







文章目录
前言
前段时间都在忙毕业论文,强化学习这块的总结就拉下了,本小节将对《深度强化学习》中的策略学习章节进行总结。如有错误,欢迎指出。
策略学习概述
价值学习让神经网络学习最优动作价值函数
Q
π
(
s
,
a
)
Q_{\pi}(s,a)
Qπ(s,a),而策略学习让神经网络学习最优策略函数
π
(
a
∣
s
)
\pi(a|s)
π(a∣s),其中
a
a
a表示智能体执行的动作,
s
s
s表示环境状态。如下图所示,策略学习中的神经网络的输入为状态
s
s
s,输出为智能体执行各个动作的概率,接着依据概率随机抽样一个动作让智能体执行。

如未特殊提及,本文将利用
a
a
a、
A
A
A表示动作,
s
s
s、
S
S
S表示状态,
π
\pi
π表示策略。
策略学习的目标
不论是策略学习,还是价值学习,其目标都是让处于状态
s
t
s_t
st时刻的智能体,在执行一系列动作后得到的回报最大化。策略学习的目标为最大化状态价值函数
V
π
(
S
)
V_\pi(S)
Vπ(S),其定义为
V
π
(
S
)
=
E
A
∼
π
(
.
∣
S
;
θ
)
[
Q
π
(
A
,
S
)
]
(1.0)
V_\pi(S)=E_{A\sim \pi(.|S;\theta)}[Q\pi(A,S)]\tag{1.0}
Vπ(S)=EA∼π(.∣S;θ)[Qπ(A,S)](1.0)
动作价值函数
Q
π
(
A
,
S
)
Q_\pi(A,S)
Qπ(A,S)表示智能体使用策略
π
\pi
π,在状态
S
S
S做出动作后
A
A
A后获得回报的上限。而状态价值函数表示
V
π
(
S
)
V_\pi(S)
Vπ(S)表示智能体使用策略
π
\pi
π,处于状态
S
S
S时获得回报的上限。状态越好,状态价值函数取值越大,未来获得的回报也越大,例如《王者荣耀》中破敌方三高,经济领先敌方一万,这种状态下状态价值函数取值将较大,表示未来获得的回报将较大(控野区、拿双龙,甚至是破地方水晶)。依据状态价值函数的定义,策略学习的目标函数为
max
J
(
θ
)
=
max
E
S
[
V
π
(
S
)
]
(1.1)
\max J(\theta)=\max E_S[V_\pi(S)]\tag{1.1}
maxJ(θ)=maxES[Vπ(S)](1.1)
即让神经网络学习到一个策略函数
π
\pi
π,能在任意状态下让状态价值函数的取值最大化。式1.1可以使用梯度上升法优化,因此需要计算
J
(
θ
)
J(\theta)
J(θ)的梯度(又被称为策略梯度),经过一系列计算有
∇
J
(
θ
)
=
E
S
[
E
A
∼
π
(
.
∣
S
;
θ
)
[
Q
π
(
S
,
A
)
∇
θ
ln
π
(
A
∣
S
;
θ
)
]
]
(1.2)
\nabla J(\theta)=E_S[E_{A\sim \pi(.|S;\theta)}[Q_\pi(S,A)\nabla_{\theta}\ln\pi(A|S;\theta)]] \tag{1.2}
∇J(θ)=ES[EA∼π(.∣S;θ)[Qπ(S,A)∇θlnπ(A∣S;θ)]](1.2)
式1.2的具体推导可以查看原文87页到91页。对式1.2使用蒙特卡洛近似,利用
t
t
t时刻智能体所处的状态
s
t
s_t
st和动作
a
t
a_t
at,则有
∇
J
(
θ
)
=
(
1
+
γ
+
γ
2
+
.
.
.
+
γ
n
)
Q
π
(
s
t
,
a
t
)
∇
θ
ln
π
(
a
t
∣
s
t
;
θ
)
(1.2)
\nabla J(\theta)=(1+\gamma+\gamma^2+...+\gamma^n)Q_\pi(s_t,a_t)\nabla_{\theta}\ln\pi(a_t|s_t;\theta) \tag{1.2}
∇J(θ)=(1+γ+γ2+...+γn)Qπ(st,at)∇θlnπ(at∣st;θ)(1.2)
其中
γ
\gamma
γ表示回报的折扣率,n表示智能体完成一次游戏所经历的状态个数。
(
1
+
γ
+
γ
2
+
.
.
.
+
γ
n
)
(1+\gamma+\gamma^2+...+\gamma^n)
(1+γ+γ2+...+γn)为常数,会被学习率所吸收,因此可以忽略不计。策略学习的目标是使用神经网络(又称为策略网络)拟合策略函数,因此式1.2中的
θ
\theta
θ表示策略网络的参数,
∇
θ
ln
π
(
a
t
∣
s
t
;
θ
)
\nabla_{\theta}\ln\pi(a_t|s_t;\theta)
∇θlnπ(at∣st;θ)可以通过策略网络的反向传播计算得到。对于
Q
π
(
s
t
,
a
t
)
Q_\pi(s_t,a_t)
Qπ(st,at),存在REINFORCE和Actor-Critic两种方式近似表达。
策略学习方法:REINFORCE
由于
Q
π
(
s
t
,
a
t
)
Q_\pi(s_t,a_t)
Qπ(st,at)表示智能体在状态
s
t
s_t
st时,执行动作
a
t
a_t
at后获得回报(奖励)的上限,因此可以让策略网络操纵智能体完整完成一次游戏,由此可得到
(
s
1
,
a
1
,
r
1
)
、
(
s
2
,
a
2
,
r
2
)
、
.
.
.
、
(
s
n
,
a
n
,
r
n
)
(s_1,a_1,r_1)、(s_2,a_2,r_2)、...、(s_n,a_n,r_n)
(s1,a1,r1)、(s2,a2,r2)、...、(sn,an,rn)
一系列的轨迹,其中
r
i
r_i
ri表示智能体在状态
s
i
s_i
si执行动作
a
i
a_i
ai后获得的奖励。利用上述轨迹,可以计算
t
t
t时刻,智能体在状态为
s
t
s_t
st时,做出动作
a
t
a_t
at后得到的回报
u
t
u_t
ut为
u
t
=
∑
k
=
t
n
γ
k
−
t
r
k
=
Q
π
(
s
t
,
a
t
)
(1.3)
u_t=\sum_{k=t}^n \gamma^{k-t}r_k=Q_\pi(s_t,a_t) \tag{1.3}
ut=k=t∑nγk−trk=Qπ(st,at)(1.3)
策略梯度
∇
J
(
θ
)
\nabla J(\theta)
∇J(θ)可以表示成
∇
J
(
θ
)
=
∑
t
=
1
n
γ
t
−
1
E
S
t
,
A
t
[
Q
π
(
S
t
,
A
t
)
∇
θ
ln
π
(
A
t
∣
S
t
;
θ
)
]
≈
∑
t
=
1
n
γ
t
−
1
Q
π
(
s
t
,
a
t
)
∇
θ
ln
π
(
a
t
∣
s
t
;
θ
)
(1.4)
\begin{aligned} \nabla J(\theta)&=\sum_{t=1}^n\gamma^{t-1} E_{S_t,A_t}[Q_\pi(S_t,A_t)\nabla_{\theta}\ln\pi(A_t|S_t;\theta) ]\\ &\approx \sum_{t=1}^n\gamma^{t-1} Q_\pi(s_t,a_t)\nabla_{\theta}\ln\pi(a_t|s_t;\theta) \tag{1.4} \end{aligned}
∇J(θ)=t=1∑nγt−1ESt,At[Qπ(St,At)∇θlnπ(At∣St;θ)]≈t=1∑nγt−1Qπ(st,at)∇θlnπ(at∣st;θ)(1.4)
由此可得策略梯度为
∇
J
(
θ
)
=
∑
t
=
1
n
γ
t
−
1
u
t
∇
θ
ln
π
(
a
t
∣
s
t
;
θ
)
(1.5)
\nabla J(\theta)=\sum_{t=1}^n\gamma^{t-1}u_t\nabla_{\theta}\ln\pi(a_t|s_t;\theta)\tag{1.5}
∇J(θ)=t=1∑nγt−1ut∇θlnπ(at∣st;θ)(1.5)
REINFORCE的训练流程
- 用策略网络控制智能体完成一整局游戏,得到一系列轨迹: ( s 1 , a 1 , r 1 ) 、 ( s 2 , a 2 , r 2 ) 、 . . . 、 ( s n , a n , r n ) (s_1,a_1,r_1)、(s_2,a_2,r_2)、...、(s_n,a_n,r_n) (s1,a1,r1)、(s2,a2,r2)、...、(sn,an,rn)
- 计算所有时刻的回报 u t = ∑ k = t n γ k − t r k = Q π ( s t , a t ) (1.6) u_t=\sum_{k=t}^n \gamma^{k-t}r_k=Q_\pi(s_t,a_t)\tag{1.6} ut=k=t∑nγk−trk=Qπ(st,at)(1.6)
- 利用随机梯度上升法更新策略网络的参数 θ n e w = θ n o w + β ∑ t = 1 n γ t − 1 u t ∇ θ ln π ( a t ∣ s t ; θ ) \theta_{new}=\theta_{now}+\beta \sum_{t=1}^n \gamma^{t-1} u_t\nabla_{\theta}\ln\pi(a_t|s_t;\theta) θnew=θnow+βt=1∑nγt−1ut∇θlnπ(at∣st;θ)其中 θ n o w \theta_{now} θnow表示策略网络当前的参数, θ n e w \theta_{new} θnew表示更新后的策略网络参数, γ \gamma γ表示折扣率,为超参数。
策略学习方法:Actor-Critic方法
Actor-Critic方法利用神经网络近似动作价值函数 Q π ( s t , a t ) Q_\pi(s_t,a_t) Qπ(st,at),这个网络又被称为价值网络,记为 q π ( s , a ) q_\pi(s,a) qπ(s,a)。其输入为状态 s s s,输出为每个动作的动作价值函数,使用价值学习中的SARSA策略训练。价值网络(Critic)负责对策略网络(Actor)做出的动作评分
Actor-Critic的训练流程
- 观测到当前的状态 s t s_t st,将该状态输入到策略网络 π ( a ∣ s t ; θ ) \pi(a|s_t;\theta) π(a∣st;θ)中,得到智能体执行各个动作的概率。依据概率抽样其中一个动作 a t a_t at,智能体执行该动作后得到新的状态 s t + 1 s_{t+1} st+1和奖励 r t r_t rt。将状态 s t + 1 s_{t+1} st+1输入到策略网络 π ( a ∣ s t ) \pi(a|s_t) π(a∣st)中,依据输出概率抽样得到智能体执行的动作 a t + 1 a_{t+1} at+1。
- 计算 q ^ t = q π ( s t , a t ; w n o w ) \hat q_t=q_\pi(s_t,a_t;w_{now}) q^t=qπ(st,at;wnow)、 q ^ t + 1 = q π ( s t + 1 , a t + 1 ; w n o w ) \hat q_{t+1}=q_\pi(s_{t+1},a_{t+1};w_{now}) q^t+1=qπ(st+1,at+1;wnow)
- 利用利用贝尔曼方程优化价值网络 q ( s , a ; w ) q(s,a;w) q(s,a;w) w n e w = w n o w − α [ q ^ t − ( r t + q ^ t + 1 ) ] ∇ w q ( s t , a t ; w n o w ) w_{new}=w_{now}-\alpha [\hat q_t-(r_t+\hat q_{t+1})]\nabla_{w}q(s_t,a_t;w_{now}) wnew=wnow−α[q^t−(rt+q^t+1)]∇wq(st,at;wnow)
- 更新策略网络 θ n e w = θ n o w + β q ^ t ∇ θ ln π ( a t ∣ s t ; θ ) \theta_{new}=\theta_{now}+\beta \hat q_t \nabla_{\theta}\ln\pi(a_t|s_t;\theta) θnew=θnow+βq^t∇θlnπ(at∣st;θ)
其中 α \alpha α、 β \beta β为学习率。由于使用贝尔曼方程优化价值网络,因此上述训练策略会导致价值网络出现高估,可以引入目标网络解决,具体查阅强化学习——价值学习中的DQN
随着训练的进行,价值网络对策略网络做出动作的评分会越来越高,这是因为策略学习的目标是最大化状态价值函数,依据式1.0可知,最大化状态价值函数将使得动作价值函数的取值越来越大,即价值网络读策略网络做出动作的评分越来越高。
带基线的策略学习方法
上述两个策略学习的方法存在训练难以收敛的问题。对于REINFORCE方法,不同轮训练采样到的轨迹不同,回报 u t u_t ut的取值方差大,导致策略梯度方差较大,模型难以收敛。对于Actor-Critic方法,价值网络的参数不断更新也将导致 Q π ( S , A ) Q_\pi(S,A) Qπ(S,A)的取值方差大,导致策略梯度的方差较大,模型难以收敛。
基于上述考虑,带基线的策略学习方法引入了基线 b b b,此时策略梯度为
∇ J ( θ ) = E S [ E A ∼ π ( . ∣ S ; θ ) [ ( Q π ( S , A ) − b ) ∇ θ ln π ( A ∣ S ; θ ) ] ] (1.7) \nabla J(\theta)=E_S[E_{A\sim \pi(.|S;\theta)}[(Q_\pi(S,A)-b)\nabla_{\theta}\ln\pi(A|S;\theta)]] \tag{1.7} ∇J(θ)=ES[EA∼π(.∣S;θ)[(Qπ(S,A)−b)∇θlnπ(A∣S;θ)]](1.7)
其中
b
b
b即基线,
b
b
b不依赖于动作A。值得一提的是,基线并不会影响策略梯度的取值,具体而言
∇
J
(
θ
)
=
E
S
[
E
A
∼
π
(
.
∣
S
;
θ
)
[
(
Q
π
(
S
,
A
)
−
b
)
∇
θ
ln
π
(
A
∣
S
;
θ
)
]
]
=
E
S
[
E
A
∼
π
(
.
∣
S
;
θ
)
[
Q
π
(
S
,
A
)
∇
θ
ln
π
(
A
∣
S
;
θ
)
]
]
−
E
S
[
E
A
∼
π
(
.
∣
S
;
θ
)
[
b
∇
θ
ln
π
(
A
∣
S
;
θ
)
]
]
=
E
S
[
E
A
∼
π
(
.
∣
S
;
θ
)
[
Q
π
(
S
,
A
)
∇
θ
ln
π
(
A
∣
S
;
θ
)
]
]
−
E
S
[
b
E
A
∼
π
(
.
∣
S
;
θ
)
∇
θ
ln
π
(
A
∣
S
;
θ
)
]
=
E
S
[
E
A
∼
π
(
.
∣
S
;
θ
)
[
Q
π
(
S
,
A
)
∇
θ
ln
π
(
A
∣
S
;
θ
)
]
]
−
E
S
[
b
∑
A
π
(
A
∣
S
;
θ
)
∇
θ
ln
π
(
A
∣
S
;
θ
)
]
=
E
S
[
E
A
∼
π
(
.
∣
S
;
θ
)
[
Q
π
(
S
,
A
)
∇
θ
ln
π
(
A
∣
S
;
θ
)
]
]
−
E
S
[
b
∑
A
∇
θ
π
(
A
∣
S
;
θ
)
]
=
E
S
[
E
A
∼
π
(
.
∣
S
;
θ
)
[
Q
π
(
S
,
A
)
∇
θ
ln
π
(
A
∣
S
;
θ
)
]
]
−
E
S
[
b
∇
θ
∑
A
[
π
(
A
∣
S
;
θ
)
]
]
=
E
S
[
E
A
∼
π
(
.
∣
S
;
θ
)
[
Q
π
(
S
,
A
)
∇
θ
ln
π
(
A
∣
S
;
θ
)
]
]
−
E
S
[
b
∇
θ
1
]
]
=
E
S
[
E
A
∼
π
(
.
∣
S
;
θ
)
[
Q
π
(
S
,
A
)
∇
θ
ln
π
(
A
∣
S
;
θ
)
]
]
\begin{aligned} \nabla J(\theta)&=E_S[E_{A\sim \pi(.|S;\theta)}[(Q_\pi(S,A)-b)\nabla_{\theta}\ln\pi(A|S;\theta)]]\\ &=E_S[E_{A\sim \pi(.|S;\theta)}[Q_\pi(S,A)\nabla_{\theta}\ln\pi(A|S;\theta)]]-E_S[E_{A\sim \pi(.|S;\theta)}[b\nabla_{\theta}\ln\pi(A|S;\theta)]]\\ &=E_S[E_{A\sim \pi(.|S;\theta)}[Q_\pi(S,A)\nabla_{\theta}\ln\pi(A|S;\theta)]]-E_S[bE_{A\sim \pi(.|S;\theta)}\nabla_{\theta}\ln\pi(A|S;\theta)]\\ &=E_S[E_{A\sim \pi(.|S;\theta)}[Q_\pi(S,A)\nabla_{\theta}\ln\pi(A|S;\theta)]]- E_S[b\sum_A \pi(A|S;\theta)\nabla_{\theta}\ln\pi(A|S;\theta)]\\ &=E_S[E_{A\sim \pi(.|S;\theta)}[Q_\pi(S,A)\nabla_{\theta}\ln\pi(A|S;\theta)]]-E_S[b\sum_A \nabla_{\theta}\pi(A|S;\theta)]\\ &=E_S[E_{A\sim \pi(.|S;\theta)}[Q_\pi(S,A)\nabla_{\theta}\ln\pi(A|S;\theta)]]-E_S[b \nabla_{\theta}\sum_A[\pi(A|S;\theta)]]\\ &=E_S[E_{A\sim \pi(.|S;\theta)}[Q_\pi(S,A)\nabla_{\theta}\ln\pi(A|S;\theta)]]-E_S[b \nabla_{\theta}1]]\\ &=E_S[E_{A\sim \pi(.|S;\theta)}[Q_\pi(S,A)\nabla_{\theta}\ln\pi(A|S;\theta)]] \end{aligned}
∇J(θ)=ES[EA∼π(.∣S;θ)[(Qπ(S,A)−b)∇θlnπ(A∣S;θ)]]=ES[EA∼π(.∣S;θ)[Qπ(S,A)∇θlnπ(A∣S;θ)]]−ES[EA∼π(.∣S;θ)[b∇θlnπ(A∣S;θ)]]=ES[EA∼π(.∣S;θ)[Qπ(S,A)∇θlnπ(A∣S;θ)]]−ES[bEA∼π(.∣S;θ)∇θlnπ(A∣S;θ)]=ES[EA∼π(.∣S;θ)[Qπ(S,A)∇θlnπ(A∣S;θ)]]−ES[bA∑π(A∣S;θ)∇θlnπ(A∣S;θ)]=ES[EA∼π(.∣S;θ)[Qπ(S,A)∇θlnπ(A∣S;θ)]]−ES[bA∑∇θπ(A∣S;θ)]=ES[EA∼π(.∣S;θ)[Qπ(S,A)∇θlnπ(A∣S;θ)]]−ES[b∇θA∑[π(A∣S;θ)]]=ES[EA∼π(.∣S;θ)[Qπ(S,A)∇θlnπ(A∣S;θ)]]−ES[b∇θ1]]=ES[EA∼π(.∣S;θ)[Qπ(S,A)∇θlnπ(A∣S;θ)]]
设引入基线后,利用蒙特卡洛近似可得一次参数更新的梯度为
g
b
(
S
,
A
)
=
(
Q
π
(
S
,
A
)
−
b
)
∇
θ
ln
π
(
A
∣
S
;
θ
)
g_b(S,A)=(Q_\pi(S,A)-b)\nabla_{\theta}\ln\pi(A|S;\theta)
gb(S,A)=(Qπ(S,A)−b)∇θlnπ(A∣S;θ)
上式的期望即为策略梯度,则梯度的方差为
v
a
r
=
E
S
,
A
[
∣
∣
g
b
(
S
,
A
)
−
∇
θ
J
(
θ
)
∣
∣
2
]
(1.8)
var=E_{S,A}[||g_b(S,A)-\nabla_{\theta}J(\theta)||^2]\tag{1.8}
var=ES,A[∣∣gb(S,A)−∇θJ(θ)∣∣2](1.8)
当
b
b
b的取值近似于
Q
π
(
S
,
A
)
Q_\pi(S,A)
Qπ(S,A)关于动作的均值时(状态价值函数),式1.8的方差较小(比未引入基线的梯度方差小),有助于加速模型收敛,因此
b
b
b的取值为
b
=
V
π
(
S
)
(1.9)
b=V_\pi(S)\tag{1.9}
b=Vπ(S)(1.9)
带基线的REINFORCE方法
带基线的REINFORCE方法利用一个神经网络 V π ( S ; θ v ) V_\pi(S;\theta_v) Vπ(S;θv)近似状态函数 V π ( S ) V_\pi(S) Vπ(S),将MSE作为损失函数。带基线的REINFORCE方法的训练流程为
-
用策略网络控制智能体完成一整局游戏,得到一系列轨迹:
( s 1 , a 1 , r 1 ) 、 ( s 2 , a 2 , r 2 ) 、 . . . 、 ( s n , a n , r n ) (s_1,a_1,r_1)、(s_2,a_2,r_2)、...、(s_n,a_n,r_n) (s1,a1,r1)、(s2,a2,r2)、...、(sn,an,rn) -
计算所有时刻的回报
u t = ∑ k = t n γ k − t r k = Q π ( s t , a t ) (1.6) u_t=\sum_{k=t}^n \gamma^{k-t}r_k=Q_\pi(s_t,a_t)\tag{1.6} ut=k=t∑nγk−trk=Qπ(st,at)(1.6) -
计算
v ^ t = V π ( s t ; θ v ) t = 1 , 2 , 3... n \hat v_t=V_\pi(s_t;\theta_v) \ \ \ \ \ t=1,2,3...n v^t=Vπ(st;θv) t=1,2,3...n -
计算MSE损失:
L ( θ v ) = 1 2 n ∑ i = 1 n [ V π ( s t ; θ v ) − u t ] 2 L(\theta_v)=\frac{1}{2n}\sum_{i=1}^{n}[V_\pi(s_t;\theta_v)-u_t]^2 L(θv)=2n1i=1∑n[Vπ(st;θv)−ut]2
反向传播更新神经网络 V π ( S ; θ v ) V_\pi(S;\theta_v) Vπ(S;θv) -
利用随机梯度上升法更新策略网络的参数 θ n e w = θ n o w + β ∑ t = 1 n γ t − 1 ( u t − v ^ t ) ∇ θ ln π ( a t ∣ s t ; θ ) \theta_{new}=\theta_{now}+\beta \sum_{t=1}^n \gamma^{t-1} (u_t-\hat v_t)\nabla_{\theta}\ln\pi(a_t|s_t;\theta) θnew=θnow+βt=1∑nγt−1(ut−v^t)∇θlnπ(at∣st;θ)其中 θ n o w \theta_{now} θnow表示策略网络当前的参数, θ n e w \theta_{new} θnew表示更新后的策略网络参数, γ \gamma γ表示折扣率,为超参数。
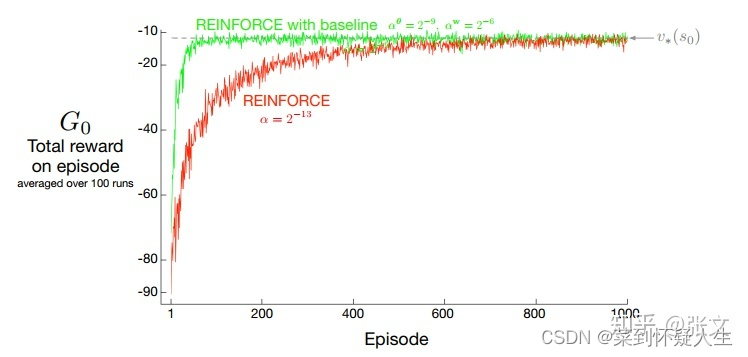
带基线与不带基线的REINFORCE方法的收敛速度比较可以看下图(源自有baseline的REINFORCE算法),由于梯度方差更小(梯度更为稳定),带基线情况下模型的收敛速度明显更快。
带基线的AdvantageActor-Critic方法(A2C)
AdvantageActor-Critic使用价值网络 q π ( s , a ; w ) q_\pi(s,a;w) qπ(s,a;w)拟合动作价值函数,而A2C使用价值网络 V π ( s ; w ) V_\pi(s;w) Vπ(s;w)拟合状态价值函数 V π ( s ) V_\pi(s) Vπ(s)。具体而言,对贝尔曼方程进行变化可得:
Q π ( S t , A t ) = E S t + 1 , A t + 1 [ R t + γ Q π ( S t + 1 , A t + 1 ) ] = E S t + 1 [ R t + γ V π ( S t + 1 ) ] (1.7) \begin{aligned} Q_\pi(S_t,A_t)&=E_{S_{t+1},A_{t+1}}[R_t+\gamma Q_\pi(S_{t+1},A_{t+1})]\\ &=E_{S_{t+1}}[R_t+\gamma V_\pi(S_{t+1})]\tag{1.7} \end{aligned} Qπ(St,At)=ESt+1,At+1[Rt+γQπ(St+1,At+1)]=ESt+1[Rt+γVπ(St+1)](1.7)
式1.7对动作
A
t
A_t
At求期望,则有
V
π
(
S
t
)
=
E
S
t
+
1
[
R
t
+
γ
V
π
(
S
t
+
1
)
]
\begin{aligned} V_\pi(S_t)&=E_{S_{t+1}}[R_t+\gamma V_\pi(S_{t+1})] \end{aligned}
Vπ(St)=ESt+1[Rt+γVπ(St+1)]
利用上式即可训练价值网络
V
π
(
s
;
w
)
V_\pi(s;w)
Vπ(s;w)拟合状态价值函数
V
π
(
s
)
V_\pi(s)
Vπ(s)(类似于SARSA)。使用蒙特卡洛近似后,带基线的策略梯度为:
∇
J
(
θ
)
≈
[
(
r
t
+
γ
V
π
(
s
t
+
1
)
)
−
V
π
(
s
t
)
]
∇
θ
ln
π
(
a
t
∣
s
t
;
θ
)
]
]
\nabla J(\theta)\approx[(r_t+\gamma V_\pi(s_{t+1}))-V_\pi(s_t)]\nabla_{\theta}\ln\pi(a_t|s_t;\theta)]]
∇J(θ)≈[(rt+γVπ(st+1))−Vπ(st)]∇θlnπ(at∣st;θ)]]
基于上述分析,A2C方法的训练流程为
- 观测到当前的状态 s t s_t st,将该状态输入到策略网络 π ( a ∣ s t ; θ ) \pi(a|s_t;\theta) π(a∣st;θ)中,得到智能体执行各个动作的概率。依据概率抽样其中一个动作 a t a_t at,智能体执行该动作后得到新的状态 s t + 1 s_{t+1} st+1和奖励 r t r_t rt。
- 计算 v ^ t = V π ( s t ; w n o w ) \hat v_t=V_\pi(s_t;w_{now}) v^t=Vπ(st;wnow)、 v ^ t + 1 = V π ( s t + 1 ; w n o w ) \hat v_{t+1}=V_\pi(s_{t+1};w_{now}) v^t+1=Vπ(st+1;wnow)
- 利用利用贝尔曼方程优化价值网络 q ( s , a ; w ) q(s,a;w) q(s,a;w) w n e w = w n o w − α [ v ^ t − ( r t + v ^ t + 1 ) ] ∇ w q ( s t , a t ; w n o w ) w_{new}=w_{now}-\alpha [\hat v_t-(r_t+\hat v_{t+1})]\nabla_{w}q(s_t,a_t;w_{now}) wnew=wnow−α[v^t−(rt+v^t+1)]∇wq(st,at;wnow)
- 更新策略网络 θ n e w = θ n o w + β [ ( r t + v ^ t + 1 ) − v ^ t ] ∇ θ ln π ( a t ∣ s t ; θ ) \theta_{new}=\theta_{now}+\beta [(r_t+\hat v_{t+1})-\hat v_t] \nabla_{\theta}\ln\pi(a_t|s_t;\theta) θnew=θnow+β[(rt+v^t+1)−v^t]∇θlnπ(at∣st;θ)
其中 α \alpha α、 β \beta β为学习率。由于使用贝尔曼方程优化价值网络,因此上述训练策略会导致价值网络出现高估,可以引入目标网络解决,具体查阅强化学习——价值学习中的DQN
其他
在实际场景中,我们可以对环境返回的奖励进行定义,利用策略梯度算法让神经网络学习具备某种特性的策略。例如在王者荣耀中,可以将智能体的击杀定义为奖励,智能体击杀一个敌人后,从环境中返回一个正向奖励,此时通过策略网络学习到的将是如何最大化自己的击杀数。


















 2081
2081

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









