量化预测结果的不确定性或随机性的指标,它是损失函数中的一部分。)
其中,Ent ( . )表示熵,σ ( ω )可以看作H的实例化。
( 2 )degree作为特征:
一些图数据使用节点的度作为特征。在这种情况下,特征可以从邻接矩阵A中导出。因此,不需要显式地学习特征H,目标( 5 )简化为:
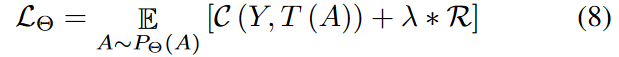
我们已经讨论了一些常见的图先验,而对于不同的图可能有其他的先验。幸运的是,目标( 5 )很容易扩展到不同的图数据。
优化
目标函数(公式(5))是一个期望损失函数,它依赖于 H 和 Θ,并且可能还包括一个正则化项 R。为了找到目标函数的最小值,通常需要通过梯度下降或其变体来迭代调整 H 和 Θ。
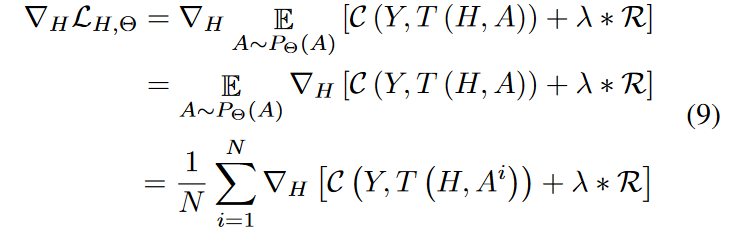
式中的: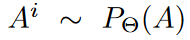 为独立同分布。
为独立同分布。
独立同分布(Independent and Identically Distributed,简称 i.i.d.)是概率论、统计学和机器学习中的一个基本概念,用来描述一组随机变量或数据点的特定性质。
为什么要用独立同分布?
在数学和统计学中,i.i.d. 假设可以显著简化涉及随机变量的问题的分析和计算。当我们假设生成的图数据是独立同分布的,我们可以更容易地估计梯度并应用随机优化算法。
为了估计关于结构参数 Θ 的梯度,需要对 A的期望进行计算。假设 A的元素是i.i.d.,可以使得梯度的估计变得更加可行,因为可以直接对每个元素的条件概率进行操作。
==难点在于梯度w . r . t的计算。==Θ存在于分布P Θ ( A )中。我们引入一个梯度估计量
为了简单起见,我们在下面的目标( 5 )中省略了λ * R。式( 5 ) 中的伯努利随机变量A可以由两个指数随机变量重新参数化:
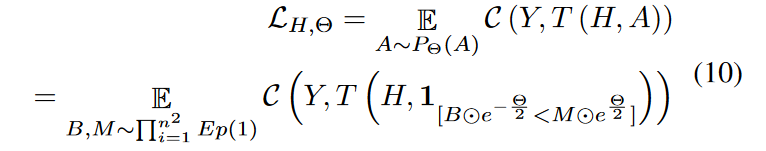
这个公式用于通过重参数化技巧来估计结构参数 Θ 的梯度。这个公式是基于指数随机变量的期望来重新表达损失函数,从而允许梯度的估计。目的是将原始的损失函数 𝐶(𝑌,𝑇(𝐻,𝐴))转换为一个可以更容易计算梯度的形式。
- LH,Θ:损失函数,依赖于特征参数 H 和结构参数 Θ。
- E:期望运算符,表示对随机变量的平均值。
- B和M:分别是 n2 维的随机变量,其中 n2 是图的节点数的平方,代表图的邻接矩阵的大小。这些变量遵循指数分布 Exp(1)。
- ⊙:表示元素乘法,即两个相同维度的矩阵或向量的对应元素相乘。
- e−Θ/2和eΘ/2:指数函数,用于变换结构参数Θ。
- 1[⋅]:指示函数,它在括号内的表达式为真时取值为1,否则为0。在这里,它用于创建一个伯努利随机变量,该变量以一定的概率取值为1,这个概率由 B 和 M 以及 Θ 决定。
- C(Y,T(H,A)):原始的损失函数,通常是基于教师网络 T 的输出和真实标签 Y 之间的比较。
通过使用指数随机变量 B 和 M,公式10允许我们利用重参数化技巧来估计梯度,而不需要对原始的伯努利分布直接进行反向传播。这样做的好处是,可以避免在反向传播过程中对图结构的不连续操作,从而使得整个优化过程更加稳定和高效。
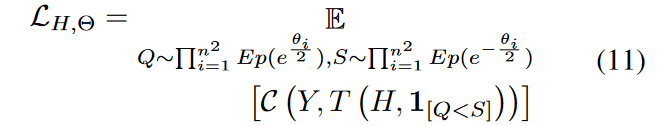
Q 和 S 是通过 B 和 M 以及结构参数 Θ 计算得到的新的随机变量。
下面说明如何获得梯度w . r . t Θ。将先验知识应用到( 11 )中得到:
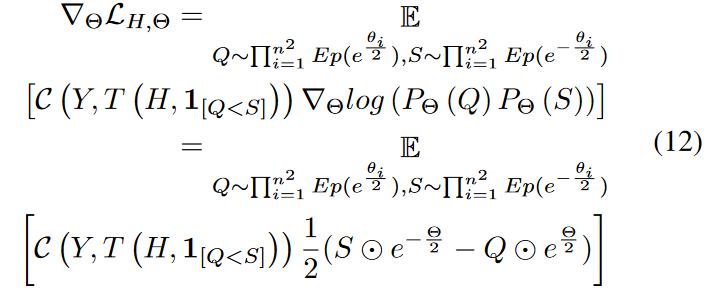
将公式11中的Q和S带入公式12中,即可得到公式13:
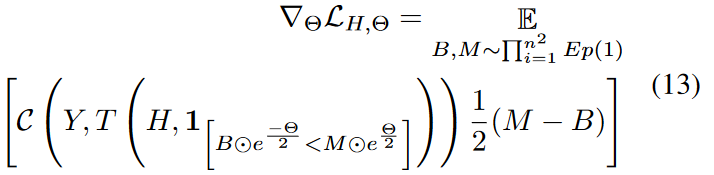
B和M可以进一步重新参数化为:
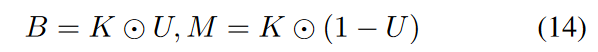
其中U和K分别表示均匀分布和伽马分布( 13 )可以进一步重新参数化为:
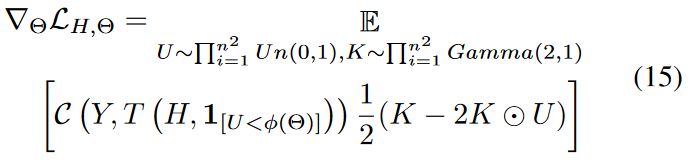
通过对( 15 )进行Rao - Blackwellization,得到了( 15 )的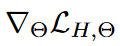 ,也就是相当于进行了梯度下降,其中Θ等于:
,也就是相当于进行了梯度下降,其中Θ等于:
Rao-Blackwellization:
Rao-Blackwellization是一种统计学技术,用于提高估计量的性能,特别是降低其方差。这一概念源自著名的Rao-Blackwell定理,该定理表明,如果一个估计量可以通过给定一个充分统计量的条件期望来改进,则在任何凸损失函数下,改进后的估计量都会有更低的方差或等同的方差
 等价于
等价于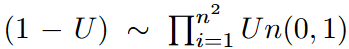
因此,可以将( 16 )中的U替换为1 - U,从而得到一个新的无偏梯度估计.取新估计量和( 16 )式的平均值,可以进一步降低抽样方差,得到公式17:
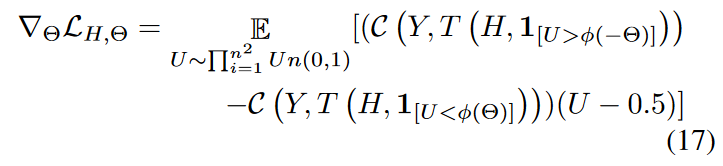
对U n( 0、1 )进行简单采样,即可得到梯度w . r . t。Θ
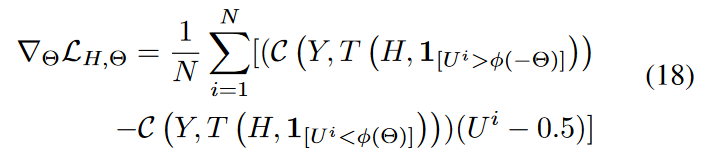
式中的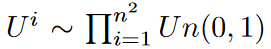 为iid(独立同分布).
为iid(独立同分布).
更多的推导细节在附录中给出。由于方差较小,本文将N设置为1。如( 18 )所示,这种无偏梯度估计器允许我们仅通过GNN前向传播来获得关于结构参数Θ的梯度,因此它是有效的,并得到了当前GNN库的支持。
利用生成的伪图进行知识迁移
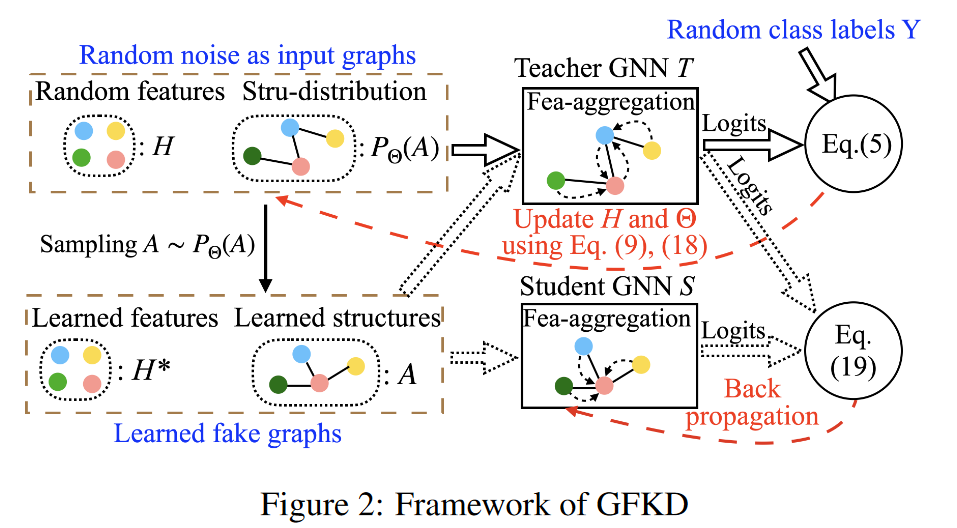
如图2所示,我们首先用梯度( 9 )和( 18 )分别最小化( 5 )来更新特征参数H和随机结构参数Θ。然后,我们通过使用H作为节点特征和从P Θ ( A )中采样来生成拓扑结构来简单地获得假图。教师GNN在这些图上输出的概率很高,因此知识更有可能集中在这些图上。然后利用这些带有KL散度损失的伪图数据x,将知识从教师传递给学生:
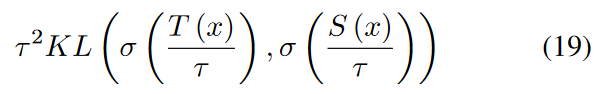
式中:**σ为softmax函数;Τ是生成软标签的温度,KL表示KL散度;S为学生GNN。**最终,我们在没有任何可观测图的情况下实现了知识蒸馏。
4、Experiments
在这一部分,我们报告了评估GFKD的大量实验。值得注意的是,我们的目标不是生成真实的图,而是在不使用任何训练数据的情况下,将尽可能多的知识从预训练的教师GNN转移到学生身上。
4.1 实验设置
我们采用了6个图分类基准数据集。包括3个生物信息学图数据集MUTAG、PTC和PROTEINS,以及3个社会网络图数据集IMDB - B、COLLAB和REDDITB。这些数据集的统计数据汇总在表3中。
在每个数据集上,70 %的数据用于教师的预训练,剩下的30 %作为测试数据。
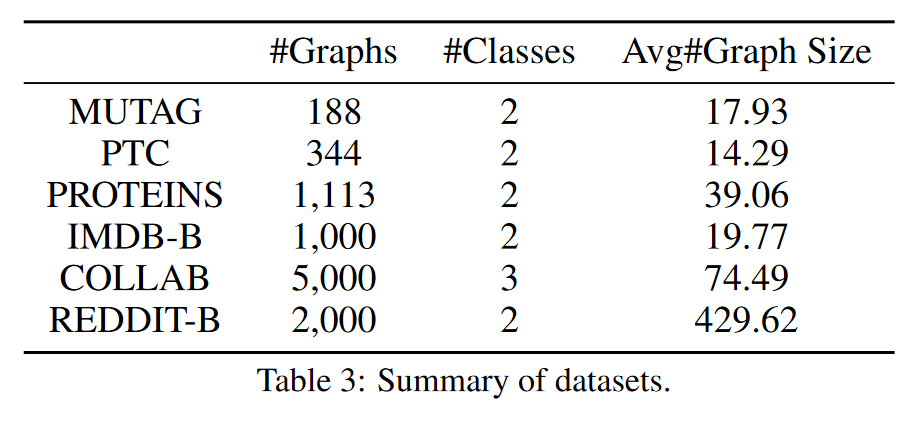
我们使用了两个著名的GNN架构,即GCN [基普夫和韦林, 2017]和GIN [ Xu et al . , 2019]。我们在两种不同的环境中提取知识,即教师和学生共享相同的架构或使用不同的架构。我们用(架构层数量特征维度)的形式表示一个GNN。例如,GIN - 5 - 64表示一个具有5个GIN层和64个特征维度的GNN。
由于在没有可观测的图数据的情况下,没有现有的方法适用于GNNs来提取知识,我们设计了两个基线以供参考:
• 随机图( Random Graphs,RandG ):RandG通过从均匀分布中随机抽取作为节点特征和拓扑结构生成伪图,然后利用这些图进行知识迁移。
• Deep Inv G:由于原始的Deep Inversion [ Yin et al , 2020]无法学习图数据的结构,这里Deep Inv G首先随机生成图结构,然后使用Deep Inversion学习节点特征,目标为C( Y , T ( H , A) ) + Rbn。
为了生成伪图,我们进行了2500次迭代。结构和特征参数的学习率分别设置为1.0 ( 5.0对PROTEINS、COLLAB和REDDIT - B的影响)和0.01,每1000次迭代除以10。对于KD,使用Adam对所有GNN进行400个历元的训练,学习率从1.0线性递减到0,τ设置为2。更多的细节在附录中给出。
4.2 在生物信息学图数据上的实验
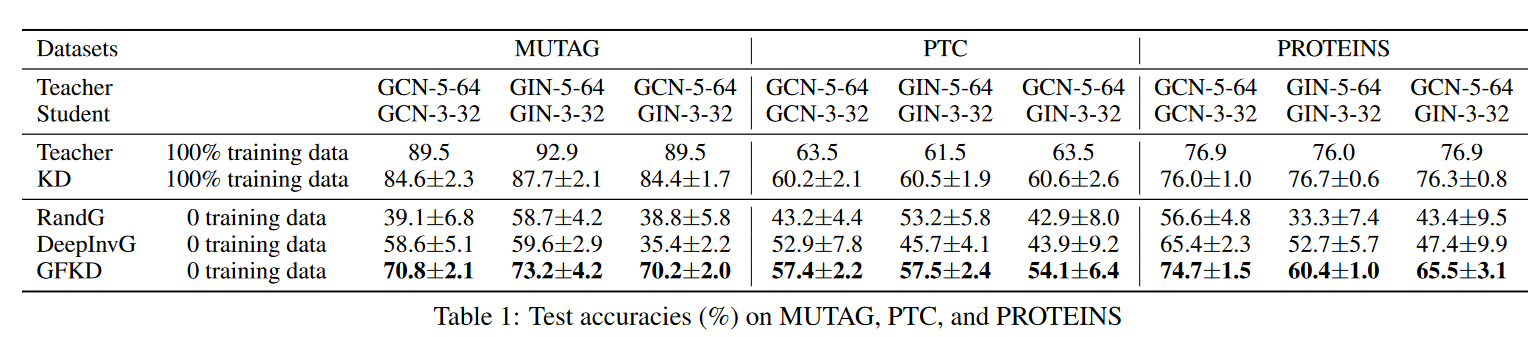
表1报告了在3个生物信息学图数据集上的比较结果。可以观察到,在不使用任何训练数据的情况下,GFKD在不同数据集和架构之间传递的知识比基线多得多,这证明了GFKD的有效性。正如预期的那样,Rand G的整体表现比其他方法差,因为教师的知识并不集中在随机图上。GFKD和Deep InvG都是针对伪图学习节点特征,但不同之处在于GFKD学习图结构,而Deep InvG随机生成结构。
如表1所示,GFKD比DeepInvG的精度有了很大的提高。例如,在MUTAG上使用教师GCN - 5 - 64和学生GCN - 3 - 32,GFKD的精度比Deep InvG提高了12.2 %。这说明了GFKD对于学习图结构的有效性。我们还注意到,在不同结构的师生对( GCN - 5 - 64和GIN - 3 - 32 )中,GFKD在三个数据集上都显著优于基线,这表明GFKD适用于教师和学生具有不同结构的情况。
4.3 在社交网络图数据上的实验

为了考察GFKD在不同领域的泛化性,我们进一步在3个社交网络图数据集上进行实验。表2报告了对比结果。值得注意的是,在三个数据集上,节点特征都是由图结构导出的节点(或一个常数)的度。于是,Deep InvG被还原为RandG。可以看到,GFKD在3个社交网络数据集上的表现也都明显优于基线,说明了GFKD对于不同类型图数据的泛化性和有用性。GFKD的优越性归因于其能够学习图数据的拓扑结构。
4.4 消融研究
关于伪图数量的消融研究
理论上,GFKD可以生成无限个假图用于知识转移。然而,质量和多样性受限于受过预训练的教师。我们研究了GFKD的性能如何随着伪样本数量的变化而变化。我们用 r 表示假图的数量与教师使用的训练样本数量的比值。
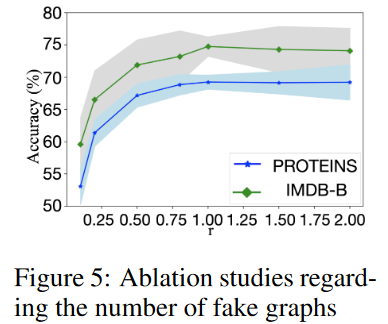
图5展示了假图数量的影响,其中GCN - 5 - 64和GCN - 3 - 32分别被用作教师和学生。这并不奇怪,GFKD的性能先增加后稳定。性能稳定的原因是生成图的多样性受到预训练教师的约束。
关于正则化器的消融研究
我们引入了两个正则化器分别处理BN和one - hot特征。我们用GCN - 5 - 64和GCN3 - 32分别作为教师和学生来评估它们对GFKD性能的影响。我们采用MUTAG和PTC数据集,因为它们的特征是one - hot的。

比较结果如图3所示,其中GFKDw/obn,GFKDw/ooh和GFKDw/obnoh分别表示没有BN正则化器,没有one - hot正则化器和没有这两种正则化器的GFKD。我们观察到,在没有这两种正则化器的情况下,性能显著下降,这证明了这两种正则化器的有效性和实用性。同时,这也表明更多关于图数据的先验知识会带来更好的性能。红色是使用了正则化器。
4.5 可视化
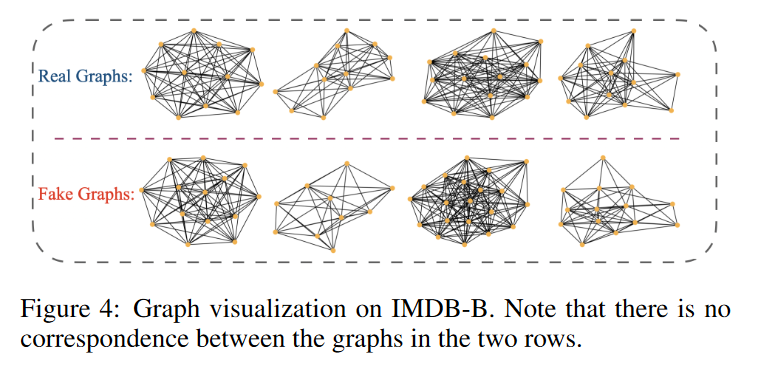
虽然GFKD的目标不是生成真实的图数据,但是我们在图4中展示了GFKD学习到的一些伪图,其中伪图是在IMDB - B上从预训练的教师GCN - 5 - 64学习到的。可以观察到,假图和真实图有一些视觉上的相似性。
为了进一步考察GFKD能否从这些伪图中学习到具有判别性的特征,我们使用 t - SNE 对不同方法学习到的特征进行可视化。本实验采用GCN - 5 - 64和GCN - 3 - 32分别作为教师和学生。

图6展示了Rand G、GFKD和教师学习到的特征的可视化。可以观察到,Rand G学习到的特征表示对于不同的类是混合的,这表明使用随机生成的图无法学习到具有判别性的特征。相比之下,GFKD学习到的特征对于不同的类具有很好的区分性,并且与教师学习到的特征具有同样的区分性。这说明GFKD学习到的伪样本有利于表示学习,知识集中在这些伪图上。
5、结论
在本文中,我们研究了一个新颖的问题,即如何在没有可观测图数据的情况下从GNN中提取知识,并引入GFKD作为解决方案,这是迄今为止该方向的第一项工作。为了学习教师的知识集中在哪里,我们提出用多元伯努利分布对图结构进行建模,然后引入梯度估计量对其进行优化。本质上,结构梯度可以通过仅使用GNN前向传播获得。在6个基准数据集上的大量实验证明了GFKD在无可观测图的GNNs中提取知识的优越性。
















 934
934











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











