







三 策略学习
1. policy Function π ( a ∣ s ) \pi(a|s) π(a∣s)
什么是策略函数
π
(
a
∣
s
)
\pi(a|s)
π(a∣s),策略函数就像现实世界中的参谋长、军师,他们根据你的现身处境,帮你出谋划策,指引你采取下一步动作。
在强化学习中,我们用策略函数来表示它,多数情况下,该函数是以一种概率密度函数PDF(probability density function)
π
(
a
∣
s
)
\pmb{\pi(a|s)}
π(a∣s)的形式来表现出来的,以用来模拟现实中做决定的不确定性。
//
策略函数以状态s作为输入, 以 动作a作为输出:
即:
s
→
π
→
a
s \rightarrow \pi \rightarrow a
s→π→a
比如有如下处境s:

策略给出的结果是:
π
(
←
∣
s
)
=
0.7
\pi(\leftarrow | s) = 0.7
π(←∣s)=0.7
π
(
→
∣
s
)
=
0.2
\pi(\rightarrow | s) = 0.2
π(→∣s)=0.2
π
(
↑
∣
s
)
=
0.1
\pi(\uparrow | s) = 0.1
π(↑∣s)=0.1
智能体马里奥根据概率值随机抽样一个动作执行。那么马里奥大概率会向左走。
2. 策略神经网络 π ( a ∣ s , θ ) \pi(a | s, \pmb{\theta}) π(a∣s,θ)
那么问题来了: 既然策略学习流程那么简单, 那我们该如何得到一个这样的策略函数呢?
毕竟游戏里画面简单,动作只有前后跳三种动作,但是现实世界中动作可能都是连续的,可能有无数个可选的动作。
如此复杂的情况,当然需要神经网络上场了。
policy Network: 使用策略网络近似策略函数 :
π ( a ∣ s , θ ) ≈ π ( a ∣ s ) \pi(a|s,\pmb{\theta}) \approx \pi(a|s) π(a∣s,θ)≈π(a∣s)
其中 θ \theta θ表示可训练的神经网络参数
将一个状态作为输入, 经卷积层得到特征向量。
再经过全连接层映射到一个三维向量(输出是上中下三个动作)
经过softmax激活函数得到概率分布函数.
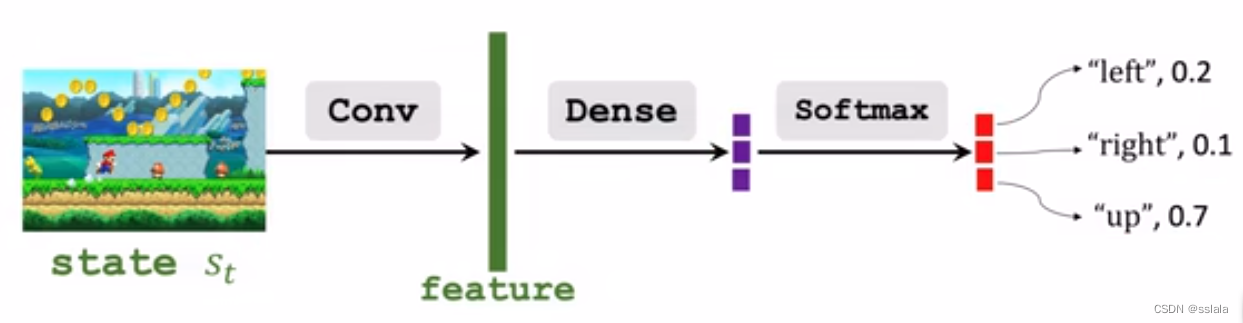
softmax 保证概率是正数且加和等于1
3. state value function 状态值函数
既然策略有了,该如何评价这个策略的好坏(更新策略网络)呢.
V
π
(
s
t
)
V_{\pi}(s_t)
Vπ(st)状态值函数就是这样一个评价标准。
我们知道动作值函数
Q
π
(
s
t
,
a
t
)
Q_{\pi}(s_t, a_t)
Qπ(st,at)是用来评价一个动作好坏的标准。
而值函数
V
π
(
s
t
)
V_{\pi}(s_t)
Vπ(st)评价的是采用该策略后,做出任意动作后状态的好坏。
用公式来说就是:
V
π
(
s
t
)
=
E
A
[
Q
π
(
s
t
,
A
)
]
V_{\pi}(s_t) = E_A[Q_{\pi}(s_t, A)]
Vπ(st)=EA[Qπ(st,A)]
E A E_A EA是 Q π Q_{\pi} Qπ的期望值, Q π Q_{\pi} Qπ表示任意动作的好坏,
即 E A E_A EA = 动作的概率 x 动作的回报。
如果A 是离散的变量有:
V
π
(
s
t
)
=
∑
a
π
(
a
∣
s
t
)
⋅
Q
π
(
s
t
,
a
)
.
V_{\pi}(s_t) = \sum_a\pi (a|s_t)\cdot Q_\pi (s_t, a).
Vπ(st)=a∑π(a∣st)⋅Qπ(st,a).
4. policy-based Reinforcement learning 策略学习
既然理解了上面3个重要成员,下面让我们来看看策略学习是如何进行的。
首先要明确的是,我们的最终目标就是要训练出一个优秀的策略
π
\pi
π来使得回报最大。
换句话说,就是要训练出一个优秀的 θ \pmb{\theta} θ
我们有预测值
V
(
s
;
θ
)
=
∑
a
π
(
a
∣
s
t
;
θ
)
⋅
Q
π
(
s
t
,
a
)
.
V(s;\pmb{\theta}) = \sum_a\pi (a|s_t; \pmb{\theta})\cdot Q_\pi (s_t, a).
V(s;θ)=∑aπ(a∣st;θ)⋅Qπ(st,a).
目标就是使得
V
(
s
;
θ
)
V(s;\pmb{\theta})
V(s;θ)最大。
使用梯度上升来更新 θ \pmb{\theta} θ 以最大化 V ( s ; θ ) V(s;\pmb{\theta}) V(s;θ) :
θ ← θ + β ⋅ δ V ( s ; θ ) δ θ \theta \leftarrow \theta + \beta \cdot \frac{\delta V(s;\theta)}{\delta \theta} θ←θ+β⋅δθδV(s;θ)
5. policy gradient 策略梯度
根据上一节的推理分析,我们要做的就是求梯度上升的 δ V ( s ; θ ) δ θ \frac{\delta V(s;\theta)}{\delta \theta} δθδV(s;θ)
做一系列数学推导,得到如下两种表达形式:(这里的数学推导就不再解释了,因为比较考验数学,而且也无关紧要,主流的框架都支持自动求梯度)
δ V ( s ; θ ) δ θ = { ∑ a δ π ( a ∣ s ; θ ) δ θ ⋅ Q π ( s , a ) ,离散情况 E A ∼ π ( ⋅ ∣ s ; θ ) [ δ l o g π ( a ∣ s ; θ ) δ θ Q π ( s , a ) ] ,连续情况 \frac{\delta V(s;\theta)}{\delta \theta} =\begin{cases} \sum_a \frac{\delta \pi(a|s;\theta)}{\delta \theta} \cdot Q_{\pi}(s, a),离散情况\\ E_{A\sim \pi(\cdot|s;\pmb{\theta})}[\frac{\delta log \pi (a|s; \theta)}{\delta \theta} Q_{\pi}(s, a)],连续情况\end{cases} δθδV(s;θ)={∑aδθδπ(a∣s;θ)⋅Qπ(s,a),离散情况EA∼π(⋅∣s;θ)[δθδlogπ(a∣s;θ)Qπ(s,a)],连续情况
对于离散的情况,就是把每个动作对应的值叠加,就得到了梯度 δ V ( s ; θ ) δ θ \frac{\delta V(s;\theta)}{\delta \theta} δθδV(s;θ)
对于连续的动作,公式右边的期望计算非常复杂,目前学界都是使用蒙特卡罗近似
蒙特卡洛抽样近似,就是抽多个随机样本,通过抽取样本的观测值的期望来近似所要计算的公式的期望。
也就是说我们虽然不能计算这个期望,但是我们可以枚举,通过多次的枚举,也能大差不差的算出函数的期望值。
蒙特卡罗近似记为:
g
(
a
^
,
θ
)
\pmb{g}(\hat{a}, \pmb{\theta})
g(a^,θ)
这里的蒙特卡洛就是用来近似:
g
(
a
^
,
θ
)
=
δ
l
o
g
π
(
a
∣
s
;
θ
)
δ
θ
Q
π
(
s
,
a
)
\pmb{g}(\hat{a}, \pmb{\theta}) = \frac{\delta log \pi (a|s; \theta)}{\delta \theta} Q_{\pi}(s, a)
g(a^,θ)=δθδlogπ(a∣s;θ)Qπ(s,a)
6. 让我们总结以下算法的伪代码
- 观测到状态 s t s_t st
- 根据策略 π ( ⋅ ∣ s t ; θ t ) \pi(\cdot|s_t; \pmb{\theta_t}) π(⋅∣st;θt)的概率随机抽取动作 a t a_t at执行
- 计算该动作的预期价值回报: q t ≈ Q π ( s t , a t ) q_t \approx Q_{\pi}(s_t, a_t) qt≈Qπ(st,at)
- 微分求策略网络的梯度: d θ , t = δ l o g π ( a t ∣ s t , θ ) δ θ ∣ θ = θ t \pmb{d_{\theta,t}} = \frac{\delta log\pi(a_t|s_t,\pmb{\theta)}}{\delta \theta} |_{\pmb{\theta = \theta_t}} dθ,t=δθδlogπ(at∣st,θ)∣θ=θt (tensorflow, pythorch 这些框架都支持自动求梯度)
- 近似求策略梯度(用蒙特卡洛采样求梯度): g ( a t , θ t ) = q t ⋅ d θ , t \pmb{g}(a_t, \pmb{\theta_t}) = q_t \cdot \pmb{d_{\theta, t}} g(at,θt)=qt⋅dθ,t
- 更新策略网络: θ t + 1 = θ t + β ⋅ g ( a t , θ t ) \pmb{\theta_{t+1}} = \pmb{\theta_t}+\beta\cdot\pmb{g}(a_t, \pmb{\theta_t)} θt+1=θt+β⋅g(at,θt)
上述步骤3中,如何近似计算 q t q_t qt:
方法1: 强化学习的暴力破解方法:1局玩完,然后计算所有状态的奖励r:
s 1 , a 1 , r 1 , s 2 , a 2 , r 2 , . . . . . . , s T , a T , r T s_1, a_1, r_1, s_2, a_2, r_2, ......, s_T, a_T,r_T s1,a1,r1,s2,a2,r2,......,sT,aT,rT
然后对所有时刻的t 计算回报: u t = ∑ K = t T γ K − t r K u_t = \sum_{K=t}^{T}\gamma^{K-t}r_K ut=∑K=tTγK−trK
方法2:使用神经网络来近似计算 Q π Q_{\pi} Qπ
那么这样就有2个神经网络了,一个叫actor(策略网络),一个叫critic(评价网络)即actor-critic方法。















 696
696











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









