






目标检测
评估概念:
TP:被正确划分为正例的个数、FP:被错误划分为正例的个数、FN:被错误划分为负例的个数、TN:被正确划分为负例的个数。
P-R曲线表示召回率与精确率之间的关系,如下图所示:
yolo检测
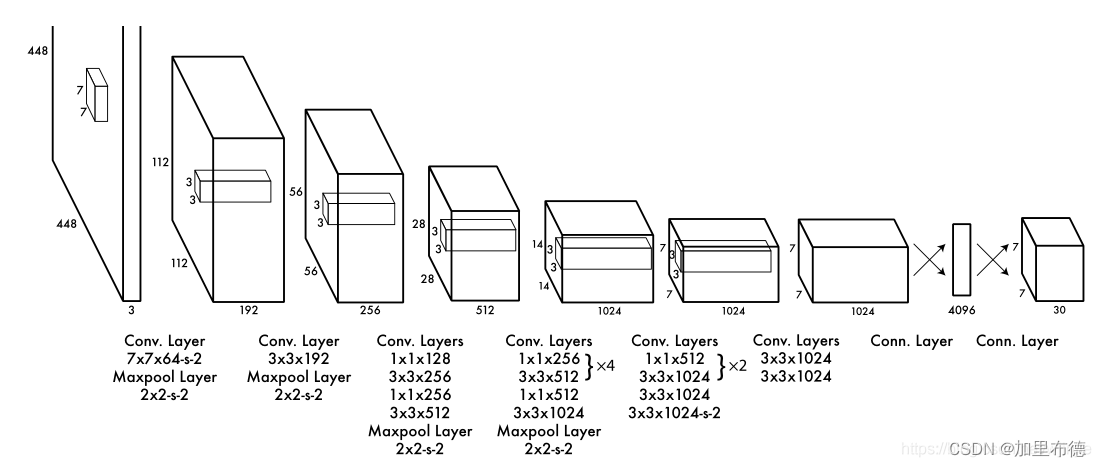
YOLOv1的网路结构非常明晰,是一种传统的one-stage的卷积神经网络:
- 网络输入:448×448×3的彩色图片。
- 中间层:由若干卷积层和最大池化层组成,用于提取图片的抽象特征。
- 全连接层:由两个全连接层组成,用来预测目标的位置和类别概率值。
- 网络输出:7×7×30的预测结果。
损失由三部分组成,分别是:坐标预测损失、置信度预测损失、类别预测损失。
使用的是差方和误差。需要注意的是,w和h在进行误差计算的时候取的是它们的平方根,原因是对不同大小的bounding box预测中,相比于大bounding box预测偏一点,小box预测偏一点更不能忍受。而差方和误差函数中对同样的偏移loss是一样。 为了缓和这个问题,作者用了一个比较取巧的办法,就是将bounding box的w和h取平方根代替原本的w和h。定位误差比分类误差更大,所以增加对定位误差的惩罚。
在每个图像中,许多网格单元不包含任何目标。训练时就会把这些网格里的框的“置信度”分数推到零,这往往超过了包含目标的框的梯度。从而可能导致模型不稳定,训练早期发散。因此要减少了不包含目标的框的置信度预测的损失。
(1)优点:
YOLO检测速度非常快。标准版本的YOLO可以每秒处理 45 张图像;YOLO的极速版本每秒可以处理150帧图像。这就意味着 YOLO 可以以小于 25 毫秒延迟,实时地处理视频。对于欠实时系统,在准确率保证的情况下,YOLO速度快于其他方法。
YOLO 实时检测的平均精度是其他实时监测系统的两倍。
迁移能力强,能运用到其他的新的领域(比如艺术品目标检测)。
(2)局限:
YOLO对相互靠近的物体,以及很小的群体检测效果不好,这是因为一个网格只预测了2个框,并且都只属于同一类。
由于损失函数的问题,定位误差是影响检测效果的主要原因,尤其是大小物体的处理上,还有待加强。(因为对于小的bounding boxes,small error影响更大)
YOLO对不常见的角度的目标泛化性能偏弱。
语义分割
语义指具有人们可用语言探讨的意义,分割指图像分割。语义分割即能够将整张图的每个部分分割开,使每个部分都有一定类别意义。和目标检测不同的是,目标检测只需要找到图片中目标,打上框然后分出类别。语义分割是以描边的形式,将整张图不留缝隙的分割成每个区域,每个区域是一个类别,没有类别的默认为背景background。
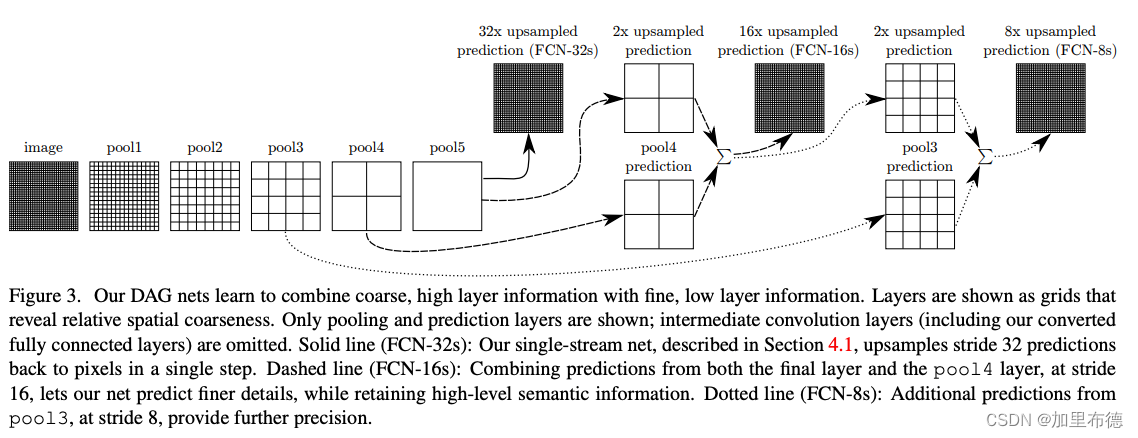
FCN 方法是第一个基于深度学习的分割方法,只包含卷积层,原CNN中的全连接层使用1×1卷积层进行替代,可以输入任意大小的图然后生成其分割结果图。

FCN-32s:直接将 pool5 的输出,上采样到原图大小,做预测,从图 4 可以看出,预测的结果非常粗糙(mIoU 59.4)
FCN-16s:将 pool5 上采样 2 倍,和 pool 4 特征进行相加,然后上采样到原图大小,结果会比 32s 的精细一些(mIoU 62.4)
FCN-8s:将 pool5(上采样2倍)和 pool4 相加后的特征,先上采样 2 倍,然后和 pool3 相加,得到 FCN-8s 特征(mIoU 62.7)
















 3221
3221











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









