









Deep Long-Tailed Learning: A Survey
Deep Long-Tailed Learning: A Survey-论文地址
引言
长尾数据是指数据失衡,数据集中类别数量存在分布不均衡问题,典型的长尾数据集数据分布如下图所示:
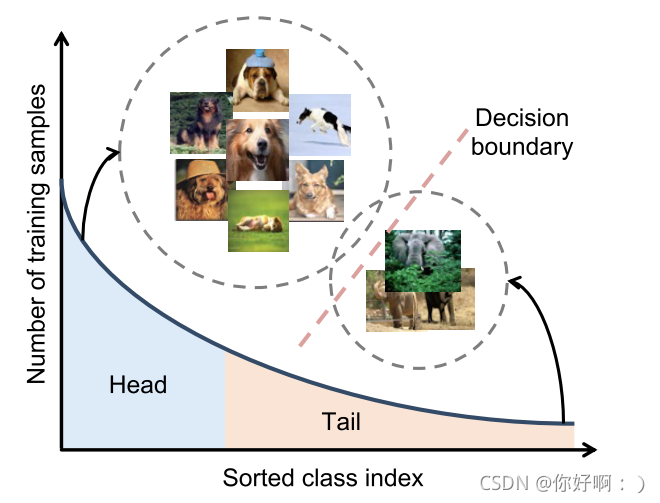
长尾学习
- 在数据分布不平衡的情况下,能够训练良好的深度学习模型。
- 在长尾数据集中,通用的视觉识别模型容易偏向Head部数据,而忽视tail数据。
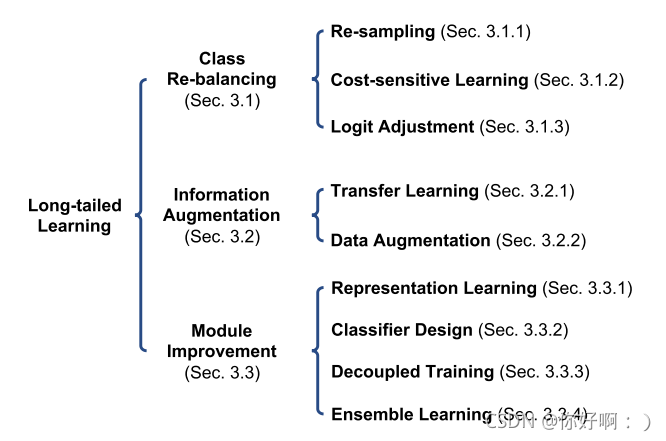
- 长尾数据的学习研究主要分为三大类:
- 类重新平衡(class re-balancing)
- 数据增强(informaton augmentation)
- 模块改进(module improvement)
介绍
在实际应用中,训练样本通常呈现长尾类分布,其中一小部分具有大量样本点,而其他类仅有少数样本。在这种训练集下,经过训练的模型很容易偏向于具有大量训练数据的头部类别,导致在数据有限的尾部类上模型性能较差。
下面是长尾数据集学习的方式如下:
本文通过一个全新的指标“相对准确度”(Relative accuracy metric),对长尾效应解决的SOTA方法进行评估
问题定义与基本概念
问题定义
长尾学习寻求从具有长尾类分布的训练数据集中学习深度神经网络模型,即其中一小部分类具有大量样本,其余类仅与少量样本关联。主要面临挑战是:
- 数据数量不平衡使得深度模型偏向于头类,而在尾类上表现不佳
- 尾类样本的缺乏使得训练模型进行尾类分类更具挑战性。
- 类不平衡:类不平衡可以看做是包含长尾效应的,但是类不平衡有时候类别数目比较少,而长尾学习中有大量的类并且尾部数据更加的稀少
- 少样本学习:少样本学习可以看作是长尾学习的一个子任务,在长尾学习中尾部样本数目通常非常少。
- 域外泛化学习:指的是训练集和测试集分布不一致,包括数据边际分布、不一致类别分布、以及两种的组合情况。长尾学习可以看作域外泛化的特定任务。

类平衡方法
现在的长尾学习方法,主要包含类别重平衡、信息增强、模型提升。
- 类平衡:重采样、重新加权分类损失、逻辑调整
- 信息增强:数据增强、迁移学习
- 模型增强:特征学习、分类器设计、解耦训练、集成学习
类重平衡
Re-Sampling
常见的采样平衡方式主要是有Random under-sampling和random over-sampling,通过减少头部数据的采样或者过多的采样尾部数据,可能分别导致头部数据的检测表现下降或者尾部数据出现过拟合。另外有两种现阶段的方法如下:
- Class-balanced re-sampling:Instance-balanced sampling 表示每个实例抽样概率相同,Class-balanced sampling表示每个类别选取的概率是相同。
· Square-Root sampling(文献117) — 取样本的平方根概率。
· Progressively balanced sampling(文献32) — 在Instance-balanced sampling 和 Class-balanced sampling中渐进插值。
· bi-Level class-balanced(文献34) — 结合图像级采样和实例级采样。
· Dyanmic curriculum learning(文献75) — 从一个类中抽样越多,一个类的的概率越低。
· Balanced meta-softmax(文献86) — 提出元学习方法,通过平衡元验证集优化模型分类器性学习最佳样本分布参数。
· FASA(文献103)— 通过使用平衡元验证集上的模型分类损失(作为度量)来调整不同类别的特征采样率。
· LOCE(文献33)— 建议使用平均分类预测分数(即运行预测概率)来监控不同类别上的模型训练,并指导记忆增强特征采样以增强尾部类别性能。
· VideoLT(文献38)— FrameStack在训练期间根据运行模型的性能动态调整不同类的采样率,以便可以从尾部类(通常运行性能较低)中采样更多的视频帧,从头部类中采样更少的帧。 - Scheme-oriented sampling:为长尾学习提供一些特定的学习方案,如度量学习和集成学习
· LMLE (文献66)— 提出一个五元采样器,对四组对比,一组正样本,三组负样本
· Truplet loss (文献118)— 两两对比样本
· Partitioning reservoir sampling(文献82) — 提出一种在线记忆算法,能动态维护数据
· Bilateral-branch network (文献48)— BBN对传统分支采用均匀采样,模拟原始长尾训练分布;同时,BBN在重平衡分支上采用了反向采样器来采样更多的尾类样本,以提高尾类性能。最后的预测是两个网络分支的加权和。
·LTML (文献77) — 将双边分支网络扩展到长尾多标签分配问题。
· GIST (文献102)— 也探索了头部到尾部的迁移学习问题。
· BAGS(文献78)— 将数据按样本数目划分为多个小组,分别进行预测
· LST(文献77)— Class balanced data reply strategy进行数据平衡
Cost-sensitive Learning Cost-sensitive
处理类别不平衡的方式主要包括class-level re-weighting 和 class-level re-margining.
- Class-level re-weighting:优化标签频率对损失的影响
· (文献105)— 基于样本的影响
· (文献29)— 模型预测和平衡之间的对齐
· (文献86)— 提出使用标签频率调整训练过程中的模型预测
· LADE(文献31)— 介绍了标签分配Disentangling loss学习训练过程中的长尾分布
· CB(文献16)— 引入effective number(训练样本数量的指数函数),通过与有效样本数反比的方式进行类平衡
· Focal loss (文献68) — 将更高的权重分配给尾部数据,头部数据获得更低的权重。
· Meta-Weight-Net (文献76)— 通过学习得到类别权重,元学习
· DisAlign(文献29)— 通过最小化调整后的预测分布和给定平衡参考分布之间的KL-Divergence
· EQL(文献19)— 当尾部样本使用头部样本作为负样本时,减少loss权重
` EQLV2(文献91) — 分为子任务,每个子任务专注一个类
· Seesaw loss(文献92)— 使用两个参数提高Loss和抑制Loss
· Adaptive class suppression loss(文献93)— 根据输出的置信度是抑制梯度 - Class-level re-margining :调整不同类学习功能与模型分类器之间的最小边界(距离)
· label-distribution-aware margin (LDAM)(文献18)
· Bayesian estimate (文献72)
Logit Adjustment
Information Augmentation
Transfer Learning
- 迁移学习-Transfer Learning:在长尾学习领域,主要在头部到尾部的迁移学习、模型预训练学习、知识蒸馏、自训练。
Data Augmentation
- 数据增强:对数据进行增强,但是常规的增强手段往往不能直接应用,需要对类别进行调整。
Module Improvement
主要分为四个部分:
- (1) representation learning improves the feature extractor—基于表征学习的特征提取器;
- (2) classifier design enhances the model classifier—分类器设计的增强分类器模型;
- (3) decoupled training boosts the learning of both the feature extractor and the classifier—解耦训练提高特征提取和分类器学习;
- (4) ensemble learning improves the whole architecture—集成学习改善整个架构
Representation Learning
主要包含 Metric Learning、Sequential trianing、Prototype Learning 和Transfer Learining
- Metric Learning:目的是建立物体之间相似性或者不相似性,在长尾学习中是探索目标之间的距离损失,学习更具判别特征空间
- Sequential trianing:数据不同的排布训练模式,按照特定顺序进行训练,感觉有点像两阶段解耦训练的方式。
- Prototype Learning :新的网络结构,开放世界检测/记忆力等方式
- Transfer Learining:权重文件的不同加载
Decoupled Training
第一阶段学习特征的表达,第二阶段学习分类

















 4144
4144

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









