










我们要用一个神经网络来近似策略函数,这个网络叫做策略网络。它可以用来控制agent去运动。
策略函数
策略函数记作为π(a|s),它是一个概率密度函数,我们可以使用它来控制agent去运动。策略函数的输入是当前状态s,输出是一个概率分布,给每一个动作一个概率值。
下图是超级玛丽游戏的例子

只要有了好的策略函数π,我们可以使用它来控制agent去运动。问题是怎么得到这样的策略函数呢?我们需要用函数来近似,学出一个函数来近似策略函数。函数近似有多种多样:线性函数、神经网络等。如果用神经网络,就将其叫做policy network记作

θ是神经网络的参数,一开始参数是随机初始化的,然后通过学习进行改进参数。
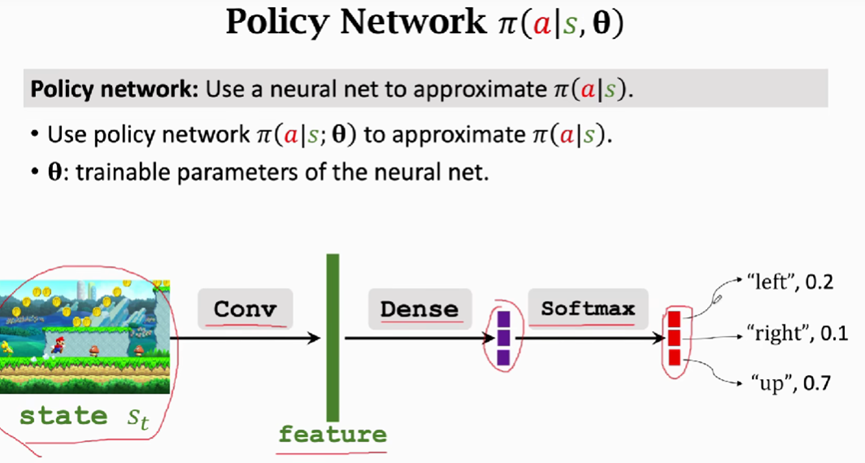
以超级玛丽的游戏为例
将屏幕上的画面作为输入,用一个或多个卷积层将画面变成特征向量,使用全连接层将特征映射成三维向量,使用softmax激活函数(softmax可以将输出的都是正数而且加和等于1),这样的输出是一个概率分布,输出是一个三维向量,每一个元素对应一个动作,里面的值是动作的概率
策略梯度
策略梯度的两种形式

假如动作是离散的就可以使用第一个
举例:

假如是连续的动作可以使用第二个公式,做蒙特卡洛近似(蒙特卡洛就是抽一个或多个随机样本,用随机样本来近似期望)。这种方法对于离散的动作也是适用的。

策略梯度算法:
观测到t时刻的状态st
使用蒙特卡洛近似来计算梯度,把策略网络π作为概率密度函数,用其随机抽样得到动作at
计算价值函数Qπ的值,将结果记作qt
对策略网络求导,得到的

是向量矩阵或者是张量,其的大小和θ是一样的。
近似的算策略梯度,
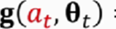
是策略梯度的蒙特卡洛近似
更新θ,做梯度上升

还有一个问题没有解决---我们并不知道
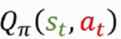
所以没有办法求qt。有两种方法可以解决。
reinforce算法
reinforce算法需要玩完一局游戏,观测到所有的奖励,然后才能更新策略网络。使用ut来近似代替qt

actor-critic方法
使用另外一个网络来近似价值网络















 6004
6004











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









