







本文是基于
(https://blog.csdn.net/weixin_42612434/article/details/83005212)和(https://zhuanlan.zhihu.com/p/27910430)的总结和自己的一些理解(更详细的注释),因为刚学完学校python做期末课题,所以借此对python数据分析方面的一些知识进行应用
数据来源是上面链接中网盘下载
这里利用课程论文的思路去描述:
数据导入:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from datetime import datetime
%matplotlib inline
%matplotlib inline是个魔法函数:可以在Ipython编译器里直接使用,功能是可以内嵌绘图,并且可以省略掉plt.show()这一步
columns = ['user_id', 'order_dt', 'order_products', 'order_amount']
df =pd.read_csv(r'D:/CDNOW_master.txt', names = columns, sep = '\s+')
由于原数据没有表头,手动输入,并以任意空格|s+为分隔符号
这里最好不要用pd.read_table,会弹警告
D:\pyyyth\lib\site-packages\ipykernel_launcher.py:2: FutureWarning: read_table is deprecated, use read_csv instead.
显示未来可能出问题,所以换成pd.read_csv
基本数据
df.info()
查看下读取后的数据集概况

这个数据集是被预处理过的,所以没有空值
df.describe()
这是个统计函数,可以获得平均值、最大值、最小值、标准差等很多信息

平均每笔订单购买2.4个商品,而标准差在2.3,波动不算大。中位数在2个商品,而75分位在3个商品,可以看出大部分订单购买的商品都不算多,最大值在99个,所以大部分订单都集中在小额,此数据符合二八模型,也就是说80%左右的用户贡献小额消费,20%左右的而用户贡献大额消费。
df.head()
这个函数读取前5行

基于用户分析
user_grouped=df.groupby('user_id').sum()
user_grouped.head()
利用groupby创建一个新对象user_grouped

可以直观的看出用户的消费量
user_grouped.describe()

从用户角度每个用户平均购买7个产品,最多的购买了1033个产品,用户的平均消费额在106元,而标准差在240,波动较大;且在50%分位的消费只才3个和43元,而到75%分为的消费值才和平均值接近,所以存在小部分的大额消费用户聚集在75%分为以上,即为存在小部分大额消费用户。
基于时间
df.groupby('month').order_amount.sum().plot()

可以看出第一个季度的销量非常高,而后面的销量都很平稳,这种趋势是异常的,可能的原因猜测是应为促销或者统计的早期用户出了问题,有异常值。
用户质量分析
复购率分析
pivoted_counts=df.pivot_table(index='user_id',columns='month',values='order_dt',aggfunc='count').fillna(0)
#对消费次数进行数据透视,利用userid做索引,month做列,用count方法计算order_dt出现次数(统计有多少必订单)
#有空值(NaN)用0进行填充
cloumns_month=df.month.sort_values().astype('str').unique()
pivoted_counts.columns=columns_month
pivoted_counts.head()
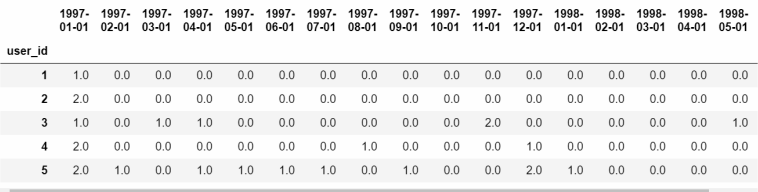
这里统计了具体次数,观察发现只有0-2次三种情况,所以进一步规范可以得出更直观的数据。
pivoted_counts_transf=pivoted_counts.applymap(lambda x:1 if x>1 else np.NaN if x==0 else 0)
#applymap()将自定义的匿名函数lambda作用于df的所有元素,两次返回1,一次NaN,零次返回0
pivoted_counts_transf.head()
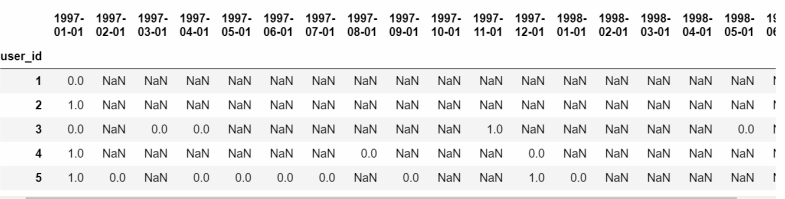
利用applymap对每个元素进行转换后可以直观看出复购情况,为了直观观察复购率,所以转换成折现图观察
(pivoted_counts_transf.sum()/pivoted_counts_transf.count()).plot(figsize=(10,4))
#复购次数/样本数量=复购率

替代法计算复购率:sum()和count()都会忽略NaN,所以复购率统计了消费两次以上的用户数量占全部用户数量的百分比
可以看出回购率在早期因为大量新客户加入所以不高,1997-01就只有6%,而后因为稳定的客源,老客户的回购率上升后就稳定在20%左右,新客和老客的回购率差距在三倍左右。
回购率分析
#对消费金额进行透视,用平均值统计
pivoted_amount = df.pivot_table(index='user_id',columns='month',values='order_amount',aggfunc='mean').fillna(0)
columns_month=df.month.sort_values().astype('str').unique()
pivoted_amount.columns =columns_month
pivoted_purchase=pivoted_amount.applymap(lambda x:1 if x>0 else 0)
pivoted_purchase.head()

pivoted_amount = df.pivot_table (values = 'order_dt', index= 'user_id', columns = 'month', aggfunc = 'count').fillna(0)
#转化数据,有过购买的为1,没有购买的为0
pivoted_purchase = pivoted_amount.applymap(lambda x: 1 if x>0 else 0)
pivoted_purchase.head()
#定义函数,每个月都要跟后面一个月对比下,本月有消费且下月也有消费,则本月记为1,下月没有消费则为0,本月没有消费则为NaN,由于最后个月没有下月数据,规定全为NaN
def purchase_return(data):
status = []
for i in range(17):
if data[i] == 1:
if data[i+1] == 1:
status.append(1)
if data[i+1] == 0:
status.append(0)
else:
status.append(np.NaN)
status.append(np.NaN)
return pd.Series(status)
#应用并且绘图
pivoted_purchase_return = pivoted_purchase.apply(purchase_return, axis = 1)
pivoted_purchase_return.head()

因为回购率是指连续购买的概率,所以要写一个函数purchase_return来统计连续购买的概率并化成表
(pivoted_purchase_return.sum()/pivoted_purchase_return.count()).plot(figsize=(10,4))

回购率=回购人数/总人数
由图可以看出用户的回购率高于复购率,波动性较强,新用户回购率在15%左右,老客的差距不大。
由回购率和复购率可知,新客质量高于老客,而老客的忠诚度(回购率)较好,消费频次稍次;所以应该努力留住新客,多发放优惠等给新客,而老客也应该有所挽留避免流失。
销售额分布
user_amount = df.groupby('user_id').order_amount.sum().sort_values().reset_index()
#建立一个新对象对订单数求和并从小到大排序
user_amount['amount_cumsum'] = user_amount.order_amount.cumsum()
#cunsun是累加函数,累加计算金额
user_amount.tail()

按照用户id计算订单数并求和,然后用cumsum()对每个用户的所有订单金额求和
amount_total=user_amount.amount_cumsum.max()
#计算金额总和
user_amount['prop']=user_amount.apply(lambda x:x.amount_cumsum/amount_total,axis=1)
#转换成百分比
user_amount.tail()

转换成百分比
user_amount.prop.plot()
 横坐标是用户排序,纵坐标是贡献所占百分比,可以看出前20000个用户贡献了40%的销售额,之后的4000人用户贡献了60%的销售额,符合二八分布;同时也体现了此数据的长尾效应,应该对小额消费进行刺激,从而达成小额消费者像大额消费者转化。
横坐标是用户排序,纵坐标是贡献所占百分比,可以看出前20000个用户贡献了40%的销售额,之后的4000人用户贡献了60%的销售额,符合二八分布;同时也体现了此数据的长尾效应,应该对小额消费进行刺激,从而达成小额消费者像大额消费者转化。
销售量分布
user_counts = df.groupby('user_id').order_dt.count().sort_values().reset_index()
user_counts['counts_cumsum'] = user_counts.order_dt.cumsum()
counts_total=user_counts.counts_cumsum.max()
user_counts['prop']=user_counts.apply(lambda x:x.counts_cumsum/counts_total,axis=1)
user_counts.prop.plot()

也符合二八分布
用户生命周期
user_purchase=df[['user_id','order_products','order_amount','order_date']]
#按用户id分组后按消费的最后一天和最早一天排序
order_date_min=user_purchase.groupby('user_id').order_date.min()
order_date_max=user_purchase.groupby('user_id').order_date.max()
(order_date_max-order_date_min).head(10)

因为上面统计得出用户多数1-3月注册,所以得出的是用户1-3月注册到最后一次消费的生命周期。
life_time['life_time']=life_time.order_date/np.timedelta64(1,'D')
#转换单位
life_time[life_time.life_time>0].life_time.hist(bins=100,figsize=(12,6))
#将生存周期不到一天的排除后做直方图

可以看出生命周期在1天的用户虽然也多,但是在20天左右顾客开始迅速下降,而到了120天左右用户已经降到最低点,所以应该在20天和120天给用户选择性的递送优惠券等尽量留住顾客。
life_time[life_time.life_time>0].life_time.mean()
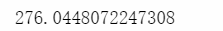
可以得出用户的平均生命周期是276天左右,所以也应该在此时间点进行一定的优惠活动留存顾客。
用户留存率
user_purchase_retention = pd.merge(left = user_purchase, right = order_date_min.reset_index(), how = 'inner',
on = 'user_id', suffixes=('', '_min'))
#merge类似于sql的join,将用户消费表和用户最早开始消费的时间内联在一个表里
user_purchase_retention['order_date_diff'] = user_purchase_retention.order_date-user_purchase_retention.order_date_min
#得出用户留存时间order_date_diff
user_purchase_retention['date_diff'] = user_purchase_retention.order_date_diff.apply(lambda x: x/np.timedelta64(1,'D'))
#转换成标准形式
user_purchase_retention.head(10)

利用merge函数得出用户至今留存时间
bin = [0,30,60,90,120,150,180]
#给出0-30天,30-60天的距离分组
user_purchase_retention['date_diff_bin'] = pd.cut(user_purchase_retention.date_diff, bins = bin)
#pd.cut用给出的bin的距离给数据分组计算购买总额
pivoted_retention= user_purchase_retention.groupby(['user_id','date_diff_bin']).order_amount.sum().unstack()
#按照用户id和区间排序,unstack()规定不能折叠
pivoted_retention.head()

用透视得出用户在第一次消费后的在后续各个时间段的消费总额
pivoted_retention_trans = pivoted_retention.fillna(0).applymap(lambda x: 1 if x >0 else 0)
#NaN用0填充,并将回购次数大于0的转化为1,其余为0
(pivoted_retention_trans.sum()/pivoted_retention_trans.count()).plot.bar()

同样用之前的方法将所赐消费的转为1其他转为0从而得到用户留存率,可以发现第一个月的留存路在45%左右,而第二个月就将到35%,后面就稳定在25%左右,说明在前三个月留住顾客十分重要,如何在前三个月进行积极的营销也是需要注意的重点。
问题总结
1)导入数据后时间显示问题

order_dt(购买日期)现在是一串数字没有太多意义
解决:
对order_dt进行转换
df['order_date']=pd.to_datetime(df.order_dt,format="%Y%m%d")
df['month']=df.order_date.values.astype('datetime64[M]')
df.head()
法一:导入的datetime库可以调用to_datetime()对特定字符串或者数字转换成时间格式,format用于参数匹配。
%Y——4位年份(这里的1997等)
%m——2位月份(这里的01)
%d——2位日期(这里的01)
%h——小时
%M——分钟,和月份大小写区分
%s——秒
法二:利用pandas自带astype转换,[M]转换成月份,所以转换后具体哪一天会被模糊成01,也就是只计入每月1日。选择月份做主要事件窗口因为对于小额消费来说按具体天数计算太琐碎,按照年份过于模糊。
2)基于月份分析时销售集中在前三个月,后面销售额断崖式下降,这种数据是异常的。

解决:
根据日常经验可以假设是用户的原因(用户注册时间等)、统计误差原因、销售网站的原因(促销活动等),每一个我们进行一定的分析来排除。
假设①:网站促销
df.plot.scatter(x='order_products',y='order_amount')

绘制每笔订单的散点图,可以看出有消费金额和商品量有一定的规律,在消费金额在0-20的时候消费量没有在1000以上的,而价格在30-100等高价的时候就包括了大部分1000件以上的订单,可以看出不是促的原因,数据也符合其低额销量少,高额销量多的特点。
假设②:统计误差
df.groupby('user_id').sum().plot.scatter(x='order_amount',y='order_products')

绘制用户散点图,可以看出用户消费金额和商品量成正比,离群点极少,所以用户的消费规律性也很强,比较健康。
假设③:用户原因
消费量统计
plt.figure(figsize=(12,4))#指定宽和高
plt.subplot(121)#换分为1行2列组成的区块,并获取到第一块区域
df.order_amount.hist(bins=30)#hist绘制直方图,指定20竖条
plt.subplot(122)
df.groupby('user_id').order_products.sum().hist(bins=30)

用plt.subplot绘制两个子图,分别是1行2列的两个区块,可以看出大部分消费者消费能力不高,都集中在0-200元区间,高消费的用户几乎看不到。
第一次消费时间统计
df.groupby('user_id').month.min().value_counts()

groupby之后求月份的最小值并计数,也就是求出每个用户第一次消费的月份,并统计每个月份第一次消费的用户数,可以清晰的看出所有用户都是在1-3月进行第一次消费,所以可以得出数据可能是统计了某个时段内注册开始消费的用户在之后18个月的消费行为。
这也可以解释为什么大部分消费都在1-3月,因为大部分用户都在这几个月份注册并进行第一次消费。
最后一次消费时间统计
df.groupby('user_id').month.max().value_counts()
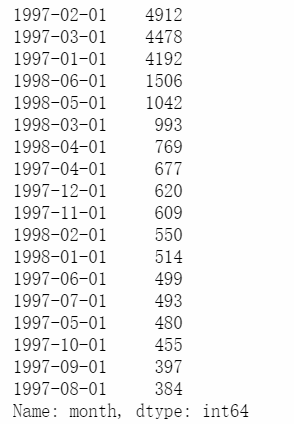
同样可以看出大部分用于在1997的1-3月进行消费后面逐渐减少,1998的5-6月的消费也偏多,可以看出大部分用户在第一次消费之后就不再消费,消费量也逐月减少。
综上所述,用户消费集中在1-3月是因为此数据集给出的是1-3月注册购买的用户的数据,所以1-3月的购买量极高。
3)统计时间(年月日)出现具体时间点的问题
统计完之后本来希望的列名称只是具体月份,但是因为利用pandas自带astype转换,[M]转换成月份,时间也模糊成了(00:00:00),这些时间点是没有意义的。

解决:
cloumns_month=df.month.sort_values().astype('str').unique()
pivoted_counts.columns=columns_month
转换成str型截掉时间(时分秒)就可以去掉

4)数据类型不允许用于绘图

得到的生命周期类型是timedelta64无法用于绘图
解决:
调用numpy的timedelta函数,用所得时间去除以这个函数(‘D’表示天,1表示一天)
除完之后就是标周期天数,就可以用于绘图
((order_date_max-order_date_min)/np.timedelta64(1,'D')).hist(bins=15)
#数据类型是timedelta时间,无法做直方图,所以除timedelta函数,‘D’表示天,1表示一天,所以除完之后就是标周期天数
但是得到生命周期之后发现大量用户聚集于0(也就是第一次消费处),这样子不利于观察后面的数据,所以排除只是在注册时消费的。
life_time=(order_date_max-order_date_min).reset_index()
#按照生命周期重新排序
life_time.head()
**life_time['life_time']=life_time.order_date/np.timedelta64(1,'D')
#转换单位
life_time[life_time.life_time>0].life_time.hist(bins=100,figsize=(12,6))
#将生存周期不到一天的排除后做直方图**

最后对几个统计常用指标的公式和作用总结一下
-
复购率
购买次数大于1次的人/所有购买过的人=复购率 指消费者对该品牌产品或者服务的重复购买次数,重复购买率越多,则反应出消费者对品牌的忠诚度就越高,反之则越低。 -
回购率
连续两月购买人次/所有购买过的人=回购率 指消费者第一次购买之后30天内再次购买的概率,反映新用户的忠诚度,波动性等。 -
用户生命周期
最后一次消费时间-第一次消费时间 从用户第一次消费到用户最后一次消费持续的时间,体现了用户对产品的使用时间。 -
用户留存率
某段时间内留存用户数量/新增用户数量 每隔一段时间“有多少用户留下来了”,体现了应用的质量和保留用户的能力。














 3757
3757











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









