







描述性统计

统计数据类型分类
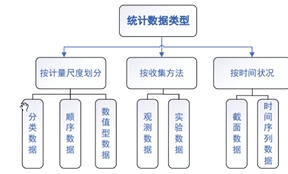
按计量尺度划分
分类数据
能归于某一类别的非数字数据,数据是对事进行分类的结果,结果表现为类别,用文字来描述。
例如:人口按照性别(男、女),企业按照所处行业(医药、家电、纺织品等)。
顺序数据
能归于某一有序类别的非数字数据,顺序数据虽然有类别,但是这些类别是有序的。
例如:将产品分为(一等品、二等品、三等品、次品),学习成绩分为(优秀、良好、及格、不及格)。
数值型数据
具体的数值,生活中处理的大部分都是数值型数据
例如:年龄、体重(KG),身高(CM)
按收集方法划分
观测数据
通过调查或观测获得的数据
实验数据
通过实验获得的数据,例如新药(实验过程中的各项数据)、新农作物(实验数据)
按时间状态划分
截面数据
相同或者近似相同的时间节点上不同空间收集得到的数据,用于描述现象在某一时刻的变化。(时间相同、维度不同)
例如:2020年某汽车品牌在全国不同地区的销售量
时间序列数据
不同时间收集到的数据,用于描述现象随时间变化的变化情况(时间不同,维度相同)。
例如:2018-2024年某汽车在某地区每个月的销量情况。
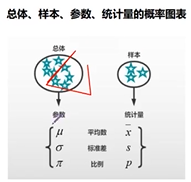
总体和样本
总体
研究的全部个体(数据)的集合。
例如:多个企业构成的集合,多个居民构成的集合
样本
从总体中抽取一部分元素的集合,构成样本的数目称为样本量
抽样目的是根据样本提供的信息推断出总体的特征。
比如:从一个流水线上抽取一百件商品,通过这一百件商品的合格率来推断,这批商品的合格率
参数
用来描述总体的概括性数字度量,总体的某些特征值。
例如:总体平均数、总体方差、总体标准差、总体比例等。
统计量
用来描述样本的概括性数字度量,样本的某些特征值。
例如:样本平均数、样本标准差、样本比例等。
总体、样本、参数、统计量对比
变量
定义
数值会发生变化的量,特点是从一次观察到下一次观察结果呈现出差别(变化)。变量的具体取值称为变量值。
分类
分类变量
事务类别的一个名称,取值是分类数据。(例如:性别、对错)
顺序变量
事务有序类别的一个名称,取值是顺序数据。(例如:产品等级分为‘一等品’、‘二等品’、‘三等品’、‘残次品’)
数字型变量
事务数字特征的一个名称,取值是数值型数据。(例如:商品销售额、销量、单价)
集中趋势分析
- 一组数据向其中心值靠拢的倾向和程度
- 测试集中趋势就是寻找数据水平的代表值或中心值
- 不同类型的数据用不同的集中趋势测量值
- 低层次数据的测度值适用于高层次的测量数据,但高层数据的测度值并不适用于低层次的测量数据
众数和中位数
众数
性质
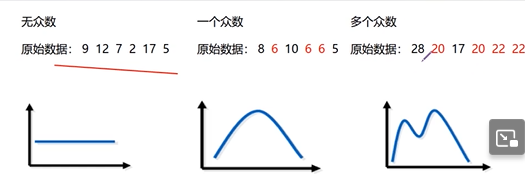
- 一组数据中出现最多的变量值
- 适用于数据量较多时使用
- 不受极端值的影响
- 一组数据可能没有众数或有几个众数
- 主要用于分类数据,也可用于顺序数据和数值型数据
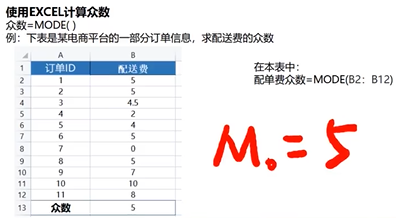
案例
使用M来表示

Excel函数
Mode()
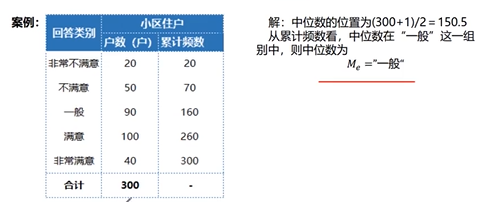
中位数
性质
- 排序处于中间位置上的值(偶数为中间两个值的平均值)
- ※不受极端值的影响
- 主要用于顺序数据,也可用于数值型数据,但不能用于分类数据
- 各变量值与中位数的离差(差值)绝对值之和最小
案例

Excel函数
median()

平均数(均值)
- 集中趋势的最常用测量值
- 一组数据的均衡点所在
- 体现了数据的必然特征
- 易受极端值的影响
- 有简单平均数和加权平均数之分
- 根据总计数据计算的称为平均数,记为μ;根据样本计算的称为样本平均数,记为x-bar
总体平均数是一个定值,样本平均数会随着样本的不同而变化
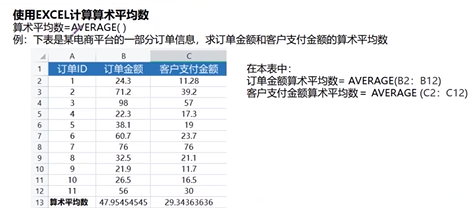
算术平均数
Excel函数
average()
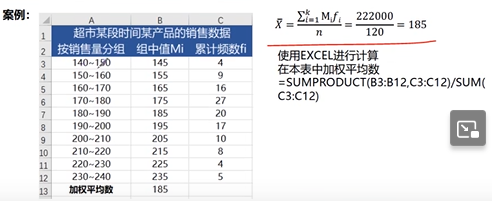
加权平均数
算数平均数默认每个数的权重都是相等的,加权平均数给每个数据赋予权值

Excel函数
sumproduct(平均值列:权数列)/sum(权数列)
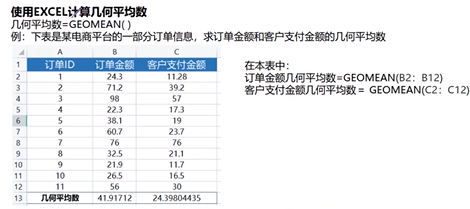
几何平均值
N个变量的N次方


Excel函数
geomean()
四分位数
性质
- 排序后处于25%和75%位置上的值
- 不受极端值的影响


Excel函数
quartile(范围,1/2/3)
1代表上四分位(75%)
2代表中位数(50%)
3代表下四分位(25%)

众数、中位数、平均数区别


离散程度分析
离散趋势
- 数据分布的另一个重要特征
- 反应各变量远离其中心值的程度(离散程度)
- 从另一个侧面说明了集中趋势测度值的代表程度
- 不同类型的数据有不同的离散程度测度值
分类数据:异众比率
非众数组的频率占总频数的比例

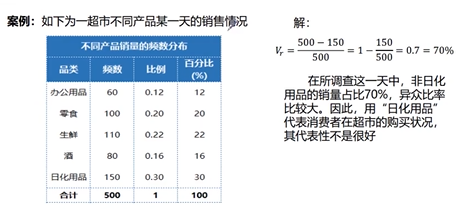
顺序数据:四分位差
对顺序数据离散程度的测度,也称为内距或四分间距,为上四分位数与下四分位数之差,反应中间50%数据的离散程度;不受极值的影响,用于衡量中位数的代表性

数据型数据:方差、标准差(开根号)
数据离散程度的最常用测度值,反应了各变量值与均值的平均差异,根据总体数据计算的,称为总体方差(标准差),根据样本计算的称为样本方差。
性质
数据离散程度的最常用的测量值,反映了各变量与均值的平均差异,根据总体计算的称为总体方差(标准差),根据样本计算的称为样本方差(标准差)。
分组和未分组区别
未分组就是正常算所有元素与平均数之差的平方再处于元素个数
分组就是每组是一个单位(比如10-20组之间平均数是15,元素个数5,就是在这个组之内求一下标准差,然后乘5(频数)然后和各组累加最后再除总元素个数)

 相对位置的度量:标准分数
相对位置的度量:标准分数
性质
对某一个值在一组数据中相对位置的度量,可以判断一组数据是否有离群点,对于变量的标准化处理,计算公式“标准分数=(样本值-样本均值)/标准差”说的就是某个数与平均数相差多少个标准差
相对离散程度:离散系数
性质
标准差与其相应的均值之比,对数据相对离散程度的测量,消除了数据水平高低和计量单位的影响,用于对不同组别数据离散程度的比较,计算公式“离散系数=标准差/均值”越大说明离散程度大
S代表标准差(标准差越小说明离散程度越集中(不准确))数据量级不同,因此引入了离散系数

偏态
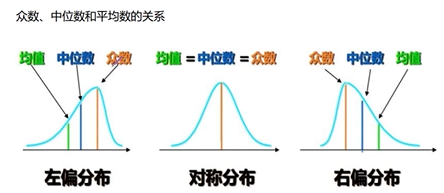
平均数大于中位数,正偏态(右偏)
平均数小于中位数,负偏态(左偏)
性质
1、数据分布偏斜程度的度量
- 偏态系数=0为对称分布
- 偏态系数>0为右偏分布
- 偏态系数<0为左偏分布
- 偏态系数>1或<-1,被称为高度偏态分布;偏态系数在0.5~1之间称为中等偏态分布;偏态系数越接近0,偏斜程度就越低
2、偏态系数是已经去量纲(除以标准差)的参数


案例

Excel函数

峰态
性质
1、数据分布扁平程度的测量
- 峰态系数=0扁平峰度适中
- 峰态系数<0为扁平分布
- 峰态系数>0为尖峰分布
2、峰态系数是已经去除量纲后的参数(除以标准差)

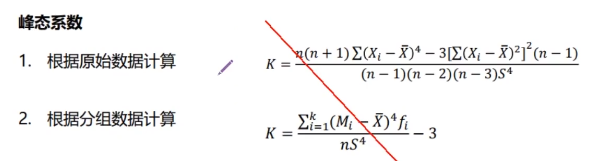
案例

Excel函数















 286
286











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









