







大部分引用参考了既安的https://www.zhihu.com/question/337886108/answer/893002189这篇文章,个人认为写的很清晰,此外补充了一些自己的笔记。
弄清楚Decoder的输入输出,关键在于图示三个箭头的位置:
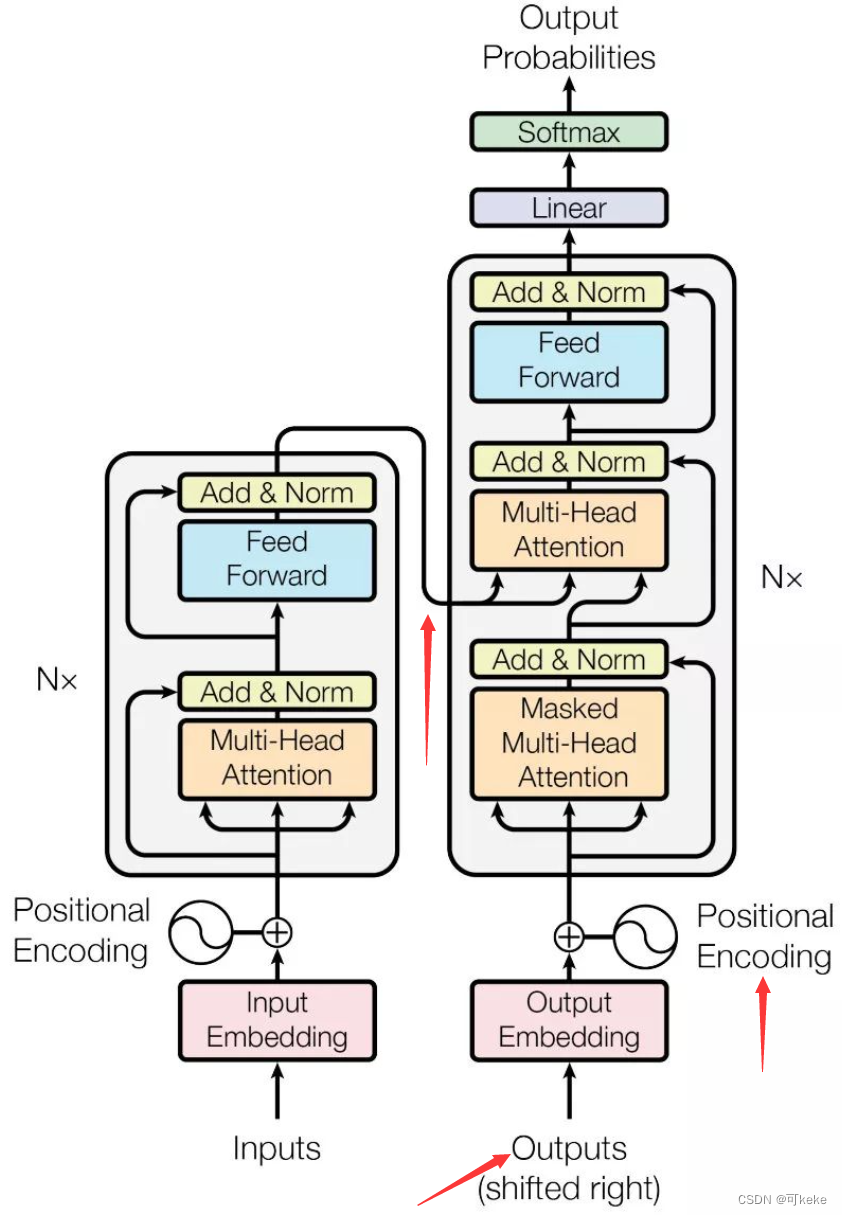
以翻译为例:
- 输入:我爱中国
- 输出: I Love China
因为输入(“我爱中国”)在Encoder中进行了编码,这里我们具体讨论Decoder的操作,也就是如何得到输出(“I Love China”)的过程。
Decoder执行步骤
Time Step 1
- 初始输入: 起始符
</s>+ Positional Encoding(位置编码) - 中间输入:(我爱中国)Encoder Embedding
- 最终输出: 产生预测“I”
Time Step 2
- 初始输入:起始符
</s>+ “I”+ Positonal Encoding - 中间输入:(我爱中国)Encoder Embedding
- 最终输出:产生预测“Love”
Time Step 3
- 初始输入:起始符
</s>+ “I”+ “Love”+ Positonal Encoding - 中间输入:(我爱中国)Encoder Embedding
- 最终输出:产生预测“China”
图示

整体右移一位(Shifted Right)
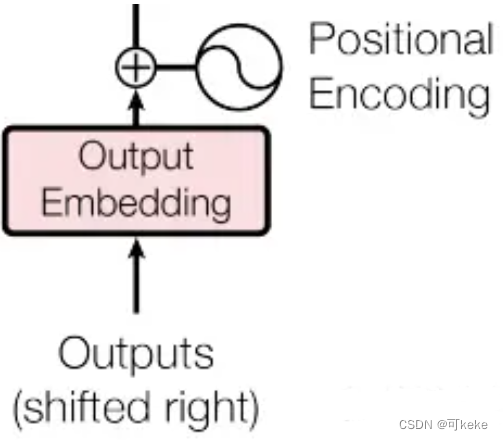
论文在Decoder的输入上,对Outputs有Shifted Right操作。
Shifted Right 实质上是给输出添加起始符/结束符,方便预测第一个Token/结束预测过程。
正常的输出序列位置关系如下:
- 0-“I”
- 1-“Love”
- 2-“China”
但在执行的过程中,我们在初始输出中添加了起始符,相当于将输出整体右移一位(Shifted Right),所以输出序列变成如下情况:
- 0-【起始符】
- 1-“I”
- 2-“Love”
- 3-“China”
这样我们就可以通过起始符预测“I”,也就是通过起始符预测实际的第一个输出。
笔记
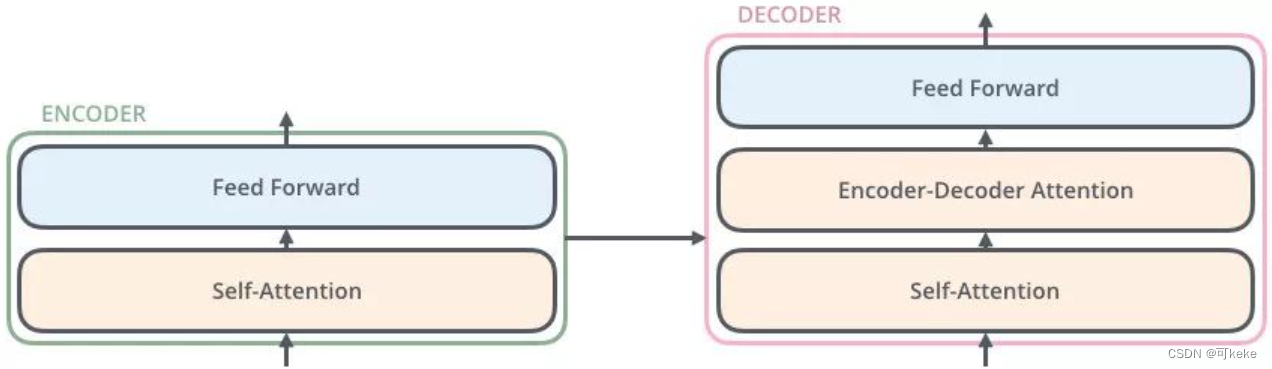
Transformer中Decoders也是 N=6 层,通过上图我们可以看到每层 Decoder 包括 3 个 sub-layers:
-
第一个 sub-layer是 Masked Multi-Head Self-Attention,这个层的输入是:
前一时刻Decoder输入+前一时刻Decoder的预测结果 + Positional Encoding。 -
第二个sub-layer是Encoder-Decoder Multi-Head Attention,这个层的输入是:
Encoder Embedding+上层输出。
也就是在这个层中:
Q是Decoder的上层输出(即Masked Multi-Head Self-Attention的输出)
K\V是Encoder的最终输出
tips:这个层不是Self-Attention,K=V!=Q(等号是同源的意思)。 -
第三个 sub-layer 是前馈神经网络层,与 Encoder 相同。
总结
Transformer Decoder的输入:
- 初始输入:前一时刻Decoder输入+前一时刻Decoder的预测结果 + Positional Encoding
- 中间输入:Encoder Embedding
- Shifted Right:在输出前添加起始符,方便预测第一个Token















 216
216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









